05 RDD编程
1.读文本文件生成RDD lines
lines = sc.textFile('file:///home/hadoop/word.txt')
lines.collect()

2.将一行一行的文本分割成单词 words
words=lines.flatMap(lambda line:line.split())
words.collect()

3.全部转换为小写
words=lines.flatMap(lambda line:line.lower().split())
words.collect()

4.去掉长度小于3的单词
words=lines.flatMap(lambda line:line.split()).filter(lambda line:len(line)>3)
words.collect()

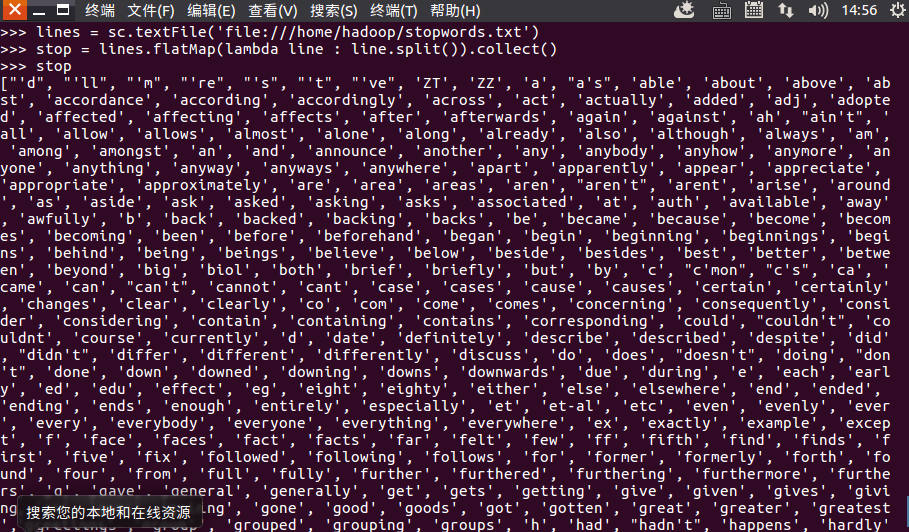
5.去掉停用词
1.准备停用词文本:
lines = sc.textFile('file:///home/hadoop/stopwords.txt')
stop = lines.flatMap(lambda line : line.split()).collect()
stop
2.去除停用词:
lines=sc.textFile("file:///home/hadoop/word.txt")
words=lines.flatMap(lambda line:line.lower().split()).filter(lambda word:word not in stop)
words
words.collect()

6.转换成键值对 map()
wordskv=words.map(lambda word:(word.lower(),1))
wordskv.collect()

7.统计词频 reduceByKey()
wordskv.reduceByKey(lambda a,b:a+b).collect()

8、按字母顺序排序 sortBy(f)
wordskv=words.map(lambda word:(word.lower(),1)).reduceByKey(lambda a,b:a+b).sortBy(lambda word:word[0])
wordskv.collect()

9、按词频排序 sortByKey()
wordskv=words.map(lambda word:(word.lower(),1)).reduceByKey(lambda a,b:a+b)
wordskv.sortByKey().collect()

10、结果文件保存 saveAsTextFile(out_url)
courseSave=lines.map(lambda word : (word,1)).reduceByKey(lambda a,b:a+b)tByKey()
courseSave.collect()


