
openstack octavia的实现与分析(一)
openstack负载均衡的现状与发展以及lvs,Nginx,Haproxy三种负载均衡机制的基本架构和对比
【负载均衡】
大量用户发起请求的情况下,服务器负载过高,导致部分请求无法被响应或者及时响应。
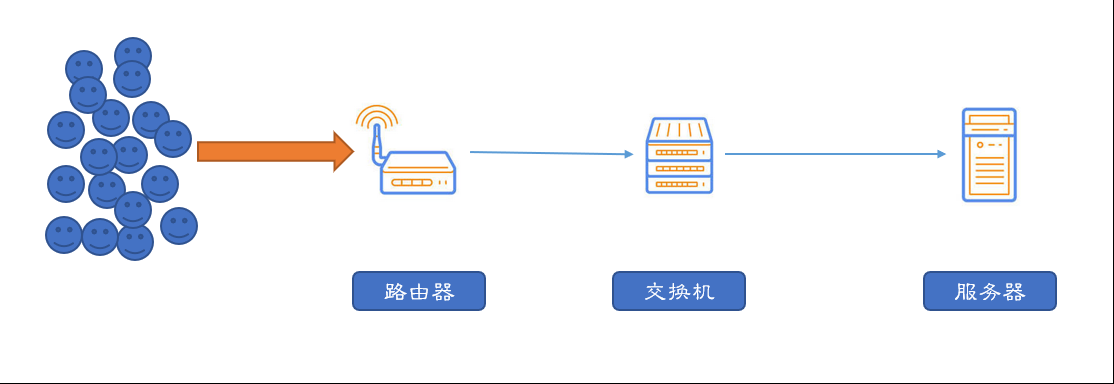
负载均衡根据一定的算法将请求分发到不同的后端,保证所有的请求都可以被正常的下发并返回。
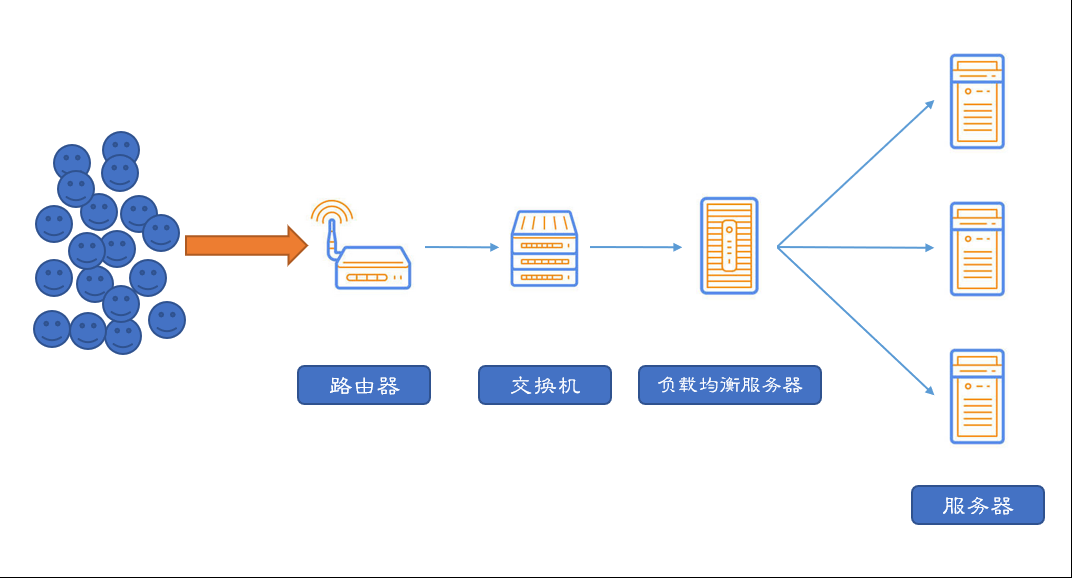
【主流实现-LVS】
LVS 是 Linux Virtual Server 的简称,也就是 Linux 虚拟服务器,已经是 Linux 标准内核的一部分。
采用IP负载均衡技术和基于内容请求分发。
调度器具有很好的吞吐率,将请求均衡得转移到不同的服务器上执行,且调度器可以自动屏蔽掉故障的服务器,从而将一组服务器构成一个高可用,高性能的服务器集群。

*负载均衡机制
1. LVS是四层负载均衡,也就是说在传输层上,LVS支持TCP/UDP。由于是四层负载均衡,所以相对于其他的高层负载均衡而言,对于DNS域名轮流解析,应用层负载的调度,客户端的调度等,它的效率是相对较高的。
2. 四层负载均衡,主要通过报文的目标地址和端口。(七层负载均衡又称为"内容交换",主要是通过报文中真正有意义的应用层内容)
3. LVS的转发主要通过修改IP地址(NAT模式,包括SNAT和DNAT),修改目标MAC(DR模式)来实现。
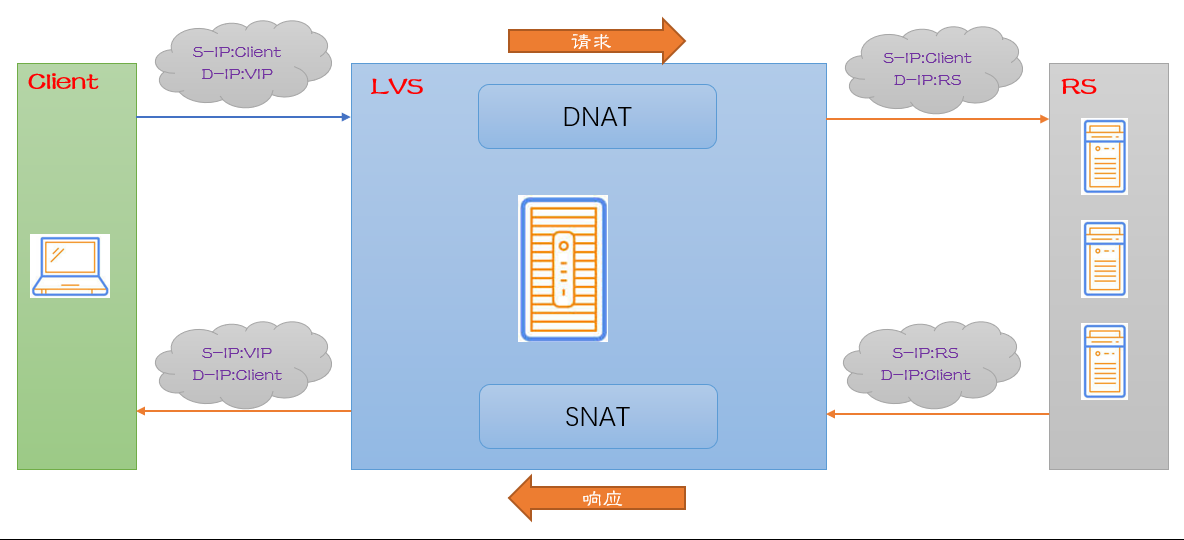
*负载均衡模式-NAT模式
NAT(Network Address Translation)是一种外网和内网地址映射的技术。
NAT模式下,网络数据包的进出都要经过LVS的处理。LVS需要作为RS(真实服务器)的网关。
