

CBAM: Convolutional Block Attention Module (ECCV 2018 attention)
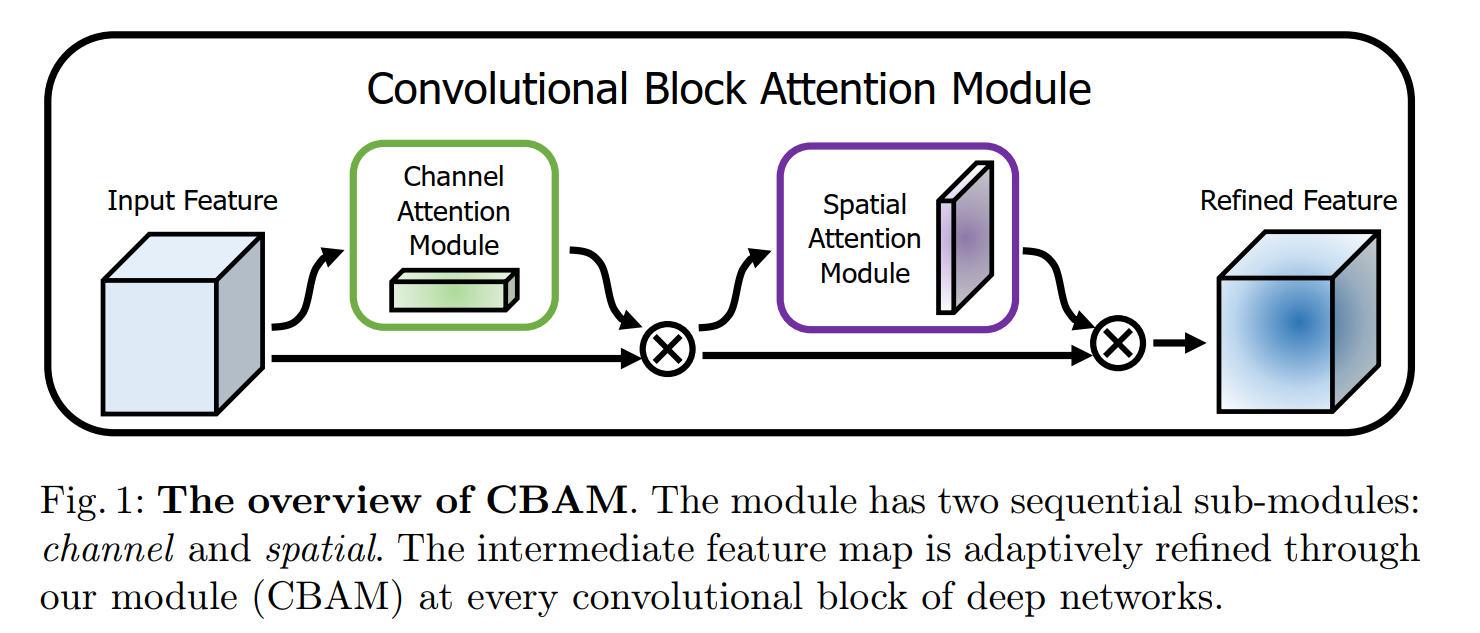
在本文中作者提出了一个轻量、通用的attention 模块(CBAM),可以同时做到通道(Channel Attentation Module)和空间上(Spatial Attention Module)的注意力,其中通道上的注意力主要是增强"what", 而空间上的注意力主要是增强‘where’。下图是CBAM的示意图。
Channel Attention Module
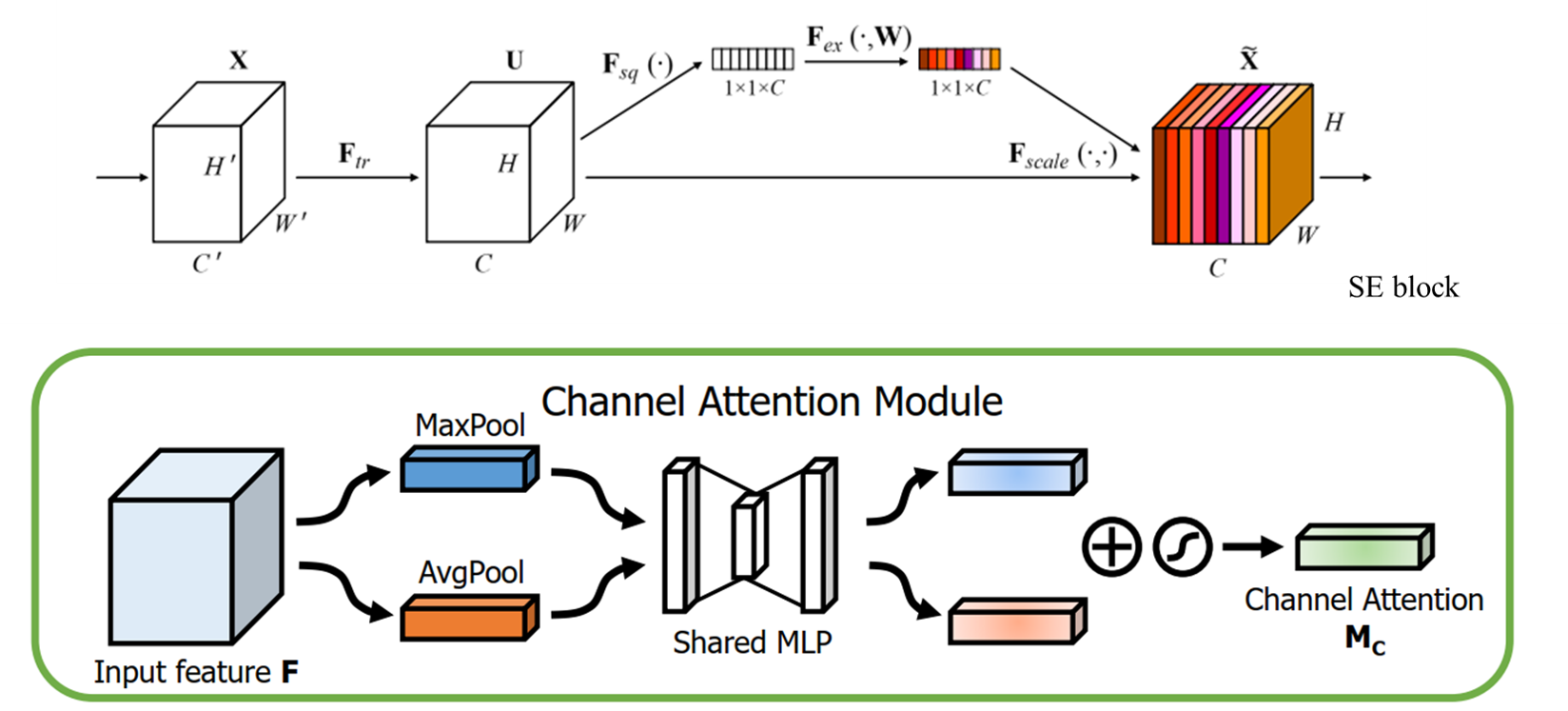
图2 Channel attention module 示意图
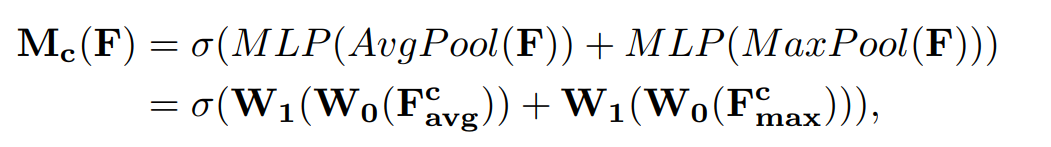
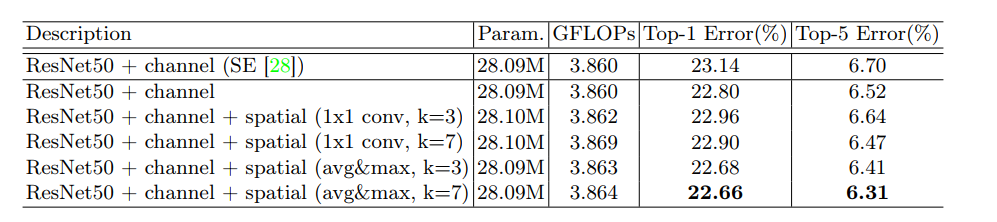
Channel attention module 和 SE block 类似,只是 SE block 只采用了全局平均池化, 而 CAM同时使用了 平局池化和最大池化,这样在一定层度上能降低池化带来的信息丢失(可不可以采用其他的方式来进行信息的统计,),文章中的实验表明同时使用平均池化和最大池化的效果优于单独使用平均池化 (表1)。SE block 的相关信息可以查看博客https://www.cnblogs.com/zhongyong7630/p/12838936.html
表1 不同 Channel attention 之间的对比

Spatial Attention Module
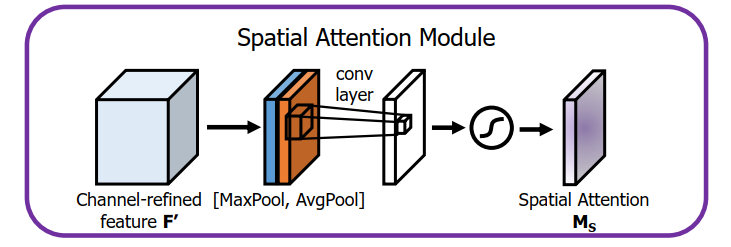
图3 Spatial Attention Module 示意图
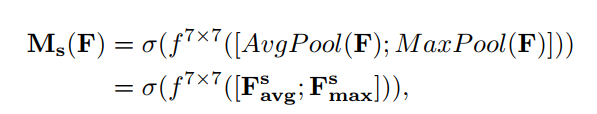
