35.正则表达式
正则表达式概述
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为regex、regexp或RE),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。
Regular Expression的"Regular"一般被译为"正则"、"正规"、"常规"。此处的"Regular"即是"规则"、"规律"的意思,Regular Expression即"描述某种规则的表达式"之意。
核心笔记:
1、当我们完全讨论与字符串中模式有关的正则表达式时,我们会用术语 "matching"(匹配),指的是术语 pattern-matching(模式匹配)。
2、在 Python专门术语中,有两种主要方法完成模式匹配:搜索(searching)和匹配(matching)
3、搜索,即在字符串任意部分中查找匹配的模式,而匹配是指,判断一个字符串能否从起始处全部或部分的匹配某个模式
4、搜索通过 search()函数或方法来实现,而匹配是以调用 match()函数或方法实现的。
5、总之,当我们说模式的时候,我们全部使用术语“matching”(“匹配”);我们按照 Python 如何完成模式匹配的方式来区分“搜索”和“匹配”。
下图展示了使用正则表达式进行匹配的流程:
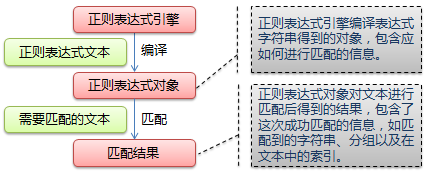
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
二、正则表达式使用的特殊符号和字符
现在,我们来介绍最常用的元字符(metacharacters)——特殊字符和符号,正是它们赋予了正则表达式强大的功能和灵活性
下面为正则表达式中常见的符号和字符
1、普通字符和11个元字符:
| 普通字符 |
匹配自身
|
abc
|
abc
|
|
.
|
匹配任意除换行符"\n"外的字符(在DOTALL模式中也能匹配换行符 |
a.c
|
abc
|
|
\
|
转义字符,使后一个字符改变原来的意思
|
a\.c;a\\c
|
a.c;a\c
|
|
*
|
匹配前一个字符0或多次
|
abc*
|
ab;abccc
|
|
+
|
匹配前一个字符1次或无限次
|
abc+
|
abc;abccc
|
|
?
|
匹配一个字符0次或1次
|
abc?
|
ab;abc
|
|
^
|
匹配字符串开头。在多行模式中匹配每一行的开头 | ^abc |
abc
|
|
$
|
匹配字符串末尾,在多行模式中匹配每一行的末尾 | abc$ |
abc
|
| | | 或。匹配|左右表达式任意一个,从左到右匹配,如果|没有包括在()中,则它的范围是整个正则表达式 |
abc|def
|
abc
def
|
| {} | {m}匹配前一个字符m次,{m,n}匹配前一个字符m至n次,若省略n,则匹配m至无限次 |
ab{1,2}c
|
abc
abbc
|
|
[]
|
字符集。对应的位置可以是字符集中任意字符。字符集中的字符可以逐个列出,也可以给出范围,如[abc]或[a-c]。[^abc]表示取反,即非abc。 所有特殊字符在字符集中都失去其原有的特殊含义。用\反斜杠转义恢复特殊字符的特殊含义。 |
a[bcd]e
|
abe
ace
ade
|
|
()
|
被括起来的表达式将作为分组,从表达式左边开始每遇到一个分组的左括号(,编号+1. 分组表达式作为一个整体,可以后接数量词。表达式中的|仅在该组中有效。 |
(abc){2} a(123|456)c |
abcabc
a456c
|
2、预定义字符集(可以写在字符集[...]中)
|
\d
|
匹配任何数字:[0-9] |
a\bc
|
a1c
|
|
\D
|
非数字:[^\d] |
a\Dc
|
abc
|
|
\s
|
匹配任何空白字符:[<空格>\t\r\n\f\v] |
a\sc
|
a c
|
| \S | 非空白字符:[^\s] |
a\Sc
|
abc
|
|
\w
|
匹配包括下划线在内的任何字符:[A-Za-z0-9_] |
a\wc
|
abc
|
|
\W
|
匹配非字母字符,即匹配特殊字符 |
a\Wc
|
a c
|
|
\A
|
仅匹配字符串开头,同^ | \Aabc |
abc
|
|
\Z
|
仅匹配字符串结尾,同$ |
abc\Z
|
abc
|
|
\b
|
匹配\w和\W之间,即匹配单词边界。匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 | \babc\b a\b!bc |
空格abc空格 a!bc |
|
\B
|
[^\b] |
a\Bbc
|
abc
|
这里需要强调一下\b的单词边界的理解:
w = re.findall('\btina','tian tinaaaa') print(w) s = re.findall(r'\btina','tian tinaaaa') print(s) v = re.findall(r'\btina','tian#tinaaaa') print(v) a = re.findall(r'\btina\b','tian#tina@aaa') print(a) 执行结果如下: [] ['tina'] ['tina'] ['tina']
3、特殊分组用法:
|
(?P<name>)
|
分组,除了原有的编号外再指定一个额外的别名 | (?P<id>abc){2} |
abcabc
|
|
(?P=name)
|
引用别名为<name>的分组匹配到字符串 | (?P<id>\d)abc(?P=id) |
1abc1
5abc5
|
|
\<number>
|
引用编号为<number>的分组匹配到字符串 | (\d)abc\1 |
1abc1
5abc5
|
分组就是用一对圆括号()括起来的正则表达式,匹配出的内容就表示一个分组。从正则表达式的左边开始看,看到的第一个左括号"("表示第一个分组,第二个表示第二个分组,依次类推,需要注意的是,有一个隐含的全局分组(就是0),就是整个正则表达式。
命名分组
命名分组就是给具有默认分组编号的组另外再给一个别名。命名分组的语法格式如下:
(?P<name>正则表达式) #name是一个合法的标识符
(?P=name)通过命名分组名进行引用
(?P=name) 字符P必须是大写的P,name表示命名分组的分组名
(?P<name>)(?P=name) 引用分组的值匹配值必须与第一个分组匹配值相等才能匹配到
例如:
1) 引用前一个分组,前后值相同都是2,故能匹配到
例如:
import re
print re.match(r'(?P<xst>\d)(?P=xst)','22').groups() #('2',)
print re.match(r'(?P<xst>\d)(?P=xst)','22').group() #22
2) 引用前一个分组,前后值不相同分别为2和3,故不能匹配到
例如
import re
print re.match(r'(?P<xst>\d)(?P=xst)','23').group() #AttributeError: 'NoneType' object has no attribute 'group'
