


【转载 | 翻译】Visualizing A Neural Machine Translation Model(可视化讲解神经机器翻译模型)
转载并翻译Jay Alammar的一篇博文:Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
可视化讲解神经机器翻译模型(基于注意力机制的Seq2Seq模型)
Sequence-to-sequence models are deep learning models that have achieved a lot of success in tasks like machine translation, text summarization, and image captioning. Google Translate started using such a model in production in late 2016. These models are explained in the two pioneering papers (Sutskever et al., 2014, Cho et al., 2014).
sequence-to-sequence模型(以下简称Seq2Seq)在机器翻译、文本摘要、图片标注等领域取得了很好的成绩。Google翻译也从2016年底开始在其产品中使用该模型(相关细节参见早期的两篇论文:Sutskever et al., 2014, Cho et al., 2014)。
I found, however, that understanding the model well enough to implement it requires unraveling a series of concepts that build on top of each other. I thought that a bunch of these ideas would be more accessible if expressed visually. That’s what I aim to do in this post. You’ll need some previous understanding of deep learning to get through this post. I hope it can be a useful companion to reading the papers mentioned above (and the attention papers linked later in the post).
尽管如此,如果想充分理解并实现该模型,你得先拆解一堆错综复杂的概念。我觉得如果把这些概念及其关联用可视化的形式表现出来,可能会更有助于理解。这就是我写这篇博文的主要目的。当然想要看懂这篇博文,你需要提前学习并掌握一些深度学习的相关知识。总之,期望这篇博文能对你理解上面提到的两篇论文(以及稍后提到的注意力机制论文)带来有用的帮助~!
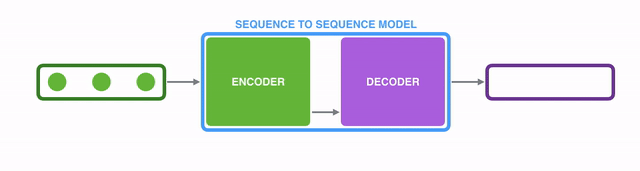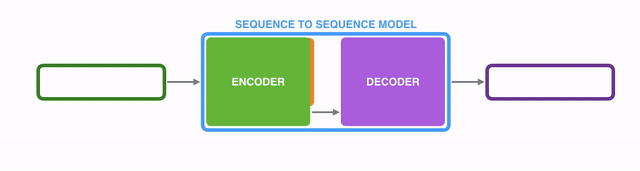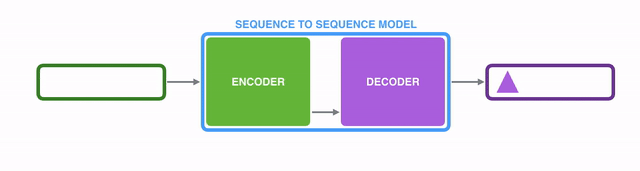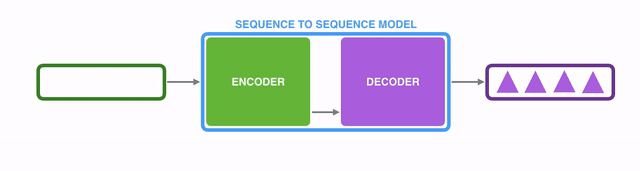
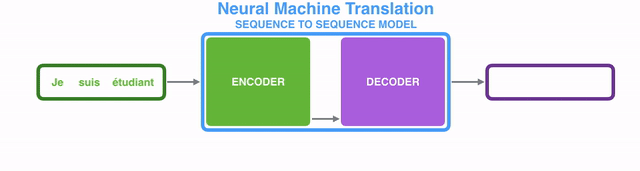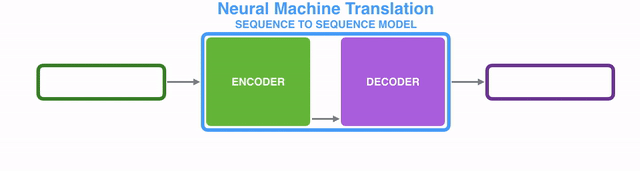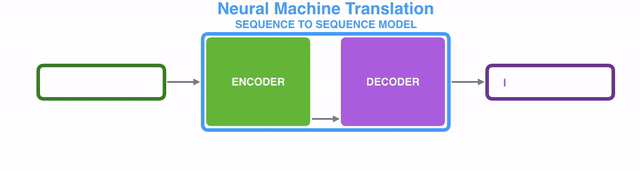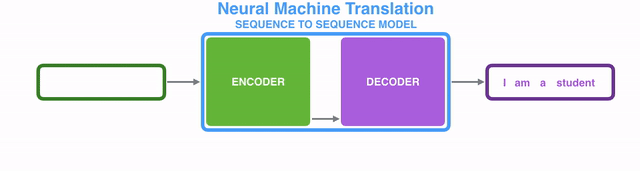
A sequence-to-sequence model is a model that takes a sequence of items (words, letters, features of an images…etc) and outputs another sequence of items. A trained model would work like this:
seq2seq模型是这样的一种模型:它接收一个item序列(item可以是word、letter、feature或image等等),然后输出另一个item序列。如下图所示:【译注:输入的item应该是同质的,比如都是word,或都是image,应该不能混杂;输出的item也类似】

In neural machine translation, a sequence is a series of words, processed one after another. The output is, likewise, a series of words:
应用在神经机器翻译场景下,就是将由一系列单词组成的序列输入到模型中,顺次处理这些单词后,在产出一系列单词组成的另一个序列:

Looking under the hood
Under the hood, the model is composed of an encoder and a decoder.
