
并发编程笔记
1、原因
掌握并发编程技术,利用多核处理来提升软件项目的性能是软件工程师一项基本技能。本文以c++语言为例,探索如何进行并发编程。内容涉及C++11,C++14以及C++17的主要内容。
测试环境:MacBook Pro ,处理器 M1, 编译器 gcc ,IDE xcode。
2、并发与并行
Erlang之父Joe Armstrong曾经以人们使用咖啡机的场景为例描述这两个术语。
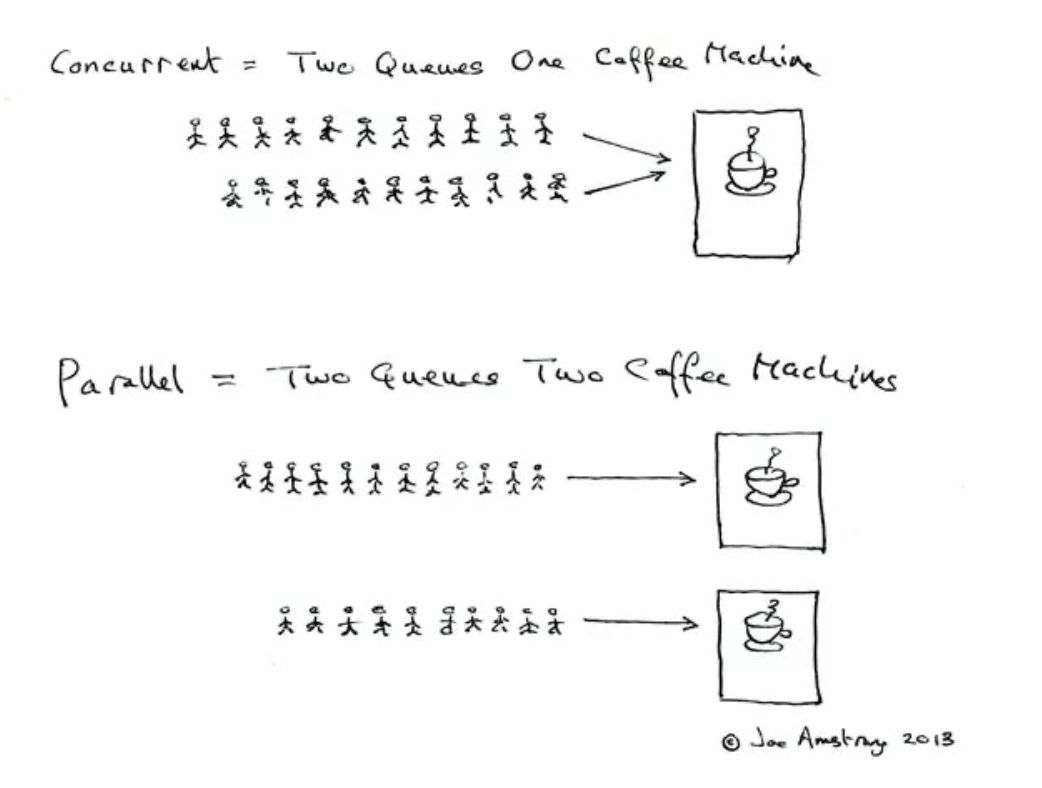
并发(Concurrent):如果多个队列可以交替使用某台咖啡机,则这一行为就是并发的。
并行(Parallel):如果存在多台咖啡机可以被多个队列交替使用,则就是并行。
这里队列中的每个人类比于计算机的任务,咖啡机类比于计算机处理器。因此:并发和并行都是在多任务的环境下的讨论。
更严格的来说:如果一个系统支持多个动作同时存在,那么这是一个并发系统。如果这个系统还支持多个动作(物理时间上)同时执行,则这个系统上一个并行系统。
所以并行其实是并发的子集。它们的区别在于是否具有多个处理器。如果存在多个处理器同时执行多个线程,就是并行。
在不考虑处理器数量的情况下,我们统称之为“并发”。
3、并发系统的性能
开发并发系统最主要的动机就是提升系统性能(事实上,这是以增加复杂度为代价的)
但是,单纯的使用多线程并不一定能提升系统系能(当然,也并非线程越多系统的性能就越好)。从上面的两幅图中可以直观感受到:线程(任务)的数量要根据具体的处理器数量来决定。假设只有一个处理器,那么划分太多线程可能适得其反。因为很多时间都花在任务切换上。
所以,在涉及并发系统之前,一方面要做好对硬件性能的了解,另一个方面需要对我们的任务有足够的认识。
具体参考阿姆达尔定律。
4、c++与并发编程
并非所有的语言都提供了多线程的环境。
即便是c++语言,知道c++11标准之前,也是没有线程支持的。在这种情况下,Linux/Unix平台的开发者通常会使用POSIX Threads,windows上的开发者也有相应的借口。但很明显,这些API都只针对特定的操作系统平台,可移植性较差。如果要同时支持Linux和Windows系统,就可能要写两套代码。
这个状态在c++11标准发布之后得到了改变。并且,在c++14 和c++17标准中又对并发编程机制进行了增强。
下图是最近几个版本的c++标准特性的线路图:
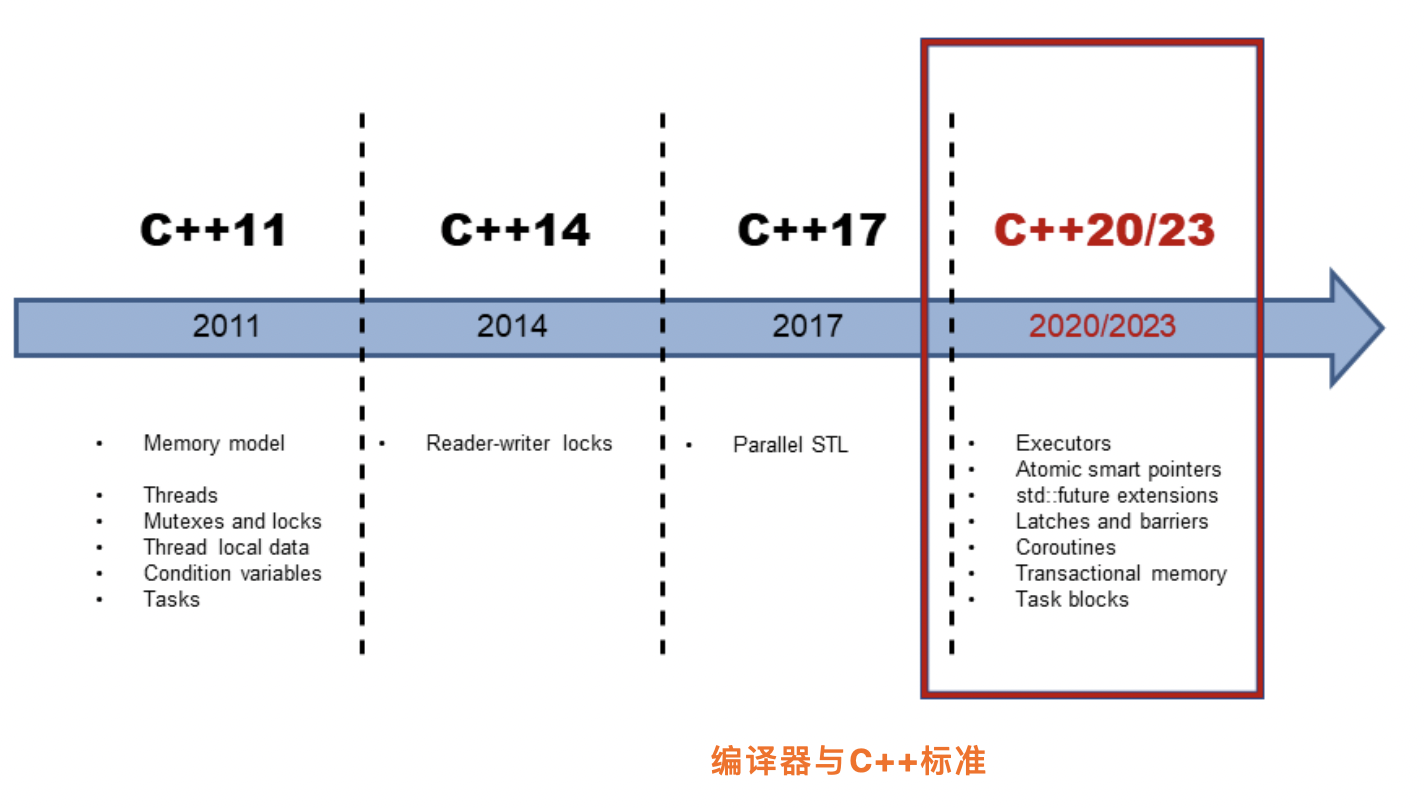
编译器对于语言特性的支持是逐步完成的。想要使用特定的特性则需要相应版本的编译器。
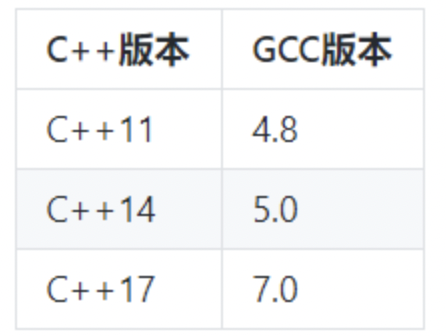
下面表格列出了c++标准和相应的编译器版本对照:
- c++标准与相应的gcc版本要求如下:
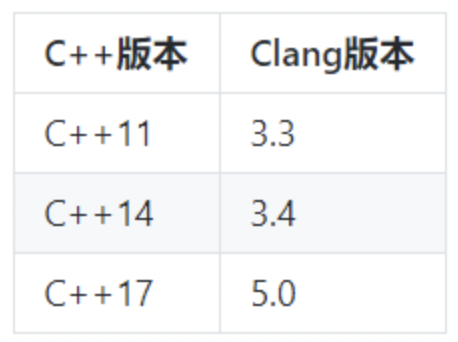
- c++标准与相应的clang版本要求如下:
默认情况下变压器是以较低的标准来编译的,如果希望使用新的标准,则需要通过编译参数-std=c++xx告知编译器。例如:
g++ -std=c++17 your_file.cpp -o your_program
5、线程
5.1 创建线程
如下所示:

#include <iostream> #include <thread> using namespace std; void hello() { cout << "Hello World from new thread." << endl; } int main() { thread t(hello); t.join(); return 0; }
thread可以和callable类型一起工作,如可以直接用lambda表达式:
#include <iostream> #include <thread> using namespace std; int main() { thread t([] { cout << "Hello World from lambda thread." << endl; }); t.join(); return 0; }
也可以传递参数给入口函数:
请注意,参数是以拷贝的形式传递的。因此,对于拷贝耗时的对象可能需要传递指针或者引用类型作为参数。如果是传递指针或者引用,则需要考虑参数对象的生命周期。因为线程的运行长度很可能会超过参数的生命周期,这个时候如果线程还在访问一个已经被销毁的对象就会出现问题。
5.2 join和detach
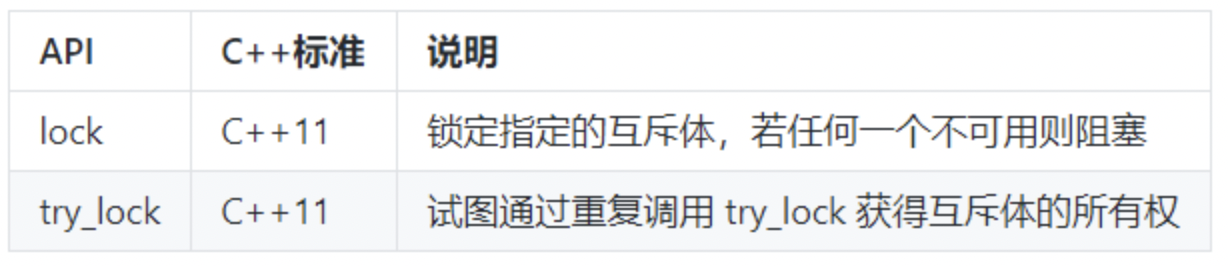
- 主要API
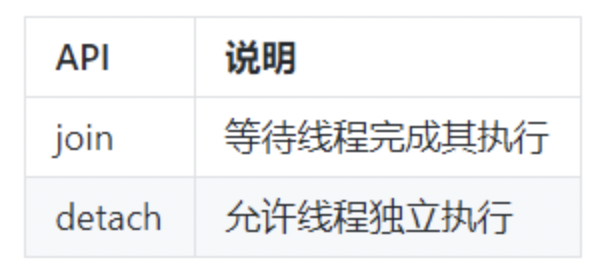
一旦启动线程之后,我们必须决定是要等待它结束(通过jion),还是让它独立运行(通过detach),我们必须二者选择其一。如果在thread对象销毁的时候我们还没做决定,则thread对象在析构函数处将调用std::terminate()从而导致我们的进程异常退出。
需要注意的是:在我们做决定的时候,很可能线程已经执行完了(例如上面的示例中线程的逻辑仅仅是一句打印,执行时间会很短)。新的线程创建之后,究竟是新的线程执行,还是当前线程的下一条语句先执行这是不确定的,因为这是由操作系统的调度策略决定的。不过这不要紧,我们只要在thread对象销毁之前做决定即可。
- join:调用此接口时,当前线程会一直阻塞,直到目标线程执行完成(当然,很可能目标线程在此调用之前就已经执行完成了,不过这不要紧)。因此,如果目标线程的任务非常耗时,你就要考虑是否需要在主线程上等待它了,因此这很可能会导致主线程卡住。
