
c++从office word的xml源文本文件中提取空行后的首个段落
背单词时将难记单词的词源整理到了一个word文档中,按字典序排好了顺序,每个单词之间用空行隔开。
由于记录的单词越来越多,手动维护(查找)新的生词要插入的位置越来越费力(词汇量大,难以统计已被记录的生词;词源解释中包含大量无关单词,难以通过crtl+f查找立即定位想要的前缀)。
就想着写一个程序,从已有的word文件中预处理出已记录的单词的列表,存储在txt文件中,方便日后直接通过该txt文件查找插入位置。
——————————————————————————————————————————————————————————————————
准备工作1:确定要提取的文本
——————————————————————————————————————————————————————————————————
记录词源的word文档如图:


记录时有意识地让每个单词间隔了个空行(万幸);单词释义和词源之间也通过换行符分割开来。(如果有意识地记录加入了哪些单词就不用这么费事了)
容易看出单词内部没有空行(段),不同单词之间一定有空行(段)。
容易想到只需要处理出所有空行(段)后面的第一段(非空)就可以了。
————————
准备工作2:观察word文档的xml文本文件。
————————
将word文档用压缩文件打开。
找到记录文本的document.xml文件。
通过记事本打开可以发现,正片文档只有两行,无需处理空行。
第一行:
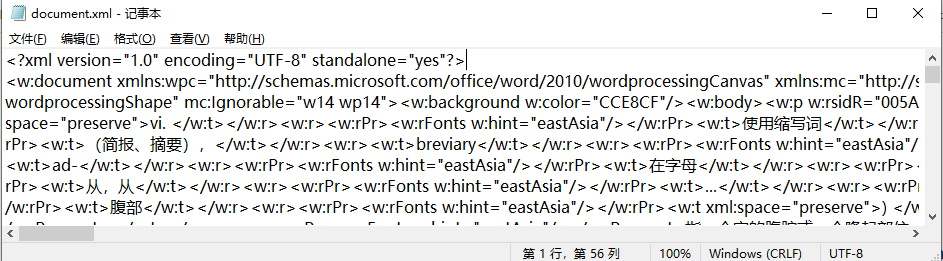
第二行:

通过浏览器打开该xml文件,可以清晰地看出目录结构。

之前听说过xml文件是由大量标签构成的标记语言,每个标签的作用及语法无需细究,能看出和html语言类似的地方(指 body 标签和段落标签。(<w:p></w:p>标签标记了一个段落))
对照word文件和xml文件容易发现空行(段落)的几种主要形式:
1.形如<w:p />。
//形如 <w:p />
<w:p w:rsidR="00D53387" w:rsidRDefault="00D53387"/>

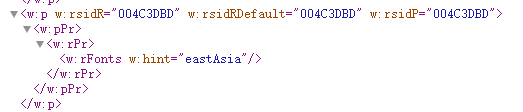
2.只含标签的空段落。
//只含标签的空段落
<w:p w:rsidR="004C3DBD" w:rsidRDefault="004C3DBD" w:rsidP="004C3DBD">
<w:pPr>
<w:rPr>
<w:rFonts w:hint="eastAsia"/>
</w:rPr>
</w:pPr>
</w:p>
3.暂时没找到。
——————————————————————
文本被<w:t></w:t>标签包围,同段文本在同样的<w:p></w:p>标签之间。

准备工作结束
可以看出,只要定位出空段落的位置,再从接下来的段落中提取出文本就可以了。
——————————————————————
——————————————————————
主要思路:
1,所有空行(段落)都由"<w:p"开头,读到"<w:p"时进行空行(段落)判定。
1)读完一个标签时,如果末尾由"/>"结尾,可判定为空行。
2)不满足1)时,如果由"<w:p "开头,则对整段进行判定,读取到"</w:p>"为止,只含标签,则判定为空行。
2,判定为空行时文件指针已经移动到下一段开头,直接在下一段内(下一个</w:p>标签前)寻找<w:t></w:t>标签,打印其中内容。
细节优化:
1、连续空行且出现不同空行形式时,可能会出现无输出的情况,如图所示。在打印文本时需要设置flag=1,在有文本输出时将其置为0,否则不断循环(防止遇到空段结束直接跳出)。

