
论文笔记——Rethinking the Inception Architecture for Computer Vision
1. 论文思想
- factorized convolutions and aggressive regularization.
- 本文给出了一些网络设计的技巧。
2. 结果
- 用5G的计算量和25M的参数。With an ensemble of 4 models and multi-crop evaluation, we report 3.5% top-5 error and 17.3% top-1 error.
3. Introduction
- scaling up convolution network in efficient ways.
4. General Design Principles
-
Avoid representational bottlenecks, especially early in the network.(简单说就是feature map的大小要慢慢的减小。)
-
Higher dimensional representations are easier to process locally within a network. Increasing the activations per tile in a convolutional network allows for more disentangled features. The resulting networks will train faster.(在网络较深层应该利用更多的feature map,有利于容纳更多的分解特征。这样可以加速训练)
-
Spatial aggregation can be done over lower dimensional embeddings without much or any loss in representational power.(也就是bottleneck layer的设计)
-
Balance the width and depth of the network.(Increasing both the width and the depth of the network can contribute to higher quality networks.同时增加网络的深度和宽度)
5. Factorizing Convolution With Large Filter Size
- 分解较大filter size的卷积。
5.1. Factorization into smaller convolutions
- 一个5x5的卷积可以分解为两个3x3的卷积。
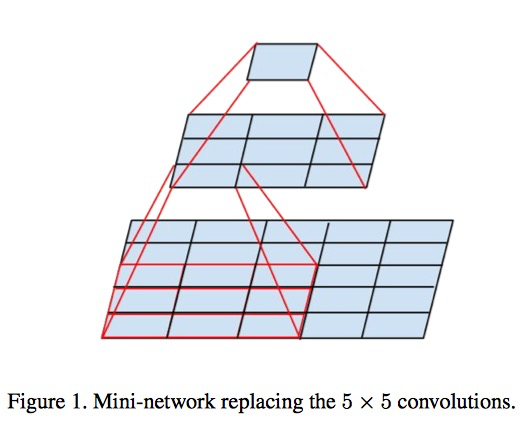
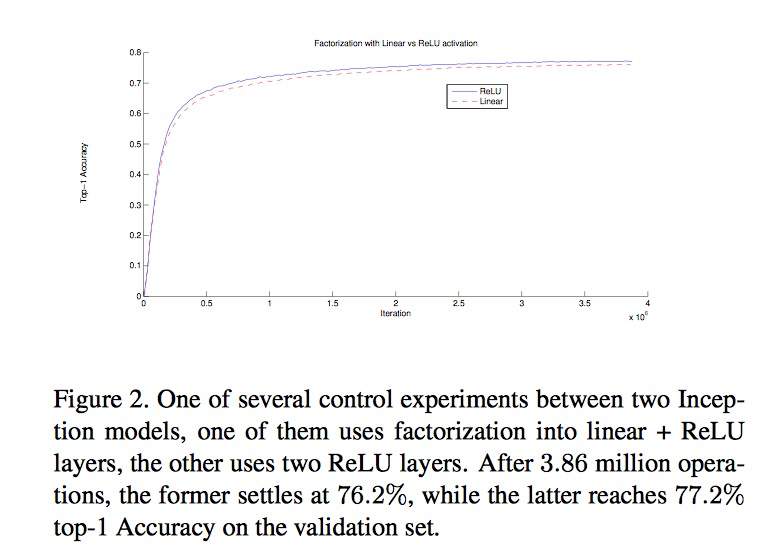
- 实验表明,将一个卷积分解为两个卷积的时候,在第一个卷积之后利用ReLU会提升准确率。也就是说线性分解性能会差一些。
5.2 Spatial Factorization into Asymmetric Convolutions

- 将3x3的卷积分解成31和13的卷积,可以减少33%计算量,如果将3x3分解为两个2x2,可以减少11%计算量,而且利用非对称卷积的效果还更好。
- 实践表明,不要过早的使用这种分解操作,在feature map 大小为(12 ~ 20)之间,使用它,效果是比较好的。
6. Utility of Auxiliary Classifier
7. Efficient Grid Size Reduction
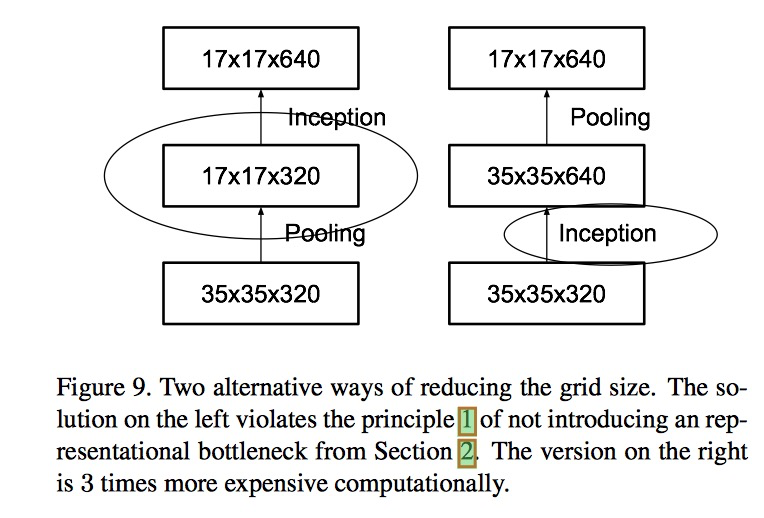
- 左边引入了 representational bottleneck,右边的会增加大量的计算量,最佳的做法就是减少feature map大小的同时增大channel的数目。

- 以上才是正确的方式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号