Hadoop演进与Hadoop生态
1.了解对比Hadoop不同版本的特性,可以用图表的形式呈现。
|
发行版本 |
功能特点 |
|
DKhadoop发行版 |
DKhadoop发行版:有效的集成了整个HADOOP生态系统的全部组件,并深度优化,重新编译为一个完整的更高性能的大数据通用计算平台,实现了各部件的有机协调。因此DKH相比开源的大数据平台,在计算性能上有了高达5倍(最大)的性能提升。DKhadoop将复杂的大数据集群配置简化至三种节点(主节点、管理节点、计算节点),极大的简化了集群的管理运维,增强了集群的高可用性、高可维护性、高稳定性。 |
|
cloudera发行版 |
Cloudera发行版:CDH是Cloudera的hadoop发行版,完全开源,比Apache hadoop在兼容性,安全性,稳定性上有增强。 |
|
hortonworks发行版 |
€Hortonworks发行版:Hortonworks 的主打产品是Hortonworks Data Platform (HDP),也同样是100%开源的产品,其版本特点:HDP包括稳定版本的Apache Hadoop的所有关键组件;安装方便,HDP包括一个现代化的,直观的用户界面的安装和配置工具 |
|
MAPR发行版 |
MAPR发行版:mapR有免费和商业两个版本,免费版本在功能上有所减少 |
|
华为hadoop发行版 |
华为hadoop发行版:华为的hadoop版本基于自研的Hadoop HA平台,构建NameNode、JobTracker、HiveServer的HA功能,进程故障后系统自动Failover,无需人工干预,这个也是对hadoop的小修补,远不如mapR解决的彻底 |
2.Hadoop生态的组成、每个组件的作用、组件之间的相互关系,以图例加文字描述呈现。
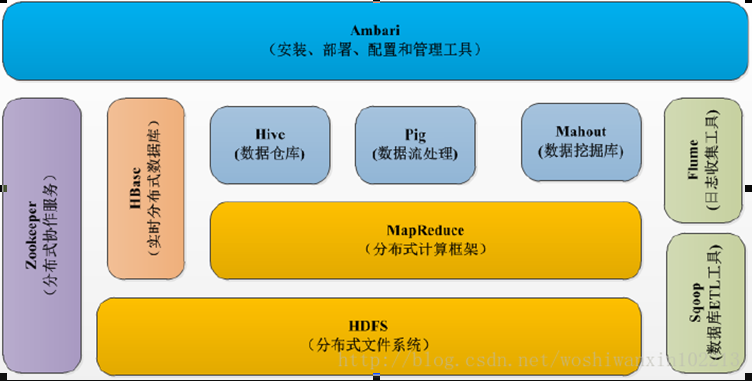
HDFS(Hadoop分布式文件系统)
源自于Google的GFS论文,发表于2003年10月,HDFS是GFS克隆版。
是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
HDFS这一部分主要有一下几个部分组成:
(1)、Client:切分文件;访问HDFS;与NameNode交互,获取文件位置信息;与DataNode交互,读取和写入数据。
(2)、NameNode:Master节点,在hadoop1.X中只有一个,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户端请求。对于大型的集群来讲,Hadoop1.x存在两个最大的缺陷:1)对于大型的集群,namenode的内存成为瓶颈,namenode的扩展性的问题;2)namenode的单点故障问题。
针对以上的两个缺陷,Hadoop2.x以后分别对这两个问题进行了解决。对于缺陷1)提出了Federation namenode来解决,该方案主要是通过多个namenode来实现多个命名空间来实现namenode的横向扩张。从而减轻单个namenode内存问题。
针对缺陷2),hadoop2.X提出了实现两个namenode实现热备HA的方案来解决。其中一个是处于standby状态,一个处于active状态。
(3)、DataNode:Slave节点,存储实际的数据,汇报存储信息给NameNode。
(4)、Secondary NameNode:辅助NameNode,分担其工作量;定期合并fsimage和edits,推送给NameNode;紧急情况下,可辅助恢复NameNode,但Secondary NameNode并非NameNode的热备。
