


性能测试四十一:sql案例之慢sql配置、执行计划和索引
MYSQL 慢查询使用方法
MYSQL慢查询介绍
分析MySQL语句查询性能的问题时候,可以在MySQL记录中查询超过指定时间的语句,我们将超过指定时间的SQL语句查询称为“慢查询”。MYSQL自带的慢查询分析工具mysqldumpslow可对慢查询日志进行分析:主要功能是, 统计sql的执行信息,其中包括 :
出现次数(Count),
执行最长时间(Time),
累计总耗费时间(Time),
等待锁的时间(Lock),
发送给客户端的行总数(Rows),
扫描的行总数(Rows),
用户以及sql语句本身(抽象了一下格式, 比如 limit 1, 20 用 limit N,N 表示).
案例:慢sql
先确定项目指向的数据库是对的

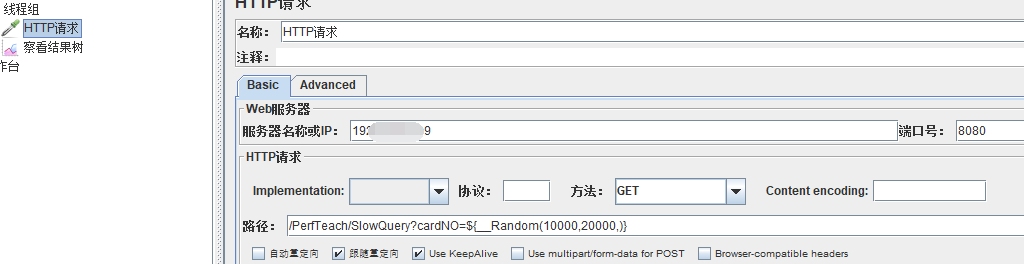
问题接口:http://localhost:8080/PerfTeach/SlowQuery?cardNO=10001
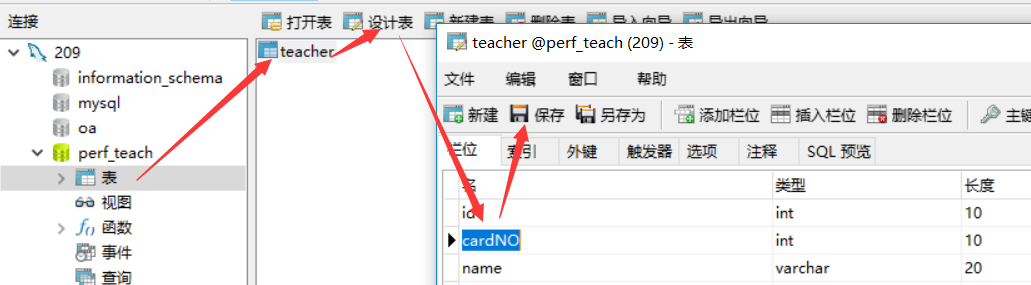
由于数据库里面是card_no,而代码里面是cardNO,所以要改一下数据库里面的字段名

修改
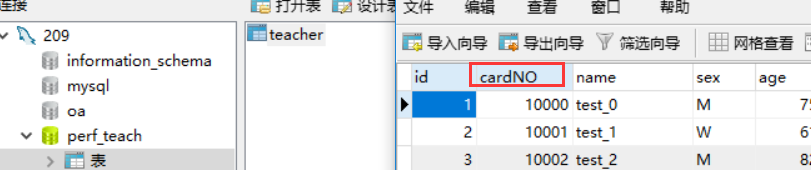
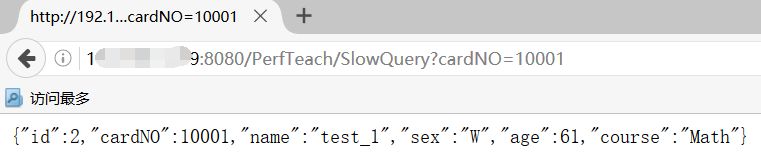
访问一下:http://localhost:8080/PerfTeach/SlowQuery?cardNO=10001,和数据库里的一样
在jmeter里面造一个10000--20000的随机数函数