当包从Client到达LVS时,LVS做DNAT(目标地址转换),将D-IP(目的地址)改变为RS的IP。
RS处理完成,将包返回的时候,S-IP(源地址)是RS,D-IP是Client的IP。
到达LVS做网关中转时,LVS会做SNAT(源地址转换),将包的S-IP改为VIP。
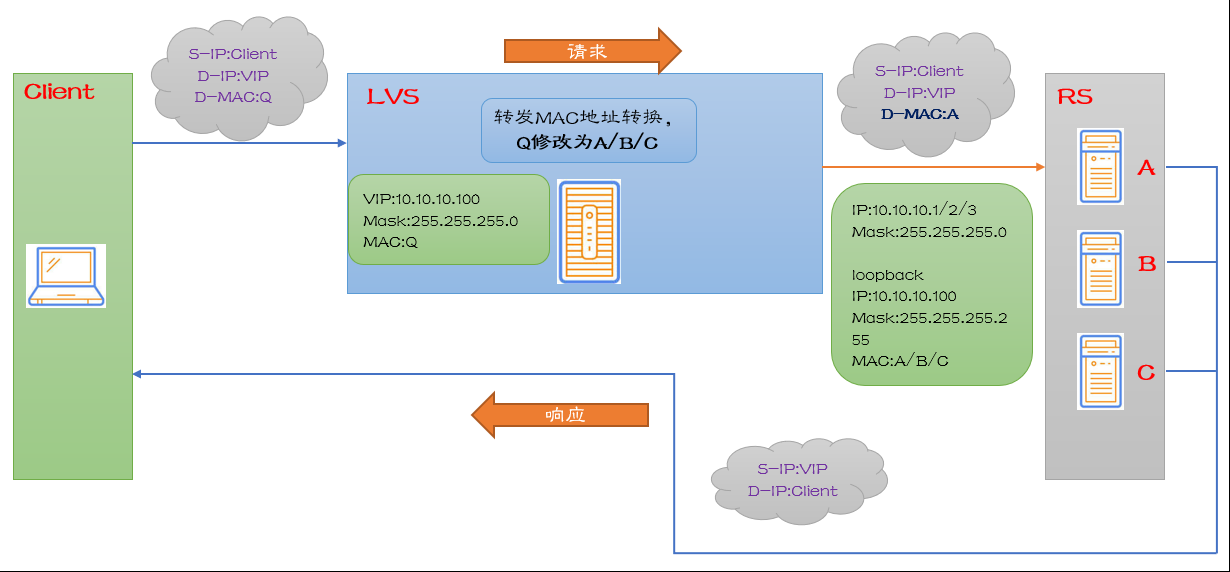
*负载均衡模式-DR模式
DR(直接路由)模式下需要LVS和RS绑定同一个集群(RS通过将VIP绑定在loopback实现)。
请求由LVS接受,返回的时候由RS直接返回给Client。
当包到LVS的时候,LVS将网络帧的MAC地址修改为某台RS的MAC,此包会被转发到对应的RS上面进行处理。
此时S-IP和D-IP都没有发生改变。
RS收到LVS转发的包时,链路层发现MAC地址是自己的,网络层发现IP地址也是自己的,于是包被合法接受,RS不感知LVS。
当包返回时,RS直接返回给Client,不再经过LVS。
它要维护从一个目标IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP地址到一台服务器的映射。
在LBLC算法里面,某些热门站点报文较多,可能服务器很快会达到饱和,然后切换到第二台又会很快达到饱和,然后后端服务器就一直在切换,造成资源不必要的浪费。
LCLBR里面,单个服务器变成了一组服务器,就会有效避免这种情况。
7. 目标地址散列
8. 源地址散列
*LVS的优点
1. 抗负载能力强,由于工作在传输层上,只做分发,无流量产生,所以它在所有的负载均衡里面性能是最强的,对内存和CPU的消耗也比较低。
2. 配置性较低,减少人为出错的概率,但是也相应减少了人为自主性。
3. 工作稳定,自身有完整的双机热备方案,如:LVS + Keepalived
4. 无流量,保证IO不会受到影响。
*LVS的缺点