后向引用
正则表达式中,放在圆括号()中的表示是一个组。然后你可以对整个组使用一些正则操作,例如重复操作符。
要注意的是,只有圆括号()才能用于形成组。""用于定义字符集。{}用于定义重复操作。
当用()定义了一个正则表达式组后,正则引擎则会把被匹配的组按照顺序编号,存入缓存。这样我们想在后面对已经匹配过的内容进行引用时,就可以用"\数字"的方式或者是通过命名分组进行"(?P=name)"进行引用。\1表示引用第一个分组,\2引用第二个分组,以此类推,\n引用第n个组。而\0则引用整个被匹配的正则表达式本身。这些引用都必须是在正则表达式中才有效,用于匹配一些重复的字符串。
前向肯定断言、后向肯定断言
前向肯定断言的语法:
(?=pattern)
(?<=pattern) 前向肯定断言表示你希望匹配的字符串前面是pattern匹配的内容时,才匹配。
后向肯定断言的语法:
(?<=pattern)
(?=pattern) 后向肯定断言表示你希望匹配的字符串的后面是pattern匹配的内容时,才匹配
前后向断言同时使用
需要注意的是,如果在匹配的过程中,需要同时用到前向肯定断言和后向肯定断言,那么必须将后向肯定断言写在正则语句的前面,前向肯定断言写在正则语句的后面,表示后向肯定模式之后,前行肯定模式之前
前向否定断言、后向否定断言
前向否定断言语法:
(?!pattern)
(?<!pattern) 前向否定断言表示你希望匹配的字符串的前面不是pattern匹配的内容时,才匹配.
后向否定断言语法:
(?<!pattern)
(?!pattern) 后向否定断言表示你希望匹配的字符串后面不是pattern匹配的内容时,才匹配。
注意:
前向肯定(否定)断言括号中的正则表达式必须是能确定长度的正则表达式,比如\w{3},而不能写成 \w*或者\w+或者\w?等这种不能确定个数的正则模式符。
数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。
表达式 .* 的意思很好理解,就是单个字符匹配任意次,即贪婪匹配。
表达式 .*? 是满足条件的情况只匹配一次,即懒惰匹配
三、正则表达式
re 模块: 核心函数和方法
常见的正则表达式函数与方法
re 模块的函数
compile(pattern,flags=0) :对正则表达式模式 pattern 进行编译,flags 是可选标志符,并返回一个 regex 对象
常用的flags有:
编译标志让你可以修改正则表达式的一些运行方式。在 re 模块中标志可以使用两个名字,一个是全名如 IGNORECASE,一个是缩写,字母形式如 I
re.S(DOTALL):使.匹配包括换行在内的所有字符。没有这个标志, "." 匹配除了换行外的任何字符。
re.I(IGNORECASE):使匹配对大小写不敏感
re.L(LOCALE):影响 "w, "W, "b, 和 "B,这取决于当前的本地化设置。cales 是 C 语言库中的一项功能,是用来为需要考虑不同语言的编程提供帮助的。
做本地化识别(locale-aware)匹配,法语等
re.M(MULTILINE):多行匹配,影响^和$。当本标志指定后, "^" 匹配字符串的开始和字符串中每行的开始。
同样的, $ 元字符匹配字符串结尾和字符串中每行的结尾(直接在每个换行之前)。
re.X(VERBOSE):该标志通过给予更灵活的格式以便将正则表达式写得更易于理解。当该标志被指定时,在 RE 字符串中的空白符被忽略,
除非该空白符在字符类中或在反斜杠之后;这可以让你更清晰地组织和缩进 RE。它也可以允许你将注释写入 RE,这些注释会被引擎忽略;
注释用 "#"号 来标识,不过该符号不能在字符串或反斜杠之后。
re.U:根据Unicode字符集解析字符,这个标志影响\w,\W,\b,\B
re 模块的函数和 regex 对象的方法
findall(pattern,string[,flags]): 在字符串 string 中查找正则表达式模式 pattern 的所有(非重复)出现的字串;返回一个匹配对象的列表
如果模式中存在一个或多个组,则返回组列表;如果模式有多个组,那么这将是一个元组列表。
结果中包含空的匹配项。
finditer(pattern,string[, flags]): 和 findall()相同,但返回的不是列表而是迭代器;对于每个匹配,该迭代器返回一个匹配对象
match(pattern,string, flags=0) :尝试用正则表达式模式 pattern 匹配字符串 string,flags 是可选标志符,如果匹配成功,则返回一个匹配对
象;否则返回 None
search(pattern,string, flags=0) :在字符串 string 中查找正则表达式模式 pattern 的第一次出现的字串,flags 是可选标志符,如果匹配成功,则返回
一个匹配对象;否则返回 None
匹配对象的方法
group(num=0) 或group([group1,...]:返回全部匹配对象,或指定编号是 num 的子组。返回匹配到的一个或者多个子组。如果是一个参数,那么结果就是一个字符串,
如果是多个参数,那么结果就是一个参数一个item的元组。group1的默认值为0(将返回所有的匹配值).如果groupN参数为0,
相对应的返回值就是全部匹配的字符串,如果group1的值是[1…99]范围之内的,那么将匹配对应括号组的字符串。
如果组号是负的或者比pattern中定义的组号大,那么将抛出IndexError异常。如果pattern没有匹配到,
但是group匹配到了,那么group的值也为None。如果一个pattern可以匹配多个,那么组对应的是样式匹配的最后一个。
另外,子组是根据括号从左向右来进行区分的
groups([default]) :返回一个包含全部匹配的子组的元组(如果没有成功匹配,就返回一个空元组)。
返回一个包含所有子组的元组。Default是用来设置没有匹配到组的默认值的。Default默认是None,
split(pattern,string, max=0): 根据正则表达式 pattern 中的分隔符把字符 string 分割为一个列表,返回成功匹配的列表,最多分割 max 次(默
认是分割所有匹配的地方)。
sub(pattern, repl, string, max=0) :把字符串 string 中所有匹配正则表达式 pattern 的地方替换成字符串 repl,如果 max 的值没有给出, 则对所有
匹配的地方进行替换(另外,请参考 subn(),它还会返回一个表示替换次数的数值)。
groupdict([default]):返回一个包含所有命名组的名字和子串的字典,default参数,用于给那些没有匹配到的组做默认值,它的默认值是None
返回匹配到的所有命名子组的字典。Key是name值,value是匹配到的值。参数default是没有匹配到的子组的默认值
start([group]),end([group]):返回的是:被组group匹配到的子串在原字符串中的位置。如果不指定group或group指定为0,则代表整个匹配。