监控开起来
运行jmeter,用10个并发,跑600秒
TPS很低
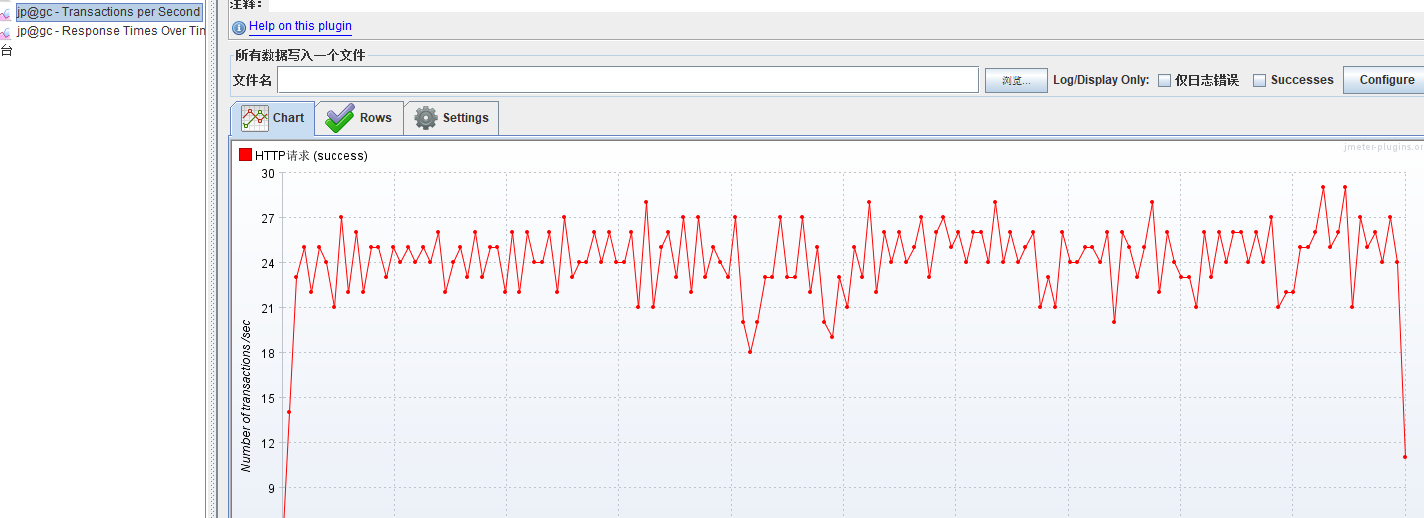
响应时间很长

CPU高

mysql进程占了89.9%的cpu使用率
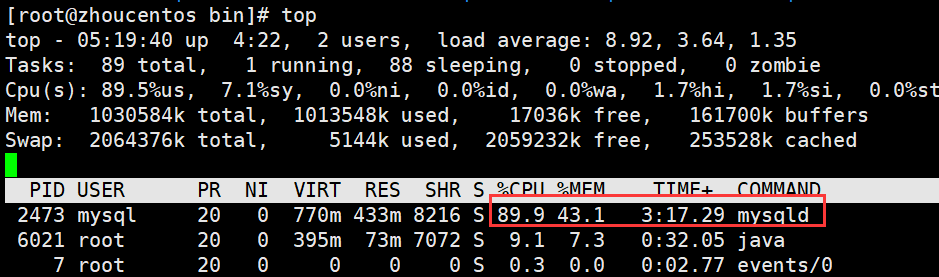
所以,可以确定是mysql这块有问题,而这种问题一般都是sql写的不好造成的
1、 开启慢SQL的配置
1.1 LIUNX 系统 在mysql配置文件my.cnf中(文件最后)增加
slow_query_log:这是一个布尔型变量,默认为真。没有这变量,数据库不会打印慢查询的日志。
slow_query_log_file=/usr/local/mysql/data/zhoucentos-slow.log:(指定日志文件存放位置(安装mysql的目录),可以为空,系统会给一个缺省的文件hostName-slow.log)
long_query_time=0.1:(记录超过的时间,默认为10s),与DBA沟通,性能测试分析问题时可以将该值设为0.1即100毫秒,这样分析的粒度更详细。
备选 :log-queries-not-using-indexes (log下来没有使用索引的query,可以根据情况决定是否开启)。log-long-format (如果设置了,所有没有使用索引的查询也将被记录)


重启mysql

1.2 Windows下配置:
在my.ini的[mysqld]添加如下语句:
log-slow-queries = E:\web\mysql\log\mysqlslowquery.log
long_query_time = 0.1(其他参数如上)
注: 配置完成后,重新mysql服务配置才能生效。
2、 慢查询开启与关闭
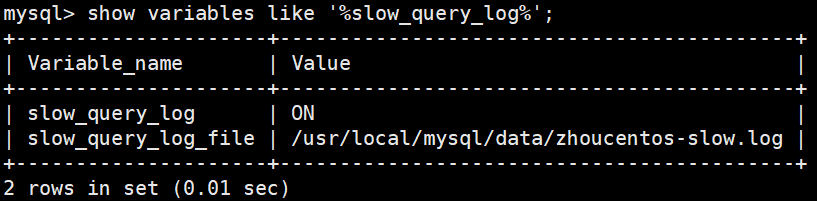
2.1 配置完成,连接数据库检查慢查询日志是否开启:
命令如下:mysql> show variables like '%slow_query_log%';


