
MeshFlow视频降噪
MeshFlow Video Denoising
代码地址:https://github.com/AlbusPeter/MeshFlow_Video_Denoising_OpenCV310
论文地址:http://www.liushuaicheng.org/ICIP/2017/Ren.pdf
Abstract
我们提出了一种有效的视频去噪方法,利用最近提出的用于摄像机运动补偿的meshflow运动模型生成干净的视频。meshflow是一个空间光滑的稀疏运动场,运动矢量位于网格顶点。该模型具有轻量级、非参数化、空间变形体等内在特征,能够有效地实现多帧图像的去噪。具体来说,meshflow是在相邻帧之间进行估计的,这些帧用于在一个滑动时间窗口内对齐帧。一个去噪的帧是由几帧在空间和时间的方式与离群拒绝融合产生的。各种具有挑战性的例子证明了该方法的有效性和实用性。
1. Introduction
在弱光环境下拍摄的视频,强噪声常常会影响严重降低视频质量的。图像/视频去噪方法[1,2,3,4,5]旨在去除或抑制噪声,提高视频质量。一些方法探索小波域内多分辨率表示法的稀疏性[6,7]或利用非局部测量进行恢复[8,9]。一般情况下,多幅图像去噪优于单幅图像去噪,因为提供了更多的观测值。视频帧通常包含互补信息,可以融合这些信息进行强去噪[10,11]。在这项工作中,我们的目标是用手持摄像机拍摄的视频去噪。请参考项目页面的视频和结果。
通常,在实际的视频去噪方面有两个挑战,即摄像机运动补偿和瞬时像素融合过程中离群点的处理。前者是指相邻视频帧之间的图像配准。由于相机在捕捉过程中不是静止的,精确的运动估计可以提高各种应用程序的性能,如HDR[12]、视频去模糊[13]和视频稳定[14]。后者可以抑制由未对齐引起的伪影(如重影),这可能是由各种原因引起的,包括动态对象、遮挡和对运动模型的描述不足(如单一单应性)。
Liu等人提出了一种多帧去噪方法,该方法将多个手机突发模型捕获的图像合并到一个干净的去噪图像[15]中。提出了一种用于图像序列比对的参数金字塔同伦流运动模型。采用基于多尺度的时空融合和一致像素验证相结合的方法,对去噪结果进行了综合。最近,Liu等人提出了一种用于视频稳定[16]的meshflow运动模型。meshflow是一种非参数运动模型,它由分布在网格顶点上的稀疏运动矢量组成。
受这两篇文章的启发,我们提出使用meshflow运动模型进行视频去噪。与多尺度同类流相比,网格流的估计不需要层次结构和逐层优化,效率更高,更方便,即使不是更优的结果,也具有可比性。在meshflow的基础上,我们利用像素轮廓的概念[17,18],而不是采用真实的运动轨迹,来进行有效的运动积累和一致的像素识别。通过结合多种新颖的方法,我们提出了一种视频去噪框架,与目前最先进的技术相比,该框架不仅可以高效地运行,而且可以产生高质量的结果方法: BM3D[5]、VBM3D[19]、BM4D[20]、VBM4D[21]、Burst[15]。
2. MeshFlow Denoising
图1显示了我们的思路。对于给定的输入噪声视频,我们估计相邻帧之间的meshflow (Sec. 2.1)。为了对一帧去噪,我们沿着视频移动一个时间窗口,半径为5帧。根据meshflow估计的运动,窗口内的帧向中心帧翘曲(第2.2节)。在本地窗口中,所有的帧都与中心帧对齐,我们将它们融合以消除中心帧的噪声。融合包括离群点的识别。在图1(c)中,绿色和红色圆点表示离群点和离群点像素。关于细节一致性检查和融合过程将在第2.3节中讨论。窗口每次向前移动一帧,视频逐帧去噪。
