

测开之路八十五:python处理csv文件
写入csv文件
一:写入字典


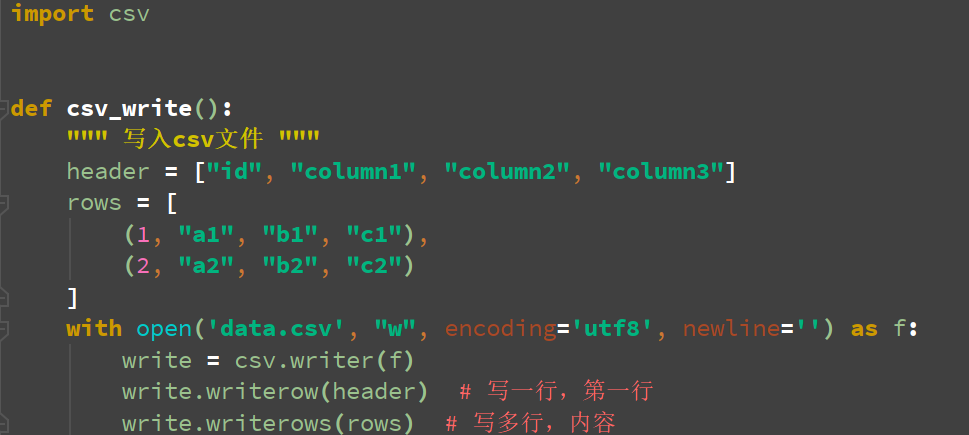
二:写入普通数据
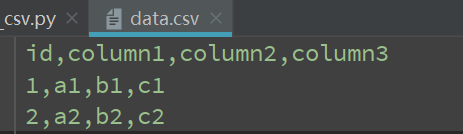
读取:
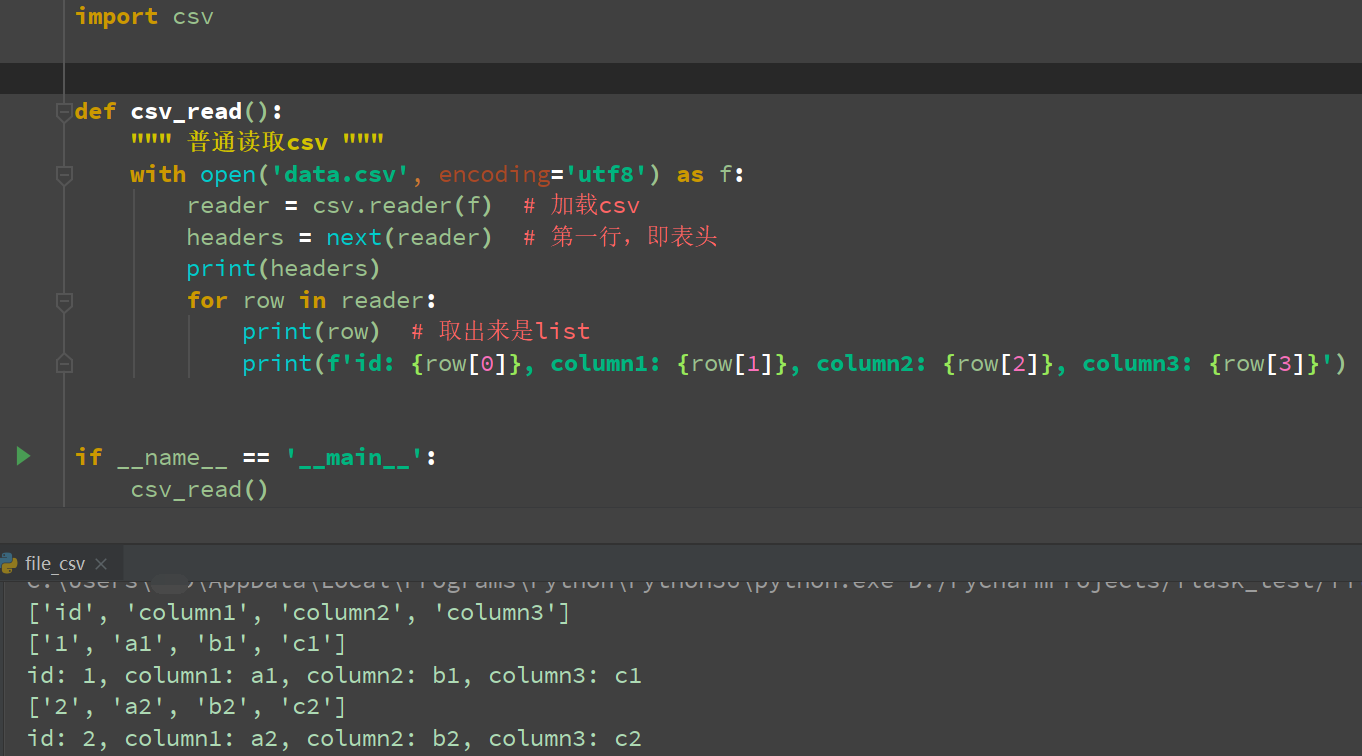
第一种:普通读取
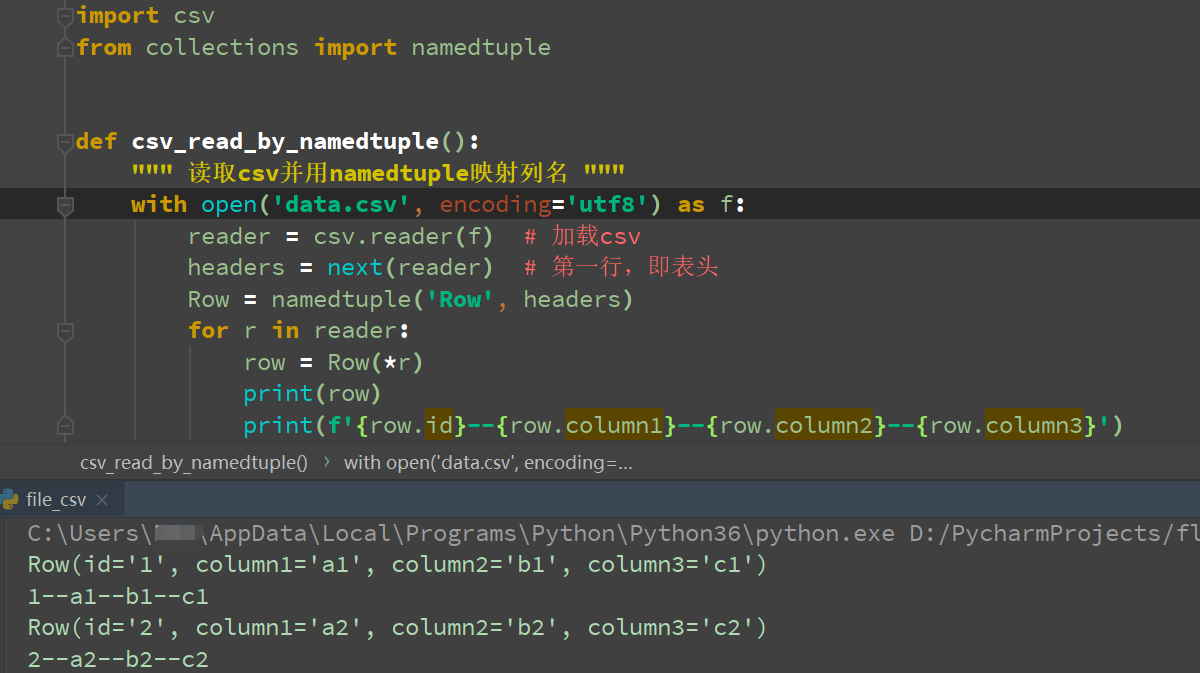
第二种:读取csv并用namedtuple映射列名,类似于使用类的实例
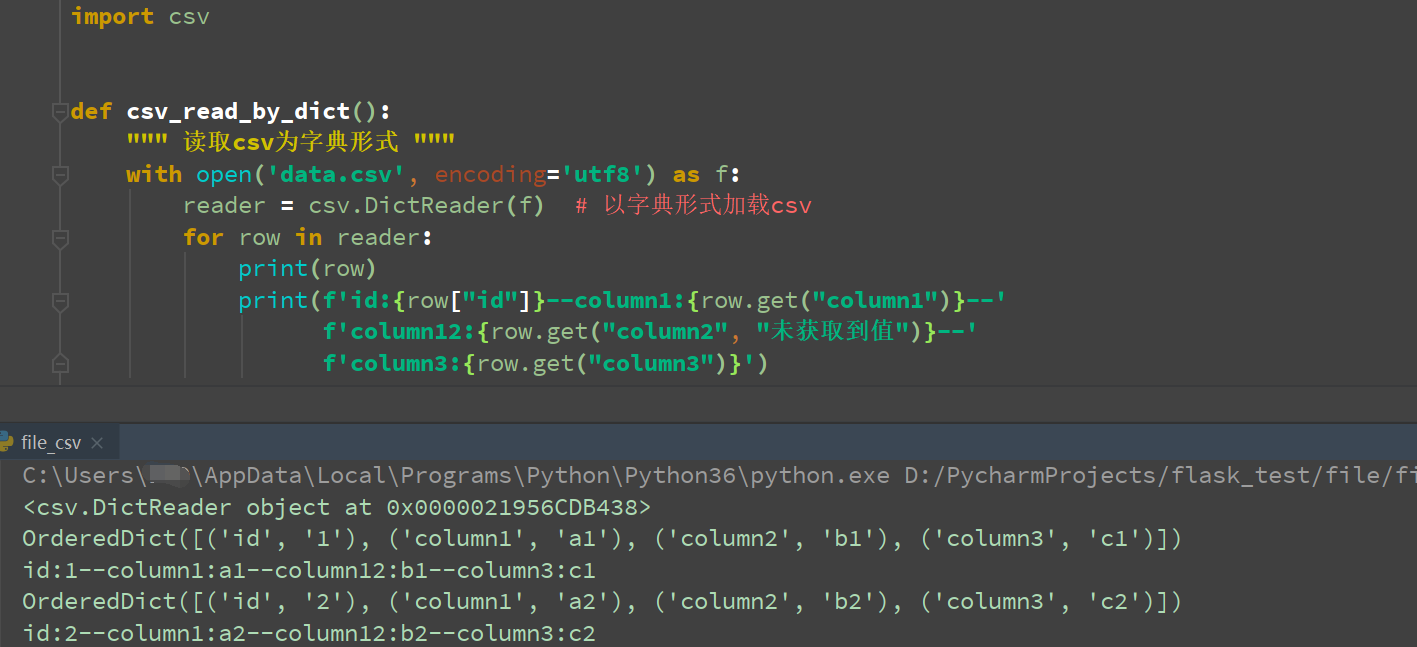
第三种:字典形式
import csv
from collections import namedtuple
def csv_write_dict():
""" 写入字典 """
header = ["_id", "column1", "column2", "column3"]
rows = [
{"_id": 1, "column1": "a1", "column2": "b1", "column3": "c1"},
dict(_id=2, column1="a2", column2="b2", column3="c2")
]
with open("data.csv", "w", encoding="utf8", newline="") as f:
writer = csv.DictWriter(f, header)