The encoder processes each item in the input sequence, it compiles the information it captures into a vector (called the context). After processing the entire input sequence, the encoder send the context over to the decoder, which begins producing the output sequence item by item.
表象之下,seq2seq2模型由一个encoder(编码器)和一个decoder(解码器)组成。
encoder处理输入序列中的每个item,把从item中获取到的信息编译到一个被称为context的vector中。当整个输入序列都处理完之后,encoder将这个context发送给decoder,decoder开始逐个item生成输出序列内容。
The same applies in the case of machine translation.
类似地,在神经机器翻译场景下:
The context is a vector (an array of numbers, basically) in the case of machine translation. The encoder and decoder tend to both be recurrent neural networks (Be sure to check out Luis Serrano’s A friendly introduction to Recurrent Neural Networks for an intro to RNNs).
在神经机器翻译的例子中,context是一个vector(就是一个由数字组成的数组)。而encoder和decoder都是RNN。

The context is a vector of floats. Later in this post we will visualize vectors in color by assigning brighter colors to the cells with higher values.
图示中的context是一个浮点数vector。为便于展示,本文中会对context中的数字填上背景色,数值越大颜色越浅,否则越深
You can set the size of the context vector when you set up your model. It is basically the number of hidden units in the encoder RNN. These visualizations show a vector of size 4, but in real world applications the context vector would be of a size like 256, 512, or 1024.
你可以在创建模型之初对context的尺寸进行设定,通常就是等于encoder RNN中隐藏单元的数量。上面示例中的conext尺寸是4,但实际应用场景中一般用256、512或1024。
By design, a RNN takes two inputs at each time step: an input (in the case of the encoder, one word from the input sentence), and a hidden state. The word, however, needs to be represented by a vector. To transform a word into a vector, we turn to the class of methods called “word embedding” algorithms. These turn words into vector spaces that capture a lot of the meaning/semantic information of the words (e.g. king - man + woman = queen).
按照设计,RNN在每个time step里都接收两项内容:一个输入(在encoder的例子中就是输入语句的一个word)以及一个隐藏状态。这里word需要表示成vector,将word转换为vector的方法称为词嵌入(Word Embedding)算法。这种将单词映射到矢量空间的过程会捕获单词中很多语义级别的信息(例如一个典型的例子:king - man + woman = queen)。
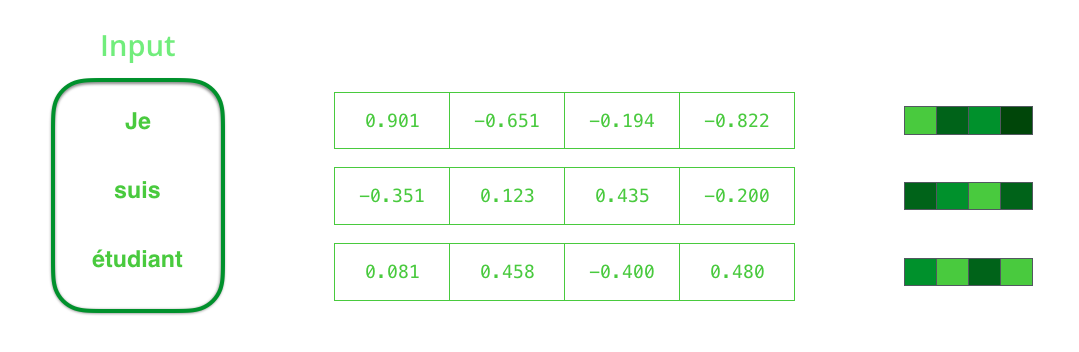
We need to turn the input words into vectors before processing them.
That transformation is done using a word embedding algorithm.
We can use pre-trained embeddings or train our own embedding on our dataset.
Embedding vectors of size 200 or 300 are typical, we're showing a vector of size four for simplicity.