一个简单的小模拟,我的实现也不是最优的,就写到这里。
下面是代码。
#include<stdio.h> #include<algorithm> #include<string.h> #include<stdlib.h> const int maxn = 1e5+5; int tx[maxn+5]; //向后移动文件指针 inline int moven(int num, FILE* now) { int chn; while((chn = getc(now)) != EOF && (--num)); return chn; } // make array for lable //full <W:P> has been saved int r_lable(FILE *now) { int cnt = 0; while((tx[++cnt] = getc(now)) != EOF){ if(tx[cnt] == '>') break; } return cnt; } //read </w:p> after reading <w:p> bool is_emptwp(FILE * now) { int chn; while((chn = getc(now)) != EOF) { if(chn == '<'){ chn = getc(now); //second if(chn == '/'){ chn = moven(3, now); if(chn == 'p'){ chn = getc(now); if(chn == '>') return 1; } } //move while(chn != '>' && (chn = getc(now)) != EOF); } else return 0; } return 0; } inline bool is_readwp(int len, FILE *now) { //<w:p /> || empty<w:p></w:p> return tx[len-1] == '/' || is_emptwp(now); } //find next <w:t></w:t> int match_t(FILE * now, FILE * outn){ int chn, flag = 1; while((chn = getc(now)) != EOF){ if(chn == '<'){ chn = getc(now); if(chn == '/'){ chn = moven(3, now); if(chn == 'p') { chn = getc(now); if(chn == '>') return flag; } } else { chn = moven(2, now); if(chn == 't'){ chn = getc(now); if(chn != 'a'){ while(chn != '>' && (chn = getc(now)) != EOF); while((chn = getc(now)) != EOF && chn != '<') { putc(chn, outn); flag = 0; }; } } } } } return 0; } int main() { int chr, chw; FILE *in, *out; // char n_read[55], n_out[55]; in = fopen("document.xml", "r"); out = fopen("base.txt", "r+"); //locate body while((chr = getc(in)) != EOF){ if(chr == '<'){ chr = moven(3, in); if(chr == 'b') break; else continue; } } //locate <w:p /> while((chr = getc(in)) != EOF){ if(chr == '<'){ chr = moven(3, in); if(chr == 'p'){ chr = getc(in); if(chr == ' ') { int len = r_lable(in); if(is_readwp(len, in)){ while(match_t(in, out)); putc('\n', out); } } //if match <w:p /> go match <w:t></w:t> } } } fclose(in); fclose(out); return 0; } /* 提取<w:t></w:t>间的字符 定位空行<w:p />后的段落 读取空行后 读取一段 */
成果如图:
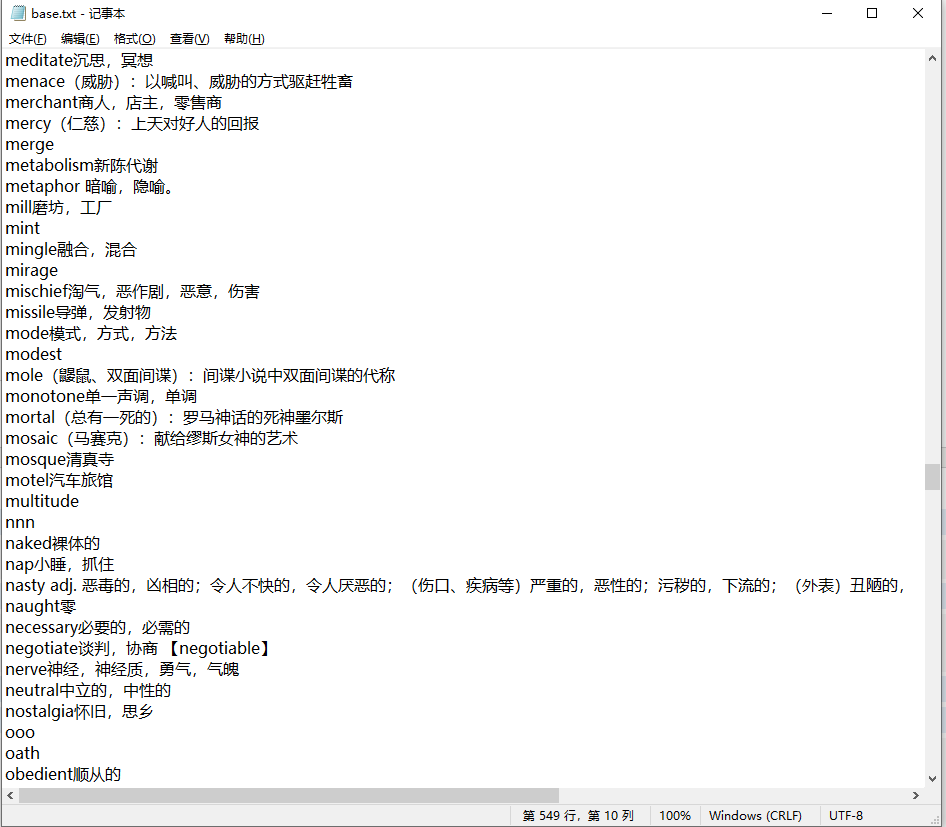
有了这个再跑kmp,二分或者后缀自动机就方便了(
