


25.继承和组合
继承
继承是一种创建新类的方式,在python中,新建的类可以继承一个或多个父类,父类又可称为基类或超类,新建的类称为派生类或子类
继承可以得到父类定义的方法,子类就可以复用父类的方法
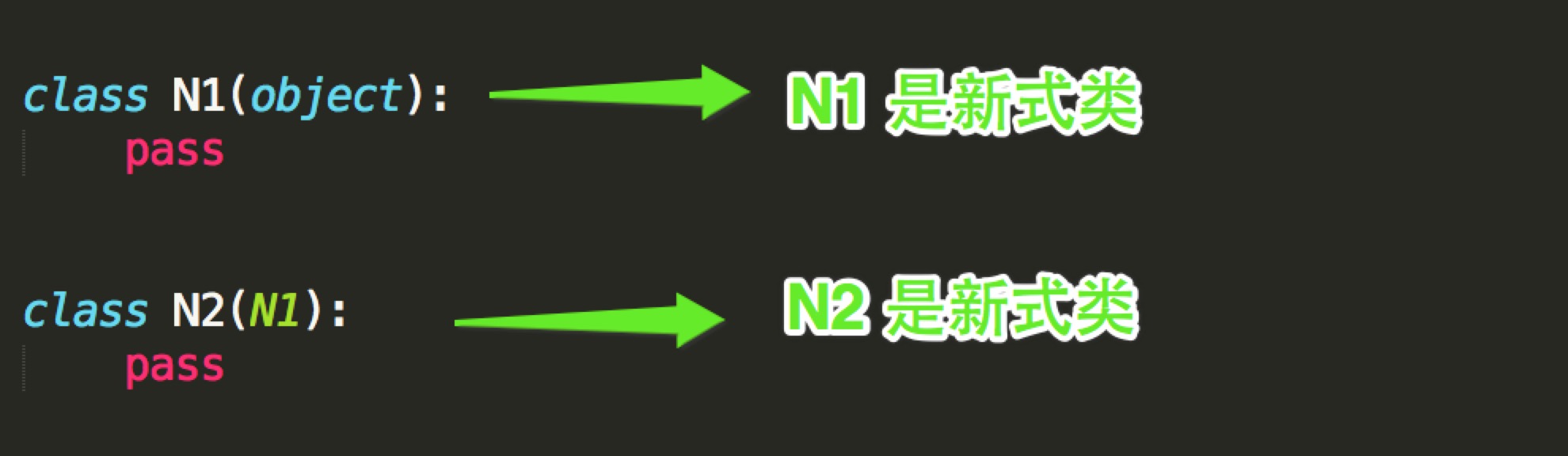
子类继承父类是在定义子类时,将多个父类放在子类之后的圆括号内,如果定义类时,未指定这个类的直接父类,则默认继承object类,所以object类是所有类的父类(直接父类或者是间接父类)
在Python3中,所有类都默认继承object,都是新式类。
在Python2中,有经典类和新式类。
没有继承object类以及object的子类的类都是经典类。
python中类的继承分为:单继承和多继承
class ParentClass1: #定义父类 pass class ParentClass2: #定义父类 pass class SubClass1(ParentClass1): #单继承,基类是ParentClass1,派生类是SubClass pass class SubClass2(ParentClass1,ParentClass2): #python支持多继承,用逗号分隔开多个继承的类 pass
查看继承
>>> SubClass1.__bases__ #__base__只查看从左到右继承的第一个子类,__bases__则是查看所有继承的父类 (<class '__main__.ParentClass1'>,) >>> SubClass2.__bases__ (<class '__main__.ParentClass1'>, <class '__main__.ParentClass2'>)
提示:如果没有指定基类,python的类会默认继承object类,object是所有python类的基类,它提供了一些常见方法(如__str__)的实现。
>>> ParentClass1.__bases__ (<class 'object'>,) >>> ParentClass2.__bases__ (<class 'object'>,)
经典类与新式类
1.只有在python2中才分新式类和经典类,python3中统一都是新式类 2.在python2中,没有显式的继承object类的类,以及该类的子类,都是经典类 3.在python2中,显式地声明继承object的类,以及该类的子类,都是新式类 4.在python3中,无论是否继承object,都默认继承object,即python3中所有类均为新式类
__bases__类属性
__bases__类属性,对任何(子)类,它是一个包含其父类(parent)的集合的元组。
父类是相对所有基类(它包括了所有祖先类)而言的
那些没有父类的类,它们的__bases__属性为空
例子1:
#!/usr/bin/env python
#coding:utf8
class A(): # 定义类 A
pass
class B(A):# A 的子类
pass
class C(B): # B 的子类(A 的间接子类)
pass
class D(A,B): # A,B 的子类
pass
print A.__bases__
print C.__bases__
print D.__bases__
执行结果:
()
(<class __main__.B at 0x05BC4AB0>,)
(<class __main__.A at 0x05BC4AE8>, <class __main__.B at 0x05BC4AB0>)
从上面看到,在经典类中,A没有继承父类,C的父类是B,D的父类是A和B。
例子2:
#!/usr/bin/env python
#coding:utf8
class A(object): # 定义类 A
pass
class B(A):# A 的子类
pass
class C(B): # B 的子类(A 的间接子类)
pass
class D(A,B): # A,B 的子类
pass
print A.__bases__
print C.__bases__
print D.__bases__
执行结果:
TypeError: Error when calling the metaclass bases
Cannot create a consistent method resolution
order (MRO) for bases A, B
在新式类中,则会出现上面的报错提示。
原因是写多重继承的时候因为父类的顺序问题导致了python的方法解析顺序出现了问题。
其中红色的地方就是出错的地方。把A与B换下位置就好了。
#!/usr/bin/env python
#coding:utf8
class A(object): # 定义类 A
pass
class B(A):# A 的子类
pass
class C(B): # B 的子类(A 的间接子类)
pass
class D(B,A): # A,B 的子类
pass
print A.__bases__
print C.__bases__
print D.__bases__
