

论文笔记——DenseNet
《Densely Connected Convolutional Networks》阅读笔记
代码地址:https://github.com/liuzhuang13/DenseNet
首先看一张图:
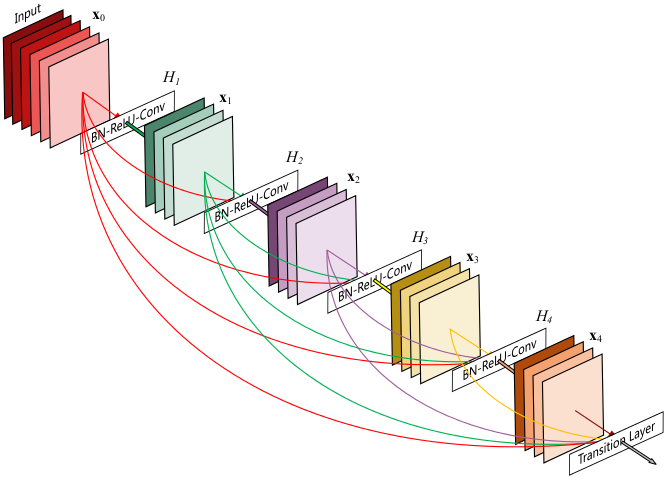
稠密连接:每层以之前层的输出为输入,对于有L层的传统网络,一共有L个连接,对于DenseNet,则有L(L+1)2。
这篇论文主要参考了Highway Networks,Residual Networks (ResNets)以及GoogLeNet,通过加深网络结构,提升分类结果。加深网络结构首先需要解决的是梯度消失问题,解决方案是:尽量缩短前层和后层之间的连接。比如上图中,H4层可以直接用到原始输入信息X0,同时还用到了之前层对X0处理后的信息,这样能够最大化信息的流动。反向传播过程中,X0的梯度信息包含了损失函数直接对X0的导数,有利于梯度传播。
DenseNet有如下优点:
1.有效解决梯度消失问题
2.强化特征传播
3.支持特征重用
4.大幅度减少参数数量
接着说下论文中一直提到的Identity function:
很简单 就是输出等于输入f(x)=x
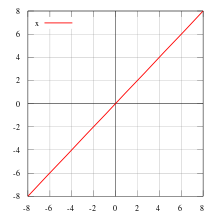
传统的前馈网络结构可以看成处理网络状态(特征图?)的算法,状态从层之间传递,每个层从之前层读入状态,然后写入之后层,可能会改变状态,也会保持传递不变的信息。ResNet是通过Identity transformations来明确传递这种不变信息。
网络结构:

每层实现了一组非线性变换Hl(.),可以是Batch Normalization (BN) ,rectified linear units (ReLU) , Pooling , or Convolution (Conv). 第l层的输出为xl。
对于ResNet:
xl=Hl(xl−1)+xl−1
这样做的好处是the gradient flows directly through the identity function from later layers to the earlier layers.