1. 软件本身不支持正则表达式处理,不能做动静分离。
2. 网站应用比较庞大的时候,LVS/DR+Keepalive实施较为复杂。
【主流实现-Nginx】
Nginx是一个很强大的高性能Web和反向代理服务器。
最大的优势在于高负载情况下对内存和CPU的低消耗。
在高并发的情况下,Nginx是Apache服务器不错的替代品。
*传统基于进程或线程的模型
传统基于进程或线程的模型(如Apache)在处理并发时会为每一个连接建立一个单独的进程或线程。这种方法会在网络传输或者I/O操作上阻塞。
对于应用来讲,在内存和CPU的使用上效率都是非常低的。
而且,生成一个单独的进程/线程还需要为其准备新的运行环境(主要包括分配堆栈内存),以及上下文执行环境。
创建这些都消耗额外的CPU时间,这最终也会因为线程上下文来回切换导致性能非常差。
*Nginx架构设计
Nginx的架构设计是采用模块化的,基于事件驱动,异步,单线程且非阻塞。
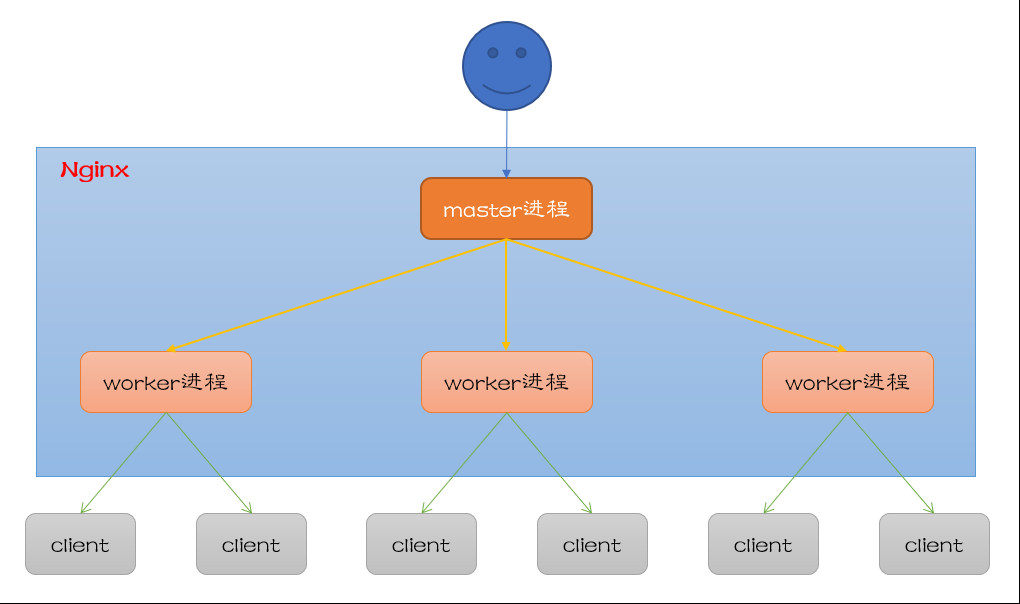
Nginx大量使用多路复用和事件通知,nginx启动之后,会在系统中以 daemon(守护进程) 的方式在后台运行,包括一个master进程和多个worker进程。
所有的进程都是单线程的,进程间通信主要通过共享内存的方式。
多个连接,是通过worker进程中高效回环(run-loop)机制来处理的。对于每个worker进程来说,每秒钟可以处理上千个请求和连接。
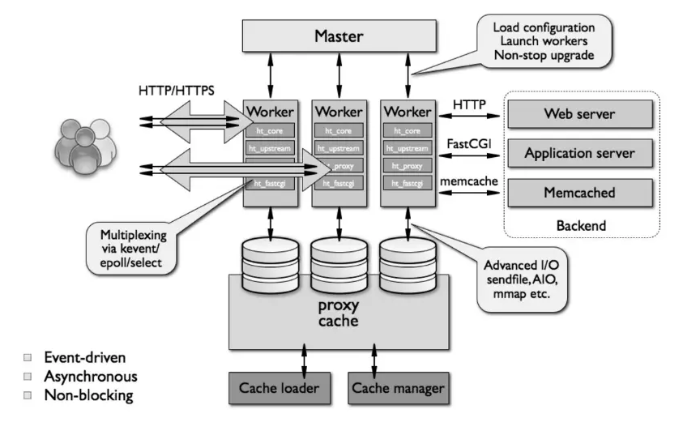
*Nginx负载均衡
Nginx 负载均衡主要针对七层的http和https,当然,四层Nginx后来也支持了(1.9.0版本增加stream模块,用来实现四层协议)。