- detach:detach是让目标线程成为守护线程(deamon threads)。一旦detach之后,目标线程将独立执行,即便其对应的thread对象销毁也不影响线程的执行。并且,你无法再与之通信。
对于这两个接口,都必须是可执行线程才有意义。可以通过joinable()接口查询是否可以对它们进行join或者detach。
- 主要API
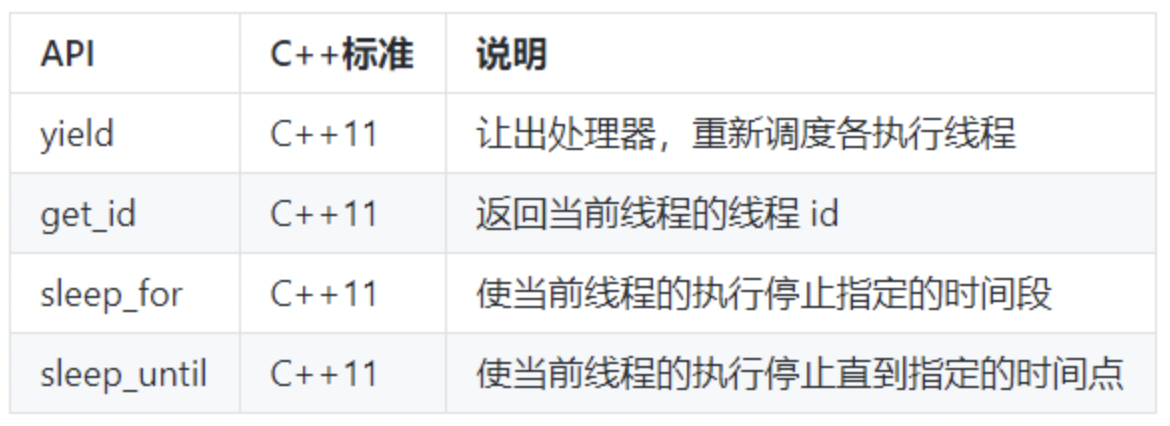
上面是一些在线程内部使用的API,它们用来对当前线程做一些控制。
- yield 通常用在自己的主要任务已完成的时候,此时希望让出处理器给其它任务使用。
- get_id 返回当前线程ID,可以以此来标识不同的线程。
- sleep_for 让当前线程停止一段时间。
- sleep_until 和sleep_for类似,但是是以具体的时间点为参数。这两个API都以chrono API为基础。
下面是一个代码示例:
void print_time() { auto now = chrono::system_clock::now(); auto in_time_t = chrono::system_clock::to_time_t(now); std::stringstream ss; ss << put_time(localtime(&in_time_t), "%Y-%m-%d %X"); cout << "now is: " << ss.str() << endl; } void sleep_thread() { this_thread::sleep_for(chrono::seconds(3)); cout << "[thread-" << this_thread::get_id() << "] is waking up" << endl; } void loop_thread() { for (int i = 0; i < 10; i++) { cout << "[thread-" << this_thread::get_id() << "] print: " << i << endl; } } int main() { print_time(); thread t1(sleep_thread); thread t2(loop_thread); t1.join(); t2.detach(); print_time(); return 0; }
上述代码创建两个线程。它们都有一些输出,其中一个会停止3秒钟,然后在输出。主线程调用join会一直卡住等待它运行结束。
输出结果如下:
now is:2022-04-05 20:19:11 [thread-0x16ff13000] print:0 [thread-0x16ff13000] print:1 [thread-0x16ff13000] print:2 [thread-0x16ff13000] print:3 [thread-0x16ff13000] print:4 [thread-0x16ff13000] print:5 [thread-0x16ff13000] print:6 [thread-0x16ff13000] print:7 [thread-0x16ff13000] print:8 [thread-0x16ff13000] print:9 [thread-0x16fe87000] is waking up now is:2022-04-05 20:19:14
5.3 一次调用
在某些情况下,有些任务需要执行一次,且只希望它执行一次,例如资源的初始化任务。这个时候可以用到上面的接口。这个接口会保证,即便在多线程的环境下,相应的函数也只会调用一次。
下面就是一个示例:有三个线程都会使用init函数,但是只会有一个线程真正执行它。
void init() { cout << "Initialing..." << endl; // Do something... } void worker(once_flag* flag) { call_once(*flag, init); } int main() { once_flag flag; thread t1(worker, &flag); thread t2(worker, &flag); thread t3(worker, &flag); t1.join(); t2.join(); t3.join(); return 0; }
无法确定具体哪个线程会执行init。而事实上我们也不关心。因为只要某个线程完成这个初始化工作就可以了。
6 并发任务
下面以一个并发任务为示例,讲述如何引入多线程。
任务:假设需要计算某个范围内所有自然数的平方根之和,例如[1,10e8]。
单线程模模型下,代码如下:
static const int MAX=10e8; static double sum = 0; void worker(int min,int max){ for(int i = min;i <= max;i++){ sum +=sqrt(i); } } void serial_task(int min,int max){ auto start_time = chrono::steady_clock::now(); sum = 0; worker(min, max); auto end_time = chrono::steady_clock::now(); auto ms = chrono::duration_cast<chrono::milliseconds>(end_time-start_time).count(); cout<<"Serial task consumed "<<ms<<" ms.Result:"<<sum<<endl; } int main(int argc, const char * argv[]) { // insert code here... serial_task(0, MAX); return 0; }