如果group未匹配到,则返回 -1。对于指定的m和g,m.group(g)和m.string[m.start(g):m.end(g)]等效。
注意:如果group匹配到空字符串,m.start(group)和m.end(group)将相等
compile函数
对正则表达式模式进行编译,返回一个正则表达式对象
不是必须要用这种方式,但是在大量匹配的情况下,可以提升效率
语法:
re.compile(pattern,flags=0)
pattern: 编译时用的表达式字符串。
flags 编译标志位,用于修改正则表达式的匹配方式,如:是否区分大小写,多行匹配等。常用的flags有:
| 标志 |
含义
|
|
re.S(DOTALL)
|
使.匹配包括换行在内的所有字符 |
|
re.I(IGNORECASE)
|
使匹配对大小写不敏感
|
|
re.L(LOCALE)
|
做本地化识别(locale-aware)匹配,法语等
|
|
re.M(MULTILINE)
|
多行匹配,影响^和$
|
|
re.X(VERBOSE)
|
该标志通过给予更灵活的格式以便将正则表达式写得更易于理解
|
|
re.U
|
根据Unicode字符集解析字符,这个标志影响\w,\W,\b,\B
|
例子1:
#!/usr/bin/env python #coding:utf-8 import re patt = re.compile('foo') m = patt.match('food') print m.group() #foo
例子2:
#!/usr/bin/env python #coding:utf-8 import re tt = "Tina is a good girl, she is cool, clever, and so on..." rr = re.compile(r'\w*oo\w*') #匹配oo,无论oo前面或后面是否出现任何字符 print(rr.findall(tt))#查找所有包含'oo'的单词
用 match()匹配字符串
match()函数尝试从字符串的开头开始对模式进行匹配。如果匹配成功,就返回一个匹配对象,而如果匹配失败了,就返回 None。
注:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'
匹配对象的 group() 方法可以用来显示那个成功的匹配
re.match是用来进行正则匹配检查的方法,若字符串匹配正则表达式,则match方法返回匹配对象(Match Object),否则返回None(注意不是空字符串"")。
匹配对象Macth Object具有group方法,用来返回字符串的匹配部分。
语法:
re.match(pattern, string, flags=0)
例子1:
#!/usr/bin/env python #coding:utf-8 import re m1 = re.match('foo','food') #成功匹配 print m1 #<_sre.SRE_Match object at 0x000000000304A510> m2 = re.match('foo', 'seafood') #未能匹配 print m2 #None
例子2:
#!/usr/bin/env python #coding:utf-8 import re print(re.match('com','comwww.runcomoob').group()) #com print(re.match('com','Comwww.runcomoob',re.I).group()) #Com
search() 在一个字符串中查找一个模式 (搜索与匹配的比较)
1、search 和 match 的工作方式一样,不同之处在于 search 会检查参数字符串任意位置的地方给定正则表达式模式的匹配情况。
如果搜索到成功的匹配,会返回一个匹配对象,否则返回 None
2、search() 查找字符串中模式首次出现的位置,而不是尝试(在起始处)匹配。严格地说,search() 是从左到右进行搜索
3、在字符串中查找正则表达式模式的第一次出现,如果匹配成功,则返回一个匹配对象;否则返回None
#!/usr/bin/env python #coding:utf-8 import re m1 = re.search('foo','food') #成功匹配 print m1 #<_sre.SRE_Match object at 0x000000000304A510> m2 = re.search('foo', 'seafood') #可以匹配在字符中间的模式 print m2 #<_sre.SRE_Match object at 0x00000000030016B0>
匹配对象 和 group(), groups() 方法
1、在处理正则表达式时,除 regex 对象外,还有另一种对象类型 - 匹配对象。这些对象是在 match()或 search()被成功调用之后所返回的结果。
匹配对象有两个主要方法:group() 和 groups()
2、group()方法或者返回所有匹配对象或是根据要求返回某个特定子组
a. group()返回re整体匹配的字符串,
b. group (n,m) 返回组号为n,m所匹配的字符串,如果组号不存在,则返回indexError异常
3、groups()则很简单,它返回一个包含唯一或所有子组的元组。如果正则表达式中没有子组的话, groups() 将返回一个空元组,而 group()仍会返回全部匹配对象
例子1:
#!/usr/bin/env python #coding:utf-8 import re a = "123abc456" print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group() #123abc456 print re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(0) #123abc456 print re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(1) #123 print re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(2) #abc print re.search("([0-9]*)([a-z]*)([0-9]*)", a).groups() #('123', 'abc', '456')
究其因:
1. 正则表达式中的三组括号把匹配结果分成三组
m.group() == m.group(0) == 所有匹配的字符(即匹配正则表达式整体结果)
group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3) 列出第三个括号匹配部分。
m.groups() 返回所有括号匹配的字符,以tuple格式。m.groups() == (m.group(0), m.group(1), ...)
