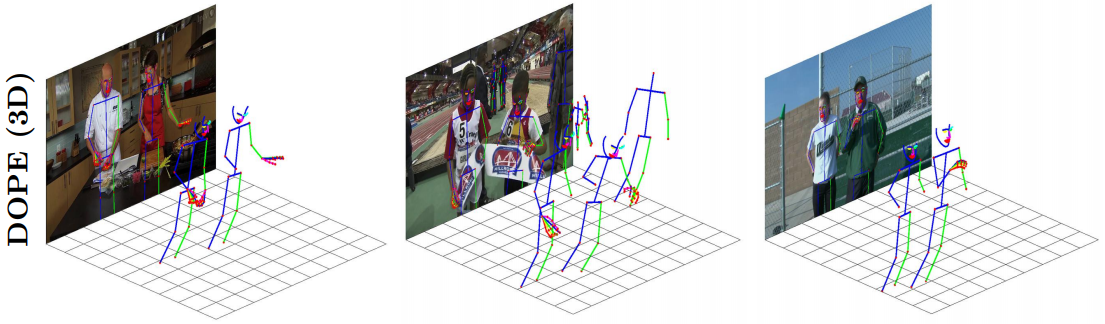
DOPE:基于蒸馏网络的全身三维姿态估计
DOPE:基于蒸馏网络的全身三维姿态估计


1. 论文简要
本论文提出一种检测和估计全身三维人体姿态的方法(身体,手,人脸),该方法的挑战主要在于带标签的3D全身姿态。大多数之前的工作将标注好的数据单独应用于身体,人手,或者人脸当中。在这项工作中,本文提出利用这些数据集来训练各个部分的独立专家模型,即身体、手和脸的模型,并将他们的知识提取到一个单一的深度网络中,用于全身的2D-3D位姿检测。在实际应用中,针对一幅有部分标注或没有标注的训练图像,各部分专家模型分别对其二维和三维关键点子集进行检测,并将估计结果结合起来得到全身伪真实标注姿态。蒸馏损失引导整个身体的预测结果尽量模仿专家模型的输出。
测试代码和模型地址:https://europe.naverlabs.com/research/computer-vision/dope
2. 背景介绍
在现实世界的图像和视频的理解在人类有许多潜在的应用,从阿凡达动画增强虚拟现实到机器人技术。人体全身三维位姿估计的任务主要是逐个部分进行的,之前的工作对人体位姿估计,人手姿态或人脸标定进行了研究。这些方法在各自的具体任务上都有突出的表现,如何有效地将它们结合起来是一个有待解决的问题。
全身三维人体姿态的标注方案在处理三维姿态时是不可能的,当目标人物的重要部分被遮挡或在图像边界之外时,就会导致全局估计失败的情况。其他一些工作利用由身体、手和脸部缝合在一起的参数化人体模型,比如Adam,SPML-X,但是这些优化方法对初始值敏感,而且常常收敛很慢,这种方法依赖于人体个体各部分的三维方向或者二维关键点位置。
在本文中提出了第一个基于学习的方法,给定一幅图像,检测出现在场景中的人,并直接预测他们的身体、手和脸的2D和3D姿态。第一步设计了一种分类回归网络,其中要检测的对象类别为身体、手和脸的姿态类;第二步通过对每个类在2D和3D中的平均姿态进行变形,使用类回归来细化身体、手和脸的姿态估计。
目前还没有现成的数据集来直接训练我们的网络,即对身体、手和脸的姿态进行3D姿态标注的图像。这样的数据只能在特定的环境中获得,例如在动作捕捉房间或通过计算机生成,这与我们在无约束的场景中进行全身姿态估计的目的是不匹配的。对于每个独立的任务,都有多个数据集使用,比如3D人体姿态估计,3D人手姿态估计,或者3D面部标定。在这些数据集上训练特定任务的方法在实际应用中效果较好,但实验表明,在这些数据集的结合上训练单一模型进行全身三维姿态估计会导致性能较差。