Nginx主要是通过反向代理的方式进行负载均衡的,所谓反向代理(Reverse Proxy),指的是以代理服务器来接收 Client 请求,然后将请求转发到内部服务器,并将内部服务器处理完成的结果返回给 Client ,对外,代理服务器就是真正的服务器,内部服务器外部不感知。
Nginx支持以下几种策略:
轮询·default
weight (权重)
ip_hash (可用于解决会话保持的问题)
fair·第三方 (按后端服务器的响应时间来分配请求,响应时间短的优先分配)
url_hash·第三方 (相同的url定位到相同的服务器)
*Nginx的优势
1. 跨平台,配置简单
2. 非阻塞,高并发(官方测试可以支撑5万并发数)
3. 事件驱动,通信机制采用 epoll 模型,支持更大的并发连接
4. 内存消耗小。(3万并发数下,10个Nginx进程只需要150M内存)
5. 内置的健康检查功能。 (一台后端服务器宕机了,不会影响前端访问)
6. 节省带宽。 (支持GZIP压缩,可以添加浏览器缓存的header)
7. 稳定性高。 (反向代理,宕机的概率很小)
*Nginx的缺点
1. 对后端服务器的健康检查,只支持通过端口检测,不支持url检测。
2. 不支持Session的直接保持。(通过ip_hash可解决)
【主流实现-Haproxy】
Haproxy提供高可用性,负载均衡以及基于TCP和HTTP的代理。
特别适用于那些负载特大的Web站点,这些站点通常需要会话保持或七层处理。
Haproxy支持四层和七层两种负载模式。
Haproxy有一些Nginx不具有的优点,比如支持Session的保持,Cookie的引导;同时支持通过获取指定的URL来检测后端服务器的状态。
Haproxy和LVS类似,本身就只是一款负载均衡软件;单纯从效率上来讲,比Nginx有更好的负载均衡速度,在并发处理上也优于Nginx。
Haproxy支持的负载均衡策略也比较多:Round-robin(轮循)、Weight-round-robin(带权轮循)、source(原地址保持)、RI(请求URL)、rdp-cookie(根据cookie)。