例子2:
#!/usr/bin/env python #coding:utf-8 import re origin = "hello alex bcd alex lge alex acd 19" #无分组 r = re.search('a\w+',origin) #\w:匹配任何数字字母字符,和[A-Za-z0-9_];+:匹配前面出现的正则表达式1次或多次 # 获取匹配到的所有结果 print(r.group()) #alex # 获取模型中匹配到的分组结果; print(r.groups()) #() # 获取模型中匹配到的分组结果 print(r.groupdict()) #{} # 有分组 # 为何要有分组?提取匹配成功的指定内容(先匹配成功全部正则,再匹配成功的局部内容提取出来) #查找a开头并且后面匹配任何字符,接着单个字符匹配任意次,最后以数字结尾 r = re.search("a(\w+).*(?P<name>\d)$", origin)# # 获取匹配到的所有结果 print(r.group()) #alex bcd alex lge alex acd 19 # 获取模型中匹配到的分组结果 print(r.groups()) #('lex', '9') # 获取模型中匹配到的分组中所有执行了key的 print(r.groupdict()) #{'name': '9'}
用 findall()找到每个出现的匹配部分
1、它用于非重叠地查找某字符串中一个正则表达式模式出现的情况
2、findall()和
search()相似之处在于二者都执行字符串搜索,但 findall()和
match()与search()不同之处是,findall()总返回一个列表。如果
findall()没有找到匹配的部分,会返回空列表;如果成功找到匹配部分,则返回所有匹配部分的列表(按从左到右出现的顺序排列)
#!/usr/bin/env python #coding:utf-8 import re m = re.search('foo', 'seafood is food') #search只匹配模式的第一次出现的字串 print m.group() #foo m = re.findall('foo', 'seafood is food') #可以匹配全部匹配的出现 print m #['foo', 'foo']
一些注意点
1、re.match与re.search与re.findall的区别:
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
#!/usr/bin/env python #coding:utf-8 import re a=re.search('[\d]',"abc33").group() print(a) #3 p=re.match('[\d]',"abc33") print(p) #None b=re.findall('[\d]',"abc33") print(b) #['3', '3']
2、贪婪匹配与非贪婪匹配
*?,+?,??,{m,n}? 前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
表达式 .* 的意思很好理解,就是单个字符匹配任意次,即贪婪匹配。
表达式 .*? 是满足条件的情况只匹配一次,即懒惰匹配
例子1:
#!/usr/bin/env python #coding:utf-8 import re a = re.findall(r"a(\d+?)",'a23b') print(a) #['2'] b = re.findall(r"a(\d+)",'a23b') print(b) #['23']
例子2:
#!/usr/bin/env python #coding:utf-8 import re a = re.match('<(.*)>','<H1>title<H1>').group() print(a) #<H1>title<H1> b = re.match('<(.*?)>','<H1>title<H1>').group() print(b) #<H1>
例子3:
#!/usr/bin/env python #coding:utf-8 import re a = re.findall(r"a(\d+)b",'a3333b') print(a) #['3333'] b = re.findall(r"a(\d+?)b",'a3333b') print(b) #['3333'] ####################### #这里需要注意的是如果前后均有限定条件的时候,就不存在什么贪婪模式了,非匹配模式失效。
finditer函数
和findall()函数有相同的功能,但返回的不是列表而是迭代器;
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。找到 RE 匹配的所有子串,并把它们作为一个迭代器返回。
对于每个匹配,该迭代器返回一个匹配对象
#!/usr/bin/env python #coding:utf-8 import re m = re.finditer('foo', 'seafood is food') for item in m: print item.group() ####### ''' foo foo '''
用 sub()和 subn()进行搜索和替换
sub
sub方法提供一个替换值,可以是字符串或函数,和一个要被处理的字符串。sub使用re替换string中每一个匹配的子串后返回替换后的字符串。
语法:
sub(pattern, repl, string, count=0, flags=0)
选项解释:
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\id或\g、\g引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
例子1:
#!/usr/bin/env python #coding:utf-8 import re m = re.sub('X', 'Mr. Smith', 'attn: X\nDear X') print m """ attn: Mr. Smith Dear Mr. Smith """
例子2:
import re text = "JGood is a handsome boy, he is cool, clever, and so on..." print(re.sub(r'\s+', '-', text)) 执行结果如下: JGood-is-a-handsome-boy,-he-is-cool,-clever,-and-so-on... 其中第二个函数是替换后的字符串;本例中为'-' 第四个参数指替换个数。默认为0,表示每个匹配项都替换。
re.sub还允许使用函数对匹配项的替换进行复杂的处理。
如:re.sub(r'\s', lambda m: '[' + m.group(0) + ']', text, 0);将字符串中的空格' '替换为'[ ]'。
import re text = "JGood is a handsome boy, he is cool, clever, and so on..." print(re.sub(r'\s+', lambda m:'['+m.group(0)+']', text,0)) 执行结果如下: JGood[ ]is[ ]a[ ]handsome[ ]boy,[ ]he[ ]is[ ]cool,[ ]clever,[ ]and[ ]so[ ]on...
