关于字符串输入输出的若干函数
 分析 C 语言中各种输入和输出函数的对比
分析 C 语言中各种输入和输出函数的对比
在 C 语言中,通过 <stdio.h> 可以使用一些非常有帮助的函数来从标准输入流 (或文件流,本篇不涉及) 中读入字符串,或者向标准输出流 (或文件流) 中写入字符串。这篇笔记整理的是这些相关函数的异同以及适用场景。
标准输入流的使用
使用场景
区别一:是否限定读入字符数量
为了分析它们的用途,我们要考虑具体的使用场景和限制。通常,读入字符串的操作可以分为 限定长度 和 不限定长度 两种。后者因为可能导致缓冲区溢出 (buffer overflow) 进而产生对未分配内存的占用或是擦出程序中其它代码的数据,最终导致程序出错。所以前者应该是更为常用的,并且不易出错。
需要说明的是,这里的 限定长度 不是指定义存储字符串的容器变量时给定长度 (如定义一个字符数组),而是要求控制输入的函数限制从标准输入流中取用字符的数量。
从这个角度,处理标准输入流输入的函数包括两类:
- 强制要求限定长度的:
fgets()和gets_s() - 不要求限定长度的:
- 可选限定长度的:
scanf() - 不能限定长度的:
gets()
- 可选限定长度的:
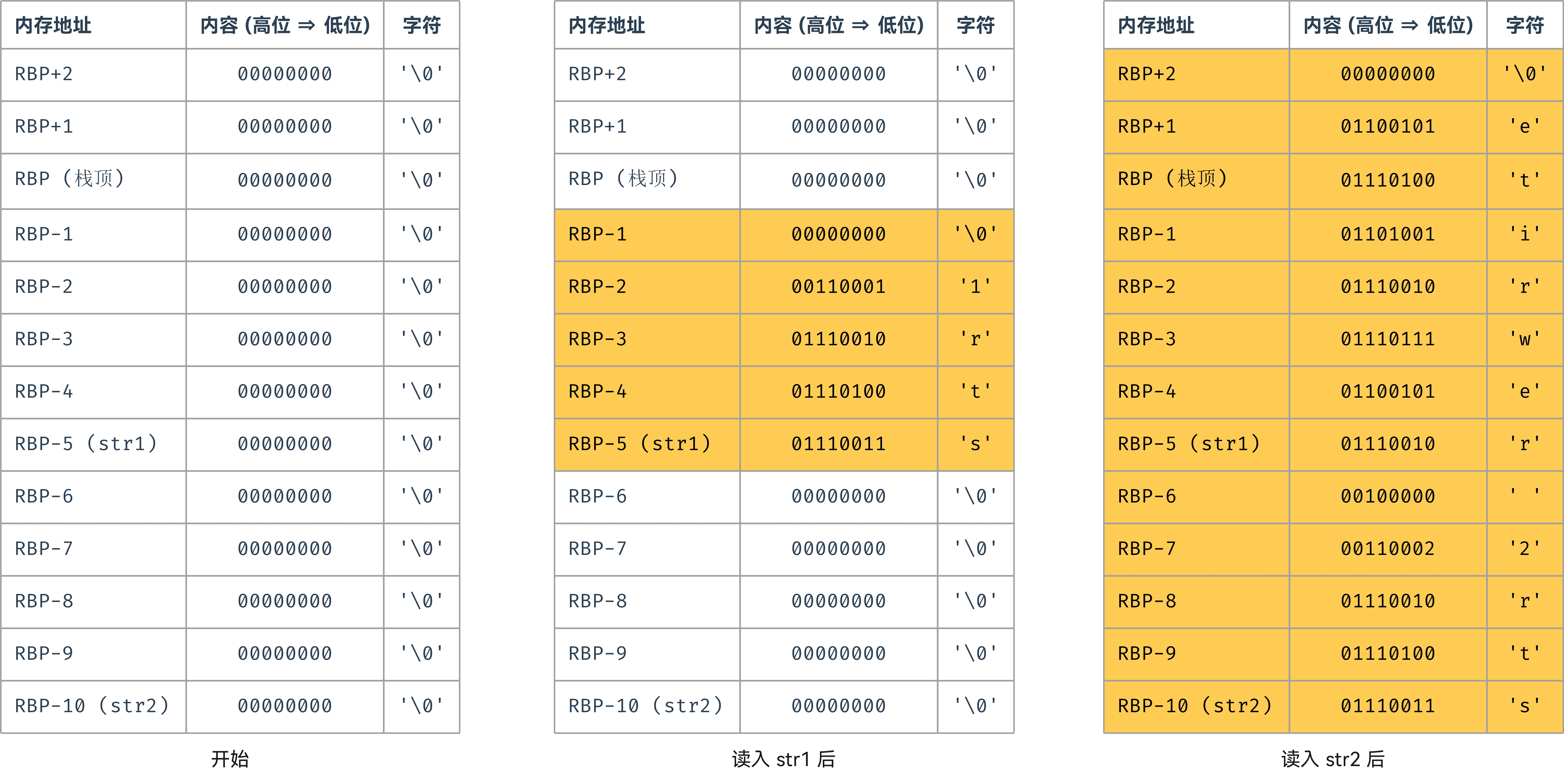
让我们来观察一段 C 语言代码和对应的汇编语句,然后分析为什么产生下列的输入和输出:
char str1[5]; char str2[5]; gets(str1); gets(str2); printf("[%s]", str1); printf("[%s]", str2);
var_A= byte ptr -0Ah var_5= byte ptr -5 push rbp mov rbp, rsp sub rsp, 30h call __main lea rax, [rbp+var_5] mov rcx, rax call gets lea rax, [rbp+var_A] mov rcx, rax call gets
以下是输入和输出内容:
>>>> str1 >>>> str2 rewrite <<<< [rewrite][str2 rewrite]
>>>>表示输入,<<<<表示输出
从输入的内容来看,两个变量 str1 和 str2 的内容本应该分别是
['s', 't', 'r', '1', '\0']['s', 't', 'r', '2', ' ']
但是却输出了:
['r', 'e', 'w', 'r', 'i', 't', 'e', '\0']['s', 't', 'r', '2', ' ', 'r', 'e', 'w', 'r', 'i', 't', 'e', '\0']
显然,第一个字符串 str1 的值被第二个的内容给覆盖了。这一点从汇编代码中 var_5 的地址比 var_A 高 5 个字节可以看出。gets() 函数读取 str2 的输入 "str2 rewrite" 时,本身的 5 个字节全部被用尽 (['s', 't', 'r', '2', ' ']),后续读入的字符覆盖到了 str1 的地址空间 (['r', 'e', 'w', 'r', 'i']),剩下的字符继续从栈顶地址开始往高地址处覆盖。最终进行打印时,str2 会打印完整内容,str1 会从被覆盖的地址处开始打印,直到超过栈顶遇到 '\0' 终结符。参见下面的图示可以了解这个过程:
从程序安全的角度来说,gets() 函数因为其潜在导致程序出错的风险,所以被 C11 标准废弃[1]。如果使用 scanf("%s", str) 这样的形式,并且标准输入流当中不包含空白字符[2],本质上和 gets(str) 没有区别,都存在导致缓冲区溢出的风险。