目前,在硬盘不坏的情况,我们可以通过secondarynamenode来实现namenode的恢复。
Mapreduce(分布式计算框架)
源自于google的MapReduce论文,发表于2004年12月,Hadoop MapReduce是google MapReduce 克隆版。MapReduce是一种计算模型,用以进行大数据量的计算。其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce这样的功能划分,非常适合在大量计算机组成的分布式并行环境里进行数据处理。
MapReduce计算框架发展到现在有两个版本的MapReduce的API,针对MR1主要组件有以下几个部分组成:
(1)、JobTracker:Master节点,只有一个,主要任务是资源的分配和作业的调度及监督管理,管理所有作业,作业/任务的监控、错误处理等;将任务分解成一系列任务,并分派给TaskTracker。
(2)、TaskTracker:Slave节点,运行Map Task和Reduce Task;并与JobTracker交互,汇报任务状态。
(3)、Map Task:解析每条数据记录,传递给用户编写的map(),并执行,将输出结果写入本地磁盘。
(4)、Reducer Task:从Map Task的执行结果中,远程读取输入数据,对数据进行排序,将数据按照分组传递给用户编写的reduce函数执行。
在这个过程中,有一个shuffle过程,对于该过程是理解MapReduce计算框架是关键。该过程包含map函数输出结果到reduce函数输入这一个中间过程中所有的操作,称之为shuffle过程。在这个过程中,可以分为map端和reduce端。
Map端:
1) 输入数据进行分片之后,分片的大小跟原始的文件大小、文件块的大小有关。每一个分片对应的一个map任务。
2) map任务在执行的过程中,会将结果存放到内存当中,当内存占用达到一定的阈值(这个阈值是可以设置的)时,map会将中间的结果写入到本地磁盘上,形成临时文件这个过程叫做溢写。
3) map在溢写的过程中,会根据指定reduce任务个数分别写到对应的分区当中,这就是partition过程。每一个分区对应的是一个reduce任务。并且在写的过程中,进行相应的排序。在溢写的过程中还可以设置conbiner过程,该过程跟reduce产生的结果应该是一致的,因此该过程应用存在一定的限制,需要慎用。
4) 每一个map端最后都只存在一个临时文件作为reduce的输入,因此会对中间溢写到磁盘的多个临时文件进行合并Merge操作。最后形成一个内部分区的一个临时文件。
Reduce端:
1) 首先要实现数据本地化,需要将远程节点上的map输出复制到本地。
2) Merge过程,这个合并过程主要是对不同的节点上的map输出结果进行合并。
3) 不断的复制和合并之后,最终形成一个输入文件。Reduce将最终的计算结果存放在HDFS上。
针对MR2是新一代的MR的API。其主要是运行在Yarn的资源管理框架上。
Yarn(资源管理框架)
该框架是hadoop2.x以后对hadoop1.x之前JobTracker和TaskTracker模型的优化,而产生出来的,将JobTracker的资源分配和作业调度及监督分开。该框架主要有ResourceManager,Applicationmatser,nodemanager。其主要工作过程如下:其ResourceManager主要负责所有的应用程序的资源分配,ApplicationMaster主要负责每个作业的任务调度,也就是说每一个作业对应一个ApplicationMaster。Nodemanager是接收Resourcemanager 和ApplicationMaster的命令来实现资源的分配执行体。
