

斯坦福【概率与统计】课程笔记(二):从EDA开始
探索性数据分析(Exploratory Data Analysis)
本节课程先从统计分析四步骤中的第二步:EDA开始。
课程定义了若干个术语,如果学习过机器学习的同学,应该很容易类比理解:
- population:上节课说过,整体数据集合被称作population
- individual:其中每个个体,课程里称之为individual,注意不仅仅指个人,也可以泛指其他集合的其中一条数据
- variable:变量,即描述个体的某个特点,类比机器学习中的特征
- dataset:从population中圈定的一个子集
举个例子:

这是一个用药记录表,其中每一行是一个individual,每一列是一个variable
变量的类型
variable可以细分为两种:Categorical variables 分类变量(也叫Qualitative variables 定性变量)和 Quantitative variables 定量变量
前者一般就是指离散型变量,后者一般指连续型变量。
课程中还提到另一种变量(或叫特征)的分类方法:
- Nominal variable:名义变量(也叫定类变量),是最不精确的度量方法,只能用来区分差别(difference)。例如生物类别:狗、猫、牛、马、人、细菌……就是典型的名义变量。其特点是:各个值之间没有优劣之分,是平等的,自然也无法相互比较和计算。
- Ordinal variable:序数变量,其比Nominal variable精确一些,其可以对不同值进行排序。例如比赛的名次:冠军、亚军、季军、第四名……就是典型的有序变量。这类变量的特点是:各个值之间有顺序或者说优劣(如冠军最好,亚军次之,最后一名最差等),但是彼此之间的间隔既不固定也不相等(如跳水冠军123分、亚军96分、季军95分)。
- Interval variable:区间变量,其比序数变量更精确一些,其相邻的值之间的差异是固定或者说相等的。例如温度计:100摄氏度和99摄氏度、99摄氏度和98摄氏度之间都相差1个摄氏度,可以看到这个差值是固定的,或者说相邻的两个值之间的差是相等的。但区间变量中的0不能表示“没有”这种变量或特征,比如0摄氏度,其并不代表没有温度了(因为0度是有意义的,此外还有零下20度、零下100度等)。【个人理解:就是interval variable的特征是可以取0值的,或者说0值是有效的值】
- Ratio:比例/比率。是最精确的度量方法,其比区间变量更精确,与区间变量的差别也就是其中的0可以表示没有这种变量或特征。比如年龄:0岁就表示没有年龄;身高:0cm表示没有身高;体重:0kg表示没有体重;【个人理解:就是ratio的0值表示的是这一条individual在这个特征上是缺失的,即没有有效值,但ratio的0是否可以用于分析呢?这个需要继续往下学习了……】
注意上述四个度量方法之间,能够用高精度的方法度量的变量,也可以转为用低精度的方法来度量,比如年龄是ratio,其可以转为用ordinal variable来度量(比如婴儿期、幼儿期、青年、中年、老年等);但反之不行,比如冠军和亚军之间无法用interval variable或ratio来度量。
interval variable 和 ratio之间可能比较难区分,多看一些例子可能会好一些:
- 考试分数是哪种?答案是interval variable,因为0分是可以存在的,考试可以考0分,而不能说成0分表示根本没参加考试;
- 老师在课堂上留给学生讨论的分钟数是哪种?答案是ratio,因为0表示老师根本没留时间给学生讨论,而一般不能说成“老师留了0分钟给学生讨论”;
有sense了吗?interval variable的0表示事情发生了其结果是0(或可以发生结果是0的事情);而ratio的0表示事情根本没发生(或根本不存在)。
单个变量的分析
从这里开始,课程阐述了EDA在做什么——可以理解为观察变量自身的特点、变量之间的关系、变量与结果之间的关系。
所以先从单个变量开始,即只看一个变量自身的特点分析。
单个变量的图示方法
单个分类变量(Categorical variables)一般可以用饼状图(pie chart)表示:
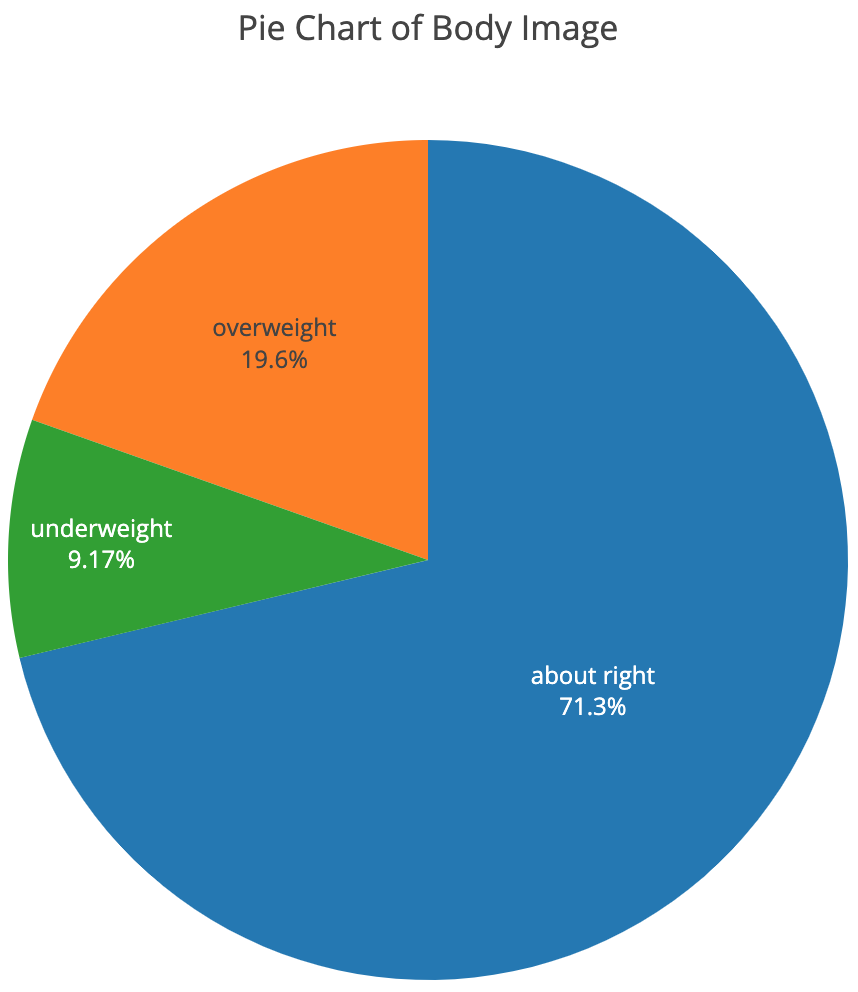
饼状图一般适合表示变量的每种取值与全局的关系。
也可以用柱状图(bar chart)来表示:

柱状图一般适合表示变量的每种取值之间的对比(柱状图Y轴的值可以从值value改为百分比percent)。
单个定量变量(Quantitative variables)一般用直方图(histogram):
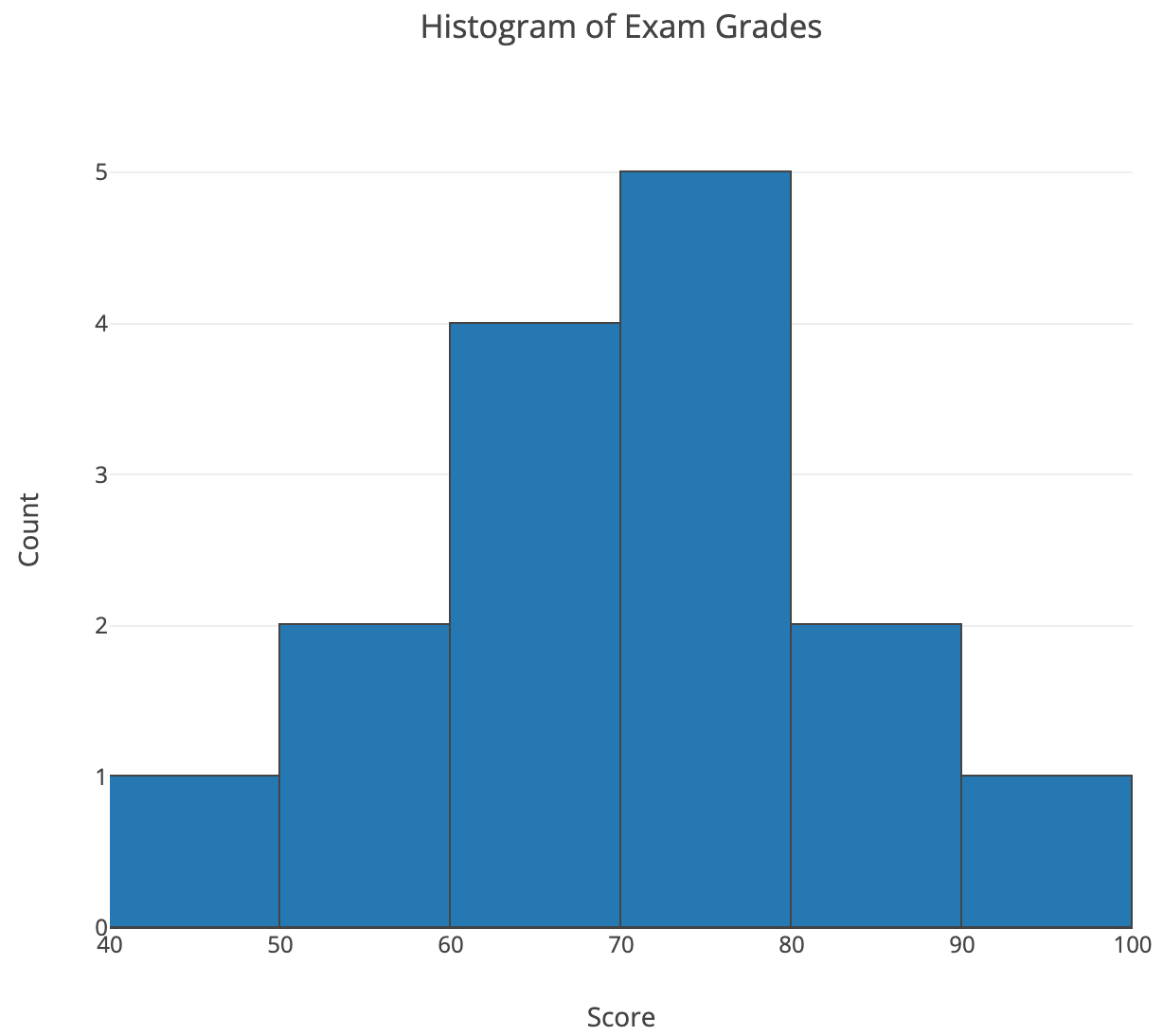
茎叶图(stemplot):

或箱线图(boxplot)表示。

下一篇就从直方图开始详细介绍对于单个连续性变量的EDA分析,包括各种术语、概念的方法论。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号