执行结果:
(<type 'object'>,)
(<class '__main__.B'>,)
(<class '__main__.B'>, <class '__main__.A'>)
在新式类中,A的父类是object,C的父类是B,D的父类是B和A
单继承
例子:
#!/usr/bin/env python
#coding:utf8
class Parent(object): # 定义父类
def parenetMethod(self):
return "calling parent method"
class Child(Parent): # 定义子类
def childMethod(self):
return "calling child method"
p = Parent() # 父类的实例
print p.parenetMethod() #父类调用它的方法
c = Child()
print c.childMethod() #子类调用它的方法
print c.parenetMethod() # 调用父类的方法
执行结果:
calling parent method
calling child method
calling parent method
例子:
#!/usr/bin/env python #coding:utf8 class Animal: def dog(self): print '我有一只狗!他叫%s' % self.dog_name class Child: def son(self): print '我有两个儿子!' # 定义Myself类,继承Animal类和Child类 class Myself(Animal, Child): def name(self): print '我叫小明!' M = Myself() # 创建Myself对象 M.dog_name = '大黄' # 通过Myself对象添加dog_name类变量 M.dog() # 调用Myself对象的dog()方法,打印 我有一只狗!他叫大黄 M.son() # 调用Myself对象的son()方法,打印 我有两个儿子! M.name() # 调用Myself对象的name()方法,打印 我叫小明!
在上面的例子中,定义了Animal和Child两个父类,和一个继承Animal类和Child类的Myself类;创建Myself对象后,可以访问Myself对象的dog()方法和son()方法,说明Myself对象也具有dog()方法和son()方法,所以继承可以得到父类定义的方法,通过继承子类就可以复用父类的方法。
多继承
子类会通过继承得到所有父类的方法,那么如果多个父类中有相同的方法名,排在前面的父类同名方法会“遮蔽”排在后面的父类同名方法,例:
#!/usr/bin/env python #coding:utf8 class Animal: def name(self): print ('我有一只狗,他叫大黄!') class Child: def name(self): print ('我有两个儿子!') class Myself(Animal, Child): pass class Yourself(Child, Animal): pass M = Myself() M.name() # 打印 我有一只狗,他叫大黄! Y = Yourself() Y.name() # 打印 我有两个儿子!
上面例子中,Myself类继承了Animal类和Child类,当Myself子类对象调用name()方法时,因为Myself子类中没有定义name()方法,Python会先在Animal父类中搜寻name()方法,一旦搜寻到就会停止继续向下搜寻,所以运行的是Animal类中的name()方法;而Yourself子类中由于Child父类排在前面,所以运行的是Child类的name()方法。
派生
当然子类也可以添加自己新的属性或者在自己这里重新定义这些属性(不会影响到父类),需要注意的是,一旦重新定义了自己的属性且与父类重名,那么调用新增的属性时,就以自己为准了。
子类包含与父类同名的方法称为方法重写(方法覆盖),可以说是重写父类方法,也可以说子类覆盖父类方法。
核心笔记:重写__init__不会自动调用基类的__init__
1、当从一个带构造器 __init()__的类派生,如果你不去覆盖__init__(),它将会被继承并自动调用。
2、但如果你在子类中覆盖了__init__(),子类被实例化时,基类的__init__()就不会被自动调用
例子:
#!/usr/bin/env python #coding:utf8 class Animal: def name(self): print ('我有一只狗,他叫大黄!') class Myself(Animal): # 重写Animal类的name()方法 def name(self): print ('我没有狗,我只有一只猫,他叫大白!') M = Myself() # 创建Myself对象 M.name() # 执行Myself对象的name()方法,打印 我没有狗,我只有一只猫,他叫大白!