ResourceManager在接收到client的作业提交请求之后,会分配一个Conbiner,这里需要说明一下的是Resoucemanager分配资源是以Conbiner为单位分配的。第一个被分配的Conbiner会启动Applicationmaster,它主要负责作业的调度。Applicationmanager启动之后则会直接跟NodeManager通信。
在YARN中,资源管理由ResourceManager和NodeManager共同完成,其中,ResourceManager中的调度器负责资源的分配,而NodeManager则负责资源的供给和隔离。ResourceManager将某个NodeManager上资源分配给任务(这就是所谓的“资源调度”)后,NodeManager需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础的保证,这就是所谓的资源隔离。
在Yarn平台上可以运行多个计算框架,如:MR,Tez,Storm,Spark等计算,框架。
3.官网学习Hadoop的安装与使用,用文档的方式列出步骤与注意事项。
简述hadoop安装
1)使用 root 账户登录
2)修改 IP
3)修改 host 主机名
4)配置 SSH 免密码登录
5)关闭防火墙
6)安装 JDK
7)解压 hadoop 安装包
8)配置 hadoop 的核心文件 hadoop-env.sh,core-site.xml , mapred-site.xml ,
hdfs-site.xml
9)配置 hadoop 环境变量
10)格式化 hadoop namenode-format
11)启动节点 start-all.sh
详细安装参考:https://cloud.tencent.com/developer/article/1456434、https://www.jianshu.com/p/96486ac810ed
4.评估华为hadoop发行版本的特点与可用性。
华为Hadoop组件中的6大特色:
1、统一的SQL接口,可以支持各种组件进行统一查询,而不需要把数据从一个组件迁移到另一个组件。
2、SparkSQL,SparkSQL概念并非华为提出,但华为为社区做出了很多贡献,自己的产品能力更强,例如华为主导向Spark SQL贡献的CPU优化器,使得稳定性和高性能比社区的开源的SQL更强。
3、完全自研的SQL引擎EIK,华为的SQL引擎更接近数据库甚至超过数据库,用户能够得到跟数据库一样甚至超过数据库交互体验效果。
4、Apach,CarbonData是华为主导的一个社区开展项目,参与者有国内众多互联网公司和大型企业,也有国外IT企业,其特点是对上层的应用无感知,提升了数据分析、数据查询的性能。
5、多级租户管理功能,FusionInsight提供的多级租户管理功能来匹配企业的组织架构,也就是说,可以有这种公司级的租户和管理员,有部门级的综合管理员,还有子部门租户和管理员,在给用户设置权限、设置资源配合有更方便的对应。
6、对异构设备支持,既支持高低配的设备在同一个大集群里,又支持开发应用可以指定某些应用运行在不同的机器上。
可用性:
中国60%的TOP 10金融、保险、银行,全球Top50运营商中的25%都用了华为的大数据平台;中国的平安城市建设有30%的客户选择了华为。华为在全球的项目、合作伙伴相当可观。迄今为止,FusionInsight HD已经交付了700多个项目,产生了300多个合作伙伴和客户;这些项目覆盖到金融、公共安全、交通、政务、电信、电力、石油等各个行业。
|
发行版本 |
功能特点 |
|
DKhadoop发行版 |