输出结果如下:
Serial task consumed 3483 ms.Result:2.10819e+13
很显然,单线程做法性能太差。且这个任务完全可以是并发执行的。
下面我们尝试以多线程方式来改造原先的程序。
改造后的程序如下:
void concurrent_task(int min,int max){ auto start_time = chrono::steady_clock::now(); unsigned concurrent_count = thread::hardware_concurrency(); cout<<"hardware_concurrency:"<<concurrent_count<<endl; vector<thread> threads; min = 0; sum = 0; for(int t=0;t<concurrent_count;t++){ int range = max /concurrent_count*(t+1); threads.push_back(thread(worker,min,range)); min = range + 1; } for(auto& t:threads) { t.join(); } auto end_time = chrono::steady_clock::now(); auto ms = chrono::duration_cast<chrono::milliseconds>(end_time-start_time).count(); cout<<"Concurrent task consumed "<<ms<<" ms.Result:"<<sum<<endl; }
输出结果:
Concurrent task consumed 1178 ms.Result:4.94391e+12
性能是提升了,但结果是错的。
要搞清楚结果为什么不正确需要我们了解更过背景知识
对于现代处理器来说,为了提高处理速度,每个处理器都会有自己的高速缓存(Cache),这个高速缓存是与每个处理器相对应的。如下图所示:
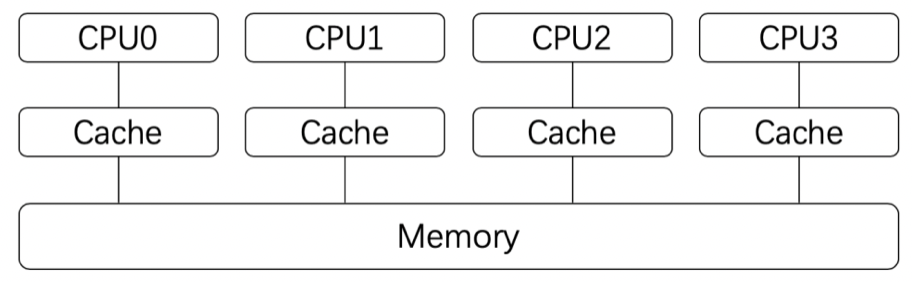
处理器在进行计算的时候,高速缓存会参与起哄,例如数据的读和写。而高速缓存和系统主存(Memory)是有可能不一致的。即:某个结果计算后保存在处理的高速缓存中了,但是没有同步到主存中,此时这个值对于其他处理器就是不可见的。
事情还远不止这么简单,我们对于全局变量值的修改:sum+=sqrt(i);这条语句,它并非原子的。它其实是很多条指令的组合才能完成。假设在某个设备上,这条语句通过下面几个步骤来完成。它们的时序可能如下所示:
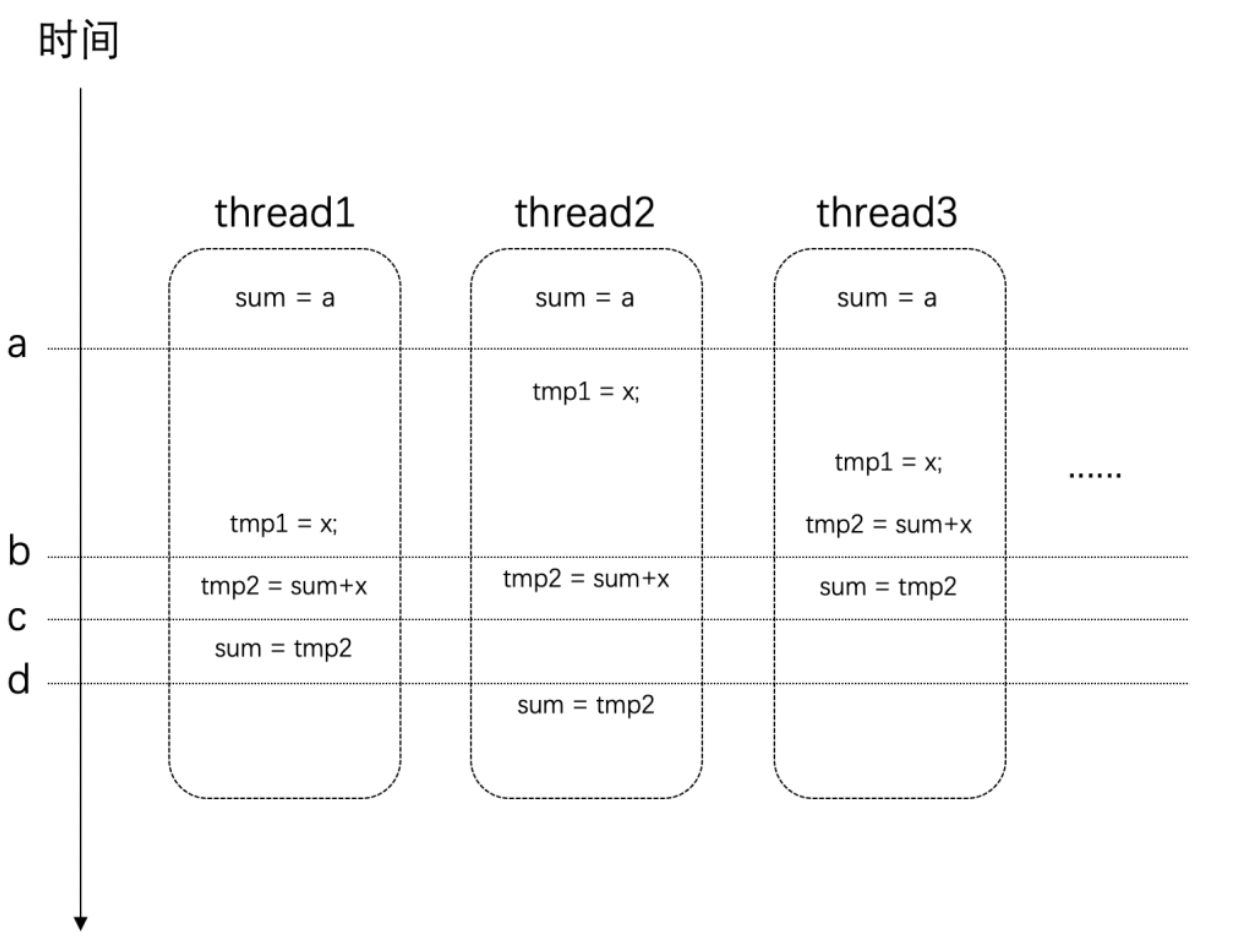
在时间点a的时候,所有线程对于sum变量的值是一致的。
但是在时间点b之后,thread3上已经对sum进行了赋值,而这时候其他几个线程也同时在其它处理器上使用这个值,那么这个时候它们所使用的值就是旧的(错误的)。最后得到的结果也自然是错误的。
7 竞争条件与临界区
当多个进程或者线程同时访问共享数据时,只要有一个任务会修改数据,那么就可能会发生问题。此时结果依赖于这些任务执行的相对时间,这种场景称为竞争条件(race condition)。
访问共享数据的代码片段称之为临界区(critical section)。具体到上面这个示例,临界区就是读写sum变量的地方。
要避免竞争条件,就需要对临界区进行数据保护。
很自然的,现在我们能够理解发生竞争条件是因为这些线程同时访问共享数据,其中有些线程的改动没有让其他线程知道,导致其他线程在错误的基础上进行处理,结果自然也就是错误的。
那么,如果一次只让一个线程访问共享数据,访问完了再让其他线程接着访问这样就可以避免问题的发生了。
下文介绍的API提供的就是这样的功能。
8 互斥体与锁
mutex
开发并发系统的目的主要是为了提升性能:将任务分散到多个线程,然后在不同的处理器上同时执行。这些分散开来的线程通常会包含两类任务:
1、独立的对于划分给自己的数据的处理。
2、对处理的结果的汇总。
其中,第1项任务因为每个线程都是独立的,不存在竞争条件的问题。而第2项任务,由于所有的线程都可能往总结果(例如上面的sum变量)汇总,这就需要做保护了。在某一个具体的时刻,只应当有一个线程更新总结果,即:保证每个线程对于共享数据的访问是“互斥”的。mutex就提供了这样的功能。
mutex是mutual exclusion(互斥)的简写。
主要API:
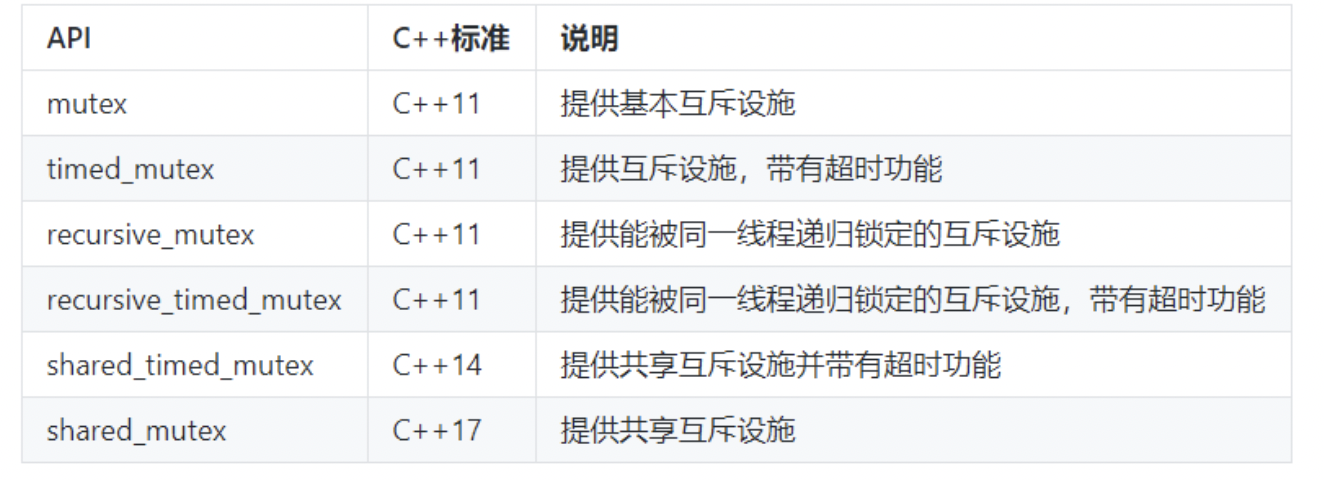
很明显,在这些类中,mutex是最基础的API。其他类都是在它的基础上改进。所以这些类都提供了下面三个方法,并且它们的功能是一样的:
- lock:锁定互斥体,如果不可用,则阻塞。
- try_lock:尝试锁定互斥体,如果不可用,则直接返回。
- unlock:解锁互斥体。
这三个方法提供了基础的锁定和解锁功能。使用lock意味着你有很强的意愿,一定要获取到互斥体。而使用try_lock则是进行一次尝试。这意味着如果失败了,通常还有其他的路径可以走。