压一下,看看有没有数据写进去,从172,变成了124800,使用-h查看:122K


2.2 如果没有打开,请开启,slow_query_log,以下方法是一次性的,只要重启mysql就会恢复到原样
开启命令:mysql> set @@global.slow_query_log = on;
关闭命令:mysql> set @@global.slow_query_log = off;
2.3 再次检查是否开启成功
mysql> show variables like '%slow_query_log%';
2.4 检查目录中是否生成文件
/mysql目录下是否存在mysql_slow.log
[root@localhost mysql]# ls -l mysql_slow.log
3、 慢查询日志分析
3.1 Linux系统:
使用mysql自带命令mysqldumpslow查看(需在mysql/bin目录下执行,因为mysqldumpslow在bin目录下)
常用命令,通过 ./mysqldumpslow -help查看
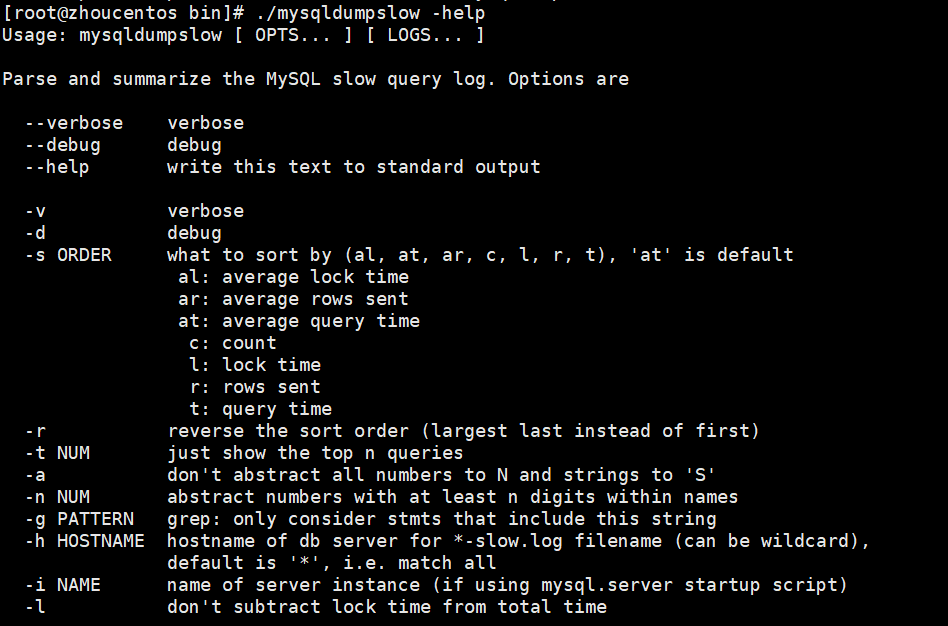
-s,是order的排序,主要有 c,t,l,r和ac,at,al,ar,分别是按照query次数,时间,lock的时间和返回的记录数来排序
-a,倒序排列
-t,是top n的意思,即为返回前面多少条的数据
-g,后边可以写一个正则匹配模式,大小写不敏感的
例如:
./mysqldumpslow -s c -t 20 host-slow.log:访问次数最多的20个sql语句

./mysqldumpslow -s r -t 20 host-slow.log:返回记录集最多的20个sql

./mysqldumpslow -t 10 -s t -g “left join” host-slow.log这个是按照时间返回前10条里面含有左连接的sql语句。
./mysqldumpslow -s at -t 50 host-slow.log 显示出耗时最长的50个SQL语句的执行信息(此方法最常用)
总共执行了602次,平均执行390毫秒,和jmeter统计出来的平均响应时间差不多了,所以,时间都耗在执行sql上面了