上面的例子中,运行M.name()时执行的不再是Animal类的fly()方法,而是Myself类的name()方法。
在子类中重写方法之后,如果需要用到父类中被重写的实例方法,可以通过类名调用实例方法来调用父类被重写的方法。
例如:
class Animal: def name(self): print ('我有一只狗,他叫大黄!') class Myself(Animal): # 重写Animal类的name()方法 def name(self): print ('我还有一只猫,他叫大白!') def pet(self): Animal.name(self) # 调用被重写的父类方法name(),使用类名.实例名调用,需要手动传self self.name() # 执行name()方法,会调用子类重写的name()方法 M = Myself() # 创建Myself对象 M.pet() ''' 打印 我有一只狗,他叫大黄! 我还有一只猫,他叫大白! '''
在子类中调用父类的方法
如果子类有多个直接的父类,那么排在前面的构造方法会遮蔽排在后面的构造方法。
例:
#!/usr/bin/env python #coding:utf8 class Animal: def __init__(self, pet, name): self.pet = pet self.name = name def favourite_animal(self): print ('我有一只%s,他叫%s!' % (self.pet, self.name)) class Fruit: def __init__(self, kind): self.kind = kind def favourite_fruit(self): print ('我喜欢的水果是%s!' % self.kind) class Myself(Animal, Fruit): pass M = Myself('狗', '大黄') # 创建Myself对象 M.favourite_animal() # 调用Myself对象的favourite_animal()方法,打印 我有一只狗,他叫大黄! #调用Myself对象的favourite_fruit方法,由于未初始化Fruit对象的kind实例变量,报错 #AttributeError: 'Myself' object has no attribute 'kind' M.favourite_fruit() #
上面例子中,Myself子类继承了Animal父类和Fruit父类,由于Animal父类排在Fruit父类前面,所以Animal父类的构造函数遮蔽了Fruit父类的构造函数,运行M.favourite_animal()没有任何问题,当运行M.favourite_fruit()时,由于未初始化Fruit对象的kind实例变量,所以程序会报错。
解决以上问题,Myself应该重写父类的构造方法,子类的构造方法可以调用父类的构造方法,即在子类派生出的新方法中,往往需要重用父类的方法
有以下两种方式:
1.使用未绑定方法,即: 父类名.__init__(self,参数1,参数2....) 2.使用super()函数调用父类构造方法。
先查看一下super()函数的帮助信息,
class super(object) | super(type, obj) -> bound super object; requires isinstance(obj, type) | super(type) -> unbound super object | super(type, type2) -> bound super object; requires issubclass(type2, type) | Typical use to call a cooperative superclass method: | class C(B): | def meth(self, arg): | super(C, self).meth(arg)
通过帮助信息,可以看到,当调用父类的实例方法时,会自动绑定第一个参数self;当调用类方法时,会自动绑定第一个参数cls。
接下来修改上面的程序:
#!/usr/bin/env python #coding:utf8 class Animal(object): def __init__(self, pet, name): self.pet = pet self.name = name def favourite_animal(self): print ('我有一只%s,他叫%s!' % (self.pet, self.name)) class Fruit(object): def __init__(self, kind): self.kind = kind def favourite_fruit(self): print ('我喜欢的水果是%s!' % self.kind) class Myself(Animal, Fruit): def __init__(self, pet, name, kind): Fruit.__init__(self, kind) # 通过未绑定方法调用父类构造方法 super(Myself,self).__init__(pet,name) # python2通过super()函数调用父类构造方法 super().__init__(pet,name) # python3通过super()函数调用父类构造方法 #super(Myself,self) 就相当于实例本身 在python3中super()等同于super(Myself,self) M = Myself('狗', '大黄', '苹果') M.favourite_animal() # 打印 我有一只狗,他叫大黄! M.favourite_fruit() # 打印 我喜欢的水果是苹果!
注意,如果出现如下报错,则有可能说明super用在了经典类上:
TypeError: must be type, not classobj
python中super只能应用于新类,而不能应用于经典类
所谓新类就是所有类都必须要有继承的类,如果什么都不想继承,就继承到object类
Python-MRO
MRO(Method Resolution Order):方法解析顺序。
Python语言包含了很多优秀的特性,其中多重继承就是其中之一,但是多重继承会引发很多问题,比如二义性,Python中一切皆引用,这使得他不会像C++一样使用虚基类处理基类对象重复的问题,但是如果父类存在同名函数的时候还是会产生二义性,Python中处理这种问题的方法就是MRO。
历史中的MRO
如果不想了解历史,只想知道现在的MRO可以直接看最后的C3算法,不过C3所解决的问题都是历史遗留问题,了解问题,才能解决问题,建议先看历史中MRO的演化。
Python2.2以前的版本:经典类(classic class)时代
经典类是一种没有继承的类,实例类型都是type类型,如果经典类被作为父类,子类调用父类的构造函数时会出错。
这时MRO的方法为DFS(深度优先搜索(子节点顺序:从左到右))。
Class A: # 是没有继承任何父类的
def __init__(self):
print "这是经典类"
inspect.getmro(A)可以查看经典类的MRO顺序
import inspect
class D:
pass
class C(D):
pass
class B(D):
pass
class A(B, C):
pass
if __name__ == '__main__':
print inspect.getmro(A)
(<class __main__.A at 0x10e0e5530>, <class __main__.B at 0x10e0e54c8>, <class __main__.D at 0x10e0e53f8>, <class __main__.C at 0x10e0e5460>)
# 测试用3.6环境测试,
(<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.D'>, <class 'object'>)
MRO的DFS顺序
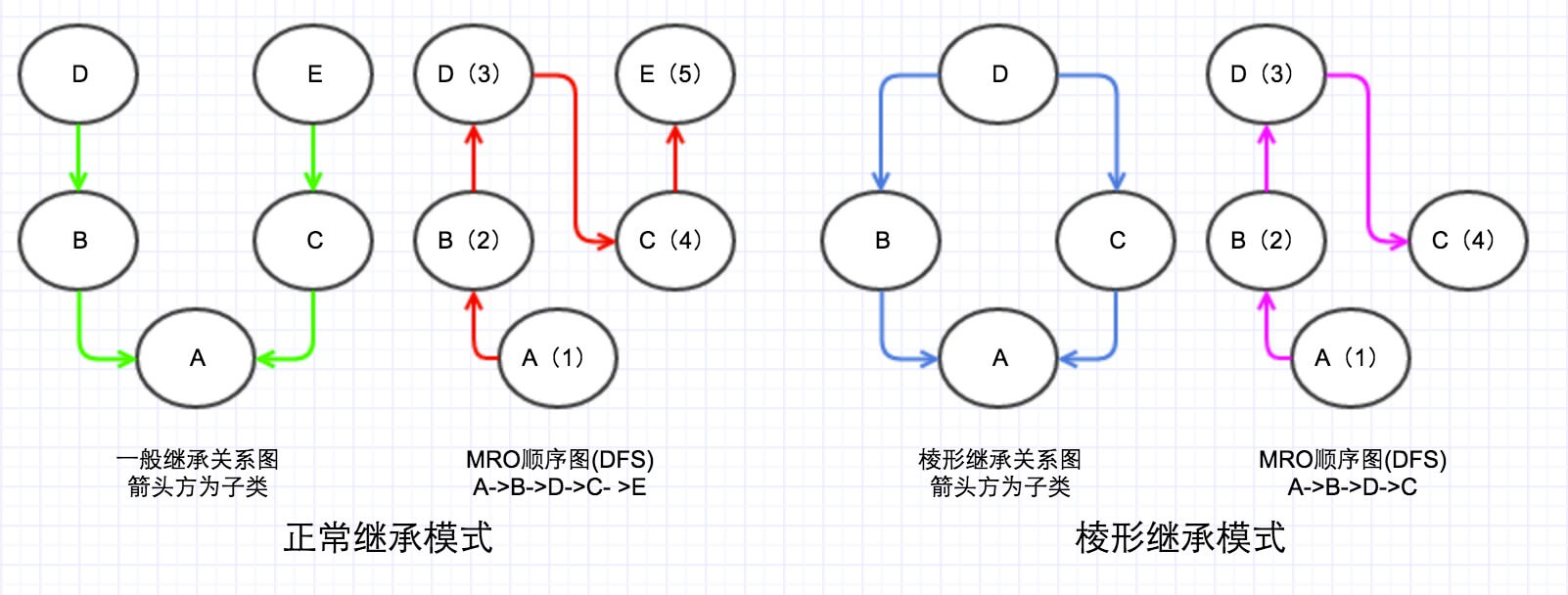
第一种
我称为正常继承模式,两个互不相关的类的多继承,这种情况DFS顺序正常,不会引起任何问题;
第二种
棱形继承模式,存在公共父类(D)的多继承(有种D字一族的感觉),这种情况下DFS必定经过公共父类(D),这时候想想,如果这个公共父类(D)有一些初始化属性或者方法,但是子类(C)又重写了这些属性或者方法,那么按照DFS顺序必定是会先找到D的属性或方法,那么C的属性或者方法将永远访问不到,导致C只能继承无法重写(override)。这也就是为什么新式类不使用DFS的原因,因为他们都有一个公共的祖先object。
Python2.2版本:新式类(new-style class)诞生
为了使类和内置类型更加统一,引入了新式类。新式类的每个类都继承于一个基类,可以是自定义类或者其它类,默认承于object。子类可以调用父类的构造函数
这时有两种MRO的方法