在继续处理单词前,需要先通过词嵌入算法将单词转换为矢量(即词向量)。
获取词向量有很多途径:既可以使用别人预训练好的词向量,也可以在自己的数据集上训练出自己的词向量。
典型的词向量的长度一般是200或300。此处为便于演示,我们使用一个长度为4的词向量。
Now that we’ve introduced our main vectors/tensors, let’s recap the mechanics of an RNN and establish a visual language to describe these models:
至此我们已经介绍了主要的vector和tensor,接下来我们回顾一下RNN的运行机制,并用可视化的方式来描述RNN模型。
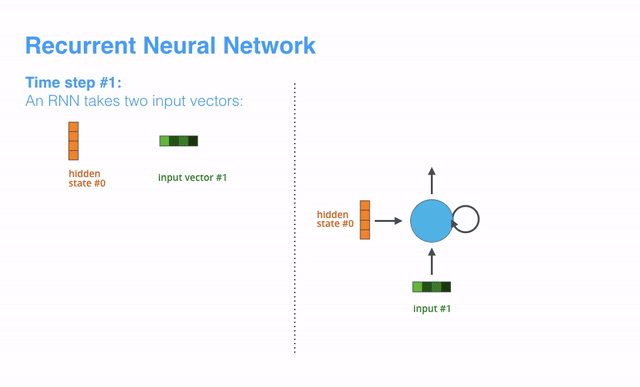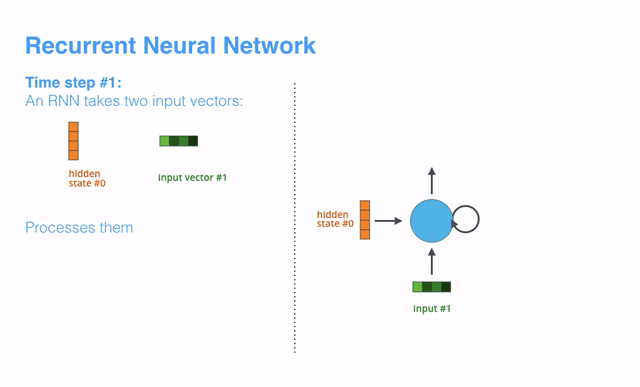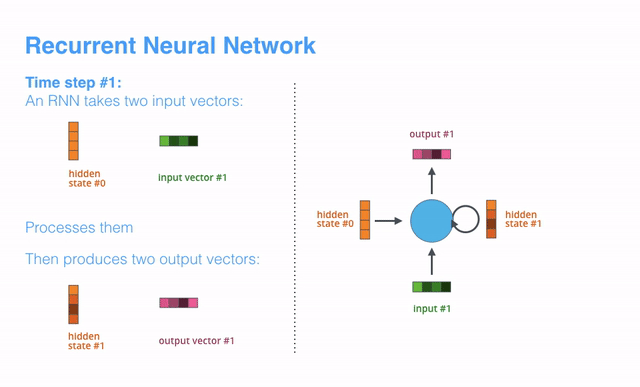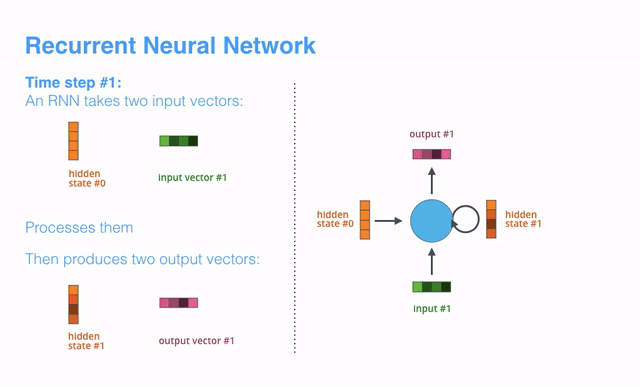
【译补】上述动画展示了time step1时,RNN接受第一个输入vector(input vector #1)和起始的隐藏态vector(hidden state #0),经过处理后产出了一个输出vector(output vector #1)和一个新的隐藏态vector(hidden state #1)
The next RNN step takes the second input vector and hidden state #1 to create the output of that time step. Later in the post, we’ll use an animation like this to describe the vectors inside a neural machine translation model.
下一个time step中,RNN会获取第二个输入vector(input vecotr #2)和隐藏态vector(hidden state #1)来生成当前time step的输出项(包括output vector #2和hidden state #2)。下文中,我们用一个类似的动画来描述神经机器翻译模型内部的vector。
In the following visualization, each pulse for the encoder or decoder is that RNN processing its inputs and generating an output for that time step. Since the encoder and decoder are both RNNs, each time step one of the RNNs does some processing, it updates its hidden state based on its inputs and previous inputs it has seen.
在接下来的可视化演示里,encoder或decoder的每一步都表示RNN在处理输入并产出一个当前时刻的输出。因为encoder和decoder都是RNN,在每个time step中,都有其中一个RNN做一些处理,它会根据它当前的输入以及之前的输入来更新它的隐藏状态。
Let’s look at the hidden states for the encoder. Notice how the last hidden state is actually the context we pass along to the decoder.