在这些基础功能上,其他的类分别在下面三个方面进行了扩展:
- 超时:
timed_mutex,recursive_timed_mutex,shared_timed_mutex名称都带有timed,这意味着它们都支持超时功能。它们都提供了try_lock_for和try_lock_until方法,这两个方法分别可以指定超时的时间长度和时间点。如果在超时的时间范围内没有获取到锁,则直接返回,不再继续等待。
- 可重入
recursive_mutex和recursive_timed_mutex的名称都带有recursive。可重入或者叫做可递归,是指在同一个线程中,同一把锁可以锁多次。这就避免了一些不必要的死锁。
- 共享
shared_timed_mutex和shared_mutex提供了共享功能。对于这类互斥体,实际上是提供了两把锁:一把是共享锁,一把是互斥锁。一旦某个线程获取了互斥锁,任务其他线程都无法在获取互斥锁和共享锁;但是如果某个线程获取到了共享锁,其他线程无法再获取到互斥锁,但是还可以获取到共享锁。这里互斥锁的使用和其他互斥体接口和功能一样。而共享锁可以同时被多个线程同时获取到(使用共享锁的接口参见下文)。
接下来,我们借助mutex来改造我们的并发系统,改造后程序如下:
static const int MAX=10e8; static double sum = 0; static mutex exclusive; void worker(int min,int max){ for(int i = min;i <= max;i++){ exclusive.lock(); sum +=sqrt(i); exclusive.unlock(); } } void concurrent_task(int min,int max){ auto start_time = chrono::steady_clock::now(); unsigned concurrent_count = thread::hardware_concurrency(); cout<<"hardware_concurrency:"<<concurrent_count<<endl; vector<thread> threads; min = 0; sum = 0; for(int t=0;t<concurrent_count;t++){ int range = max /concurrent_count*(t+1); threads.push_back(thread(worker,min,range)); min = range + 1; } for(auto& t:threads) { t.join(); } auto end_time = chrono::steady_clock::now(); auto ms = chrono::duration_cast<chrono::milliseconds>(end_time-start_time).count(); cout<<"Concurrent task consumed "<<ms<<" ms.Result:"<<sum<<endl; } int main(int argc, const char * argv[]) { // insert code here... // serial_task(0, MAX); concurrent_task(0, MAX); return 0; }
这里有三个地方需要注意:
1、在访问共享数据之前加锁。
2、访问完成之后解锁。
3、在多线程中使用带锁的版本
执行之后结果输出如下:
hardware_concurrency:8 Concurrent task consumed 36695 ms.Result:2.10819e+13
这下结果是对了,但是我们却发现这个版本比原先但线程版本性能还要差很多。这就是为什么说多线程系统会增加系统的复杂度,并行并非多线程系统就一定有更好的性能。
不过,对于这个问题是可以改进的,即只有在最后汇总数据的时候进行一次锁保护即可。
于是改造worker函数代码如下:
void worker(int min,int max){ double tmp_sum=0; for(int i = min;i <= max;i++){ tmp_sum +=sqrt(i); } exclusive.lock(); sum +=tmp_sum; exclusive.unlock(); }
代码的改变在于两处:
1、通过一个局部变量保存当前线程的处理结果。
2、在汇总总结果的时候进行锁保护。
运行改进后的程序,输出结果如下:
hardware_concurrency:8 Concurrent task consumed 675 ms.Result:2.10819e+13
可以看到,性能一下子提升了好多倍。我们终于体会到线程带来的好处。
我们用锁的粒度(granularity)来描述锁的范围。细粒度(fine-grained)是指锁保护较小的范围,粗粒度(coarse-grained)是指锁保护较大的范围。出于性能的考虑,我们应该保证锁的粒度尽可能的细。并且,不应该在获取锁的范围内执行耗时的操作,例如执行IO。如果是耗时的运算,应该尽可能的移到锁的外面。
In general,a lock should be held for only the minimun possible time needed to perform the required operations.