1. 如果是经典类,MRO为DFS(深度优先搜索(子节点顺序:从左到右))。
2. 如果是新式类,MRO为BFS(广度优先搜索(子节点顺序:从左到右))。
Class A(object): # 继承于object
def __init__(self):
print ("这是新式类")
A.__mro__ 可以查看新式类的顺序
MRO的BFS顺序如下图:
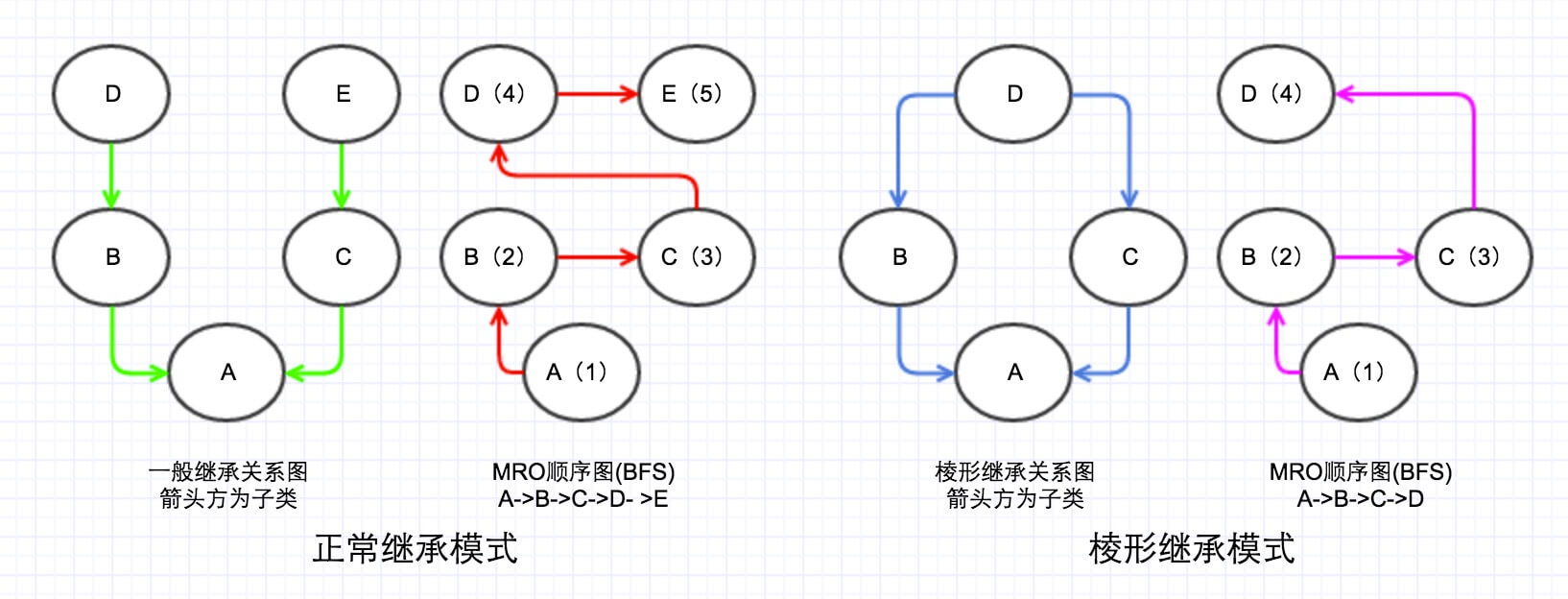
两种继承模式在BFS下的优缺点。
第一种
正常继承模式,看起来正常,不过实际上感觉很别扭,比如B明明继承了D的某个属性(假设为foo),C中也实现了这个属性foo,那么BFS明明先访问B然后再去访问C,但是为什么foo这个属性会是C?这种应该先从B和B的父类开始找的顺序,我们称之为单调性。
第二种
棱形继承模式,这种模式下面,BFS的查找顺序虽然解了DFS顺序下面的棱形问题,但是它也是违背了查找的单调性。
因为违背了单调性,所以BFS方法只在Python2.2中出现了,在其后版本中用C3算法取代了BFS。
Python2.3到Python2.7:经典类、新式类和平发展
因为之前的BFS存在较大的问题,所以从Python2.3开始新式类的MRO取而代之的是C3算法,我们可以知道C3算法肯定解决了单调性问题,和只能继承无法重写的问题。C3算法具体实现稍后讲解。
MRO的C3算法顺序如下图:看起简直是DFS和BFS的合体有木有。但是仅仅是看起来像而已。

Python3到至今:新式类一统江湖
Python3开始就只存在新式类了,采用的MRO也依旧是C3算法。
神奇的算法C3
C3算法解决了单调性问题和只能继承无法重写问题,在很多技术文章包括官网中的C3算法,都只有那个merge list的公式法,想看的话网上很多,自己可以查。但是从公式很难理解到解决这个问题的本质。我经过一番思考后,我讲讲我所理解的C3算法的本质。如果错了,希望有人指出来。
假设继承关系如下(官网的例子):
class D(object):
pass
class E(object):
pass
class F(object):
pass
class C(D, F):
pass
class B(E, D):
pass
class A(B, C):
pass
if __name__ == '__main__':
print A.__mro__
首先假设继承关系是一张图(事实上也是),我们按类继承是的顺序(class A(B, C)括号里面的顺序B,C),子类指向父类,构一张图。
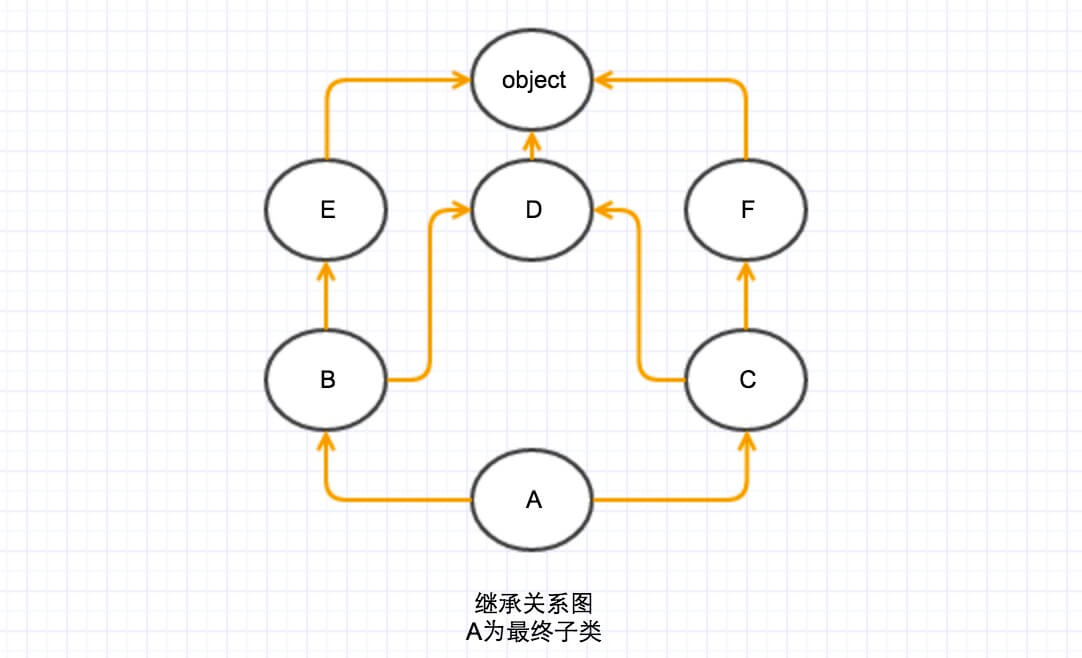
我们要解决两个问题:单调性问题和不能重写的问题。
很容易发现要解决单调性,只要保证从根(A)到叶(object),从左到右的访问顺序即可。
那么对于只能继承,不能重写的问题呢?先分析这个问题的本质原因,主要是因为先访问了子类的父类导致的。那么怎么解决只能先访问子类再访问父类的问题呢?如果熟悉图论的人应该能马上想到拓扑排序,这里引用一下百科的的定义:
对一个有向无环图(Directed Acyclic Graph简称DAG)G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边(u,v)∈E(G),则u在线性序列中出现在v之前。通常,这样的线性序列称为满足拓扑次序(Topological Order)的序列,简称拓扑序列。简单的说,由某个集合上的一个偏序得到该集合上的一个全序,这个操作称之为拓扑排序。
因为拓扑排序肯定是根到叶(也不能说是叶了,因为已经不是树了),所以只要满足从左到右,得到的拓扑排序就是结果,关于拓扑排序算法,大学的数据结构有教,这里不做讲解,不懂的可以自行谷歌或者翻一下书,建议了解完算法再往下看。
那么模拟一下例子的拓扑排序:首先找入度为0的点,只有一个A,把A拿出来,把A相关的边剪掉,再找下一个入度为0的点,有两个点(B,C),取最左原则,拿B,这是排序是AB,然后剪B相关的边,这时候入度为0的点有E和C,取最左。这时候排序为ABE,接着剪E相关的边,这时只有一个点入度为0,那就是C,取C,顺序为ABEC。剪C的边得到两个入度为0的点(DF),取最左D,顺序为ABECD,然后剪D相关的边,那么下一个入度为0的就是F,然后是object。那么最后的排序就为ABECDFobject。
对比一下 A.__mro__的结果
(<class '__main__.A'>, <class '__main__.B'>, <class '__main__.E'>, <class '__main__.C'>, <class '__main__.D'>, <class '__main__.F'>, <type 'object'>)