同时呢,由于identity function 和 H的输出通过相加的方式结合,会妨碍信息在整个网络的传播。
受GooLeNet的启发,DenseNet通过串联的方式结合:
xl=Hl([x0,x1,...,xl−1])
这里Hl(.)是一个Composite function,是三个操作的组合:BN−>ReLU−>Conv(3×3)
由于串联操作要求特征图x0,x1,...,xl−1大小一致,而Pooling操作会改变特征图的大小,又不可或缺,于是就有了上图中的分块想法,其实这个想法类似于VGG模型中的“卷积栈”的做法。论文中称每个块为DenseBlock。每个DenseBlock的之间层称为transition layers,由BN−>Conv(1×1)−>averagePooling(2×2)组成。
Growth rate:由于每个层的输入是所有之前层输出的连接,因此每个层的输出不需要像传统网络一样多。这里Hl(.)的输出的特征图的数量都为k,k即为Growth Rate,用来控制网络的“宽度”(特征图的通道数).比如说第l层有k(l−1)+k0的输入特征图,k0是输入图片的通道数。
虽然说每个层只产生k个输出,但是后面层的输入依然会很多,因此引入了Bottleneck layers 。本质上是引入1x1的卷积层来减少输入的数量,Hl的具体表示如下
BN−>ReLU−>Conv(1×1)−>BN−>ReLU−>Conv(3×3)
文中将带有Bottleneck layers的网络结构称为DenseNet-B。
除了在DenseBlock内部减少特征图的数量,还可以在transition layers中来进一步Compression。如果一个DenseNet有m个特征图的输出,则transition layer产生 ⌊θm⌋个输出,其中0<θ≤1。对于含有该操作的网络结构称为DenseNet-C。
同时包含Bottleneck layer和Compression的网络结构为DenseNet-BC。
具体的网络结构:
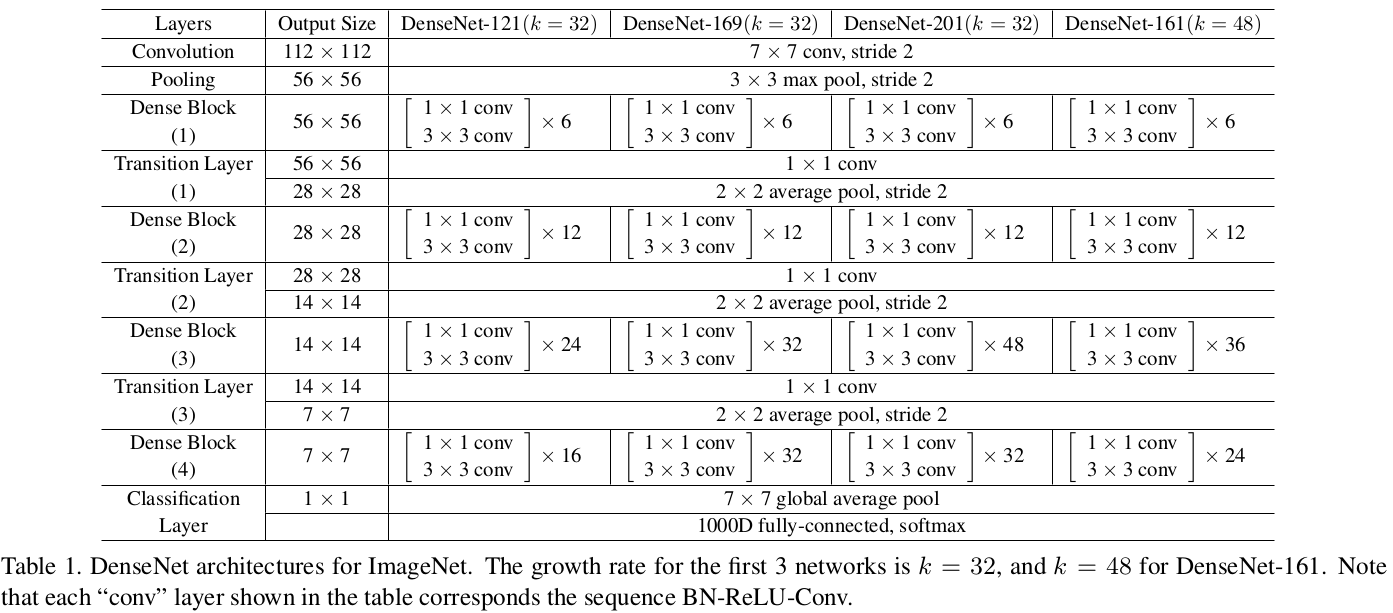
实验以及一些结论
在CIFAR和SVHN上的分类结果(错误率):
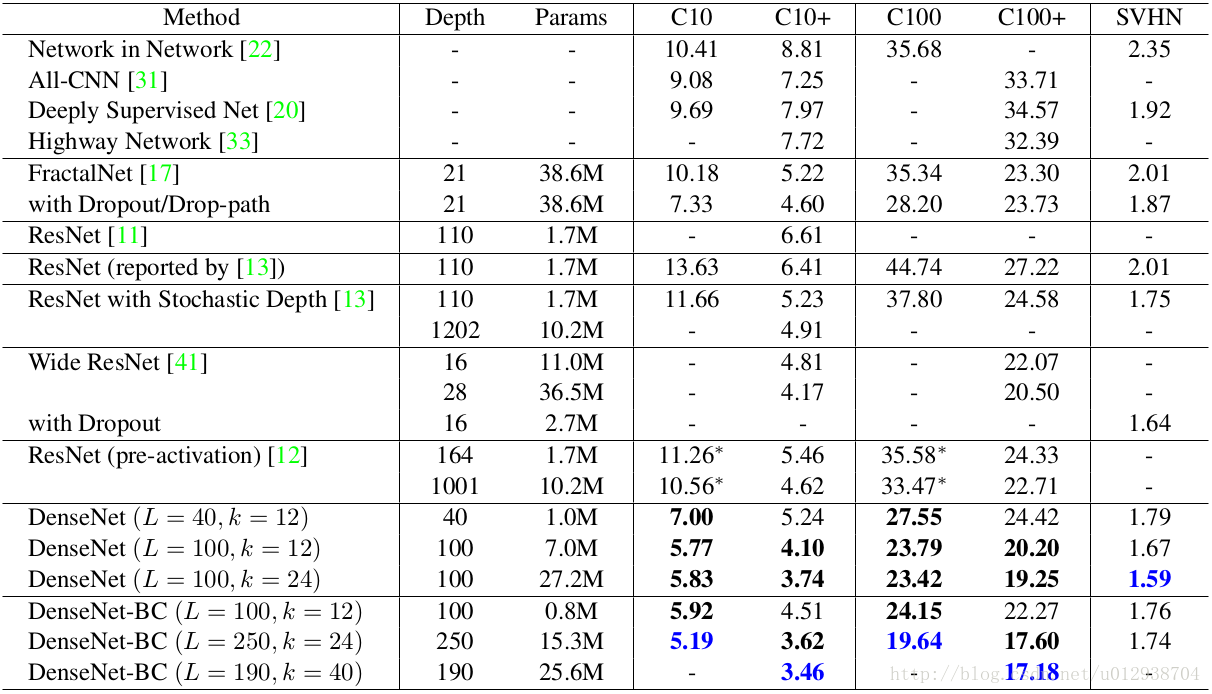
