

论文笔记——Data-free Parameter Pruning for Deep Neural Networks
论文地址:https://arxiv.org/abs/1507.06149
1. 主要思想
权值矩阵对应的两列i,j,如果差异很小或者说没有差异的话,就把j列与i列上(合并,也就是去掉j列),然后在下一层中把第j行的权值累加在第i像。 这个过程就想象一下隐藏层中少一个单元,对权值矩阵的影响。 整体思想还是考虑权值矩阵中列的相似性,有点类似于聚类。 然后作者给出了一种计算相似性的方法。
2. 原理
假设一个隐藏层,一个输出单元,那么网络表达式如下:
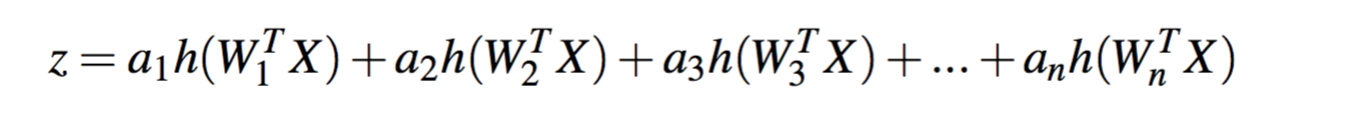
我们可以看到下面这个图:如果两个权值集合W1和W4相等或者相差不大的话,我们可以合并W1和W4,然后累加输出的权值。也就说下图对应两个权值矩阵,在第一个权值矩阵中,删除第4列,然后在第二个权值矩阵中将第四行累加在第一行上。
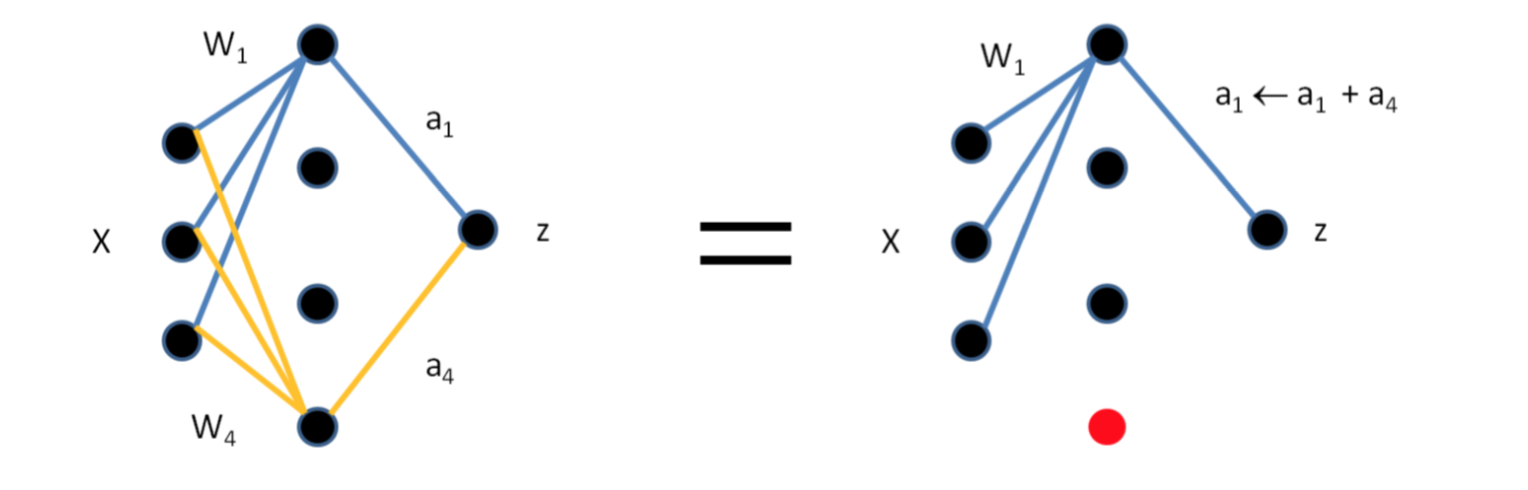
但是有一个问题就是,权值完全相等的可能比较少或者没有,那么我们就把条件放宽,差异比较小的,那么怎么衡量呢。请看下面的分析。
3. 相似条件
如果Wi和Wj相等,那么两个输出的误差为:
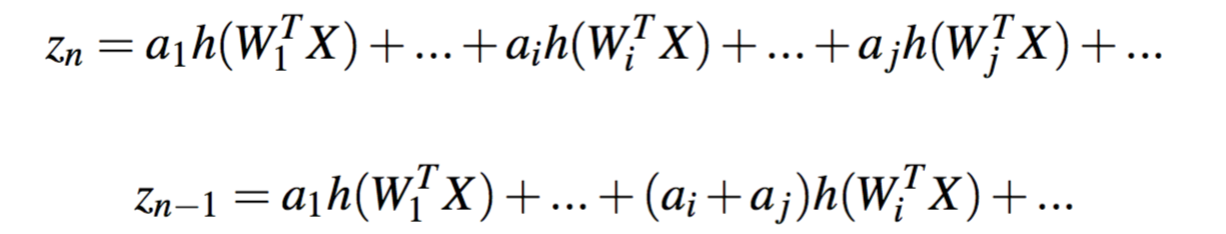
进一步化简,然后两边求期望可以得到以下:
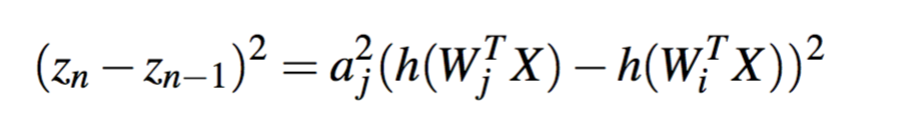
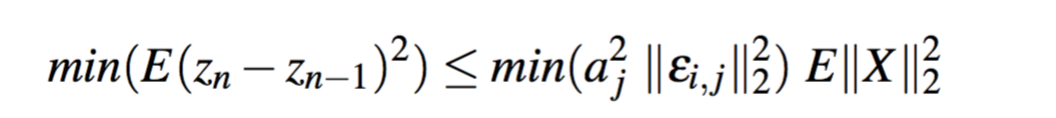
那么我们可以得到判断是否可以合并的条件:
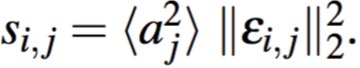
解释就是:如果两列权值的差异较少,且aj作为下一层的输入权值不大,那么就可以将i,j合并。
4. 合并过程

5. 结果
MNIST上85%的压缩,AlexNet上35%的压缩。这篇文章的可解释性还是很强的,但是可能效果没有这么的好,所以发在了BMVC上吧。