subn
subn()和 sub()一样,但它还返回一个表示替换次数的数字,替换后的字符串和表示替换次数的数字作为一个元组的元素返回
3、语法:
subn(pattern, repl, string, count=0, flags=0)
选项解释:
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\id或\g、\g引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
用 split()分割(分隔模式)
1、re 模块和正则表达式对象的方法 split()与字符串的 split()方法相似, 前者是根据正则表达式模式分隔字符串,后者是根据固定的字符串分割
2、如果你不想在每个模式匹配的地方都分割字符串,你可以通过设定一个值参数(非零)来指定分割的最大次数
3、如果分隔符没有使用由特殊符号表示的正则表达式来匹配多个模式,那 re.split()和string.split()的执行过程是一样的
根据正则表达式中的分隔符把字符分割为一个列表,并返回成功匹配的列表
格式:
split(pattern, string, maxsplit=0, flags=0)
maxsplit用于指定最大分割次数,不指定将全部分割。
字符串也有类似的方法,但是正则表达式更加灵活
#!/usr/bin/env python #coding:utf-8 import re #使用 . 和 - 作为字符串的分隔符 mylist = re.split('\.|-', 'hello-world.data') print mylist #['hello', 'world', 'data']
例子:
#!/usr/bin/env python #coding:utf-8 import re origin = "hello alex bcd alex lge alex acd 19" n1 = re.split("a\w+",origin) print(n1) #['hello ', ' bcd ', ' lge ', ' ', ' 19'] n2 = re.split("a\w+",origin,1) print(n2) #['hello ', ' bcd alex lge alex acd 19'] n3 = re.split("a(\w+)",origin,1) print n3 #['hello ', 'lex', ' bcd alex lge alex acd 19'] n4 = re.split("(a\w+)",origin,1) print n4 #['hello ', 'alex', ' bcd alex lge alex acd 19']
用flags时遇到的小坑
print(re.split('a','1A1a2A3',re.I))#输出结果并未能区分大小写
这是因为re.split(pattern,string,maxsplit,flags)默认是四个参数,当我们传入的三个参数的时候,系统会默认re.I是第三个参数,所以就没起作用。
如果想让这里的re.I起作用,写成flags=re.I即可。
正则表达式之split以及计算器思路
#1 - 2 * ( (60-30 +(-40.0/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )
origin =" 1 - 2 * ( (60-30 +(-40.0/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )"
n = re.split("\(([^()]+)\)",origin,1)
print(n)
正则表达式之计算器去括号实例
方法1:
方法1:
def f1(ex):
return 1
#1 - 2 * ( (60-30 +(-40.0/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )
origin =" 1 - 2 * ( (60-30 +(-40.0/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )"
while True:
print(origin)
result = re.split("\(([^()]+)\)",origin,1)
if len(result) == 3:
before = result[0]
content = result[1]
after = result[2]
r = f1(content)
new_str = before + str(r) + after
origin = new_str
else:
final = f1(1+4)
print(final)
break
方法2:
def f1(ex):
return 1
#1 - 2 * ( (60-30 +(-40.0/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )
origin =" 1 - 2 * ( (60-30 +(-40.0/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )"
while True:
print(origin)
result = re.split("\(([^()]+)\)",origin,1)
if len(result) == 3:
before,content,after = result
r = f1(content)
new_str = before + str(r) + after
origin = new_str
else:
final = f1(1+4)
print(final)
break
原始字符串
>>> mm = "c:\\a\\b\\c"
>>> mm
'c:\\a\\b\\c'
>>> print(mm)
c:\a\b\c
>>> print(mm)
c:\a\b\c
>>> re.match("c:\\\\",mm).group()
'c:\\'
>>> ret = re.match("c:\\\\",mm).group()
>>> print(ret)
c:\
>>> ret = re.match("c:\\\\a",mm).group()
>>> print(ret)
c:\a
>>> ret = re.match(r"c:\\a",mm).group()
>>> print(ret)
c:\a
>>> ret = re.match(r"c:\a",mm).group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
>>>
Python中字符串前面加上 r 表示原生字符串,
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,有了原始字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
>>> ret = re.match(r"c:\\a",mm).group()
>>> print(ret)
c:\a
表示数量
实例1:
需求:匹配出,一个字符串第一个字母为大小字符,后面都是小写字母并且这些小写字母可有可无
#!/usr/bin/env python #coding:utf-8 import re ret = re.match("[A-Z][a-z]*","Mm") print ret.group() #Mm ret = re.match("[A-Z][a-z]*","Aabcdef") print ret.group() #Aabcdef
实例2:需求:匹配出,变量名是否有效
#!/usr/bin/env python #coding:utf-8 import re ret = re.match("[a-zA-Z_]+[\w_]*","name1") print ret.group() #name1 ret = re.match("[a-zA-Z_]+[\w+]*","_name") print ret.group() # _name ret = re.match("[a-zA-Z_]+[\w_]*","2_name") print ret.group() #匹配不到,AttributeError: 'NoneType' object has no attribute 'group'
实例3:
#!/usr/bin/env python #coding:utf-8 import re ret = re.match("[1-9]?[0-9]","123456") print ret.group() #12 ret = re.match("[1-9]?[0-9]","123456") print ret.group() #12 ret = re.match("[1-9]?[0-9]","123456") print ret.group() #12
实例4:需求:匹配出,8到20位的密码,可以是大小写英文字母、数字、下划线
#!/usr/bin/env python #coding:utf-8 import re ret = re.match("[a-zA-Z0-9_]{6}","12a3g45678") print ret.group() #12a3g4 ret = re.match("[a-zA-Z0-9_]{8,12}","1ad12f23s34455ff66") print ret.group() #1ad12f23s344
表示边界
示例1:$
需求:匹配163.com的邮箱地址
#!/usr/bin/env python #coding:utf-8 import re # 正确的地址 ret = re.match("[\w]{4,20}@163\.com", "xiaoWang@163.com") print ret.group() #xiaoWang@163.com # 不正确的地址 ret = re.match("[\w]{4,20}@163\.com", "xiaoWang@163.comheihei") print ret.group() #xiaoWang@163.com # 通过$来确定末尾 ret = re.match("[\w]{4,20}@163\.com$", "xiaoWang@163.comheihei") print ret.group() #报错,AttributeError: 'NoneType' object has no attribute 'group'
示例2: \b
>>> re.match(r".*\bver\b", "ho ver abc").group()
'ho ver'
>>> re.match(r".*\bver\b", "ho verabc").group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
>>> re.match(r".*\bver\b", "hover abc").group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
>>>
示例3:\B
>>> re.match(r".*\Bver\B", "hoverabc").group()
'hover'
>>> re.match(r".*\Bver\B", "ho verabc").group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
>>> re.match(r".*\Bver\B", "hover abc").group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
>>> re.match(r".*\Bver\B", "ho ver abc").group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
匹配分组
重新复习分组语法:
字符 功能
| 匹配左右任意一个表达式
(ab) 将括号中字符作为一个分组
\num 引用分组num匹配到的字符串
(?P<name>) 分组起别名
(?P=name) 引用别名为name分组匹配到的字符串
分组就是用一对圆括号()括起来的正则表达式,匹配出的内容就表示一个分组。从正则表达式的左边开始看,看到的第一个左括号(表示第一个分组,第二个表示第二个分组,依次类推,需要注意的是,有一个隐含的全局分组(就是0),就是整个正则表达式。
分完组以后,要想获得某个分组的内容,直接使用group(num)和groups()函数去直接提取就行。
命名分组
命名分组就是给具有默认分组编号的组另外再给一个别名。命名分组的语法格式如下:
(?P<name>正则表达式) #name是一个合法的标识符
。
(?P=name)通过命名分组名进行引用
(?P=name) 字符P必须是大写的P,name表示命名分组的分组名
(?P<name>)(?P=name) 引用分组的值匹配值必须与第一个分组匹配值相等才能匹配到
注意:
(?P<name>...)