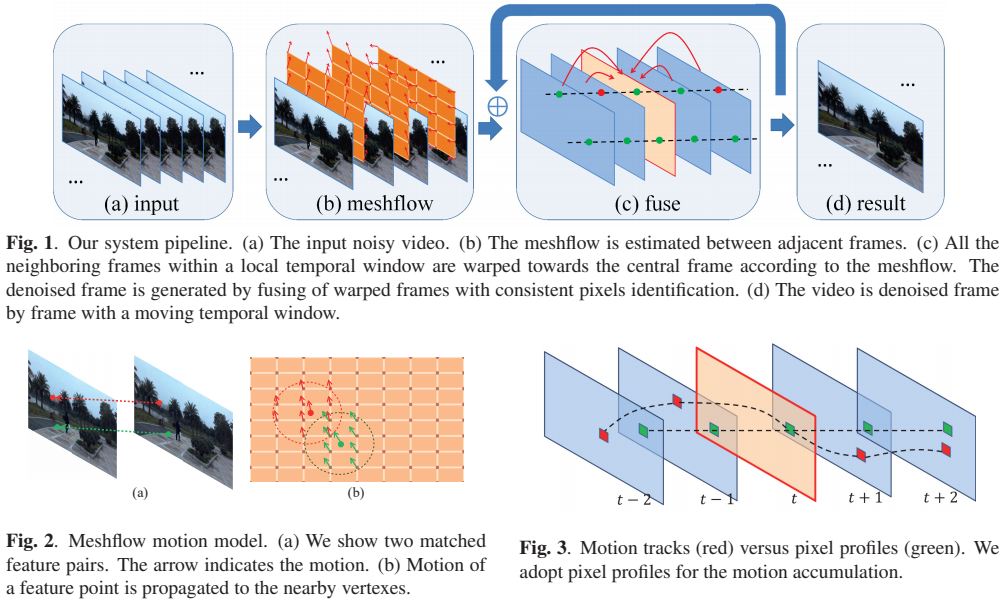
2.1 MeshFlow Motion Model
meshflow是一个稀疏运动场。它通常用于估计相邻帧之间的运动,这最初是在[16]中提出的。为了完整起见,我们将在本节中介绍meshflow。
丰富的功能。我们检测快速的图像特征[22],并通过KLT[23]对其进行相邻帧的跟踪。meshflow估计更倾向于均匀而密集的特征覆盖。因此,针对不同的图像区域,检测阈值是局部自动调整的。有关丰富的功能修剪的更多细节可以在[24]中找到。
运动传播。每个匹配的特征对产生如图2(a)所示的运动向量。在我们的实现中,我们计算当前帧与前一帧之间的运动。在当前帧上放置一个规则的网格,将特征点的运动复制到附近的网格顶点,如图2(b)所示。值得注意的是,有些顶点可能接收来自不同特征点的多个运动矢量。
中位数过滤器。每个网格顶点应该只有一个唯一的运动向量,它是由一个中值滤波器从每个顶点的候选运动中挑选出来的。在空间上应用另一个中值滤波来剔除由不匹配的特征和动态对象引起的运动异常值。为此,我们得到了一个平滑变化的稀疏运动场。更多的讨论可以在[16]中找到。
符号。当我们反向计算运动时,坐标系 \(t\) 处的meshflow表示为 \(F_t\),运动从坐标系 \(t\) 指向坐标系 \(t−1\)。第一帧的meshflow设置为0。
2.2 Motions Accumulation
图3显示了一个运动跟踪和运动积累的示例。为了去除帧t(图3的红色边框),我们需要将相邻的帧(图3的蓝色边框)向中心帧 \(t\) 弯曲。例如,我们想要将帧 \(t−2\) 弯曲到帧 \(t\)。一个解决方案是直接估计它们之间的meshflow。但由于引入了额外的特征检测和跟踪,因此效率不高。我们的解决方案是使用之前估计的相邻meshflow \(F_t\)来近似非相邻跳转。
有两种选择。直观地,我们应该跟踪运动路径,形成一个运动轨迹(图3红色方块)。然而,也有一些问题,如轨道可以移出框架。此外,我们需要检查轨道的值来决定后续的位置,这是低效的。我们的解决方案是采用像素配置策略[17]。像素轮廓沿时间在一个固定的空间位置收集运动矢量(图3绿色方块)。从[17]中可以看出,像素轮廓处的运动是对应运动轨迹的很好的近似。配置文件可以带来一些优势,比如完全覆盖(没有边界问题)和并行计算(每个像素位置都是独立计算的)。因此,对于非相邻帧,我们采用轮廓来累积相邻帧的运动:
其中 \(s\) 和 \(t\) 为帧索引,\(P^t_s\)为指向 \(s\) 到 \(t\) 的网格流,其中对稀疏运动场进行累加。我们根据该网格流由一个基于网格的图像翘曲。为此,本地窗口内的所有帧都被扭曲到中心帧。

2.3 Fusing
在所有帧与目标帧对齐的情况下,我们对同一空间位置的像素进行平均去噪。有些像素不能平均,如果他们对应的未对齐,闭塞或动态对象。这些不一致像素的融合会导致严重的“重影”效果。对于每个像素位置,我们将目标帧的像素强度与相关候选像素进行比较。像素强度差异小于一个经验阈值 \(\tau= 20\) (强度范围为0∼255)被视为一致的像素。在[15]中还探索了其他的策略。在这里,我们保持我们的方法简单而有效。
3. Experiments
通过几个方面的实验,验证了设计的有效性。
像素的一致性。图4显示了去噪结果与有一致性验证和无一致性验证的对比。请注意移动的人用红色箭头高亮显示的重影效果。
运动积累。图5显示了第2.2节中讨论的直接运动计算和运动累积的比较。这两种方法都能产生相似的结果。然而,直接计算需要额外的特征检测和非相邻帧之间的跟踪。
