
C语言II博客作业02
C语言II博客作业02
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/zswxy/SE2020-4 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/zswxy/SE2020-4/homework/11808 |
| 这个作业的目标 | <学会用数组进行数据处理,掌握用一维数组进行编程> |
| 学号 | <20209215> |
一、本周教学内容&目标
第七章 数组 7.17.1 输出所有大于平均值的数
1.学生知道在哪种情况下可以使用构造数据类型—数组进行数据的处理
2.掌握用一维数组进行编程
3.掌握选择排序法和二分查找法
二、本周作业(总分:50分)
2.1 完成PTA作业,并给出编程题完成截图(5分)
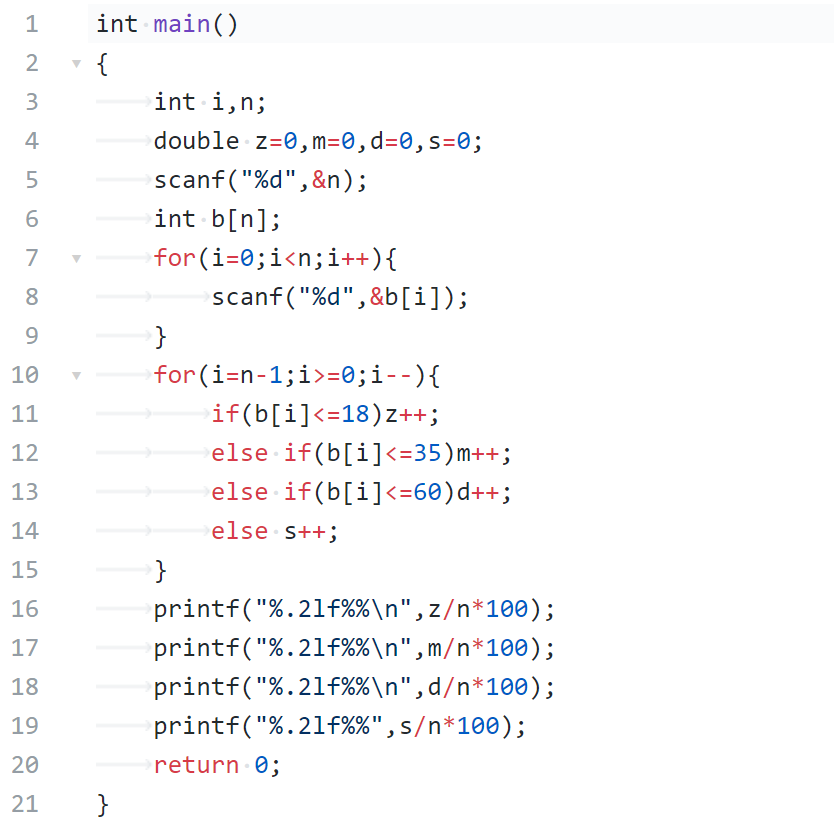
2.