总结
1、经典类,使用深度优先算法。因为新式类继承自 object,新的菱形类继承结构出现,问题也就接着而来了,所以必须新建一个 MRO。
2、Python的类如果继承了多个类,那么其寻找方法的方式有两种,分别是:深度优先和广度优先
- 当类是经典类时,多继承情况下,会按照深度优先方式查找
- 当类是新式类时,多继承情况下,会按照广度优先方式查找
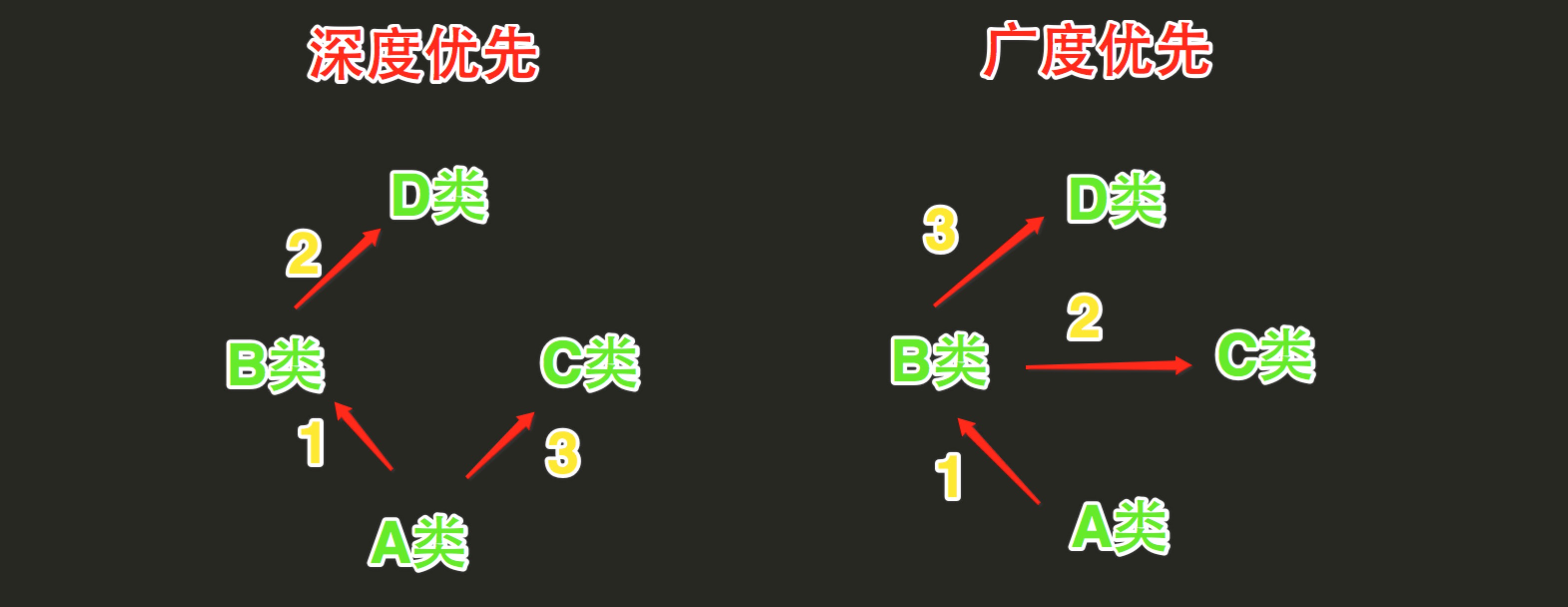
经典类和新式类,从字面上可以看出一个老一个新,新的必然包含了跟多的功能,也是之后推荐的写法,从写法上区分的话,如果 当前类或者父类继承了object类,那么该类便是新式类,否则便是经典类

经典类多继承:
#!/usr/bin/env python
#coding:utf8
class D:
def bar(self):
print 'D.bar'
class C(D):
def bar(self):
print 'C.bar'
class B(D):
def bar(self):
print 'B.bar'
class A(B, C):
def bar(self):
print 'A.bar'
a = A()
# 执行bar方法时
# 首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中没有,则继续去D类中找,如果D类中没有,则继续去C类中找,如果还是未找到,则报错
# 所以,查找顺序:A --> B --> D --> C
# 在上述查找bar方法的过程中,一旦找到,则寻找过程立即中断,便不会再继续找了
a.bar()
新式类多继承:
#!/usr/bin/env python
#coding:utf8
class D(object):
def bar(self):
print 'D.bar'
class C(D):
def bar(self):
print 'C.bar'
class B(D):
def bar(self):
print 'B.bar'
class A(B, C):
def bar(self):
print 'A.bar'
a = A()
# 执行bar方法时
# 首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中没有,则继续去C类中找,如果C类中没有,则继续去D类中找,如果还是未找到,则报错
# 所以,查找顺序:A --> B --> C --> D
# 在上述查找bar方法的过程中,一旦找到,则寻找过程立即中断,便不会再继续找了
a.bar()
经典类:首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去D类中找,如果D类中么有,则继续去C类中找,如果还是未找到,则报错
新式类:首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去C类中找,如果C类中么有,则继续去D类中找,如果还是未找到,则报错
注意:在上述查找过程中,一旦找到,则寻找过程立即中断,便不会再继续找了
总结:
1.只有在python2中才分新式类和经典类,python3中统一都是新式类
2.在python2中,没有显式的继承object类的类,以及该类的子类,都是经典类
3.在python2中,显式地声明继承object的类,以及该类的子类,都是新式类
4.在python3中,无论是否继承object,都默认继承object,即python3中所有类均为新式类
5.如果没有指定基类,python的类会默认继承object类,object是所有python类的基类,它提供了一些常见方法(如__str__)的实现。
总结
经典类 :在python2.*版本才存在,且必须不继承object
遍历的时候遵循深度优先算法
没有mro方法
没有super()方法
新式类 :在python2.X的版本中,需要继承object才是新式类
遍历的时候遵循广度优先算法
在新式类中,有mro方法
有super方法,但是在2.X版本的解释器中,必须传参数(子类名,子类对象)
今日内容总结:
组合
组合就是让不同的类混合并加入到其它类中来增加功能和代码重用性
可以在一个大点的类中创建其它类的实例,实现一些其它属性和方法来增强对原来的类对象
为了增加功能和代码重用性,有2种方法:
1.组合:组合就是让不同的类混合并加入到其它类中来增加功能和代码重用性。
2.继承:子类继承父类的方法