由于这里数据量不够,所以找了个项目中的图
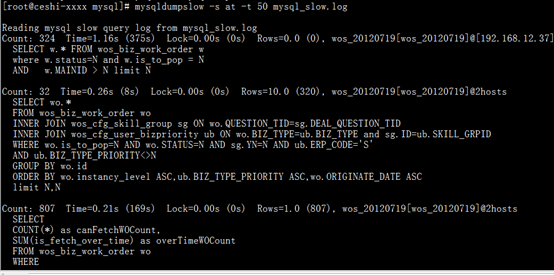
以Count: 32 Time=0.26s (8s) Lock=0.00s (0s) Rows=10.0 (320), wos_20120719[wos_20120719]@2host 为例:
Count: 32 该SQL总共执行32次
Time = 0.26s (8s) 平均每次执行该SQL耗时0.26秒,总共耗时32(次)*0.26(秒)=8秒。
Lock=0.00s(0s) lock时间0秒
Rows =10.0(320) 每次执行SQL影响数据库表中的10行记录,总共影响 10(行)*32(次)=320行记录
执行计划
在sql语句前加上explain,可以分析这条sql语句的执行情况:explain select * from teacher where cardNO=10000

select_type:
SIMPLE:简单查询
Type列可能的值(以下按效率降序排列):
Const:表中只有一个匹配行,用到primary key或unique key (性能最好)


Eq_ref:唯一性索引扫描,key的所有部分被连接联接查询使用,且key是unique或primary key
ref:非唯一性索引扫描,或只使用了联合索引的最左前缀
Range:索引范围扫描,在索引列上进行给定范围内的检索,如between,in(1,100)
Index:遍历索引...(类似于在字典上找字)
All:全表扫描(没有用索引,直接从表里面第一条找到最后一条(即使在前面或中间已经找到数据),所以项目中一般禁止使用select*和全表扫描)
所以上面就运行那条简单的sql,确很费cpu,就是因为在进行全表扫描
在工作中,一般有以下3种情况会造成sql效率低:
1.库里面没有加索引
2.加了索引,但是索引加的不合理
3.索引加的合理,但是sql写的不合理
一般,一个表里面,最多加3/4个索引,不能再多,否则就是表设计的不合理
上面那个情况就是应为没有加索引,所以,加个索引看看,
一般加索引,就看where条件的字段,用这些字段来当索引,这条sql就一个字段:cardNO