我的pyecharts版本是1.9.0,而pyecharts1.0以上必须是python3.6以上版本才能使用,所以在unbuntu系统中升级python版本号就行了,注意一定不要删除默认的python2.7或python3.5版本,只是升级。如果你在外面下载python3.6以上版本,然后上传到unbuntu上,可能会导致pyspark不能使用方向键。因为pyskaprk不支持python3.6以上版本。本人试过在外面下载python3.6的方法,然而到pyspark里面不能使用方向键,也不能使用pyecharts。
升级python3.6教程:
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt-get update
sudo apt install python3.6
这时候已经安装好python3.6了,不过使用python3还会显示python3.5,是因为没有删除python3到python3.5的软连接。
cd /usr/bin/
删除python3
sudo rm python3
建立python3->python3.6的软连接
sudo ln -s python3.6 python3
到这里就可以使用python3.6了,然后pip安装pyecharts
pip3 install pyecharts
升级python3.6操作参考该链接https://blog.csdn.net/weixin_42581401/article/details/106671897
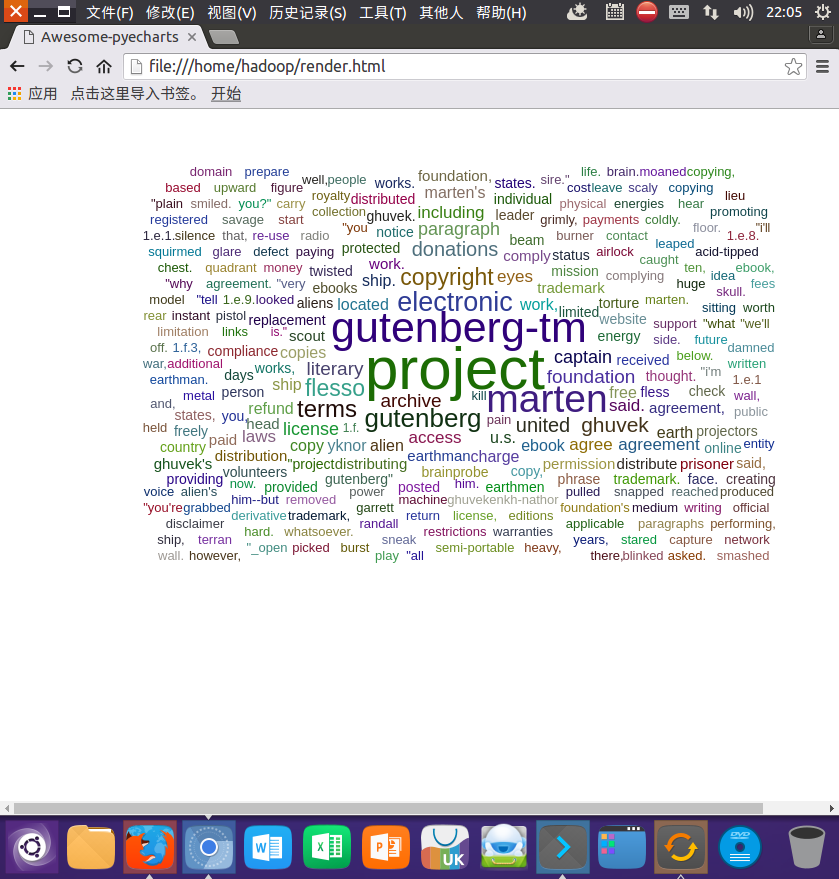
词频结果可视化 pyecharts.charts.WordCloud()
from pyecharts.charts import WordCloud
wc=words1.sortBy(lambda x : x[1],False).collect()
WordCloud().add("",wc,shape='triangle').render()

比较不同框架下(Python、MapReduce、Hive和Spark),实现词频统计思想与技术上的不同,各有什么优缺点.
python的优点:环境容易搭建
python的缺点:不能处理太大的数据
MapReduce的 优点:易于编程,有良好的扩展性和高容错性,适合PB级以上海量数据的离线处理
MapReduce 的缺点:不擅长实时计算,不擅长流式计算等
hive的优点:简单容易上手,可扩展,提供统一的元数据管理,延展性
hive的缺点:hive的HQL表达能力有限,hive的效率比较低,hive可控性差
Spark的优点:Spark可以直接对HDFS进行数据读写,支持YARN等部署模式,spark计算处理数据速度快
Spark的缺点:稳定性差,不能支持复杂的SQL统计
二、学生课程分数案例
- 总共有多少学生?map(), distinct(), count()
- lines.map(lambda line : line.split(',')[0]).distinct().count()

- 开设了多少门课程?
-
lines.map(lambda line : line.split(',')[1]).distinct().count()