【三种负载均衡的比较】
|
比较 |
HAProxy |
Nginx |
LVS |
|
优点 |
支持session保持,Cookie引导。
可通过url检测后端服务器健康状态。
也可做MySQL、Email等负载均衡。
支持通过指定的URL对后端服务器健康检查。 |
http、https、Emai协议功能较好,处理相应请求快。
Web能力强,配置简单,支持缓存功能、适用动静分离,低内存消耗。
支持WebSocket协议。
支持强大的正则匹配规则 。 |
通过vrrp转发(仅分发)效率高,流量通过内核处理,没有流量产生。(理论)
相当稳定可靠。
|
|
缺点 |
一般不做Web服务器的Cache。 |
不支持session直接保持,但可通过ip_hash解决。 只能通过端口对后端服务器健康检查。 |
不支持正则,不能做动静分离,配置略复杂,需要IP略多。 没有后端主机健康状态检查。 |
|
支持算法 |
目标uri hash(uri) url参数 (url_params) 请求头信息调度(hdr(name)) cookie (rdp-cookie) |
最小响应时间 自定义hash内容(hash key [consistent]) url hash 最短时间和最少连接 |
最短期望延迟(Shortest Expected Delay) 不排队(Never Queue) 基于局部性的最少连接(LBLC) 带复制的基于局部性最少链接(LCLBR) |
|
官网 |
|
||
|
虚拟主机 |
支持 |
支持 |
不支持 |
|
适用性 |
四层,七层(常用) |
四层,七层(常用) |
四层 |
|
量级 |
七层重量级,四层轻量级 |
七层重量级,四层轻量级 |
四层重量级 |
|
常用热备 |
Keepalived+其它 |