压一下看看
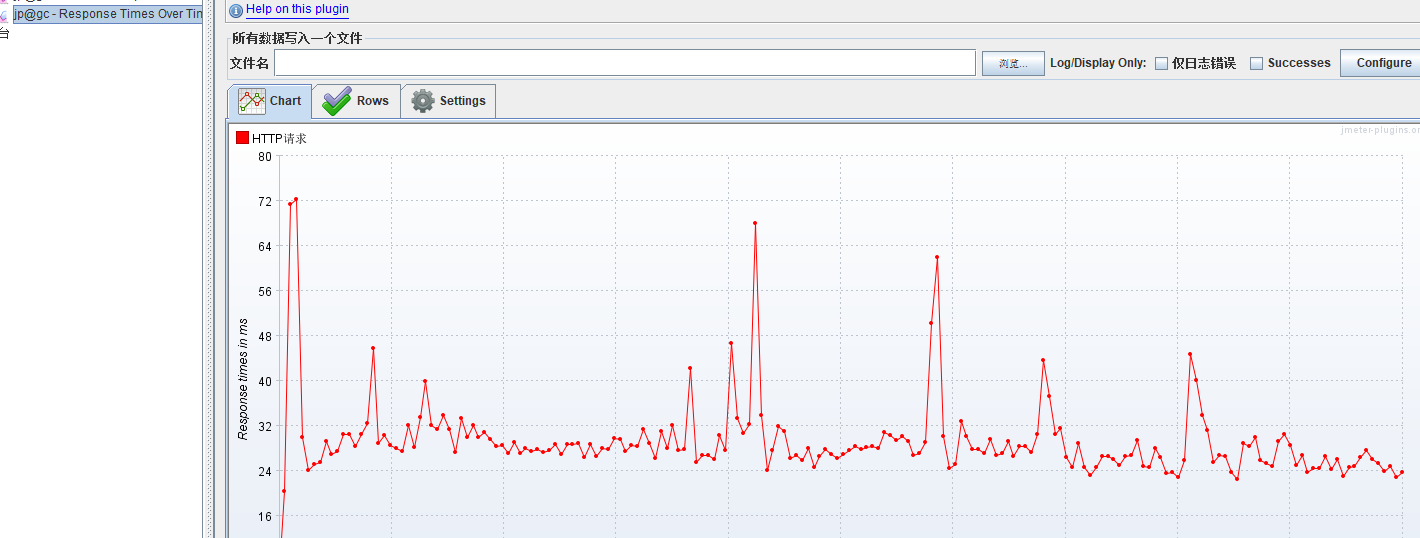
TPS从刚才的20多变成了300多,提升了15倍左右
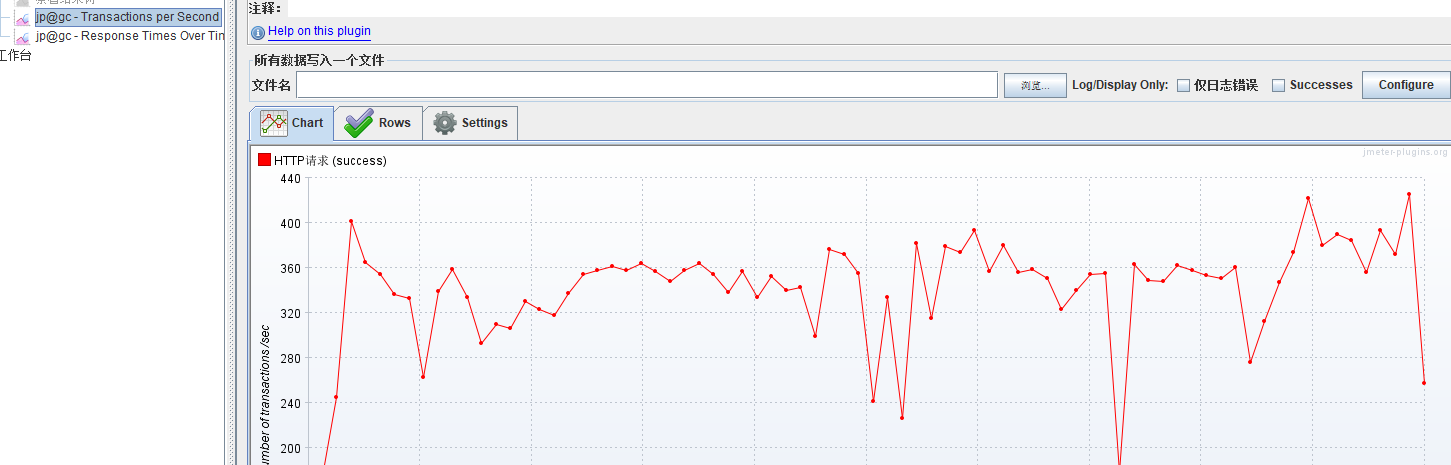
响应时间:从刚才的400左右,降到30左右
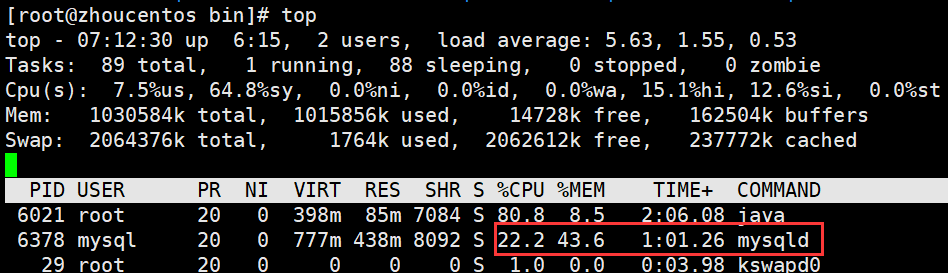
TOP命令查看,mysql只占了22.2%,一般项目中就应该是tomcat占比最高,应为它要处理业务逻辑
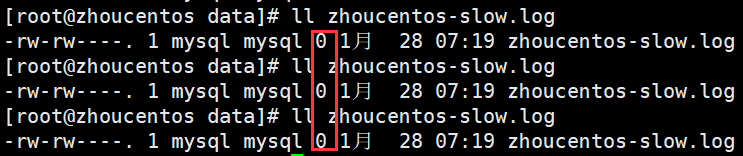
由于压测还在进行中,所以可以把慢查询的日志清空后再看看还有没有慢查询

文件大小都是0了,没有往文件里面写入内容了
3.2 Windows系统:
当你是第一次开启mysql的慢查询,会在你指定的目录下创建这个记录文件,本文就是mysqlslowquery.log,这个文件的内容大致如下(第一次开启MYSQL慢查询的情况下)
E:\web\mysql\bin\mysqld, Version: 5.4.3-beta-community-log (MySQL Community Server (GPL)). started with:
TCP Port: 3306, Named Pipe: (null)
Time Id Command Argument
可以通过如下的命令来查看慢查询的记录数:
mysql> show global status like ‘%slow%’;
+———————+——-+
| Variable_name | Value |
+———————+——-+
| Slow_launch_threads | 0 |
| Slow_queries | 0 |
+———————+——-+