让我们看一下encoder中隐藏态的处理过程,注意最后一个隐藏态实际就是要传递给decoder的那个context。
The decoder also maintains a hidden states that it passes from one time step to the next. We just didn’t visualize it in this graphic because we’re concerned with the major parts of the model for now.
解码器也会维护一个隐藏状态并把它从一个time step传给下一个time step。但我们此时先关注模型的主要部分,所以上图中没有显示出解码器的隐藏状态处理过程。
Let’s now look at another way to visualize a sequence-to-sequence model. This animation will make it easier to understand the static graphics that describe these models. This is called an “unrolled” view where instead of showing the one decoder, we show a copy of it for each time step. This way we can look at the inputs and outputs of each time step.
现在让我们用另一种方式来观察seq2seq模型,下面这个动画可以更容易地理解和描述这些模型。我称之为“展开视图”,其并不直接显示一个decoder,而是在每个time step显示它的一个副本【译注:就是把每个time step中的RNN及其处理过程都叠加到同一个画面里】。通过这种方法我们可以看到每个time step的输入和输出过程。
Let’s Pay Attention Now
The context vector turned out to be a bottleneck for these types of models. It made it challenging for the models to deal with long sentences. A solution was proposed in Bahdanau et al., 2014 and Luong et al., 2015. These papers introduced and refined a technique called “Attention”, which highly improved the quality of machine translation systems. Attention allows the model to focus on the relevant parts of the input sequence as needed.
context已经成为这类模型的一个瓶颈,它在模型处理长句子时给其带来了巨大挑战。 针对此问题,这两篇论文(Bahdanau et al., 2014 和 Luong et al., 2015 )给出了一个可行的解决方案,文中提出并完善了一项称之为注意力(attention)的技术,极大地提升了机器翻译系统的运行效果。注意力机制允许模型根据需要来关注输入序列的相应部分。
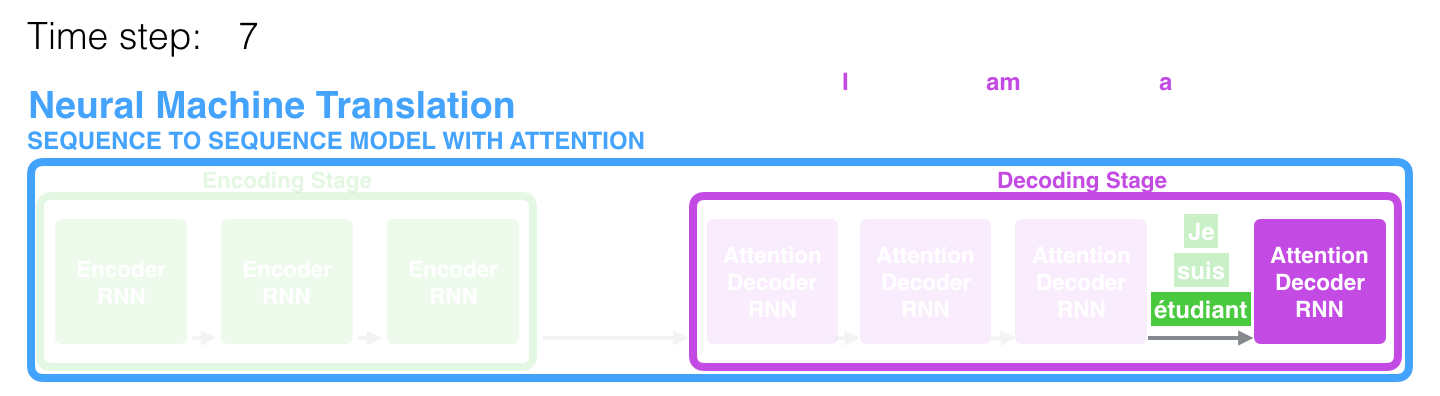
At time step 7, the attention mechanism enables the decoder to focus on the word "étudiant" ("student" in french) before it generates the English translation.
This ability to amplify the signal from the relevant part of the input sequence makes attention models produce better results than models without attention.