- 每个学生选修了多少门课?map(), countByKey()
- lines.map(lambda line : line.split(',')).map(lambda line:(line[0],(line[1],line[2]))).countByKey()

- 每门课程有多少个学生选?map(), countByValue()
- lines.map(lambda line : line.split(',')).map(lambda line : (line[1])).countByValue()

- Allen选修了几门课?每门课多少分?filter(), map() RDD
- lines.filter(lambda line:"Allen" in line).map(lambda line:line.split(',')).collect()

- Allen选修了几门课?每门课多少分?map(),lookup() list
- lines.map(lambda line:line.split(',')).map(lambda line:(line[0],(line[1],line[2]))).lookup("Allen")

- Allen的成绩按分数大小排序。filter(), map(), sortBy()
- lines.filter(lambda line:"Allen" in line).map(lambda line:line.split(',')).sortBy(lambda line:(line[2])).collect()

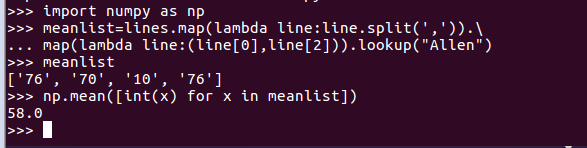
- Allen的平均分。map(),lookup(),mean()
-
import numpy as np
- meanlist=lines.map(lambda line:line.split(',')).map(lambda line:(line[0],line[2])).lookup("Allen")
-
np.mean([int(x) for x in meanlist])
-
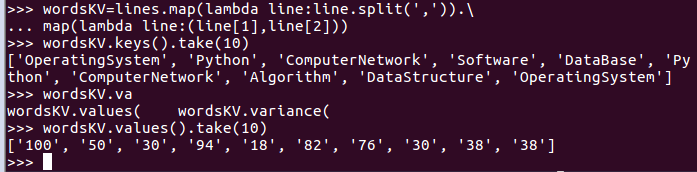
- 生成(课程,分数)RDD,观察keys(),values()
- wordsKV=lines.map(lambda line:line.split(',')).map(lambda line:(line[1],line[2]))
- wordsKV.keys().take(10)
- wordsKV.values().take(10)
- 每个分数+5分。mapValues(func)
- wordsKV.map(lambda x:(x[0],int(x[1]))).mapValues(lambda x:x+5).take(20)

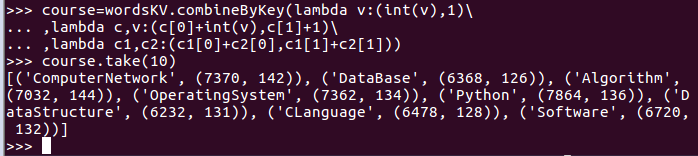
- 求每门课的选修人数及所有人的总分。combineByKey()
- course=wordsKV.combineByKey(lambda v:(int(v),1),lambda c,v:(c[0]+int(v),c[1]+1),lambda c1,c2:(c1[0]+c2[0],c1[1]+c2[1]))
- course.take(10)
- v:sore(分数)
- c[1]+1:表示某一区当前的(选修人数)遇到第一个(选修人数)相加的结果
- c[0]+int(v):表示某一区当前的(分数)遇到第一个分数相加的结果
- c1[0]+c2[0]:表示累加两个区的分数相加之和的结果
- c1[1]+c2[1]:表示累加两个区的(选修人数)相加之和的结果
- 求每门课的选修人数及平均分,精确到2位小数。map(),round()
- course.map(lambda x:(x[0],x[1][1],round(x[1][0]/x[1][1]))).take(10)