平移和行走我们在各种相机运动类型测试我们的性能。在平移和行走过程中拍摄的视频比那些没有大镜头移动的视频更具挑战性。因为由于场景的变化,在局部窗口中可以注册的帧数更少。实验结果表明,该方法能够较好地处理相机运动。
4. Results
我们在Intel i7 4.0GHz CPU和16G RAM上运行我们的方法。我们的未优化c++实现平均可以处理260ms分辨率为1920×1080的帧。具体来说,我们的方法分别需要27ms、21ms、38ms、25ms和149ms来跟踪特征、估计网格流、累积运动、检查一致性和融合像素。该方法还可以通过GPU进一步加速,特别是对于具有高度并行性的融合。
我们将我们的方法与BM3D[5]、VBM3D[19]、BM4D[20]、VBM4D[21]和Burst[15]方法进行了比较。所有这些方法都很慢。他们通常需要超过一分钟的时间来处理一个帧,除了突发的去噪[15],它报告的速度为480ms处理一个帧在类似的图像分辨率。图6给出了一些结果。在比较的例子中仍然可以观察到残余噪声。请注意第一个例子中电线的缺失。比较例子的时间问题可以在伴随视频中查看。
我们从突发去噪[15]的项目页面中收集了一些数据进行比较。图7给出了两个例子。突发式去噪方法以图像去噪为目标,其中10幅噪声图像作为系统的输入,1幅干净图像作为系统的输出。我们使用与[15]相同的输入生成结果。我们的方法可以产生类似的结果。值得注意的是,[15]的像素一致性策略倾向于拒绝移动的对象,这在输出为单一图像时可能是合理的。然而,我们的视频去噪必须保持如图7所示的动态对象。
5. Conclusion
提出了一种利用网格流运动模型进行视频去噪的方法。通过运动累积和像素一致性验证,我们的方法可以在非常快的速度下获得较强的去噪效果。我们的方法对不同类型的摄像机运动和场景类型具有鲁棒性。各种具有挑战性的案例证明了该方法的有效性。
References
[1] P. Chatterjee, N. Joshi, S. Kang, and Y. Matsushita, “Noise suppression in low-light images through joint denoising and demosaicing,” in Proc. CVPR, 2011, pp. 321–328.
[2] J. Chen, C. Tang, and J. Wang, “Noise brush: interactive high quality image-noise separation,” ACM Trans. Graph., vol. 28, no. 5, pp. 146, 2009.
[3] K. Dabov, A. Foi, V. Katkovnik, and K. Egiazarian, “Color image denoising via sparse 3d collaborative filtering with grouping constraint in luminancechrominance space,” in Proc. ICIP, 2007, vol. 1, pp. I–313.
[4] X. Chen, B. Sing, J. Yang, and J. Yu, “Fast patch-based denoising using approximated patch geodesic paths,” in Proc. CVPR, 2013, pp. 1211–1218.