在第7步(即第7个时间步长)中,注意力机制使解码器在生成英语翻译结果之前,先聚焦于单词"étudiant" (法语中的“学生”)。
这种“放大来自输入序列相关部分的信号的”能力使得有注意力机制的模型比没有注意力机制的模型产生更好的结果。
Let’s continue looking at attention models at this high level of abstraction. An attention model differs from a classic sequence-to-sequence model in two main ways:
First, the encoder passes a lot more data to the decoder. Instead of passing the last hidden state of the encoding stage, the encoder passes all the hidden states to the decoder:
让我们继续从高度抽象的层次上研究注意力模型, 注意力模型与传统的seq2seq模型相比,主要有两点不同:
首先,encoder传递给decoder的数据变多了。encoder不再只传递编码阶段最后一个隐藏态给decoder,而是将编码阶段的所有隐藏态全都传递给decoder。
Second, an attention decoder does an extra step before producing its output. In order to focus on the parts of the input that are relevant to this decoding time step, the decoder does the following:
1. Look at the set of encoder hidden states it received – each encoder hidden states is most associated with a certain word in the input sentence
2. Give each hidden states a score (let’s ignore how the scoring is done for now)
3. Multiply each hidden states by its softmaxed score, thus amplifying hidden states with high scores, and drowning out hidden states with low scores
其次,带注意力的decoder在生成输入序列之前,会多做一些额外的操作。具体来说,为了聚焦到输入序列中“和当前解码time step相对应的”的那个部分上,decoder做了如下事情:
1. 观察编码器产出的隐藏态集合,每个隐藏态都与输入序列中某个特定单词有着最大的关联性。
2. 为每个隐藏态打分(具体打分方法此处先不解释)
3. 将每个隐藏态与其对应的经过归一化处理的打分相乘,使得分高的隐藏态突出放大,得分低的隐藏态被弱化掩盖。

This scoring exercise is done at each time step on the decoder side.
这一系列操作会在decoder处理阶段的每个time step里都执行一次。
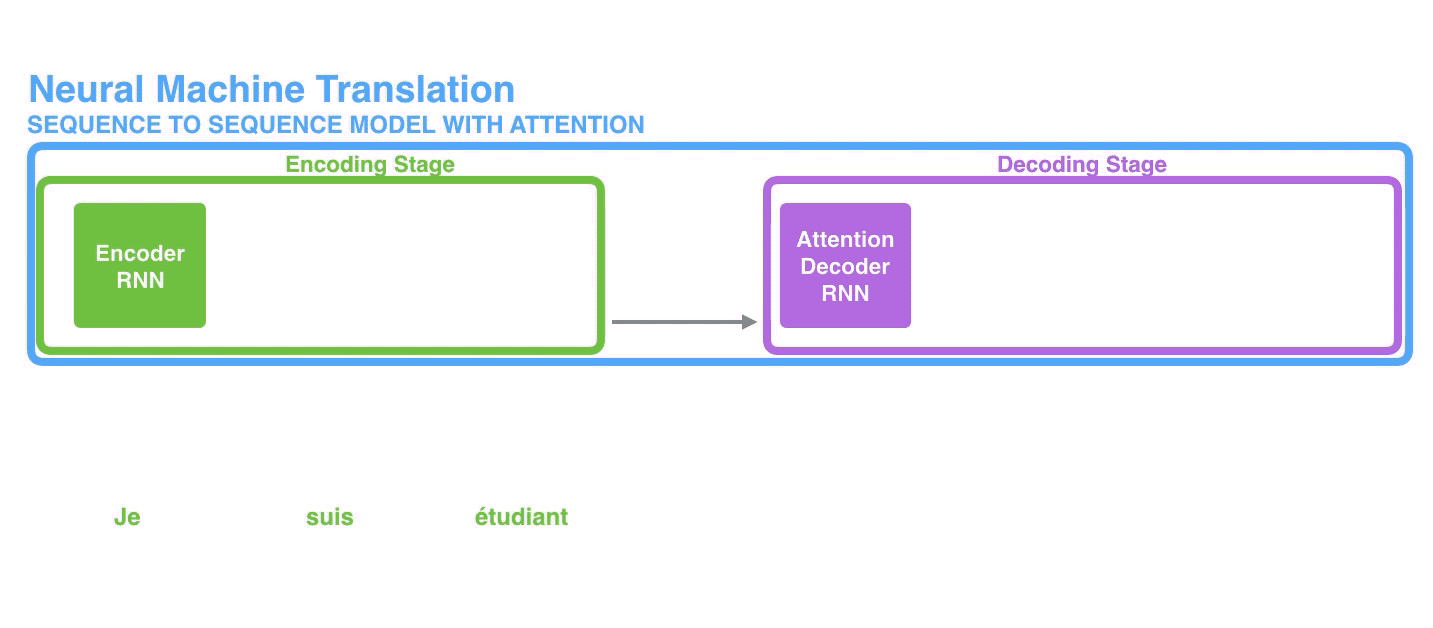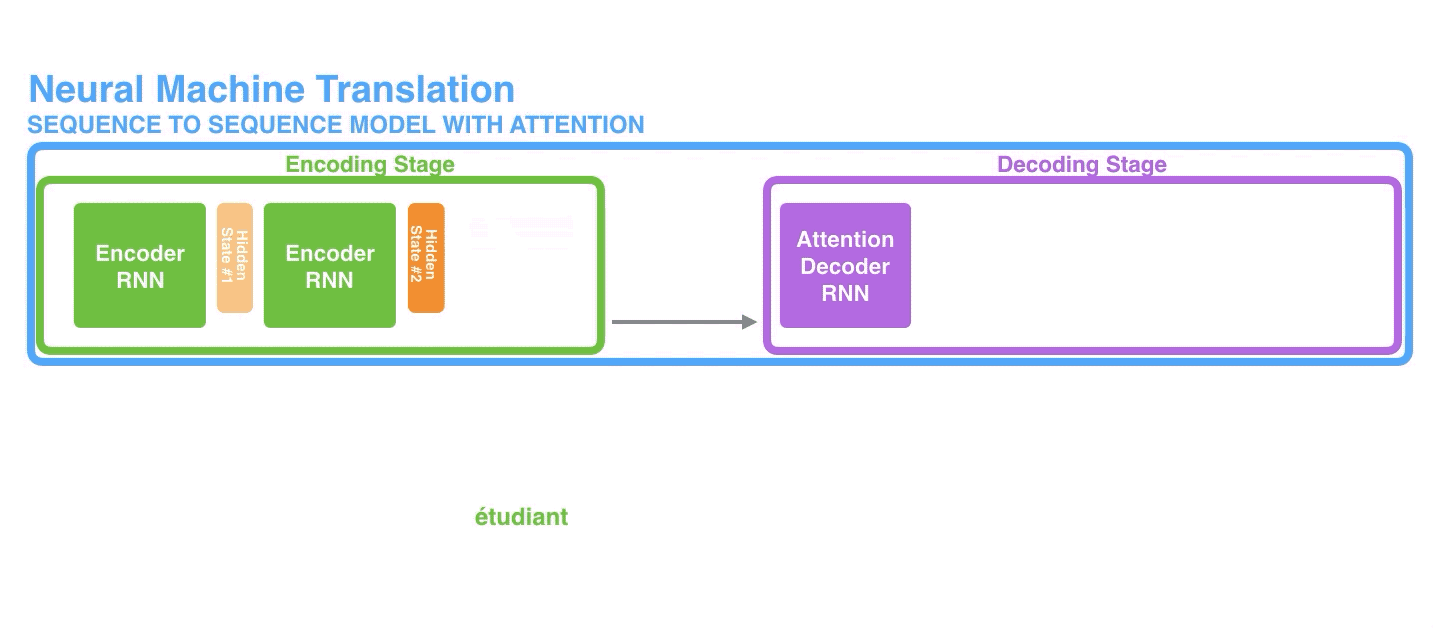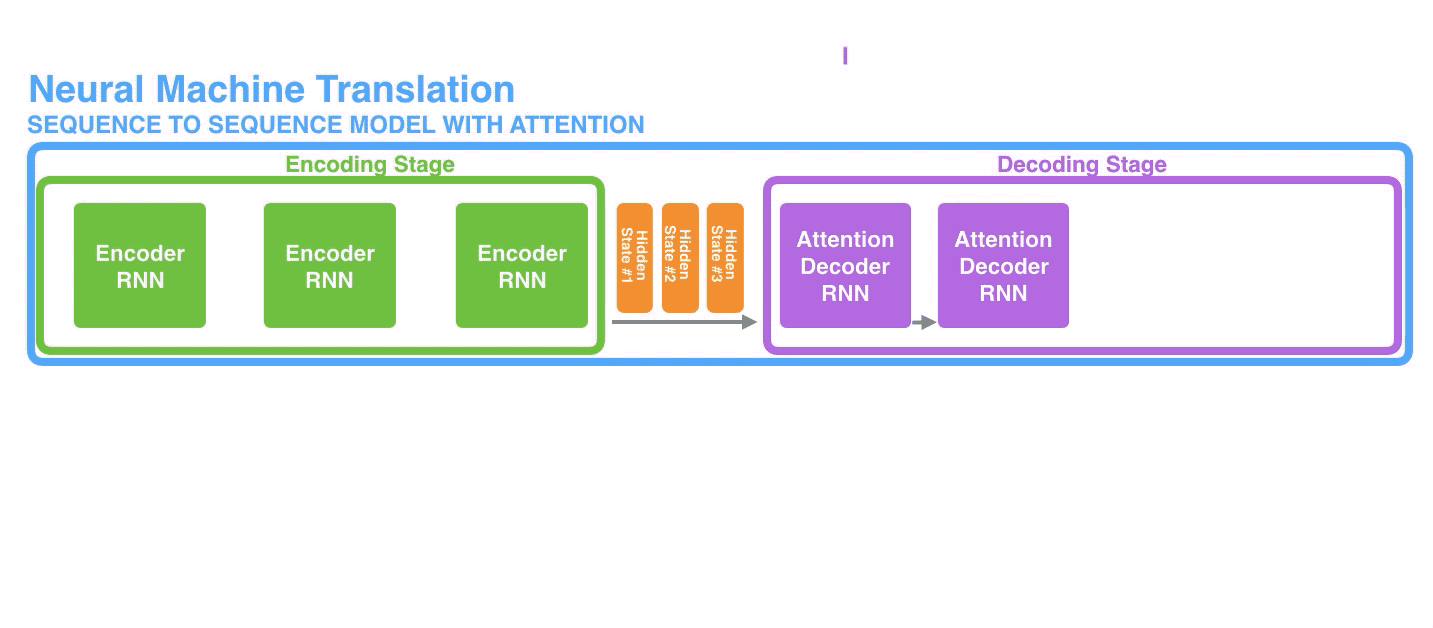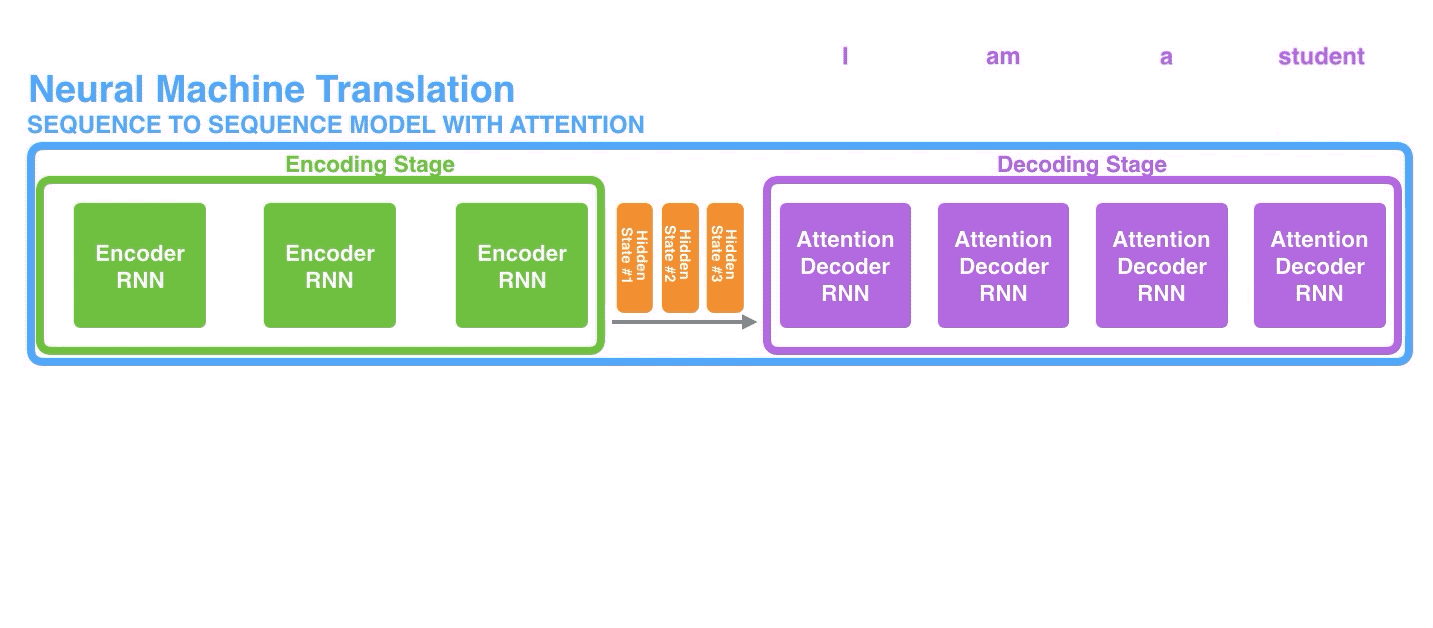
Let us now bring the whole thing together in the following visualization and look at how the attention process works:
- The attention decoder RNN takes in the embedding of the
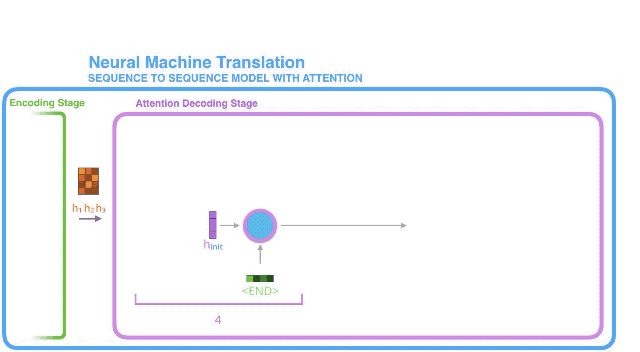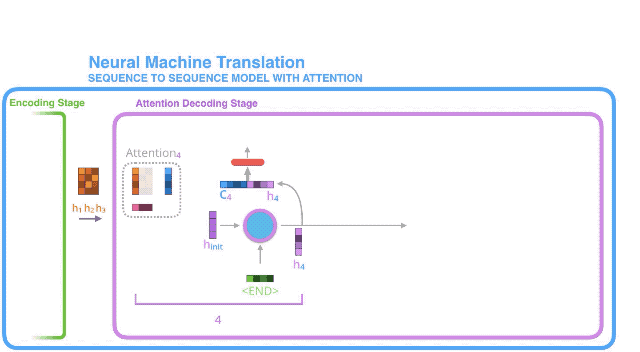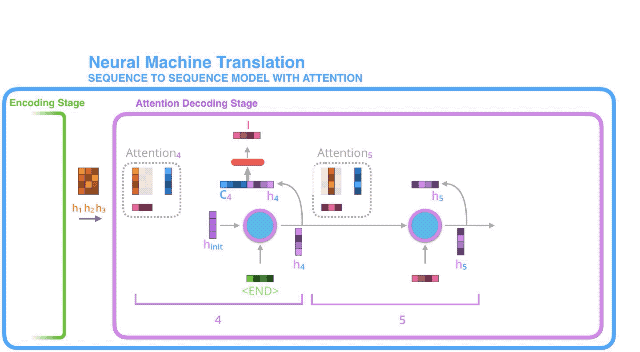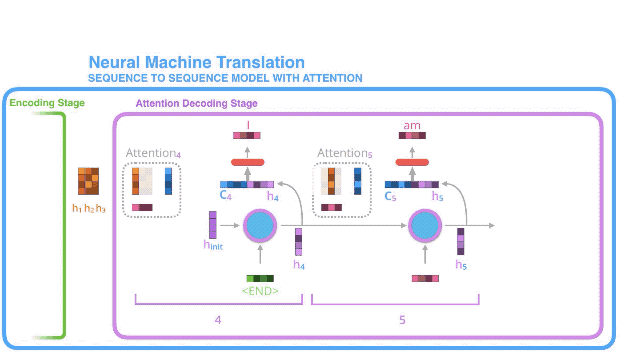