--《C++ Concurrency in Action》
9 死锁
死锁是指:两个或以上的运算单元,每一方都在等待对方释放资源,但是所有方都不愿意释放资源。结果是没有任何一方能继续推进下去,于是整个系统无法再继续运转。
示例:
假设编写一个银行系统的转账功能。首先创建一个Account类来描述银行账号。为了支持并发,这个类包含一个mutex对象,用来保护账号金额,在读写账号金额时需要先加锁保护。
class Account{ public: Account(string name,double money):m_strName(name),m_dMoney(money){}; void changeMoney(double amount){ m_dMoney += amount; } string getName(){ return m_strName; } double getMoney(){ return m_dMoney; } mutex* getLock(){ return &m_mutexMoneyLock; } private: string m_strName; double m_dMoney; mutex m_mutexMoneyLock; };
接下来,再创建Bank类。
class Bank{ public: void addAccount(Account* account){ m_Accounts.insert(account); } bool transferMoney(Account* accountA,Account* accountB,double amount){ lock_guard guardA(*accountA->getLock()); lock_guard guardB(*accountB->getLock()); if(amount>accountA->getMoney()){ return false; } accountA->changeMoney(-amount); accountB->changeMoney(amount); return true; } double totalMoney() const{ double sum = 0; for(auto a:m_Accounts){ sum += a->getMoney(); } return 0; } private: set<Account*> m_Accounts; };
银行类中记录了所有的账号,并且提供了一个方法来查询整个银行的总金额。其中,最主要关注转账的实现:transferMoney。该方法关键点如下:
- 为了保证线程安全,在修改每个账号之前,需要获取相应的锁。
- 判断转出账号金额是否足够,如果不够此次转账失败。
- 进行转账。
有了银行和账户结构之后就可以编写转系统。
void randomTransfer(Bank* bank,Account* accountA,Account* accountB){ while(true){ double randomMoney=((double)random()/RAND_MAX)*100; if(bank->transferMoney(accountA, accountB, randomMoney)){ cout<<"Transfer "<<randomMoney<<" from "<<accountA->getName()<<" to "<<accountB->getName()<<" ,Bank totalMoney:"<< bank->totalMoney()<<endl; } else{ cout<<" Transfer failed,"<<accountA->getName()<<" has only $"<<accountA->getMoney()<<" required"<<endl; } } }
最后在main函数中创建两个线程,互相在两个账号之间来回转账:
int main(int argc, const char * argv[]) { // insert code here... // serial_task(0, MAX); //concurrent_task(0, MAX); Account a("Paul",100); Account b("Moira",100); Bank aBank; aBank.addAccount(&a); aBank.addAccount(&b); thread t1(randomTransfer,&aBank,&a,&b); thread t2(randomTransfer,&aBank,&b,&a); t1.join(); t2.join(); return 0; }
测试结果可能如下:
... Transfer 83.3996 from Paul to Moira ,Bank totalMoney:0 Transfer 24.5672 from Paul to Moira ,Bank totalMoney:0 Transfer 2.06493 from Paul to Moira ,Bank totalMoney:0 Transfer 55.1409 from Paul to Moira ,Bank totalMoney:0 Transfer 3.7174 from Paul to Moira ,Bank totalMoney:0 Transfer failed,Paul has only $21.3084 required 9.80156 required
程序可能很快就卡住不动了。为什么?因为发生了死锁。
两个线程逻辑是这样的:这两个线程可能会同时获取其中一个账号的锁,然后又想获取另一个账号的锁,此时就发生了死锁。如下图所示:
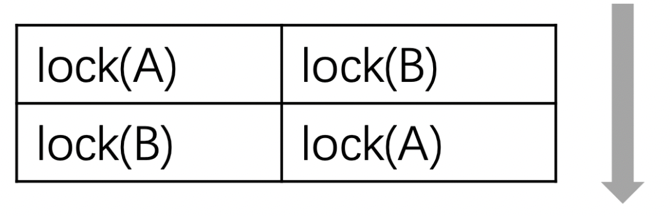
当然,发生死锁的原因远不止上面这一种情况。如果两个线程互相join就可能发生死锁。还有在一个线程中对一个不可重入对互斥体(例如mutex而非recursive_mutex)多次加锁也会死锁。
实际上,很多时候由于代码层次嵌套导致了死锁的发生,由于调用关系的复杂导致发现这类的问题并不容易。
再仔细看上面的输出,会发现另外一个问题:这里的输出时乱的。两个线程的输出混杂在一起。原因:两个线程可能会同时输出,没有做好隔离。
下面我们开始逐步解决上面的问题:
首先是输出混乱问题(专门用一把锁来保护输出逻辑即可):
mutex mutexCoutLock; void randomTransfer(Bank* bank,Account* accountA,Account* accountB){ while(true){ double randomMoney=((double)random()/RAND_MAX)*100; if(bank->transferMoney(accountA, accountB, randomMoney)){ mutexCoutLock.lock(); cout<<"Transfer "<<randomMoney<<" from "<<accountA->getName()<<" to "<<accountB->getName()<<" ,Bank totalMoney:"<< bank->totalMoney()<<endl; mutexCoutLock.unlock(); } else{ mutexCoutLock.lock(); cout<<" Transfer failed,"<<accountA->getName()<<" has only $"<<accountA->getMoney()<<" required"<<endl; mutexCoutLock.unlock(); } } }
请思考两处的lock和unlock调用,并考虑为什么不在while(true)下面写一次整体的加锁和解锁
10 通用锁定算法
要避免死锁,需要仔细的思考和设计业务逻辑。
有一个比较简单的原则可以避免死锁,即:对所有的锁进行排序,每次一定按照顺序来获取锁,不允许乱序。例如:要获取某个玩具,一定先拿到锁A,再拿锁B,才能玩玩具。这样就不会锁死了。
这个原则虽然简单,但却不容易遵守。因为数据常常是分散在很多地方的。
不过,好消息是,c++11标准提供了一些工具来避免多把锁而导致的死锁。我们只要直接调用这些接口就可以了。这个就是上面提到的两个函数。它们都支持传入多个Lockable对象。
接下来我们用它来改造之前死锁的转账系统:
bool transferMoney(Account* accountA,Account* accountB,double amount){ lock(*accountA->getLock(),*accountB->getLock()); lock_guard guardA(*accountA->getLock(),adopt_lock); lock_guard guardB(*accountB->getLock(),adopt_lock); if(amount>accountA->getMoney()){ return false; } accountA->changeMoney(-amount); accountB->changeMoney(amount); return true; }
这里只改动了3行代码。
- 通过lock函数来获取两把锁,标准库的实现会保证不会发生死锁。
- lock_guard在下面会详细介绍。此处只要知道它会在自身对象生命周期的范围锁定互斥体即可。创建lock_guard的目的是为了在transferMoney结束的时候释放锁,guardB也是一样。但是需要注意的是,这里传递了adopt_lock表示:现在是已经获取到互斥体的状态了,不用再次加锁(如果不加adopt_lock就是二次锁定了)。
改造程序后,运行结果如下:
... Transfer failed,Moira has only $0.448583 required Transfer failed,Moira has only $0.448583 required Transfer failed,Moira has only $0.448583 required Transfer failed,Moira has only $0.448583 required Transfer failed,Moira has only $0.448583 required Transfer failed,Moira has only $0.448583 required Transfer failed,Moira has only $0.448583 required Transfer failed,Moira has only $0.448583 required Transfer failed,Moira has only $0.448583 required Transfer failed,Moira has only $0.448583 required Transfer failed,Moira has only $0.448583 required Transfer failed,Moira has only $0.448583 required Transfer failed,Moira has only $0.448583 required Transfer failed,Moira has only $0.448583 required Transfer failed,Moira has only $0.448583 required Transfer failed,Moira has only $0.448583 required Transfer failed,Moira has only $0.448583 required Transfer failed,Moira has only $0.448583 required Transfer failed,Moira has only $0.448583 required Transfer failed,Moira has only $0.448583 required ...