和普通的圆括号类似,但是子串匹配到的内容将可以用命名的name参数来提取。组的name必须是有效的python标识符,而且在本表达式内不重名。命名了的组和普通组一样,也用数字来提取,也就是说名字只是个额外的属性
例如:
1) 引用前一个分组,前后值相同都是2,故能匹配到
例如:
import re
print re.match(r'(?P<xst>\d)(?P=xst)','22').groups() #('2',)
print re.match(r'(?P<xst>\d)(?P=xst)','22').group() #22
2) 引用前一个分组,前后值不相同分别为2和3,故不能匹配到
例如
import re
print re.match(r'(?P<xst>\d)(?P=xst)','23').group() #AttributeError: 'NoneType' object has no attribute 'group'
如:提取字符串中的ip地址
例子1:
>>> s = "ip='230.192.168.78',version='1.0.0'"
>>> res =re.search(r"ip='(?P<ip>\d+\.\d+\.\d+\.\d+).*", s)
>>> res.group('ip')#通过命名分组引用分组
'230.192.168.78'
例子2:
#!/usr/bin/env python
#coding:utf-8
import re
s = "ip='230.192.168.78',version='1.0.0'"
res = re.search("(?P<ip>\d+\.\d+\.\d+\.\d+)", s)
#通过命名分组引用分组
print res.group('ip') #230.192.168.78
后向引用
正则表达式中,放在圆括号()中的表示是一个组。然后你可以对整个组使用一些正则操作,例如重复操作符。
要注意的是,只有圆括号()才能用于形成组。""用于定义字符集。{}用于定义重复操作。
当用()定义了一个正则表达式组后,正则引擎则会把被匹配的组按照顺序编号,存入缓存。这样我们想在后面对已经匹配过的内容进行引用时,就可以用"\数字"的方式或者是通过命名分组进行"(?P=name)"进行引用。\1表示引用第一个分组,\2引用第二个分组,以此类推,\n引用第n个组。而\0则引用整个被匹配的正则表达式本身。这些引用都必须是在正则表达式中才有效,用于匹配一些重复的字符串。
如:
#通过命名分组进行后向引用
>>> re.search(r'(?P<name>go)\s+(?P=name)\s+(?P=name)', 'go go go').group('name')
'go'
#通过默认分组编号进行后向引用
>>> re.search(r'(go)\s+\1\s+\1', 'go go go').group()
'go go go'
交换字符串的位置
>>> s = 'abc.xyz'
>>> re.sub(r'(.*)\.(.*)', r'\2.\1', s)
'xyz.abc'
前向肯定断言、后向肯定断言
前向肯定断言的语法:
(?=pattern)
(?<=pattern) 前向肯定断言表示你希望匹配的字符串前面是pattern匹配的内容时,才匹配。
后向肯定断言的语法:
(?<=pattern)
(?=pattern) 后向肯定断言表示你希望匹配的字符串的后面是pattern匹配的内容时,才匹配
前后向断言同时使用
需要注意的是,如果在匹配的过程中,需要同时用到前向肯定断言和后向肯定断言,那么必须将后向肯定断言写在正则语句的前面,前向肯定断言写在正则语句的后面,表示后向肯定模式之后,前行肯定模式之前
如:获取c语言代码中的注释内容
>>> s1='''char *a="hello world"; char b='c'; /* this is comment */ int c=1; /* this is multiline comment */'''
>>> re.findall( r'(?<=/\*).+?(?=\*/)' , s1 ,re.M|re.S)
[' this is comment ', ' this is multiline comment ']
(?<=/*)这个是后向肯定断言,表示'/*'之后。(?=*/)这个为前向肯定断言,表示'*/'之前,这两合并起来就是一个区间了,所以后向肯定断言放在前向肯定断言前面。
前向否定断言、后向否定断言
前向否定断言语法:
(?!pattern)
(?<!pattern) 前向否定断言表示你希望匹配的字符串的前面不是pattern匹配的内容时,才匹配.