Keepalived+其它 |
Keepalived+其它 |
*补充区别
HAProxy对于后端服务器会一直做健康检测(就算请求没过来的时候也会做健康检查)
后端机器故障发生在请求还没到来的时候,haproxy会将这台故障机切掉,但如果后端机器故障发生在请求到达期间,那么前端访问会有异常。
也就是说HAProxy会把请求转到后端的这台故障机上,并经过多次探测后才会把这台机器切掉,并把请求发给其他正常的后端机,这势必会造成一小段时间内前端访问失败。
Nginx对于后端的服务器不会一直做健康检测
后端机器发生故障,在请求过来的时候,分发还是会正常进行分发,只是请求不到数据的时候,它会再转向好的后端机器进行请求,直到请求正常为止。
也就是说Nginx请求转到后端一台不成功的机器的话,还会再转向另外一台服务器,这对前端访问没有什么影响。
因此,如果有用HAProxy做为前端负载均衡的话 ,如果后端服务器要维护,在高并发的情况,肯定是会影响用户的。
但如果是Nginx做为前端负载均衡的话,只要并发撑得住,后端切掉几台不会影响到用户。
【Openstack LBaaS的现状】
Neutron中的loadbalance服务lbaas,可以将来自公网或内部网络的访问流量,分发到云资源中的云主机上,可以随时添加或者减少后端云主机的数量,而不影响业务。
lbaas在Grizzly版本集成到Neutron中。
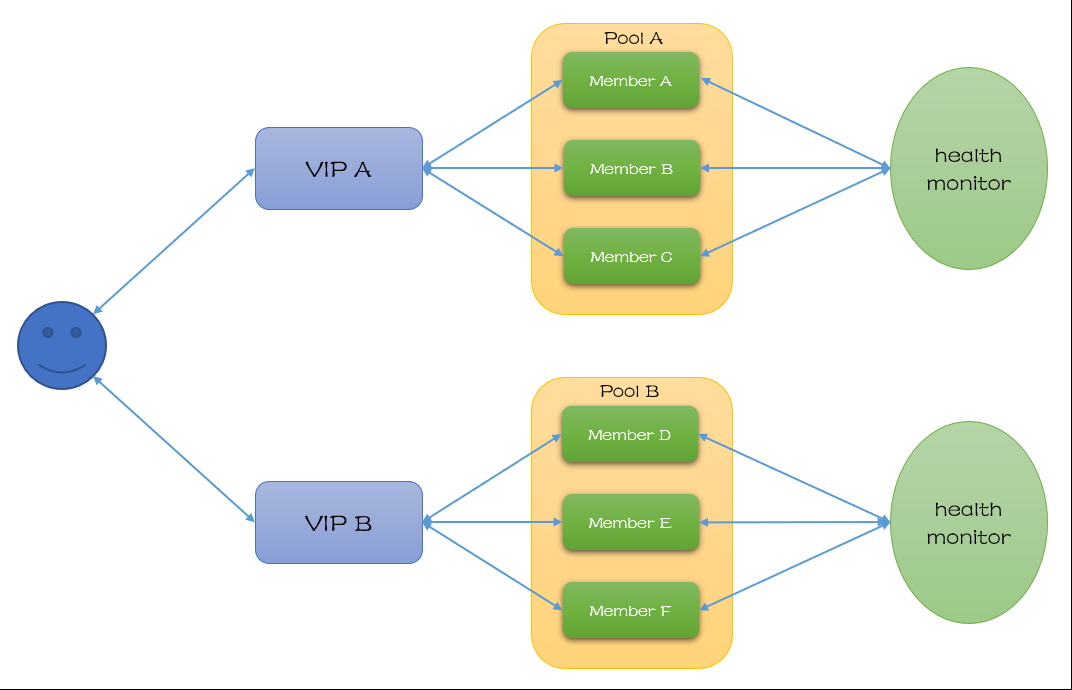
现在社区最新的API版本为V2,在Kilo中发布,包含以下概念:
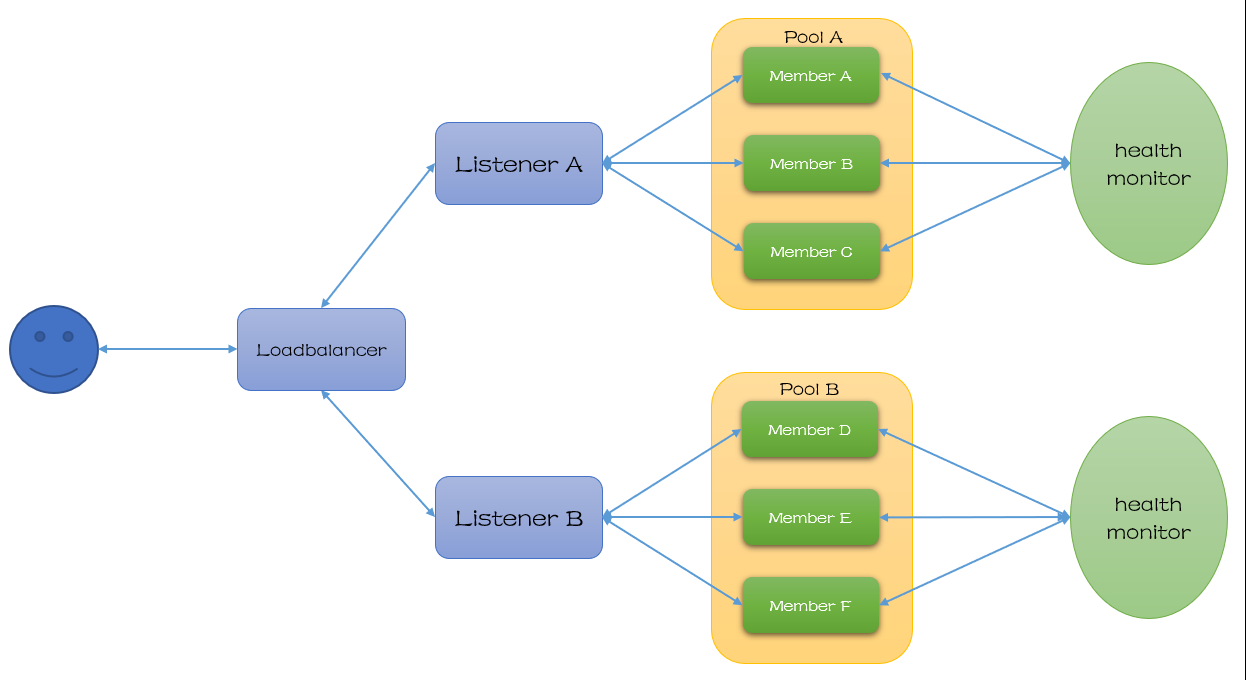
Lbaas V1与V2的区别如下:
|
功能 |
lbaas |
lbaasV2 |
|
最大连接数 |
Y |
Y |
|
TCP负载均衡 |
Y |
Y |
|
HTTP负载均衡 |