L表示网络深度,k为增长率。蓝色字体表示最优结果,+表示对原数据库进行data augmentation。可以发现DenseNet相比ResNet可以取得更低的错误率,并且使用了更少的参数。
接着看一组对比图:
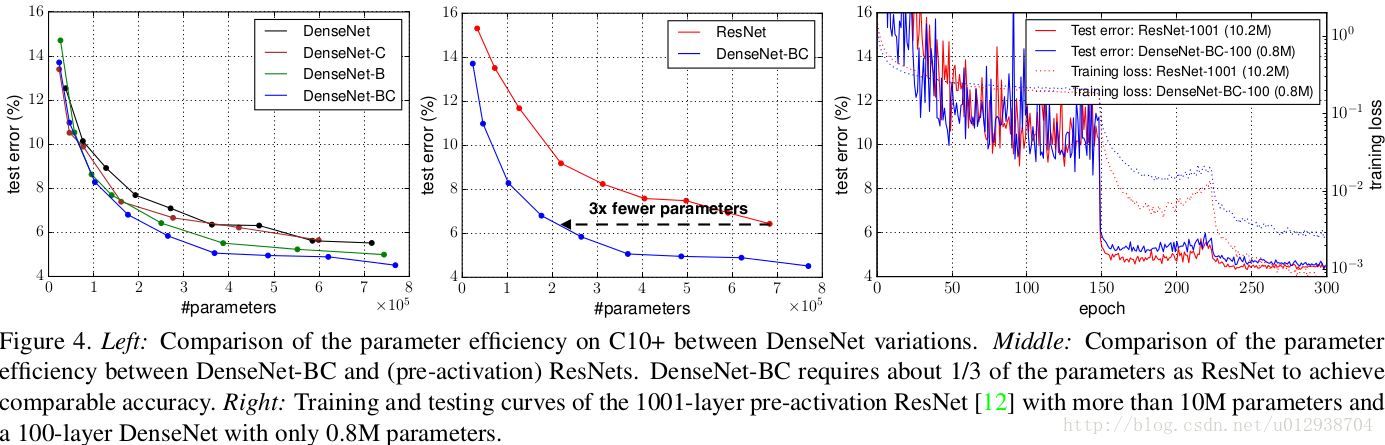
前两组描述分类错误率与参数量的对比,从第二幅可以看出,在取得相同分类精度的情况下,DenseNet-BC比ResNet少了23的参数。第三幅图描述含有10M参数的1001层的ResNet与只有0.8M的100层的DenseNet的训练曲线图。可以发现ResNet可以收敛到更小的loss值,但是最终的test error与DenseNet相差无几。再次说明了DenseNet参数效率(Parameter Efficiency)很高!
同样的在ImageNet上的分类结果:
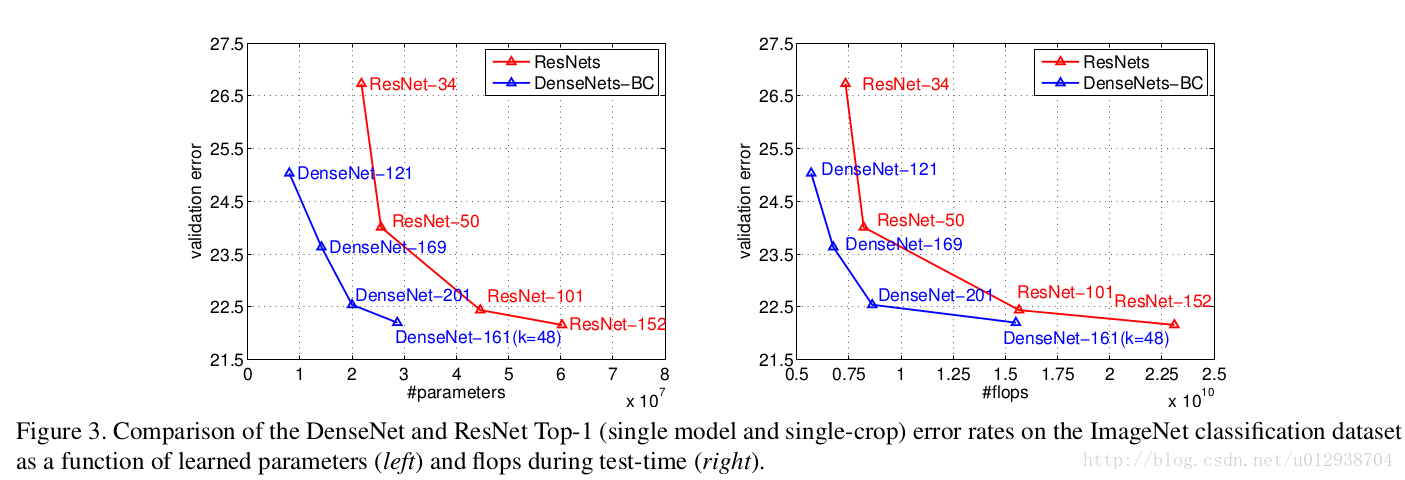
右图使用FLOPS来说明计算量。通过比较ResNet-50,DenseNet-201,ResNet-101,说明计算量方面,DenseNet结果更好。