- The RNN processes its inputs, producing an output and a new hidden state vector (h4). The output is discarded.
- Attention Step: We use the encoder hidden states and the h4 vector to calculate a context vector (C4) for this time step.
- We concatenate h4 and C4 into one vector.
- We pass this vector through a feedforward neural network (one trained jointly with the model).
- The output of the feedforward neural networks indicates the output word of this time step.
- Repeat for the next time steps
现在让我们把所有环节整合到一起,看看注意力机制是如何工作的。
1. 带有注意力机制的解码器RNN,接收到两个东西:(1) 表示编码结束的特定词向量令牌(即<END>令牌),和(2) 一个经过初始化的解码器隐藏状态;
2. 解码器RNN处理上述输入,生成一个输出和一个新的隐藏状态向量(h4),注意这里的输出会被丢弃。
3. 注意力生效步骤:使用编码器隐藏状态,和上述隐藏状态向量(h4),计算出当前时间步长的context向量(C4);
4. 将h4和C4拼接成一个向量;
5. 将上述向量放到一个与模型共同训练的前馈神经网络中;
6. 前馈神经网络的产出就是当前时间步长生成的输出单词;
7. 继续下一个time step的操作;
This is another way to look at which part of the input sentence we’re paying attention to at each decoding step:
用另一种方式来观察每个解码步骤中,我们将注意力集中在输入句子的哪个部分上:

Note that the model isn’t just mindless aligning the first word at the output with the first word from the input. It actually learned from the training phase how to align words in that language pair (French and English in our example). An example for how precise this mechanism can be comes from the attention papers listed above:
需要注意的是,模型并不只是盲目地将输出中的第一个单词与输入中的第一个单词对齐,它实际上从培训阶段学会了如何排列语言对中的单词(本例中是法语和英语),上面列举的论文中有一个展示这种注意力机制的准确性的例子:

You can see how the model paid attention correctly when outputing "European Economic Area".
In French, the order of these words is reversed ("européenne économique zone") as compared to English.
Every other word in the sentence is in similar order.
可以看出该模型在输出“European Economic”(欧洲经济区)这个词组时,是如何将注意力正确地聚焦的。
在法语中,“欧洲经济区”这个词组的词序相对英语来说是相反的("zone économique européenne"),而该句子中其他单词的顺序在两种语言中都差不多。
(译注:即模型在一个大部分单词顺序相同的句子翻译任务中,准确地发现了其中需要调整单词顺序的部分!)
If you feel you’re ready to learn the implementation, be sure to check TensorFlow’s Neural Machine Translation (seq2seq) Tutorial.
如果你觉得已经准备好学习其具体实现,一定要来看看Seq2Seq的tensorflow版本的教程:Neural Machine Translation (seq2seq) Tutorial.
【finished】