后向否定断言语法:
(?<!pattern)
(?!pattern) 后向否定断言表示你希望匹配的字符串后面不是pattern匹配的内容时,才匹配。
前向否定和后向否定实例:
#提取不是.txt结尾的文件
>>> f1 = 'aaa.txt'
>>> re.findall(r'.*\..*$(?<!txt$)',f1)
[]
#提取不以数字开头的文件
>>> re.findall(r'^(?!\d+).*','1txt.txt')
[]
#提取不以数字开头不以py结尾的文件
>>> re.findall(r'^(?!\d+).+?\..*$(?<!py$)','test.py')
[]
>>> re.findall(r'^(?!\d+).+?\..*$(?<!py$)','test.txt')
['test.txt']
注意:
前向肯定(否定)断言括号中的正则表达式必须是能确定长度的正则表达式,比如\w{3},而不能写成 \w*或者\w+或者\w?等这种不能确定个数的正则模式符。
示例1:
需求:匹配出0-100之间的数字
#coding=utf-8
import re
ret = re.match("[1-9]?\d","8")
print ret.group()
ret = re.match("[1-9]?\d","78")
print ret.group()
# 不正确的情况
ret = re.match("[1-9]?\d","08")
print ret.group()
# 修正之后的
ret = re.match("[1-9]?\d$","08")
print.group() #这个是错误
# 添加|
ret = re.match("[1-9]?\d$|100","8")
ret.group()
ret = re.match("[1-9]?\d$|100","78")
ret.group()
ret = re.match("[1-9]?\d$|100","08")
ret.group()
ret = re.match("[1-9]?\d$|100","100")
ret.group()
示例2:( )
需求:匹配出163、126、qq邮箱之间的数字
#coding=utf-8
import re
ret = re.match("\w{4,20}@163\.com", "test@163.com")
ret.group()
ret = re.match("\w{4,20}@(163|126|qq)\.com", "test@126.com")
ret.group()
ret = re.match("\w{4,20}@(163|126|qq)\.com", "test@qq.com")
ret.group()
ret = re.match("\w{4,20}@(163|126|qq)\.com", "test@gmail.com")
ret.group()
示例3:\
需求:匹配出<html>hh</html>
#coding=utf-8
import re
# 能够完成对正确的字符串的匹配
ret = re.match("<[a-zA-Z]*>\w*</[a-zA-Z]*>", "<html>hh</html>")
ret.group()
# 如果遇到非正常的html格式字符串,匹配出错
ret = re.match("<[a-zA-Z]*>\w*</[a-zA-Z]*>", "<html>hh</htmlbalabala>")
ret.group()
# 正确的理解思路:如果在第一对<>中是什么,按理说在后面的那对<>中就应该是什么
# 通过引用分组中匹配到的数据即可,但是要注意是元字符串,即类似 r""这种格式
ret = re.match(r"<([a-zA-Z]*)>\w*</\1>", "<html>hh</html>")
ret.group()
# 因为2对<>中的数据不一致,所以没有匹配出来
ret = re.match(r"<([a-zA-Z]*)>\w*</\1>", "<html>hh</htmlbalabala>")
ret.group()
示例4:\number
需求:匹配出<html><h1>www.itcast.cn</h1></html>
#coding=utf-8
import re
ret = re.match(r"<(\w*)><(\w*)>.*</\2></\1>", "<html><h1>www.itcast.cn</h1></html>")
ret.group()
ret = re.match(r"<(\w*)><(\w*)>.*</\2></\1>", "<html><h1>www.itcast.cn</h2></html>")
ret.group()
示例5:(?P<name>) (?P=name)
需求:匹配出<html><h1>www.itcast.cn</h1></html>
#coding=utf-8
import re
ret = re.match(r"<(?P<name1>\w*)><(?P<name2>\w*)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.itcast.cn</h1></html>")
ret.group()
ret = re.match(r"<(?P<name1>\w*)><(?P<name2>\w*)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.itcast.cn</h2></html>")
ret.group()
注意:(?P<name>)和(?P=name)中的字母p大写
分析 apache 访问日志
写用于分析 apache 日志的脚本,主要要求如下:
1、统计每个客户端访问 apache 服务器的次数
2、将统计信息通过字典的方式显示出来
3、分别统计客户端是 Firefox 和 MSIE 的访问次数
4、分别使用函数式编程和面向对象编程的方式实现
方案
涉及到文本处理时,正则表达式将是一个非常强大的工具。匹配客户端的 IP 地址,可以使用正则表达式的元字符,匹配字符串可以直接使用字符的表面含义。
入门级程序员的写法,使用顺序的结构,直接编写。这种方法虽然可以得出结果,但是代码难以重用。参考步骤一。
进阶的写法可以采用函数式编程,方便日后再次使用。参考步骤二。
最后,还可以使用 OOP 的编程方法,先定义一个统计类,该类将正则表达式作为它的数据属性。再定义一个方法,从指定的文件中搜索正则表达式出现的次数,并将其存入到一个字典中。参考步骤三
步骤
实现此案例需要按照如下步骤进行。
步骤一:简单实现
#!/usr/bin/env python
#coding:utf-8
import re
logfile = '/var/log/httpd/access_log'
cDict = {}
patt_ip = '^\d+\.\d+\.\d+\.\d+' #定义匹配 IP 地址的正则表达式
with open(logfile) as f:
for eachLine in f:
m = re.search(patt_ip, eachLine)
if m is not None:
ipaddr = m.group()
#如果 IP 地址已在字典中,将其值加 1,否则初始值设置为 1
cDict[ipaddr] = cDict.get(ipaddr, 0) + 1
print cDict
注意:
dict.get(key, default=None):对字典dict中的键key,返回它对应的值value,如果字典中不存在此键,则返回default的值
执行结果:需要客户端访问
root@host-192-168-3-6 test]# python countweb.py
{'61.140.232.156': 11}
步骤二:使用函数式编程实现
#!/usr/bin/env python
#coding:utf-8
import re
def countPatt(patt, fname): #定义可以在指定文件中搜索指定字符串的函数
cDict = {}
with open(fname) as f:
for eachLine in f:
m = re.search(patt, eachLine)
if m is not None:
k = m.group()
cDict[k] = cDict.get(k, 0) + 1
return cDict
def test():
logfile = '/var/log/httpd/access_log'
patt_ip = '^\d+\.\d+\.\d+\.\d+'
print countPatt(patt_ip, logfile)
patt_br = 'Firefox|MSIE'
print countPatt(patt_br, logfile)
if __name__ == '__main__':
test()
执行结果:
[root@host-192-168-3-6 test]# python countweb.py
{'61.140.232.156': 11}
{'Firefox': 11}
步骤三:使用 OOP 方式实现
#!/usr/bin/env python
#coding:utf-8
import re
class MyCount(object): #定义类,将正则表达式作为其数据属性
def __init__(self, patt):