空间特征注意力主要是对位置信息的一种增强,与Channel attention module 策略相似,作者同时采用平均池化和最大池化进行信息的统计(在通道层面进行信息统计, W*H*C 池化后变为 W*H*1, W、H和C分别表示宽度、高度和通道数)。同时采用大卷积(7*7)来提高感受野,以更好地指导信息的提取。文章中的结果表明使用1*1的卷积来进行池化操作的会在一定层度上降低精度,这可能是:1)由于1*1的卷积操作在一定层度上破坏了原有的数据分布信息。
表2 不同 Spatial attention 结果比较
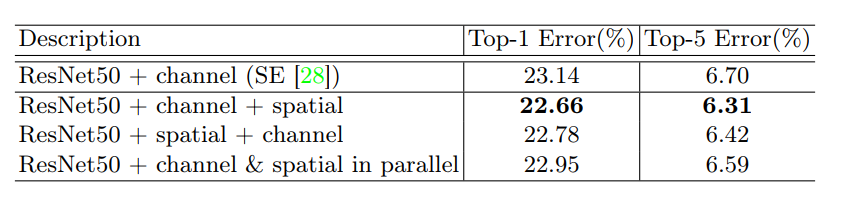
同时在文章中作者还做了 Channel Attention Module 和 Spatial Attention Module 不同的组合策略对实验解雇的影响。实验结果表明:Channel Attention Module---》 Spatial Attention Moduled的组合效果比较好。
表3 不同组合方式对比
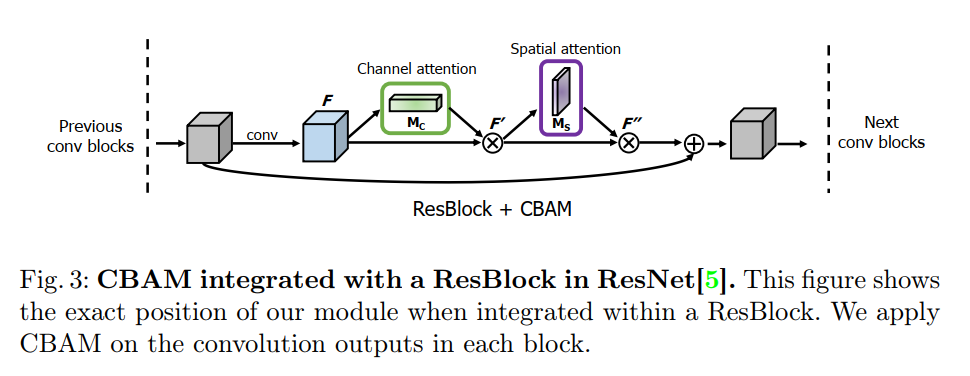
在论文中作者介绍了如何把CBAM 应用到ResNet结构中,如下图所示,CBAM是使用在每个卷积block的输出卷积中(即卷积块的最后一个卷积)。
CBAM 代码Tensorflow 实现:
# batch_size 不用固定
def cbam_module(inputs, reduction_ratio=16, name=""):
with tf.variable_scope("cbam_" + name):
hidden_num = inputs.get_shape().as_list()[-1]
# channel attention module
# max pooling process
maxpool_channel = tf.reduce_max(tf.reduce_max(inputs, axis=1, keepdims=True), axis=2, keepdims=True)