为了解决这一问题,针对身体、手和脸的各个部分训练专家模型,并将他们的知识提取到全身姿态检测网络。在实际应用中,针对一幅有部分注释或无注释的训练图像,各部分专家模型对其二维和三维关键点子集进行检测和估计,并将估计结果结合起来,得到全身网络的全身伪真实姿态,将蒸馏损失应用于网络的输出,以使其接近专家的预测。
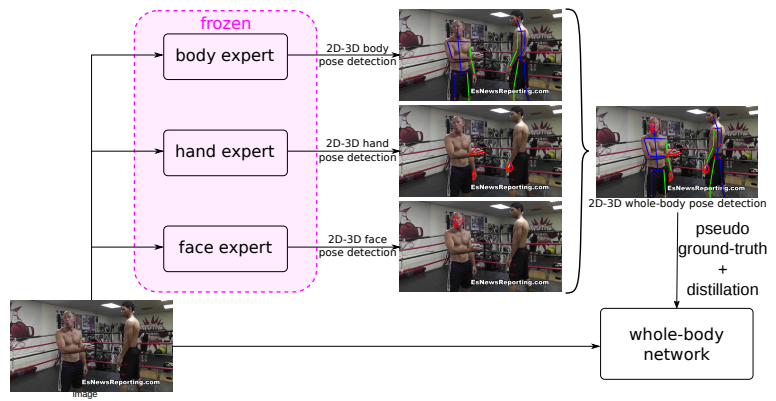
3. 相关工作
三维人体全身姿态估计问题主要是通过将人体分割成多个部分,重点研究这些部分各自的姿态推断。下面,在总结几种预测整个身体3D姿态的方法之前,将简要回顾这些子任务的最新进展,最后讨论现有的蒸馏方法。
3D人体姿态估计:(1)通过直接回归3D人体关键点;(2)先进行2D人体姿态,然后提升到3D空间(SPML);
对于人体部分,使用了LCR-Net++,它可以从图像中联合估计出2D和3D的身体姿态。
3D人手姿态估计:深度图像的人手位姿估计已经研究了很多年,由于能够获取精确的三维信息,模型的精度已经达到相当的精度,目前学术界研究热点从RGB图像中获得三维人手姿态。(1)基于回归直接预测手的关键点的三维位置,或者来自输入图像的mesh顶点。有些方法通过对变形手模型参数的回归来引入先验信息,如MANO等方法。(2)许多技术通过2D关键点热图来进行3D预测。
3D人脸姿态估计:与手一样,面部姿态的恢复通常是通过检测特定的2D面部标注。更好地感知一张脸的三维姿态和形状。(1)拟合一个三维(Morphable)形变模型;(2)回归密集的3D人脸
3D全身姿态估计:现有的几种预测全身三维位姿的方法都依赖于人体的参数化模型,例如Adam和SMPL-X。这些模型是通过结合身体、手和面部的参数化模型得到的。Adam将三种不同的模型缝合在一起,SMPL用于身体,人工创建Rig用于人手,FaceWarehouse模型用于面部。对于SMPL- x, SMPL人体模型用FLAME模型和MANO进行扩充。在SMPL-X的情况下,通过学习形状和与位置相关的混合形状,得到了更真实的模型。两种方法都基于以二维关节位置或三维部分方位为导向的优化方案。对此类模型的参数进行优化可能会耗费大量时间,而且性能通常取决于正确的初始化。
