
字符串模式匹配算法系列(一):BF算法
算法背景:
BF(Brute Force)算法,是一种在字符串匹配的算法中,比较符合人类自然思维方式的方法,即对源字符串和目标字符串逐个字符地进行比较,直到在源字符串中找到完全与目标字符串匹配的子字符串,或者遍历到最后发现找不到能匹配的子字符串。算法思路很简单,但也很暴力。
算法原理:
假设源字符串为“非常地非常地非常地喜欢你”,我们想从中寻找目标字符串“非常地非常地喜欢”,则BF算法的过程可以表述如下:
第1轮:将源字符串和目标字符串对齐,并下标0开始逐个向后比较每个字符。结果发现双方的第1个字符都是“非”、第2个字符都是“常”、……,但到了第7个字符时发现不一致:源字符串为“非”、目标字符串为“喜”,因此这一轮匹配不成功。
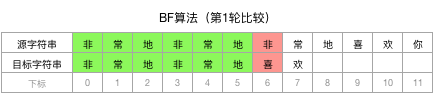
第2轮:将目标字符串整体向后移动1个字符的位置(即将目标字符串的第1个字符与源字符串的第2个字符对齐),并开始逐个向后比较每个字符,结果发现两个字符串的第1个字符就不一致,因此这一轮匹配也不成功。
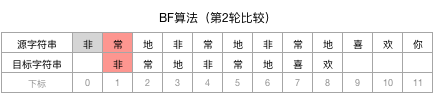
第3轮:类似地,将目标字符串整体向后移动1个字符的位置(即将目标字符串的第1个字符与源字符串的第3个字符对齐),并开始逐个向后比较,结果发现两个字符串的第1个字符就不一致,因此这一轮匹配也不成功。
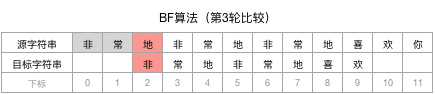
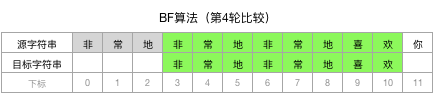
第4轮:这一轮终于发现,目标字符串的每个字符都能和源字符串对应起来,匹配成功!因此算法结束并根据需要返回相应的信息(比如返回这一轮源字符串遍历起始点的位置下标3)
算法实现:
BF算法的python实现如下:
1 #!/usr/bin/env python 2 #-*- coding: utf-8 -*- 3 import sys 4 import pdb 5 6 reload(sys) 7 sys.setdefaultencoding('utf-8') 8 9 10 class BruteForce(object): 11 """BF算法 12 成员变量: 13 str_s: 源字符串 14 str_t: 目标字符串 15 """ 16 def __init__(self, str_s, str_t): 17 self.str_s = str_s 18 self.str_t = str_t 19 20 def run(self): 21 """完全匹配则返回源字符串匹配成功的起始点的下标,否则返回-1 22 """ 23 base = 0 # 记录源字符串与目标字符串对齐的基准点 24 len_s = len(self.str_s) 25 len_t = len(self.str_t) 26 27 while base + len_t <= len_s: 28 step = 0 29 while step < len_t: 30 if str_t[step] == self.str_s[base + step]: 31 # 当前字符相同,则继续比较下一个字符 32 step += 1 33 continue 34 # 当前字符不相同,则结束次轮比较,更新base基准位置,启动下一轮比较 35 base += 1 36 break 37 # 完全匹配成功,算法结论,返回匹配成功的基准点位置下标 38 if step == len_t: 39 return base 40 # 遍历了所有情况,最终匹配失败,返回-1 41 return -1 42 43 44 if __name__ == '__main__': 45 str_s = u"非常地非常地非常地喜欢你" 46 str_t = u"非常地非常地喜欢" 47 model = BruteForce(str_s, str_t) 48 print model.run()
复杂度分析:
时间复杂度:
假设源字符串长度为m,目标字符串长度为n,则:
最好情况下是第一轮就成功匹配,则时间复杂度为O(n);
最坏情况下是遍历到最后才成功匹配,或者遍历到最后发现匹配不成功,则时间复杂度为O(n*(m-n+1)),一般实际使用时m >> n,所以可以认为趋近于O(m*n);
空间复杂度:
由于不需要额外的存储空间,所以空间复杂度为O(1)
算法评估:
整个算法其实就循环执行如下两个步骤:
一、从每一轮的基准点开始比较两个字符串;
二、如发现不能完全匹配目标字符串,将目标字符串向后挪动一个字符的位置(即更新基准点);
如果想优化算法性能,那就简单分析一下:
步骤一基本没有优化的空间:两个字符串比较就是需要从前向后逐个字符看是否匹配;
步骤二可能有优化的空间:每轮发现不匹配时,目标字符串只能向后挪动一个字符的距离,所以会想到能否多往后挪动几个字符的距离?这样不就减少了步骤一比较的轮次数,从而加快速度了吗?这基本就是KMP算法的思路,下一篇《KMP算法》会详细介绍。