self.patt = patt
def countPatt(self, fname): #定义统计正则表达式的方法
cDict = {}
with open(fname) as f:
for eachLine in f:
m = re.search(self.patt, eachLine)
if m is not None:
k = m.group()
cDict[k] = cDict.get(k, 0) + 1
return cDict
def test():
patt_ip = '\d+\.\d+\.\d+\.\d+'
logfile = '/var/log/httpd/access_log'
testip = MyCount(patt_ip)
print testip.countPatt(logfile)
patt_br = 'Firefox|MSIE'
testbr = MyCount(patt_br)
print testbr.countPatt(logfile)
if __name__ == '__main__':
test()
执行结果:
[root@host-192-168-3-6 test]# python countweb.py
{'61.140.232.156': 11}
{'Firefox': 11}
方法1:
step1:
>>> adict= {}
>>> print adict.get('a',0)
0
>>> adict['a'] = adict.get('a',0)
>>> adict
{'a': 0}
>>> adict['b'] = adict.get('b',0) + 1
>>> adict
{'a': 0, 'b': 1}
>>> adict['b'] = adict.get('b',0) + 1
>>> adict
{'a': 0, 'b': 2}
>>>
[root@host-192-168-3-6 ~]# yum -y install httpd
[root@host-192-168-3-6 ~]# systemctl start httpd
[root@host-192-168-3-6 ~]# systemctl status httpd
[root@host-192-168-3-6 ~]# tail -f /var/log/httpd/access_log
count_patt1.py内容:
#!/usr/bin/env python
#coding:utf8
import re
def count_patt(fname,patt):
patt_dict = {}
cpatt = re.compile(patt)
with open(fname) as fobj:
for line in fobj:
m = cpatt.search(line)
if m:
key = m.group()
#如果key不在字典中,设置值为1,否则加1
patt_dict[key] = patt_dict.get(key,0) + 1
'''
if key not in patt_dict:
patt_dict[key] = 1
else:
patt_dict[key] += 1
'''
return patt_dict
if __name__ == "__main__":
log_file = "/var/log/httpd/access_log"
ip_patt = "^(\d+\.){3}\d+"
br_patt = "Firefox|MSIE|Chrome|QQBrowser"
print count_patt(log_file, ip_patt)
print count_patt(log_file, br_patt)
执行结果:
[root@host-192-168-3-6 ~]# python count_patt.py
{'113.67.74.155': 250}
{'Chrome': 95, 'Firefox': 24, 'QQBrowser': 22}
count_patt2.py内容:
#!/usr/bin/env python
#coding:utf8
import re
def count_patt(fname,patt):
patt_dict = {}
cpatt = re.compile(patt)
with open(fname) as fobj:
for line in fobj:
m = cpatt.search(line)
if m:
key = m.group()
#如果key不在字典中,设置值为1,否则加1
patt_dict[key] = patt_dict.get(key,0) + 1
'''
if key not in patt_dict:
patt_dict[key] = 1
else:
patt_dict[key] += 1
'''
return patt_dict
def sort(adict):
alist = []
patt_list = adict.items()
for i in range(len(patt_list)):
greater = patt_list[0]
for j in range(len(patt_list[1:])):
greater = greater if greater[1] >=patt_list[j+1][1] else patt_list[j +1]
alist.append(greater)
patt_list.remove(greater)
return alist
if __name__ == "__main__":
log_file = "/var/log/httpd/access_log"
ip_patt = "^(\d+\.){3}\d+"
br_patt = "Firefox|MSIE|Chrome|QQBrowser"
print count_patt(log_file, br_patt)
ip_count = count_patt(log_file, ip_patt)
print ip_count
print sort(ip_count)
执行结果:
[root@host-192-168-3-6 ~]# python count_patt.py
{'113.67.74.155': 264}
{'Chrome': 100, 'Firefox': 33, 'QQBrowser': 22}
[root@host-192-168-3-6 ~]# python count_patt.py
{'Chrome': 100, 'Firefox': 33, 'QQBrowser': 22}
{'113.67.74.155': 268}
[('113.67.74.155', 268)]
count_patt3.py内容:
#!/usr/bin/env python
#coding:utf8
import re
import collections
class CountPatt(object):
def __init__(self,patt):
self.cpatt = re.compile(patt)
def count_patt(self,fname):
c = collections.Counter()
with open(fname) as fobj:
for line in fobj:
m = self.cpatt.search(line)
if m:
c.update([m.group()])
return c
if __name__ == "__main__":
log_file = "/var/log/httpd/access_log"
ip_patt = "^(\d+\.){3}\d+"
br_patt = "Firefox|MSIE|Chrome|QQBrowser"
c1 = CountPatt(ip_patt)
print c1.count_patt(log_file)
print c1.count_patt(log_file).most_common(2)
c2 = CountPatt(br_patt)
print c2.count_patt(log_file)
print c2.count_patt(log_file).most_common(2)
执行结果:
[root@host-192-168-3-6 ~]# python count_patt2.py
Counter({'113.67.74.155': 311, '47.88.191.116': 1, '139.162.88.63': 1})
[('113.67.74.155', 311), ('47.88.191.116', 1)]
Counter({'Chrome': 130, 'Firefox': 39, 'QQBrowser': 26})
[('Chrome', 130), ('Firefox', 39)]
[root@host-192-168-3-6 ~]#
参考:
https://www.cnblogs.com/dodoye/p/6218192.html
http://www.jb51.net/article/117035.htm
https://www.cnblogs.com/larry-luo/p/10814919.html
https://www.cnblogs.com/panwenbin-logs/p/5584864.html