2.2 题目:快速寻找满足条件的两个数
能否快速找出一个数组中的两个数字,让这两个数字之和等于一个给定的值,为了简化起见,我们假设这个数组中肯定存在至少一组符合要求的解。
解法一:采用穷举法,从数组中任意取出两个数字,计算两者之和是否为给定的数字。
代码: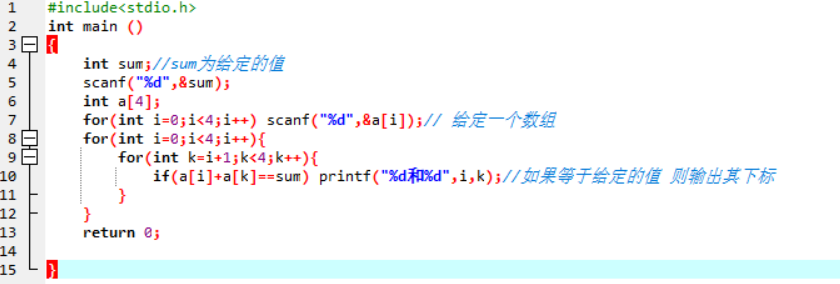
测试数据:
| 输入数据 | 输入数组值 | 输出下标 |
|---|---|---|
| 2 | 1 2 1 4 | 0和3 1和2 |
| 6 | 2 3 4 5 | 0和2 |
| 解法二:对数组中的每个数字arr[i]都判别Sum-arr[i]是否在数组中。 | ||
代码: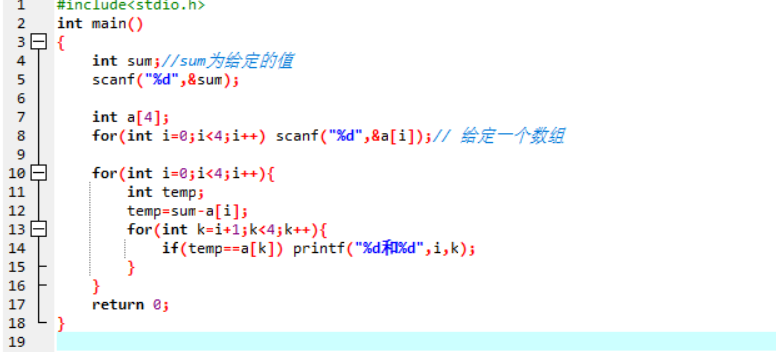 |
||
| 测试数据: | ||
| 输入数据 | 输入数组值 | 输出下标 |
| ---- | ---- | ---- |
| 4 | 2 3 1 2 | 0和2 |
| 6 | 2 2 3 4 | 0和3 1和3 |
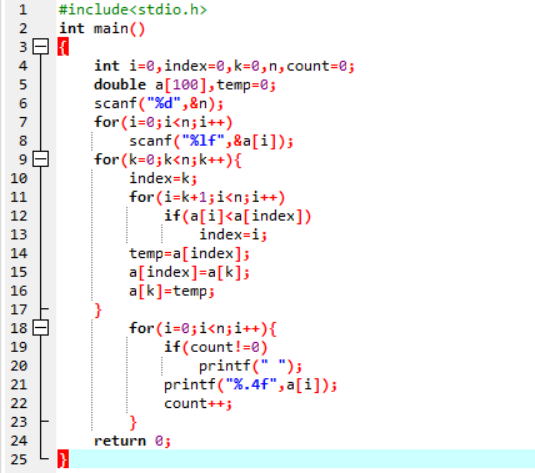
解法三:对数组进行排序,然后使用二分查找法针对arr[i]查找Sum-arr[i]。
代码: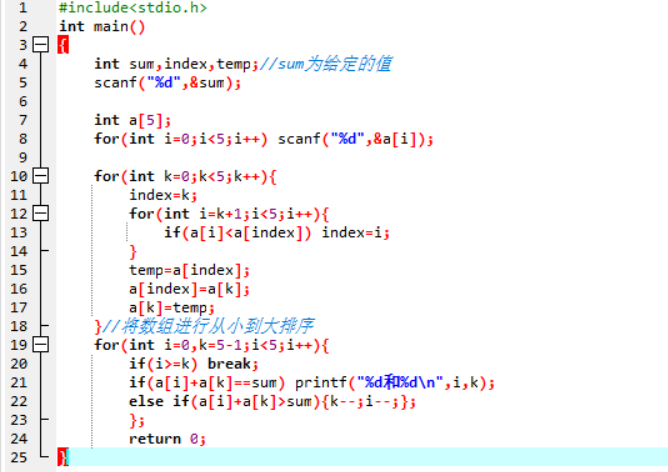
测试数据:
| 输入数据 | 输入数组值 | 输出下标 |
|---|---|---|
| 20 | 10 11 8 9 12 | 0和4 1和3 |
| 80 | 40 41 42 38 39 | 0和4 1和3 |
2.2.1请说明三种算法的区别是什么?你还可以给出更好的算法吗?(10分)
答:第一个穷举如果数据多了不好操作,第二个相比于第一个更精确的找到,第三个进行排序之后再找,对数据更好的处理。
暂时没有更好的算法
2.3 请搜索有哪些排序算法,并用自己的理解对集中排序算法分别进行描述(5分)
1.冒泡排序:就是对每个下标i,取j从0到n-1-i(n是数组长度)进行遍历,如果两个相邻的元素s[j]>s[j+1],就交换,这样每次最大的元素已经移动到了后面正确的位置
2.插入排序:插入排序又分为简单插入排序和折半插入排序;简单插入排序思想是每趟排序把元素插入到已排好序的数组中,折半插入排序是改进的插入排序,由于前半部分为已排好序的数列,这样我们不用按顺序依次寻找插入点,可以采用折半查找的方法来加快寻找插入点的速度