因此,从标准输入流中读入字符串时,应该尽量使用带有长度限定的函数,或是使用长度限定标记。比如 scanf("%10s", str) 就相当于 gets_s(str, 10),都实现了从标准输入流读入 10 个字符。
区别二:是否保留换行符
有时我们需要保留原始输入中的换行,便于在输出的时候保持原来输入的段落结构。但有时候我们只是需要每一行本身的内容,而不需要保留换行符 '\n'。针对这种场景,可以将这些函数划分为两类:
- 保留换行符:
fgets() - 不保留换行符:
gets(),gets_s()和scanf()
值得注意的是,考虑到前面讨论过的各个函数对输入长度的限制,fgets() 只有在本次读取没有耗尽全部允许读入的字数时才能够保留换行符。一旦超过,也会被保留在输入流中,等待后续取用。
区别三:对空白字符的处理
在 输入字符串的长度超过允许读入的字符限制 时 (也就意味着排除了 gets() 函数),如果读入的字符部分包含了空白字符[2:1],根据处理方式可以分为:
- 无差别结束输入捕获:
scanf() - 仅
'\n'时结束输入捕获:fgets()和gets_s()
这一特性使得 scanf() 可以作为 Latin 字符集输入的最佳单词拆分函数,根据空格和换行进行拆分读取。而 fgets() 和 gets_s() 更适合按行处理的场景。
区别四:输入字符串超过长度限定的处理
注意,这里的字符串有一个前置条件:在长度不超过限定的范围内,不能包含换行符。我们面向这个场景提出对比,最主要是针对 fgets() 和 gets_s() 两个函数。
既然不能包含换行符,那么意味着输入字符串在超长之前会被毫无丢弃地保留下来。但是,当超长时:
fgets()会正常中断读入,剩余字符保留在输入缓冲区中;gets_s()会使用'\0'将字符串清空 (只处理首字符),然后 丢弃输入缓冲区剩余字符,并调用相应的“处理函数”。
所以,如果我们希望 在超长的情况下仍然能正常获取字符串,然后丢弃剩余内容,或者 只读入输入中的第一行,剩余内容不处理,就只能使用 fgets() 函数。但是如果一开始的前置条件不成立怎么办?让我们来进一步完善它吧!
进一步完善 fgets()
我们知道 fgets() 可以从标准输入流和文件流读入字符串,此时按照是否超过长度限定和是否包含换行符 '\n':
- 如果没有超过长度限定
- 遇到
'\n',会结束读入,然后包含'\n'符号; - 没有遇到
'\n',会持续读入,直到输入耗尽;
- 遇到
- 如果超过长度限定
- 遇到
'\n',会结束读入,然后包含'\n'符号; - 没有遇到
'\n',会持续读入,直到输入到达长度限定。
- 遇到
那么我们的逻辑就是:
- Step 1: 当读入结束时,判断
fgets()函数的返回值:- 如果是
NULL,结束; - 如果不是
NULL,跳转Step 2
- 如果是
- Step 2: 从头开始遍历长度限定范围内的全部字符,直到当前字符为
'\0'或'\n':- 如果是
'\n',说明遇到换行。此时应该把当前字符改成'\0',然后结束 (剩余字符不处理); - 如果是
'\0',说明已经结束了,循环消耗流中的剩余字符直到为空。
- 如果是
以上是 C 语言中使用 stdio.h 提供的若干输入函数时需要注意的它们的限制、适用条件。请继续阅读另一部分关于输出函数的分享。
(未完待续)
注意,是否允许带有
gets()的函数取决于你所使用的库是否遵从 C11 标准,而不是具体的 GCC 编译器。 ↩︎空白字符包括但不限于空格符、空行符、换行符、制表符等。参见维基百科中的定义 Whitespace_character。 ↩︎ ↩︎


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!