[5] K. Dabov, A. Foi, V. Katkovnik, and K. Egiazarian, “Image denoising by sparse 3-d transform-domain collaborative filtering,” IEEE Trans. on Image Processing, vol. 16, no. 8, pp. 2080–2095, 2007.
[6] E. Balster, Y. Zheng, and R. Ewing, “Combined spatial and temporal domain wavelet shrinkage algorithm for video denoising,” IEEE Trans. on Circuits and Syst. for Video Tech., vol. 16, no. 2, pp. 220–230, 2006.
[7] V. Zlokolica, A. Pizurica, and W. Philips, “Waveletdomain video denoising based on reliability measures,” IEEE Trans. on Circuits and Syst. for Video Tech., vol. 16, no. 8, pp. 993–1007, 2006.
[8] A. Buades, B. Coll, and J. Morel, “A non-local algorithm for image denoising,” in Proc. CVPR, 2005, vol. 2,
pp. 60–65.
[9] A. Buades, B. Coll, and J. Morel, “A review of image denoising algorithms, with a new one,” Multiscale Modeling & Simulation, vol. 4, no. 2, pp. 490–530, 2005.
[10] J. Chen and C. Tang, “Spatio-temporal markov random field for video denoising,” in Proc. CVPR, 2007, pp. 1–8.
[11] N. Kalantari, E. Shechtman, C. Barnes, S. Darabi, D. B Goldman, and P. Sen, “Patch-based high dynamic range video,” ACM Trans. Graph., vol. 32, no. 6, pp. 202, 2013.
[12] M. Granados, K. Kim, J. Tompkin, and C. Theobalt, “Automatic noise modeling for ghost-free hdr reconstruction,” ACM Trans. Graph., vol. 32, no. 6, pp. 201, 2013.
[13] F. Tan, S. Liu, L. Zeng, and B. Zeng, “Kernel-free video deblurring via synthesis,” in Proc. ICIP, 2016, pp. 2683–2687.
[14] S. Liu, L. Yuan, P. Tan, and J. Sun, “Bundled camera paths for video stabilization,” ACM Trans. Graph., vol. 32, no. 4, pp. 78, 2013.
[15] Z. Liu, L. Yuan, X. Tang, M. Uyttendaele, and J. Sun, “Fast burst images denoising,” ACM Trans. Graph., vol. 33, no. 6, pp. 232, 2014.
[16] S. Liu, P. Tan, L. Yuan, J. Sun, and B. Zeng, “Meshflow: Minimum latency online video stabilization,” in Proc. ECCV, 2016, pp. 800–815.
[17] S. Liu, L. Yuan, P. Tan, and J. Sun, “Steadyflow: Spatially smooth optical flow for video stabilization,” in Proc. CVPR, 2014, pp. 4209–4216.
[18] S. Liu, M. Li, S. Zhu, and B. Zeng, “Codingflow: Enable video coding for video stabilization,” IEEE Trans. on Image Processing, vol. 26, no. 7, pp. 3291–3302, 2017.
[19] K. Dabov, A. Foi, and K. Egiazarian, “Video denoising by sparse 3d transform-domain collaborative filtering,” in In Proc. European Signal Process. Conf. EUSIPCO, 2007.
[20] M. Maggioni, V. Katkovnik, K. Egiazarian, and A. Foi, “Nonlocal transform-domain filter for volumetric data denoising and reconstruction,” IEEE Trans. on Image Processing, vol. 22, no. 1, pp. 119–133, 2013.
[21] M. Maggioni, G. Boracchi, A. Foi, and K. Egiazarian, “Video denoising, deblocking, and enhancement through separable 4-d nonlocal spatiotemporal transforms,” IEEE Trans. on Image Processing, vol. 21, no.
9, pp. 3952–3966, 2012.
[22] M. Trajkovic and M. Hedley, “Fast corner detection,” ´ Image and vision computing, vol. 16, no. 2, pp. 75–87, 1998.
[23] J. Shi and C. Tomasi, “Good features to track,” in Proc. CVPR, 1994, pp. 593–600.
[24] H. Guo, S. Liu, T. He, S. Zhu, B. Zeng, and M. Gabbouj, “Joint video stitching and stabilization from moving cameras,” IEEE Trans. on Image Processing, vol. 25, no. 11, pp. 5491–5503, 2016.