蒸馏:本论文的学习过程是基于蒸馏的概念,通过使用一个更大容量模型的类概率作为一个更小和更快的模型的软目标。
4. 2D-3D全身姿态估计
4.1 全身姿态估计结构
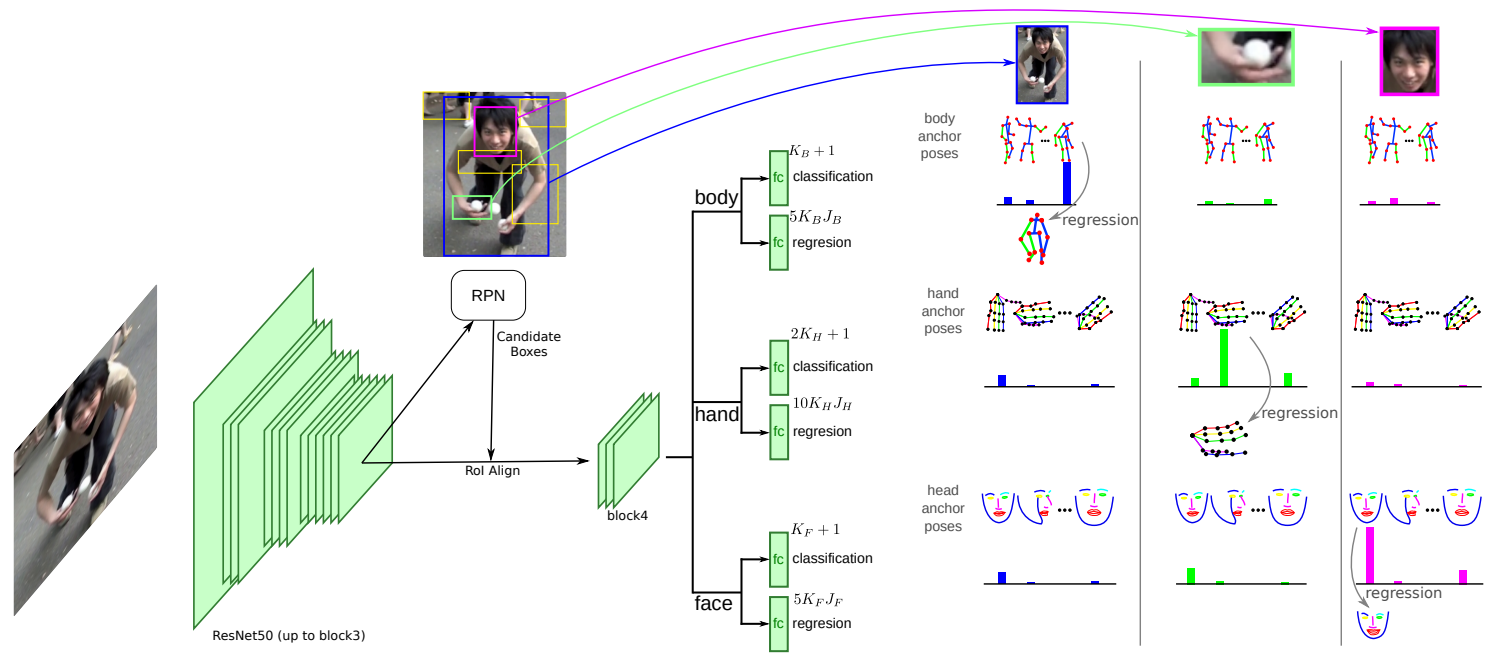
图中整个流程,给定一个输入图像,卷积特征被计算并输入到一个RPN网络来产生一个候选框列表。对于每个盒子,在RoIAlign和一些额外的层之后,计算出6个最终输出(每个部分2个)。第一个返回与此部分对应的每个锚位的分类分数(包括一个背景类),而第二个返回通过拟合锚位回归得到的精细的2D-3D位姿估计。
4.2 蒸馏专家模型
将三位专家模型的知识提取到全身姿态检测模型中,\(\cal{B}\)代表body任务,\(\cal{H}\)代表Hand任务,\(\cal{F}\)代表face任务。目标函数设置为\(\cal{L}\),RPN的损失用\(\cal{L_{RPN}}\)表示,身体,人手,脸的集合为 \(p\in\{body,hand,face\}\);(a)分类损失\(\cal{L^p_{cls}}\),(b)回归损失\(\cal{L^p_{reg}}\),(c)蒸馏损失\(\cal{L^p_{dist}}\)。
蒸馏损失函数:
4.3 训练细节
数据集:(1)人体专家模型数据集,MPII、COCO、LSP、LSPE、Human3.6M和Surreal;(2)人手专家模型数据集,RenderedHand;(3)人脸专家模型数据集,Menpo;
训练过程:SGD,动量为0.9,权重衰减0.0001,学习率为0.02,在第30、45周期后缩小10倍。
运行时间:DOPE在单个NVIDIA T4 GPU上运行100ms。当将最小的图像尺寸缩小到400px,候选框框数减少到50,并使用半精度时,它的运行速度为每幅图像28毫秒,也就是说,实时35帧/秒,性能下降2-3%。
5. 实验
5.1 数据集和评价标准
2D人体姿态估计MPII,3D人体姿态估计MuPoTs,3D人手姿态估计RenderedHand,人脸标定估计Menpo
5.2 专家系统比较

5.3 与the state of the art比较

6. 结论
本文第一个提出了全身三维人体姿态检测和估计方法DOPE,包括身体、手和脸的2D-3D关键点。解决了这个任务缺乏训练数据的问题,通过利用部分专家的精馏到的全身网络。实验验证了该方法的有效性,结果与部分专家的结果接近。