现在这个转账程序就会一直运行下去,不会出现死锁。输出也是正常的了。
11 通用互斥管理
- 主要API
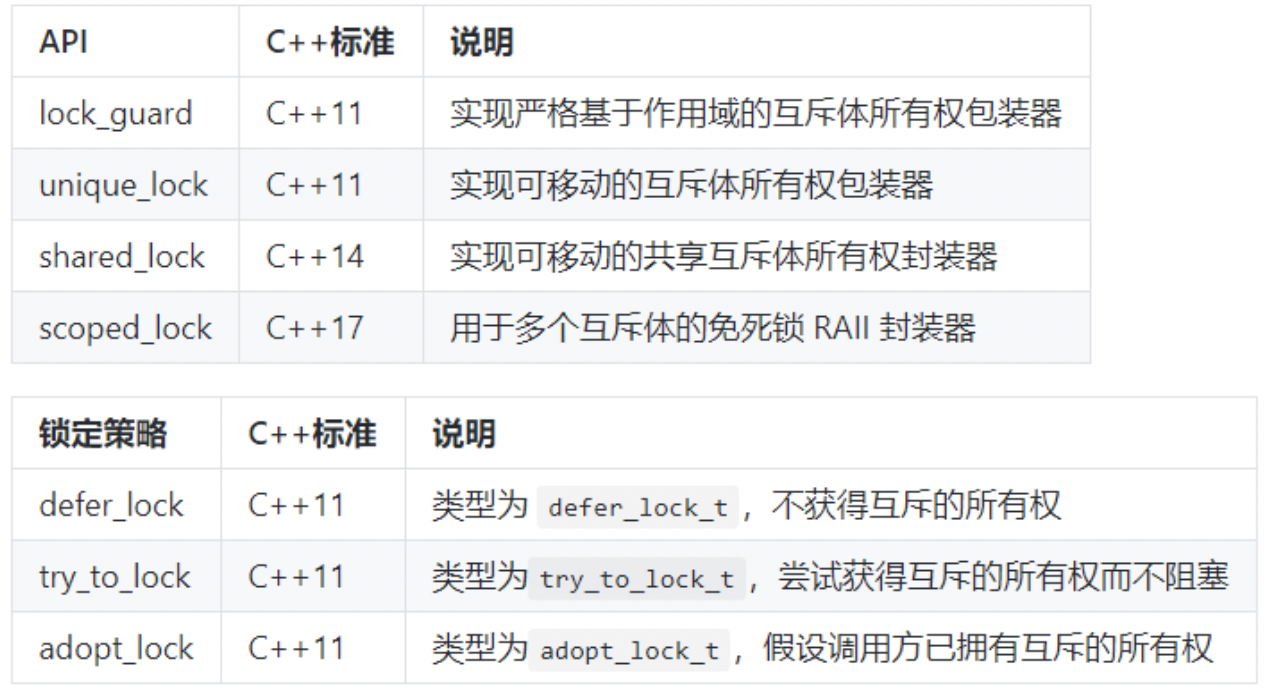
互斥体(mutex相关类)提供了对于资源的保护功能,但是手动的锁的(调用lock或者try_lock)和解锁(调用unlock)互斥体是要耗费是要耗费比较大的精力的,开发者需要精心考虑和设计代码才行。因为我们需要保证,在任何情况下,解锁要和加锁配对,因为假设出现一条路径导致获取到锁之后没有正常释放,就会影响整个系统。如果考虑方法还可以抛出异常,这样的代码写起来会更费劲。
鉴于这个原因,标准库提供了上面这些API。它们都使用了叫做RAII的编程技巧,来简化我们手动加锁和解锁的体力活。
请看下面的例子
int g_i=0; mutex g_i_mutex; void safe_increment() { lock_guard<mutex> lock(g_i_mutex); ++g_i; cout<<this_thread::get_id()<<":"<<g_i<<endl; } int main(int argc, const char * argv[]) { // insert code here... cout<<"main:"<<g_i<<endl; thread t1(safe_increment); thread t2(safe_increment); t1.join(); t2.join(); cout<<"main:"<<g_i<<endl; return 0; }
这段代码中:
- 全局的互斥体g_i_mutex用来保护全局变量g_i。
- 这是一个设计为可以被多线程环境使用的方法。因此需要使用互斥体来进行保护。这里没有调用lock方法,而是直接使用lock_guard来锁定互斥体。
- 在方法结束的时候,局部变量lock_guard<mutex>会被销毁,它对互斥体的锁的也就解除了。
- 在多线程中使用这个方法。
- RAII
上面的几个类(lock_guard,unique_lock,shared_lock,scoped_lock)都使用了一个叫做RAII的编程技巧。
RAII全称是Resource Acquisition Is Initialization,即资源获取即初始化。
RAII是一种C++编程技术,它将必须在使用前请求的资源(例如:分配的堆内存、执行线程、打开的套接字、打开的文件、锁定的互斥体、磁盘空间、数据库连接等任何存在受限供给中的事物)的生命周期与一个对象生存周期绑定。
RAII保证资源可用于任何会访问该对象的函数,也保证所有资源在其控制对象的生存期结束时,以获得顺序的逆序释放。类似地,若资源获取失败(构造函数以异常退出),则为已构造完成的对象和基类子对象所获取的所有资源,会以初始化顺序的逆序释放。这有效地利用了语言特性以消除内存泄漏并保证异常安全。
RAII可总结如下:
- 将每个资源封装入一个类,其中:构造函数请求资源,并建立所有类不变式,或在它无法完成时抛出异常。析构函数释放资源并绝不抛出异常。
- 始终经由RAII类的实例使用满足要求的资源,该资源自身拥有自动存储期或临时生存期,或具有与自动或临时对象的生存期绑定的生存期。
回想一下上下文中的transferMoney方法中的三行代码:
lock(*accountA->getLock(), *accountB->getLock()); lock_guard lockA(*accountA->getLock(), adopt_lock); lock_guard lockB(*accountB->getLock(), adopt_lock);
如果使用unique_lock这三行代码则还有一种等价的写法:
unique_lock lockA(*accountA->getLock(), defer_lock); unique_lock lockB(*accountB->getLock(), defer_lock); lock(*accountA->getLock(), *accountB->getLock());
注意这里的lock方法的调用位置。这里先定义unique_lock指定了defer_lock,因此实际没有锁定互斥体,而是到第三行才进行锁定。
最后,借助scoped_lock,我们可以将三行代码合成一行,这种写法也是等价的:
scoped_lock lockAll(*accountA->getLock(), *accountB->getLock());
scoped_lock会在其生命周期范围内锁定互斥体,销毁的时候解锁。同时,它可以锁定多个互斥体,并且避免死锁。
- 条件变量
- condition_variable C++11标准 提供与std::unique_lock关联的条件变量。
- condition_variable_any C++11标准 提供与任何锁类型关联的条件变量。
- notify_all_at_thread_exit C++11标准 安排到在此线程完全结束时对notify_all的调用。
- vc_status C++11 列出条件变量上定时等待的可能结果。
至此,我们还有一个地方可以改进。即:转账金额不足的时候,程序直接返回了false。这很难说是一个好的策略。因为即便虽然当前账号金额不足以转账,但只要别的账号又转账进来之后,当前这个转账操作或许就可以继续执行了。
这在很多业务中是很常见的一个需求:每一次操作都要正确执行,如果条件不满足就停下来等待,直到满足条件之后再继续。而不是直接返回。
条件变量提供了一个可以让多线程间同步协作的功能。这对生产者-消费者模型很有意义。再这个模型下:
- 生产者和消费者共享一个工作区。这个区间的大小是有限的。
- 生产者总是生产数据放入工作区中,当工作区满了。它就停下来等消费者消费一部分数据,然后进行工作。
- 消费者总是从工作区中拿出数据使用。当工作区中的数据全部被消费空了之后,它也会停下来等待生产者往工作区中放入新的数据。
从上面可以看到,无论是生产者还是消费者,当它们工作条件不满足时,它们并不是直接报错返回,而是停下来等待,知道条件满足。
下面我们就借助条件变量,再次改造之前的银行转账系统。这个改造主要在于账号类。重点是调整changeMoney方法。
class Account{ public: Account(string name,double money):m_strName(name),m_dMoney(money){}; void changeMoney(double amount){ unique_lock lock(m_mutexMoneyLock);//2 m_conditionVar.wait(lock,[this,amount]{ //3 return m_dMoney + amount >0;//4 }); m_dMoney += amount; m_conditionVar.notify_all();//5 } string getName(){ return m_strName; } double getMoney(){ return m_dMoney; } mutex* getLock(){ return &m_mutexMoneyLock; } private: string m_strName; double m_dMoney; mutex m_mutexMoneyLock; condition_variable m_conditionVar; //1 }
这里几处改动:
- 这里声明了一个条件变量,用来在多个线程之间协作。
- 这里使用的是unique_lock,这是为了与条件变量相配合。因为条件变量会解锁和重新锁定互斥体。
- 这里是一个比较重要的地方:通过条件变量进行等待。此时,会通过后面的lambda表达式判断条件是否满足。如果满足则继续。如果不满足,则此处会解锁互斥体,并让当前线程等待。解锁这一点非常重要,因为只有这样,才能让其他线程获取互斥体。
- 这里是条件变量等待的条件。
- 此处也很重要。当金额发生变动之后,我们需要通知所有的条件变量上等待的其他线程。此时,所有调用wait线程都会再次唤醒,然后尝试获取锁(当然,只有一个能获取到)并再次判断条件是否满足。除了notify_all还有notify_one,它只通知一个等待线程。wait和notify就构成了线程间互相协作的工具。
注意:wait和notify_all虽然是写在一个函数中的,但是在运行时它们时在多线程环境中执行的,因此对于这段代码,需要能够从不同线程的角度去思考代码的逻辑。这也是开发并发系统比较难的地方。
有了上述改动之后,银行转账方法实现就比较简单了,不用再考虑数据保护的问题了。
bool transferMoney(Account* accountA,Account* accountB,double amount){ accountA->changeMoney(-amount); accountB->changeMoney(amount); return true; }
当转账逻辑也会变得简单,不用再管转账失败的情况发生:
mutex mutexCoutLock; void randomTransfer(Bank* bank,Account* accountA,Account* accountB){ while(true){ double randomMoney=((double)random()/RAND_MAX)*100; { lock_guard guard(mutexCoutLock); cout<<"Try to Transfer "<<randomMoney <<" from "<<accountA->getName() <<"("<<accountA->getMoney()<<")" <<" to "<<accountB->getName()<<"("<<accountB->getMoney()<<"),Back total money "<<bank->totalMoney()<<endl; } bank->transferMoney(accountA, accountB, randomMoney); } }
修改完之后,程序运行输出如下:
Try to Transfer 51.2932 from Moira(146.223) to Paul(53.7769),Back total money 200 Try to Transfer 83.9112 from Moira(94.9299) to Paul(105.07),Back total money 200 Try to Transfer 61.264 from Moira(11.0186) to Paul(188.981),Back total money 200 Try to Transfer 99.8925 from Paul(188.981) to Moira(11.0186),Back total money 200 Try to Transfer 29.6032 from Paul(89.0889) to Moira(110.911),Back total money 200 Try to Transfer 63.7552 from Paul(59.4857) to Moira(79.2503),Back total money 138.736 Try to Transfer 52.4287 from Moira(79.2503) to Paul(120.75),Back total money 200 Try to Transfer 97.2775 from Moira(90.5768) to Paul(109.423),Back total money 200 Try to Transfer 49.3583 from Paul(109.423) to Moira(90.5768),Back total money 200
这下比之前都要好了。
但是细心的读者会发现,Bank totalMoney输出有时候是200,有时候不是。但不管怎么样,即便这一次不是,下一次又是了。关于这点,请自行思考为什么,以及如何改进。
- future
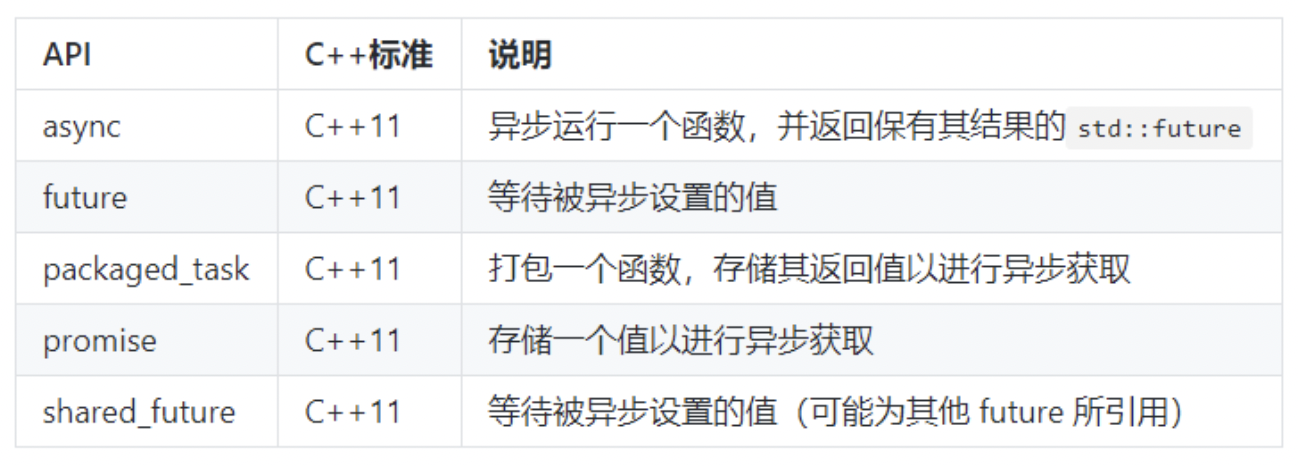
这一小节中,我们来熟悉更多的可以在并发环境中使用的工具,它们都位于<future>头文件中。
async
很多语言提供了异步机制。异步使得耗时操作不影响当前主线程的执行流程。
在c++11中,async便是完成这样的功能的:
static const int MAX=10e8; static double sum = 0; void worker(int min,int max){ for(int i = min;i <= max;i++){ sum +=sqrt(i); } } int main(int argc, const char * argv[]) { // insert code here... sum = 0; auto start_time = chrono::steady_clock::now(); auto f1 = async(worker,0,MAX); cout<<"Async task triggered"<<endl; f1.wait(); cout<<"Async task finish,result:"<<sum<<endl; auto end_time = chrono::steady_clock::now(); auto ms = chrono::duration_cast<chrono::milliseconds>(end_time-start_time).count(); cout<<"Async task consumed "<<ms<<" ms.Result:"<<sum<<endl; return 0; }
上面代码中,我们使用一个lambda表达式来编写异步任务逻辑,并通过launch::async明确指定要通过独立线程来执行任务,同时我们打印出了线程ID。输出结果:
Async task triggered Async task finish,result:2.10819e+13 Async task consumed 3475 ms.Result:2.10819e+13
这仍然是我们之前熟悉的例子。这里有两个地方需要说明:
- 这里以异步的方式启动了任务。它返回一个future对象。future用来存储异步任务的执行结果,关于future我们在后面的packed_task的例子中再详细说明。
- 此处是等待异步任务执行完成。
需要注意的是,默认情况下,async是启动一个新线程,还是以同步的方式(不启动新的线程)运行任务,这一点标准是没有指定的,由具体的编译器决定。如果希望一定要以新的线程来异步执行任务,可以通过launch::async来明确说明。launch中有两个常量:
- async:运行新线程,以异步执行任务。
- deferred:调用方线程上第一次请求其结果时才执行任务,即惰性求值。
除了通过函数来指定异步任务,还可以lambda表达式来指定。如下所示:
int main(int argc, const char * argv[]) { // insert code here... double result =0; cout<<"Async task with lambda triggered,thread:"<<this_thread::get_id()<<endl; auto f2 = async(launch::async,[&result](){ cout<<"Lambda task in thread:"<<this_thread::get_id()<<endl; for(int i=0;i<=MAX;i++){ result +=sqrt(i); } }); f2.wait(); cout<<"Async task with lambda finish,result:"<<result<<endl; return 0; }
输出:
Async task with lambda triggered,thread:0x100103d40 Lambda task in thread:0x16fe87000 Async task with lambda finish,result:2.10819e+13
对于面向对象编程来说,很多时候肯定希望以对象的方法来执行异步任务。例子如下:
class Worker{ public: Worker(int min,int max):m_min(min),m_max(max){} //1 double work(){//2 m_result=0; for(int i= m_min;i<=m_max;i++){ m_result +=sqrt(i); } return m_result; } double getResult(){ return m_result; } private: int m_min; int m_max; double m_result; }; int main(int argc, const char * argv[]) { // insert code here... Worker w(0,MAX); cout<<"Task in class triggered"<<endl; auto f3 = async(&Worker::work,&w); //3 f3.wait(); cout<<"Task in class finish,result:"<<w.getResult()<<endl; return 0; }
这段代码有三处需要说明:
- 这里通过一个类来描述任务。这个类是对前面提到的任务的封装。它包含了任务的输入参数和输出结果。
- work函数是任务的主体逻辑。
- 通过async执行任务:这里指定了具体的任务函数以及相应的对象。请注意这里是&w,因此传递的是对象的指针。如果不写&将传入w对象的临时复制。
输出:
Task in class triggered Task in class finish,result:2.10819e+13
packaged_task
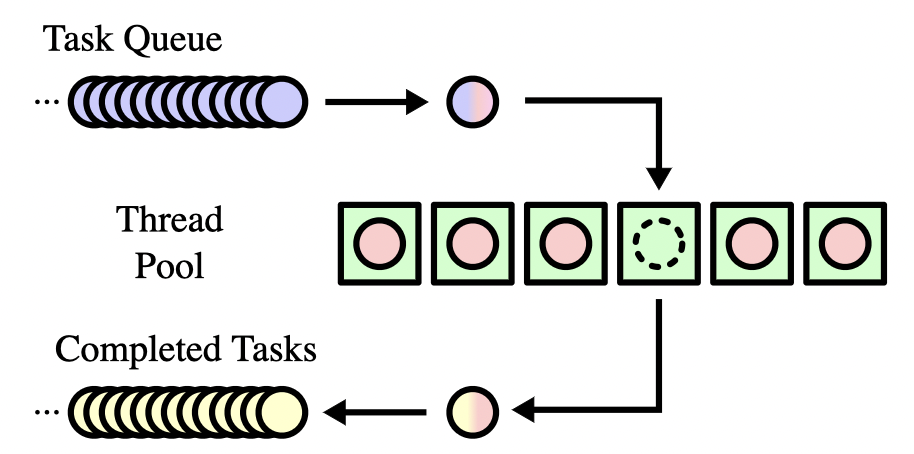
在一些业务中,我们可能会有很多的任务需要调度。这时我们常常会设计出任务队列和线程池的结构。此时,就可以使用packaged_task来包装。
packaged_task绑定到一个函数或者可调用对象上。当它被调用时,它就会调用其绑定到函数或者可调用对象。并且,可以通过与之相关联的future来获取任务的结果。调度程序只需要处理packaged_task,而非各个函数。
packaged_task对象是一个可调用对象,它可以被封装称一个std::function,或者作为线程函数传递给std::thread,或者直接调用。
下面是一个代码示例:
static const int MAX = 10e8; double concurrent_worker(int min,int max){ double sum =0; for(int i=min;i<=max ;i++){ sum += sqrt(i); } return sum; } double concurrent_task(int min,int max){ vector<future<double>> results;//1 unsigned concurrent_count=thread::hardware_concurrency(); min = 0; for(int i =0;i<concurrent_count;i++){ //2 packaged_task<double(int,int)> task(concurrent_worker);//3 results.push_back(task.get_future());//4 int range = max /concurrent_count*(i+1); thread t(std::move(task),min,range); //5 t.detach(); min = range + 1; } cout<<"threads create finish"<<endl; double sum = 0; for (auto& r:results) { sum += r.get();//6 } return sum; } int main(int argc, const char * argv[]) { // insert code here... auto start_time = chrono::steady_clock::now(); double r = concurrent_task(0,MAX); auto end_time = chrono::steady_clock::now(); auto ms = chrono::duration_cast<chrono::milliseconds>(end_time-start_time).count(); cout << "Concurrent task finish, " << ms << " ms consumed, Result: " << r << endl; return 0; }