writer.writeheader()
writer.writerows(rows)
def csv_write():
""" 写入csv文件 """
header = ["id", "column1", "column2", "column3"]
rows = [
(1, "a1", "b1", "c1"),
(2, "a2", "b2", "c2")
]
with open('data.csv', "w", encoding='utf8', newline='') as f:
write = csv.writer(f)
write.writerow(header) # 写一行,第一行
write.writerows(rows) # 写多行,内容
def csv_read():
""" 普通读取csv """
with open('data.csv', encoding='utf8') as f:
reader = csv.reader(f) # 加载csv
headers = next(reader) # 第一行,即表头
print(headers)
for row in reader:
print(row) # 取出来是list
print(f'id: {row[0]}, column1: {row[1]}, column2: {row[2]}, column3: {row[3]}')
def csv_read_by_namedtuple():
""" 读取csv并用namedtuple映射列名 """
with open('data.csv', encoding='utf8') as f:
reader = csv.reader(f) # 加载csv
headers = next(reader) # 第一行,即表头
Row = namedtuple('Row', headers)
for r in reader:
row = Row(*r)
print(row)
print(f'{row.id}--{row.column1}--{row.column2}--{row.column3}')
def csv_read_by_dict():
""" 读取csv为字典形式 """
with open('data.csv', encoding='utf8') as f:
reader = csv.DictReader(f) # 以字典形式加载csv
for row in reader:
print(row)
print(f'id:{row["id"]}--column1:{row.get("column1")}--'
f'column12:{row.get("column2", "未获取到值")}--'
f'column3:{row.get("column3")}')
if __name__ == '__main__':
csv_write()
csv_write_dict()
csv_read()
csv_read_by_namedtuple()
csv_read_by_dict()
讨论群:249728408