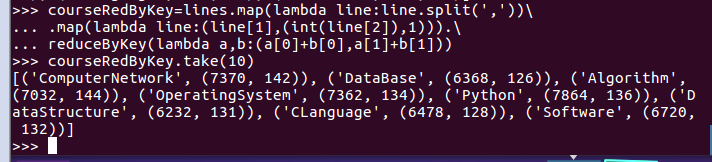
- 求每门课的选修人数及平均分。用reduceByKey()实现,并比较与combineByKey()的异同。
- courseRedByKey=lines.map(lambda line:line.split(',')).map(lambda line:(line[1],(int(line[2]),1))).reduceByKey(lambda a,b:(a[0]+b[0],a[1]+b[1]))
- courseRedByKey.take(10)
不同点:reduceByKey()操作简单通俗易懂,而combineByKey()操作复杂难懂,combineByKey()属于一个比较底层的算子。
- 相同点:reduceByKey()的底层调用了combineByKey()来实现。
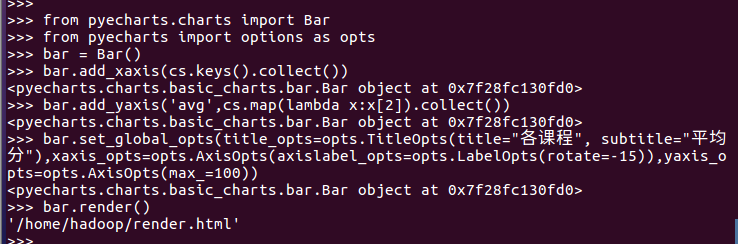
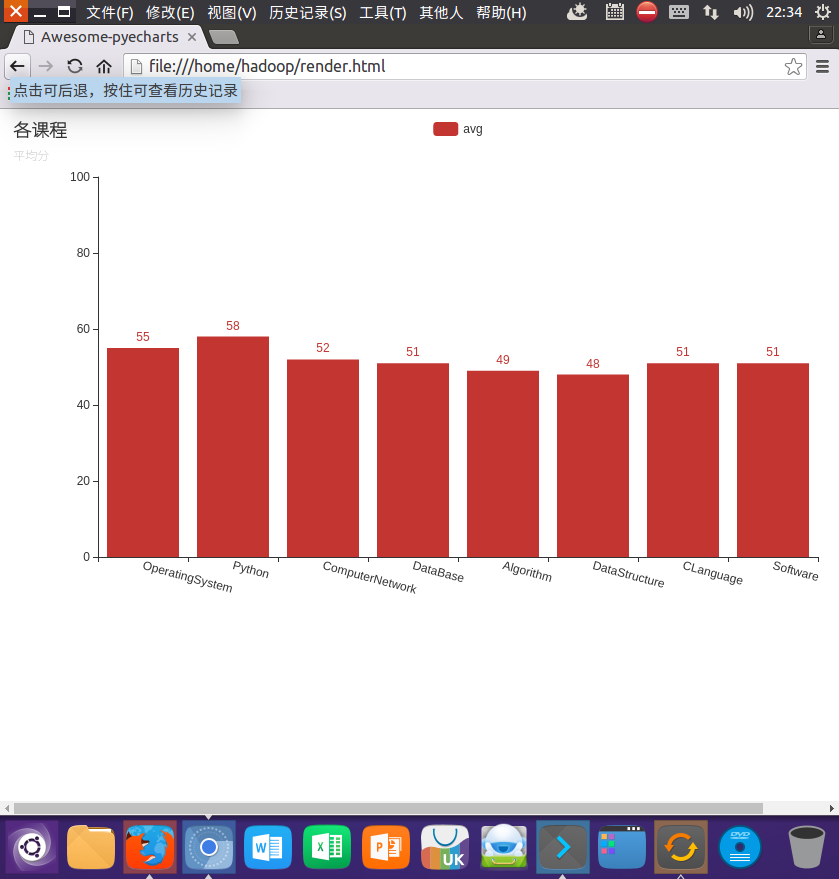
结果可视化。 pyecharts.charts,Bar()
import pyecharts.options as opts from pyecharts.charts import Bar
bar = Bar()
bar.add_xaxis(cs.keys().collect())
bar.add_yaxis('avg',cs.map(lambda x:x[2]).collect())
bar.set_global_opts(title_opts=opts.TitleOpts(title="各课程", subtitle="平均分"),xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),yaxis_opts=opts.AxisOpts(max_=100))
bar.render()