
JAVASE8流库Stream学习总结(二)
在JAVASE8流库Stream入门(一)中,我们已经看到了怎么创建流,接下来我们要对所创建的流进行进一步的操作
如果你还没不知道怎么创建流,那么请移步JAVASE8流库Stream入门(一)
转换流
什么是转换流,流的转换在我看来实际上是对集合的一种操作。
1、利用fliter()进行转换
fliter的中文意思的过滤器,在IO流中也有类似的概念。就像是用一个筛子把原先流中的元素进行筛选,这就是它的功能
例如:
Stream<String> stream5 = Stream.of("the most handsome man in the world is ZhongHaoWei".split(" ")).filter(w->w.length()>4);
show("fliter", stream5);输出:
fliter:
handsome,world,ZhongHaoWei
我们把流中长度在4以上的元素筛选出来了。
fliter()方法接收Predicate<T>参数,Predicate的中文意思的断言,判断
也就是说predicate参数是一个判断式,很像Lambda吧,其实也可以把断言看成Lambda
,我觉得他就是Lambda中的一种,只不过他与Lambda表达式的不同是
predicate的返回值只能是boolean
我们也可以看下Predicate<T>的接口说明
public interface Predicate<T> {
boolean test(T t);
}
因此,我们可以用Predicate来测试我们的输入或流是否符合某种要求
举个栗子:
Predicate<String> a=w->w.length()>4;
String test1="XiaoZhongZuiShuai";
String test2="hehe";
System.out.println(a.test(test1));
System.out.println(a.test(test2));输出:
true
false
使用fliter()进行流的转换的时候,我们只需要记住我们所写的表达式返回的是一个布尔量就行了
2、利用map()方法进行转换流
我们现在已经知道,如果要对流进行筛选,则使用fliter()方法可以解决这个问题,那如果要对流中的元素进行操作呢,没错,
我们可以使用map()方法。map()与fliter()不同的地方在于前者是对流元素的操作,他会把流中每个元素应用到某个函数上,然后
转换成新的流,而后者是对流元素的筛选,利用某种断言或判断对流元素进行选择,最后的结果也只有元素保留和元素去除两种
结果。
先来看看用法:
Stream<String> stream6=Stream.of("the most handsome man in the world is ZhongHaoWei".split(" ")).map(s->s.toLowerCase());
show("lowerCase", stream6);
输出:
lowerCase:
the,most,handsome,man,in,the,world,is,zhonghaowei
上面这个例子我们利用map方法对流元素进行了操作,使用也很简单。相信看一下都能懂。
和map()方法类似的还有一个flatMap()方法,这个方法在处理“流的流”也就是嵌套流中使用
先看两个例子:
Stream<String> stream7=Stream.of("the most handsome man in the world is ZhongHaoWei".split(" ")).flatMap(s->Stream.of(s.toLowerCase()));
show("flatMap", stream7);
Stream<Stream<String>> stream8=Stream.of("the most handsome man in the world is ZhongHaoWei".split(" ")).map(s->Stream.of(s.toLowerCase()));
show("map", stream8);
输出:
flatMap:
the,most,handsome,man,in,the,world,is,zhonghaowei
map:
java.util.stream.ReferencePipeline$Head@7d417077,java.util.stream.ReferencePipeline$Head@7dc36524,java.util.stream.ReferencePipeline$Head@35bb e5e8,java.util.stream.ReferencePipeline$Head@2c8d66b2,java.util.stream.ReferencePipeline$Head@5a39699c,java.util.stream.ReferencePipeline$Head@3cb5cdba,java.util.stream.ReferencePipeline$Head@56cbfb61,java.util.stream.ReferencePipeline$Head@1134affc,java.util.stream.ReferencePipeline$Head@d041cf
当我们的转换以某种方式转换流并且结果是流的时候,我们就可以使用flatMap来“抽出”嵌套流中元素,就像把嵌套的流给“拍扁”了,变成与之同一层次的map()。可以看到stream7和stream6是结果是相同的。
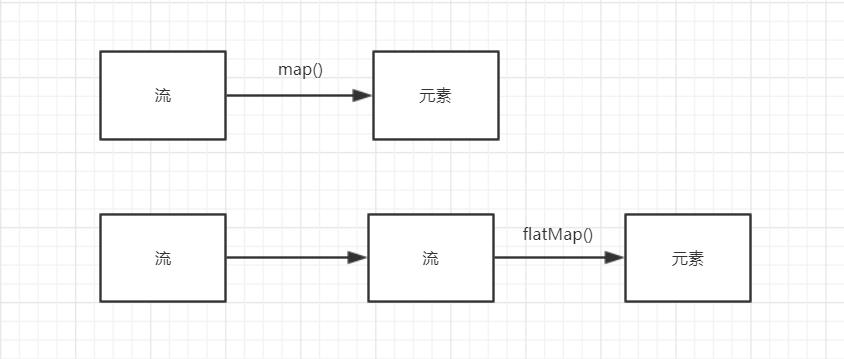
就像上图所示的这样,flatMap()是针对我们转换的表达式的结果是一个流的时候,对结果流中的元素进行操作的一个方法。
另外,看一下stream8和stream7,也可以很明显地看见二者的不同。
总结:map产生一个流,它包含表达式(我们给定的)应用于当前流中的所有元素产生的结果
flatMap,它将表达式应用于当前流中的所有元素,产生一个流结果,再对流结果的元素操作。
3、抽取子流
对流进行的操作还有裁剪,跳过,连接,去重复,排序
- 裁剪操作:利用stream.limit(n)操作完成,它会返回新的流,其中包含n个元素(如果原先的流小于n,则裁剪出的流的大小与原先流的大小一致)
- Stream<Double> stream9=Stream.generate(Math::random).limit(10);
- 会产生一个包含10个数的随机数流,裁剪操作对于无限流特别有用
- 跳过:利用stream.skip(n)跳过元素,它将跳过前n个元素
- 连接:利用Stream类的静态方法concat()对两个流进行连接,当然,只能对同一种类型的流进行连接,这个很简单,就不写例子了
- 去重复:stream.distinct返回一个流,它的元素从流中产生,但是元素的顺序保留并且剔除了重复元素,这个和数据库的那个DISTINCT的意思是一样的
- 排序:stream.sorted()对元素进行排序,接收一个Comparator参数