DKhadoop发行版:有效的集成了整个HADOOP生态系统的全部组件,并深度优化,重新编译为一个完整的更高性能的大数据通用计算平台,实现了各部件的有机协调。因此DKH相比开源的大数据平台,在计算性能上有了高达5倍(最大)的性能提升。DKhadoop将复杂的大数据集群配置简化至三种节点(主节点、管理节点、计算节点),极大的简化了集群的管理运维,增强了集群的高可用性、高可维护性、高稳定性。 |
|
cloudera发行版 |
Cloudera发行版:CDH是Cloudera的hadoop发行版,完全开源,比Apache hadoop在兼容性,安全性,稳定性上有增强。 |
|
hortonworks发行版 |
€Hortonworks发行版:Hortonworks 的主打产品是Hortonworks Data Platform (HDP),也同样是100%开源的产品,其版本特点:HDP包括稳定版本的Apache Hadoop的所有关键组件;安装方便,HDP包括一个现代化的,直观的用户界面的安装和配置工具 |
|
MAPR发行版 |
MAPR发行版:mapR有免费和商业两个版本,免费版本在功能上有所减少 |
|
华为hadoop发行版 |
华为hadoop发行版:华为的hadoop版本基于自研的Hadoop HA平台,构建NameNode、JobTracker、HiveServer的HA功能,进程故障后系统自动Failover,无需人工干预,这个也是对hadoop的小修补,远不如mapR解决的彻底 |
问题二:Hadoop生态的组成、每个组件的作用、组件之间的相互关系,以图例加文字描述呈现
答:
Hadoop的项目结构不断丰富发展,已经形成一个丰富的Hadoop生态系统;
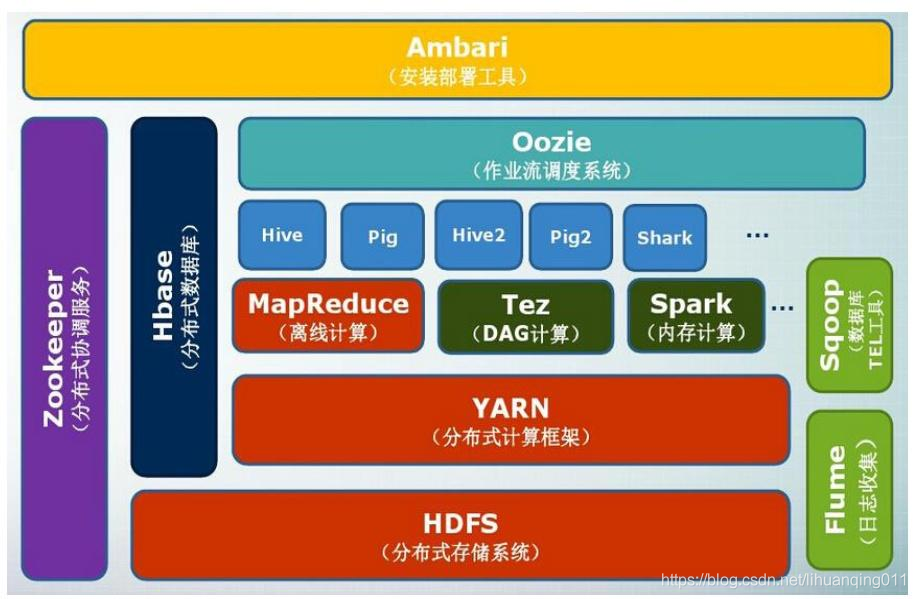
| 组件 | 功能 |
| HDFS | 分布式文件系统 |
| MapReduce | 分布式并行编程模型 |
| YARN | 资源管理和调度器 |
| Tez | 运行在YARN之上的下一代Hadoop查询处理框架 |
| Hive | Hadoop上的数据仓库 |
| HBase | Hadoop上的非关系型的分布式数据库 |
| Pig | 一个基于Hadoop的大规模数据分析平台,提供类SQL的查询语言PigLatin |
| Sqoop | 用于在Hadoop与传统数据库之间进行数据传递 |
| Oozie |
Hadoop上的工作流管理系统 |
| Zookeeper | 提供分布式协调一致性服务 |
| Storm | 流计算框架 |
| Flume | 一个高可用的,高可靠性的,分布式的海量日志采集,聚合和传输的系统 |
| Ambari | Hadoop快速部署工具,支持Apache Hadoop集群的供应,管理和监控 |
| Kafka | 一种高吞吐量的分布式发布订阅消息系统,可以处理消费者规模的网站中的所有动作流数据类似于Hadoop MapReduce的通用并行框架 |
问题三:官网学习Hadoop的安装与使用,用文档的方式列出步骤与注意事项。
答:
Hadoop的安装步骤:
1、安装hadoop的环境,必须在你的系统中有java的环境,甚至需要关闭防火墙操作。
2、配置java环境,和必须要设置SSH
3、 修改配置文件修改/usr/local/hadoop/etc/hadoop/文件夹下的core-site.xml和hdfs-site.xml 文件
4、输入相关命令
问题四:评估华为Hadoop发行版本的特点与可用性。
答:华为的hadoop版本基于自研的Hadoop HA平台,构建NameNode、JobTracker、HiveServer的HA功能,进程故障后系统自动Failover,无需人工干预,这个也是对hadoop的小修补,远不如mapR解决的彻底。