输出:
threads create finish Concurrent task finish, 701 ms consumed, Result: 2.10819e+13
这段代码中:
- 首先创建一个集合来存储future对象。我们用它来获取任务结果。
- 同样的,根据CPU的情况来创建线程数量。
- 将任务包装成packaged_task。请注意,由于concurrent_worker被包装成了任务,我们无法直接获取它的return值。而是要通过future对象来获取。
- 获取任务关联的future对象,并将其存入集合中。
- 通过一个新的线程来执行任务,并传入需要的参数。
- 通过future集合,逐个获取每个任务的计算结果,将其累加。这里r.get()获取到的就是每个任务中concurrent_worker的返回值。
为了简单起见,这里的示例只显示了我们熟悉的例子和结构。但在实际上的工程中,调用关系通常更加复杂,你可以借助于packaged_task将任务组装成队列,然后通过线程池的方式进行调度:
promise与future
在上面的例子中,concurrent_task的结果是通过return返回的。但在一些时候,我们可能不能这么做:在得到任务结果之后,可能还有一些事情需要继续处理,例如清理工作。
这时候,就可以将primise与future配对使用。这样就可以将返回结果和任务结束两个事情分开。
下面是多上代码示例的改写:
static const int MAX = 10e8; double concurrent_worker(int min,int max){ double sum =0; for(int i=min;i<=max ;i++){ sum += sqrt(i); } return sum; } void concurrent_task(int min,int max,promise<double>* result){//1 vector<future<double>> results; unsigned concurrent_count=thread::hardware_concurrency(); min = 0; for(int i =0;i<concurrent_count;i++){ packaged_task<double(int,int)> task(concurrent_worker); results.push_back(task.get_future()); int range = max /concurrent_count*(i+1); thread t(std::move(task),min,range); t.detach(); min = range + 1; } cout<<"threads create finish"<<endl; double sum = 0; for (auto& r:results) { sum += r.get(); } result->set_value(sum); cout << "concurrent_task finish" << endl; } int main(int argc, const char * argv[]) { // insert code here... auto start_time = chrono::steady_clock::now(); promise<double> sum; //3 concurrent_task(0,MAX,&sum); auto end_time = chrono::steady_clock::now(); auto ms = chrono::duration_cast<chrono::milliseconds>(end_time-start_time).count(); cout << "Concurrent task finish, " << ms << " ms consumed, Result: " << sum.get_future().get() << endl; return 0; }
输出:
threads create finish concurrent_task finish Concurrent task finish, 731 ms consumed, Result: 2.10819e+13
这段代码和上面的示例在很大程度上是一样的。只有小部分内容做了改动:
- concurrent_task不再直接返回计算结果,而是增加了一个promise对象来存放结果。
- 在任务计算完成之后,将总结果设置到primise对象上。一旦这里调用了set_value,其相关联的future对象就会就绪。
- 这里是在main中创建一个promise来存放结果,并以指针的形式传递concurrent_task中。
- 通过sum.get_future().get()来获取结果。第2点中已经说了,一旦调用了set_value,其相关联的future对象就会就绪。
需要注意的是,future对象只有被一个线程获取值。并且在调用get()之后,就没有可以获取的值了。如果从多个线程调用get会出现数据竞争,其结果是为定义的。
如果真的需要在多个线程中获取future的结果,可以使用shared_future。
12、并行算法
从c++17开始。<algorithm>和<numeric>头文件中的很多算法添加了一个新的参数:sequenced_policy。
借助这个参数,开发可以直接使用这些算法的并行版本,不用再自己创建并发系统和划分数据来调度这些算法。
sequenced_policy可能的取值有三种,它们的说明如下:

注意:本文的前面已经提到,目前clang编译器还不支持这个功能。因此想要编译这部分代码,你需要使用gcc 9.0或更高的版本。同时还需要安装Intel Threading Building Blocks。
代码示例:
void generateRandomData(vector<double>& collection, int size) { random_device rd; mt19937 mt(rd()); uniform_real_distribution<double> dist(1.0, 100.0); for (int i = 0; i < size; i++) { collection.push_back(dist(mt)); } } int main() { vector<double> collection; generateRandomData(collection, 10e6); // ① vector<double> copy1(collection); // ② vector<double> copy2(collection); vector<double> copy3(collection); auto time1 = chrono::steady_clock::now(); // ③ sort(execution::seq, copy1.begin(), copy1.end()); // ④ auto time2 = chrono::steady_clock::now(); auto duration = chrono::duration_cast<chrono::milliseconds>(time2 - time1).count(); cout << "Sequenced sort consuming " << duration << "ms." << endl; // ⑤ auto time3 = chrono::steady_clock::now(); sort(execution::par, copy2.begin(),copy2.end()); // ⑥ auto time4 = chrono::steady_clock::now(); duration = chrono::duration_cast<chrono::milliseconds>(time4 - time3).count(); cout << "Parallel sort consuming " << duration << "ms." << endl; auto time5 = chrono::steady_clock::now(); sort(execution::par_unseq, copy2.begin(),copy2.end()); // ⑦ auto time6 = chrono::steady_clock::now(); duration = chrono::duration_cast<chrono::milliseconds>(time6 - time5).count(); cout << "Parallel unsequenced sort consuming " << duration << "ms." << endl; }
这段代码很简单:
- 通过一个函数生存1000,000个随机数。
- 将数据拷贝3份,以备用。
- 接下来将通过三个不同的parallel_policy参数来调用同样的sort算法。每次调用记录开始和结束时间。
- 第一次调用使用std::execution::seq参数。
- 输出本次测试所使用的时间。
- 第二次调用使用std::execution::par参数。
- 第三次调用使用std::execution::par_unseq参数。
程序输入如下:
Sequenced sort consuming 4464ms.
Parallel sort consuming 459ms.
Parallel unsequenced sort consuming 168ms.
可以看到,性能最好和性能最差相差了超过26倍。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~