Y |
Y |
|
HTTPS负载均衡 |
Y |
Y |
|
TERMINATED_HTTPS负载均衡 |
X |
Y |
|
基于hostname的url转发 |
X |
Y |
|
基于path的url转发 |
X |
Y |
|
基于filename的url转发 |
X |
Y |
|
基于header的url转发 |
X |
Y |
|
基于cookie的url转发 |
X |
Y |
|
一个vip支持多种协议和端口 |
X |
Y |
LBaaS(Load Balancer as a Service)是 OpenStack 的网络负载均衡服务,为用户提供应用集群负载均衡解决方案。LBaaS 支持将来自公网或内部网络的应用服务访问流量按照指定的均衡策略分发到资源池内的云主机,允许用户随时增加、减少提供应用服务的云主机而不影响业务可用性,有效保障了应用服务的响应速度和高可用。
以往,LBaaS 基于 Neutron 实现,LBaaS V1 API 在 Grizzly 版本被集成到 Neutron,功能模块的代码实现在 openstack/neutron-lbaas repo,支持 Plug-In 模式,提供了 HAProxy、F5 等多种 Driver 对接底层负载均衡器。LBaaS V2 API 在 Kilo 版本发布,Liberty 版本正式支持,同期发布的还有 Octavia Plugin。历经几个版本的迭代,Octavia 在 Pike 版本成为了需要在 Keystone 上注册 endpoint 的独立项目而不再是 Neutron 的一个服务插件。现在社区也正逐渐将 openstack/neutron-lbaas repo 实现的 Driver 迁移到 openstack/octavia repo,在 Queens 版本中 neutron-lbaas 正式被标记为废弃「Neutron-lbaas is now deprecated」。