maxpool_channel = tf.layers.Flatten()(maxpool_channel)
# FC-ReLU
mlp_1_max = tf.layers.dense(inputs=maxpool_channel, units=int(hidden_num / reduction_ratio), name="mlp_1",
reuse=None, activation=tf.nn.relu)
# FC
mlp_2_max = tf.layers.dense(inputs=mlp_1_max, units=hidden_num, name="mlp_2", reuse=None)
# mlp_2_max = tf.reshape(mlp_2_max, [batch_size, 1, 1, hidden_num])
mlp_2_max = tf.expand_dims(tf.expand_dims(mlp_2_max, axis=-2), axis=-2)
# average pooling process
avgpool_channel = tf.reduce_mean(tf.reduce_mean(inputs, axis=1, keepdims=True), axis=2, keepdims=True)
avgpool_channel = tf.layers.Flatten()(avgpool_channel)
mlp_1_avg = tf.layers.dense(inputs=avgpool_channel, units=int(hidden_num / reduction_ratio), name="mlp_1",
reuse=True, activation=tf.nn.relu)
mlp_2_avg = tf.layers.dense(inputs=mlp_1_avg, units=hidden_num, name="mlp_2", reuse=True)
mlp_2_avg = tf.expand_dims(tf.expand_dims(mlp_2_avg, axis=-2), axis=-2)
channel_attention = tf.nn.sigmoid(mlp_2_max + mlp_2_avg)
channel_refined_feature = inputs * channel_attention
# spatial attention module
maxpool_spatial = tf.reduce_max(inputs, axis=-1, keepdims=True)
avgpool_spatial = tf.reduce_mean(inputs, axis=-1, keepdims=True)
max_avg_pool_spatial = tf.concat([maxpool_spatial, avgpool_spatial], axis=-1)
conv_layer = tf.layers.conv2d(inputs=max_avg_pool_spatial, filters=1, kernel_size=(7, 7), padding="same",
activation=None)
spatial_attention = tf.nn.sigmoid(conv_layer)
refined_feature = channel_refined_feature * spatial_attention
return refined_feature
论文:CBAM: Convolutional Block Attention Module
Pytorch:https://github.com/luuuyi/CBAM.PyTorch
Tensorflow: https://github.com/kobiso/CBAM-tensorflow
参考博客:
【1】https://blog.csdn.net/qq_14845119/article/details/81393127
【2】https://zhuanlan.zhihu.com/p/73927413