3.简单选择排序:选择排序思想是对每个下标i,从i后面的元素中选择最小的那个和s[i]交换
4.快速排序:快速排序是内排序中平均性能较好的排序,思想是每趟排序时选取一个数据(通常用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它的左边,所有比它大的数都放到它的右边
5.希尔排序:希尔排序是基于插入排序的一种排序算法,思想是对长度为n的数组s,每趟排序基于间隔h分成几组,对每组数据使用插入排序方法进行排序,然后减小h的值,这样刚开始时候虽然分组比较多,但每组数据很少,h减小后每组数据多但基本有序,而插入排序对已经基本有序的数组排序效率较高
6.归并排序:归并排序的思想是将两个有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。即先划分为两个部分,最后进行合并
7.堆排序:堆排序是基于选择排序的一种排序算法,堆是一个近似完全二叉树的结构,且满足子结点的键值或索引总是小于(或者大于)它的父节点。这里采用最大堆方式:位于堆顶的元素总是整棵树的最大值,每个子节点的值都比父节点小,堆要时刻保持这样的结构,所以一旦堆里面的数据发生变化,要对堆重新进行一次构建
8.基数排序:基数排序是一种非比较型整数排序算法,其原理是将数据按位数切割成不同的数字,然后按每个位数分别比较,在类似对百万级的电话号码进行排序的问题上,使用基数排序效率较高
2.4 请给出本周学习总结(15分)
1 学习进度条(5分)
| 周/日期 | 这周所花时间 | 代码行数 | 学到的知识点简介 | 目前比较迷惑的问题 |
|---|---|---|---|---|
| 第一周 | 两天 | 65 | 文件 | 文件的知识 |
| 第二周 | 四天 | 89 | 一维数组与选择排序法 | 对算法没有一个清晰的思路 |
2 累积代码行和博客字数(5分)
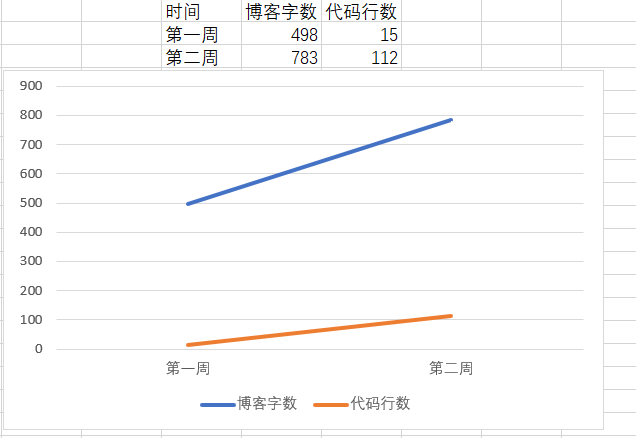
3 学习内容总结和感悟(5分)
感悟:
1.自主学习更重要。
2.课外得自己去练习。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步