实现组合
1、创建复合对象、应用组合可以实现附加的功能
2、例如,通过组合实现上述地址薄功能的增强
addrbook3.py内容:组合
#!/usr/bin/env python
#coding:utf8
class Info(object):
def __init__(self,ph,em,qq):
self.phone = ph
self.email = em
self.qq = qq
def get_phone(self):
return self.phone
def update_phone(self,newph):
self.phone =newph
class AddrBook(object):
def __init__(self,nm,ph,em,qq):
self.name = nm
self.info = Info(ph,em,qq)
if __name__ == "__main__":
bob = AddrBook("Bob Green","15011223344","bob@tedu.cn","12423234")
print bob.info.get_phone()
执行结果:
15011223344
先来看两个例子:
先定义两个类,一个老师类,老师类有名字,年龄,出生的年,月和日,所教的课程等特征以及走路,教书的技能。
class Teacher(object):
def __init__(self,name,age,year,mon,day):
self.name=name
self.age=age
self.year=year
self.mon=mon
self.day=day
def walk(self):
print "%s is walking slowly" % self.name
def teach(self):
print "%s is teaching" % self.name
再定义一个学生类,学生类有名字,年龄,出生的年,月和日,学习的组名等特征以及走路,学习的技能
class Student(object):
def __init__(self,name,age,year,mon,day):
self.name=name
self.age=age
self.year=year
self.mon=mon
self.day=day
def walk(self):
print "%s is walking slowly"%self.name
def study(self):
print "%s is studying"%self.name
根据类的继承这个特性,可以把代码缩减一下。
定义一个人类,然后再让老师类和学生类继承人类的特征和技能:
#!/usr/bin/env python
#coding:utf8
class People(object):
def __init__(self, name, age, year, mon, day):
self.name = name
self.age = age
self.year = year
self.mon = mon
self.day = day
def walk(self):
print "%s is walking" % self.name
class Teacher(People):
def __init__(self, name, age, year, mon, day, course):
super(Teacher,self).__init__(name,age,year,mon,day)
# 或者 People.__init__(self,name,age,year,mon,day)
self.course = course
def teach(self):
print "%s is teaching" % self.name
class Student(People):
def __init__(self, name, age, year, mon, day, group):
super(Student,self).__init__(name, age, year, mon, day)
# 或者 People.__init__(self,name,age,year,mon,day)
self.group = group
def study(self):
print "%s is studying" % self.name
再对老师和学生进行实例化,得到一个老师和一个学生。
t1=Teacher("alex",28,1989,9,2,"python")