为什么废弃 neutron-lbaas 扩展项目?社区给出了详尽的说明,简单总结一下有两点原因:
neutron-lbaas 与 Neutron 项目的耦合度太高,前者会直接使用 Neutron 的代码和 DB 从而导致 LBaaS API 的性能和扩展性不佳,而且 HAProxy Plugin 的实现也不具有高可用特性。总的来说,neutron-lbaas 不适用于大规模部署场景。
Ocatvia 项目已经成熟,可以向外提供稳定的 REST API,允许用户跨版本集成和迁移。同时,完全独立的状态会使 Ocatvia 发展得更加迅速。
项目组织的变化:
| items | Old | New |
|---|---|---|
| Repo | openstack/neutron-lbaas | openstack/octavia |
| CLI | neutronclient | octaviaclient (openstackclient 的扩展) |
| Horizon panels | neutron-lbaas-dashboard | octavia-dashboard (Queens 开始支持) |
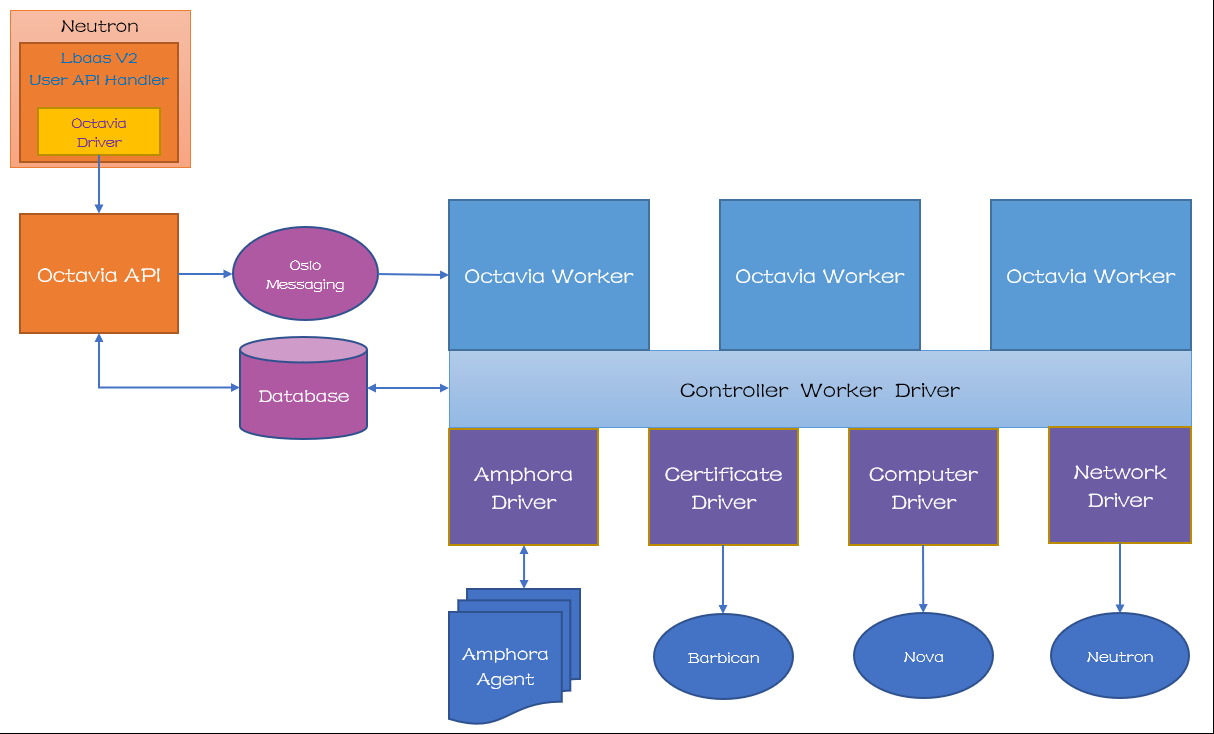
【Octavia 介绍】
Octavia当前作为lbaasV2的一个driver存在,完全兼容lbaasV2的接口,最终的发展趋势会作为一个独立的项目代替lbaasV2。
架构图如下:
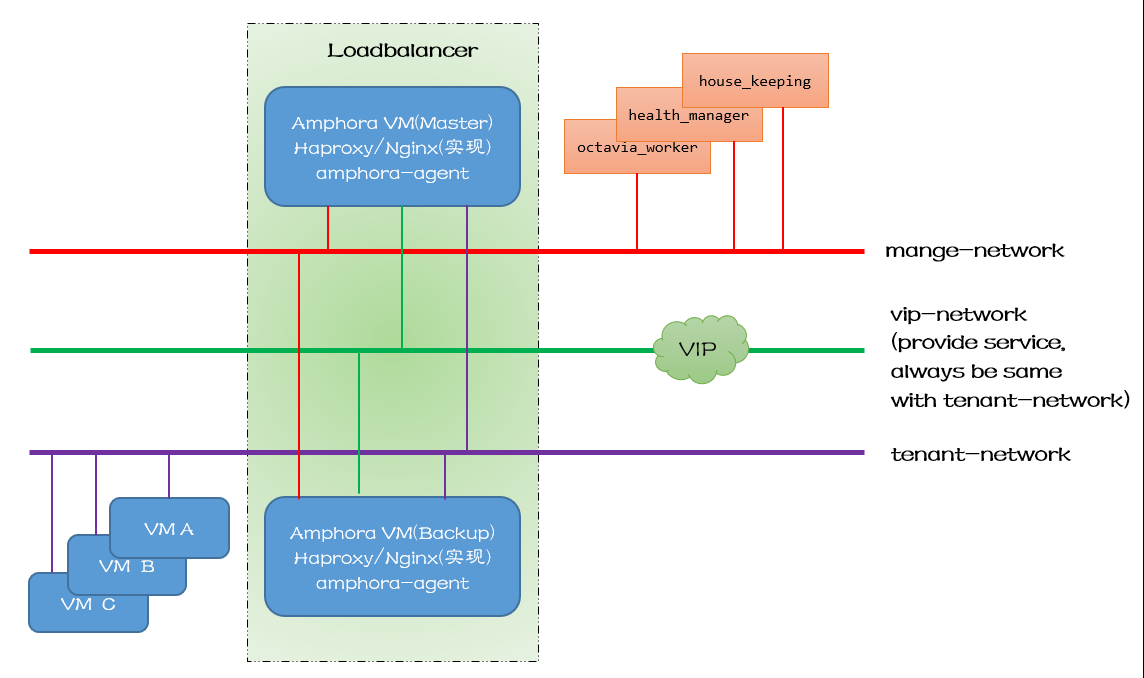
网络结构如下:
参考:https://www.cnblogs.com/liuxia912/p/11143447.html
https://blog.csdn.net/jmilk/article/details/81279795

