


python+selenium二:定位方式
# 八种单数定位方式:element
from selenium import webdriver
import time
driver = webdriver.Firefox()
time.sleep(2) # 等待2秒
driver.get('https://www.baidu.com')
1、id定位:find_element_by_id()
# 定位到输入框,输入“中文”
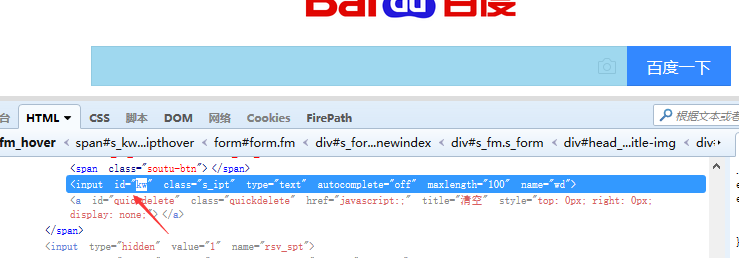
time.sleep(2)
driver.find_element_by_id('kw').send_keys('中文')

2、name定位:find_element_by_name()
# 根据name定位到百度贴吧的输入框,输入“你好”
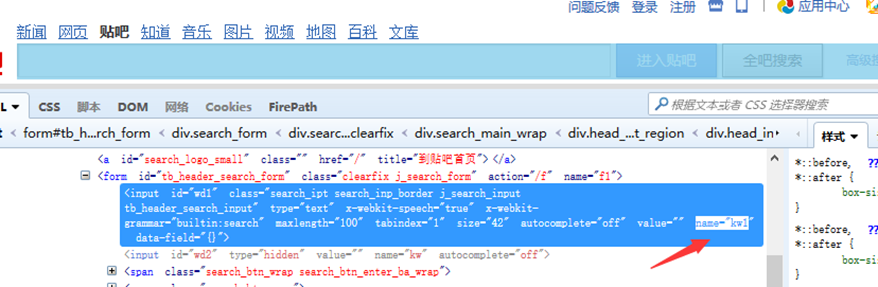
driver.find_element_by_name('kw1').send_keys('你好')

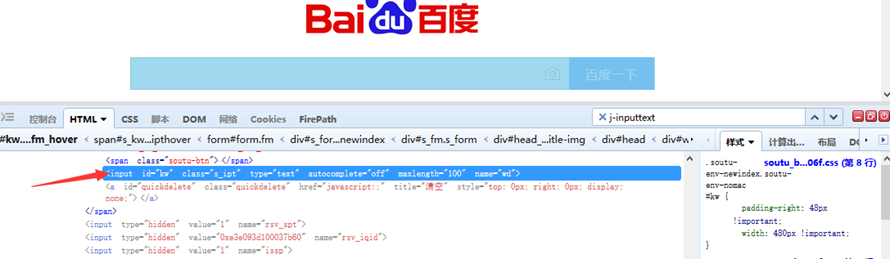
3、class定位:find_element_by_class_name()
# 当class唯一时,才能使用此方法
# 根据class属性找到输入框,输入“你好”

driver.find_element_by_class_name('s_ipt').send_keys('你好')

4、根据标签名定位:find_element_by_tag_name() (由于标签名不唯一,不建议用此方法)
driver.find_element_by_tag_name('body')
# 获取定位元素下的文本信息
t = driver.find_element_by_tag_name('body').text
print(t)

5、link定位(链接):find_element_by_link_text()
# <a class="mnav" name="tj_trnews" href="http://news.baidu.com">新闻</a>
# href="http://news.baidu.com": 一般为link属性
# 根据link的文字内容“新闻”定位到link链接
driver.find_element_by_link_text('新闻').click()
6、partial_link定位
# 当代表link链接的文字内容过长时,可使用此方式截取部分文字定位
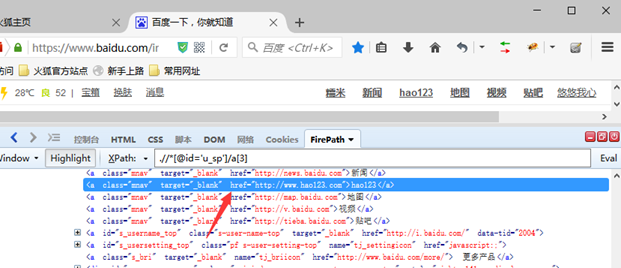
driver.find_element_by_partial_link_text('hao').click()

7、Xpath定位:find_element_by_xpath()
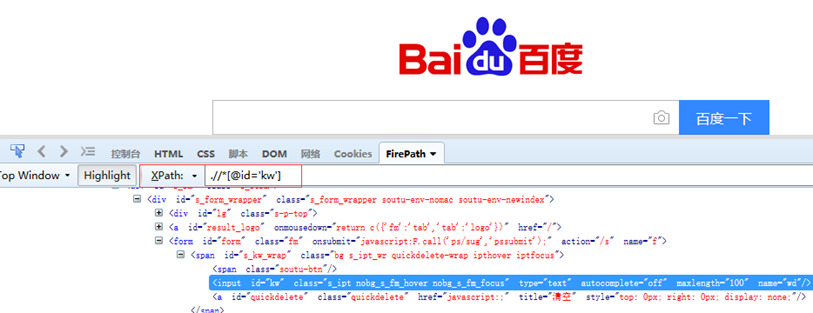
xpath定位:.//*[@class="XXX"]、.//*[@id="XXX"]、.//*[@name="XXX"]、.//input(匹配input标签)、.//*[text()="文字内容"]、.//*[contains(text(),"文字内容")](匹配text属性里面有”文字内容”的所有内容)、
driver.find_element_by_xpath(".//*[@id='u1']/a[3]").click()

8、CSS定位:find_element_by_css_selector()(不唯一)
driver.find_element_by_css_selector("#kw").send_keys("你好")

复数定位方式:elements (对元素不唯一),以id为例:
# 单数定位:
driver.find_element_by_id('kw').send_keys('中文')

# 复数定位:根据找出的元素的下标定位
elements = driver.find_elements_by_id('kw')
print(len(elements)) # 当不清楚定位到几个元素的时候,可以用此方法打印出来筛选
elements[0].send_keys('中文')

# 当class属性有多个的时候,带空格
# 当有多个class属性的时候,此空格并不是空的字符串,而是此class具有多重属性
# class="search_ipt search_inp_border j_search_input tb_header_search_input"
# 贴吧输入框
# 确定其中某一个属性是唯一以后,取此属性即可
driver.find_element_by_class_name("search_ipt").send_keys("你好")