s1=Student("jack",22,1995,2,8,"group2")
现在想知道t1和s1的名字,年龄,出生的年,月,日都很容易,但是想一次性打印出t1或s1的生日就不那么容易了,这时就需要用字符串进行拼接了,有没有什么更好的办法呢??那就是组合。
可以说每个人都有生日,而不能说人是生日,这样就要使用组合的功能 。
可以把出生的年月和日另外再定义一个日期的类,然后用老师或者是学生与这个日期的类
组合起来,就可以很容易得出老师t1或者学生s1的生日了,再也不用字符串拼接那么麻烦了。
来看下面的代码:
#!/usr/bin/env python
#coding:utf8
class Date(object):
def __init__(self,year,mon,day):
self.year=year
self.mon=mon
self.day=day
def birth_info(self):
print "The birth is %s-%s-%s" % (self.year,self.mon,self.day)
class People(object):
def __init__(self, name, age, year, mon, day):
self.name = name
self.age = age
self.birth = Date(year, mon, day)
def walk(self):
print "%s is walking" % self.name
class Teacher(People):
def __init__(self, name, age, year, mon, day, course):
super(Teacher,self).__init__(name,age,year,mon,day)
# 或者 People.__init__(self,name,age,year,mon,day)
self.course = course
def teach(self):
print "%s is teaching" % self.name
class Student(People):
def __init__(self, name, age, year, mon, day, group):
super(Student,self).__init__(name, age, year, mon, day)
# 或者 People.__init__(self,name,age,year,mon,day)
self.group = group
def study(self):
print "%s is studying" % self.name
t1=Teacher("alex",28,1989,9,2,"python")
s1=Student("jack",22,1995,2,8,"group2")
print(t1.name)
t1.walk()
t1.teach()
print(t1.birth)
这样一来,可以使用跟前面一样的方法来调用老师t1或学生s1的姓名,年龄等特征以及走路,教书或者学习的技能。
print(t1.name)
t1.walk()
t1.teach()
输出为:
alex
alex is walking
alex is teaching
那要怎么能够知道他们的生日呢:
print(t1.birth)
输出为:
<__main__.Date object at 0x0000000002969550>
这个birth是子类Teacher从父类People继承过来的,而父类People的birth又是与Date这个类组合在一起的,所以,这个birth是一个对象。而在Date类下面有一个birth_info的技能,这样就可以通过调用Date下面的birth_info这个函数属性来知道老师t1的生日了。
t1.birth.birth_info()
得到的结果为:
The birth is 1989-9-2
同样的,想知道实例学生s1的生日也用同样的方法:
s1.birth.birth_info()
得到的结果为:
The birth is 1995-2-8
组合就是一个类中使用到另一个类,从而把几个类拼到一起。组合的功能也是为了减少重复代码。
组合参考:
https://www.cnblogs.com/renpingsheng/p/7132407.html
参考:
https://www.cnblogs.com/mingmingming/p/11199890.html
https://www.cnblogs.com/xiaohei001/p/9791749.html

