
JAVASE8流库Stream学习总结(三)
3、聚合(终止流操作)
前面我们已经看到过如何创建流和转换流了,现在是时候让流终止,并返回些有用的东西给我们了,这个过程就叫做聚合,
也叫约简。
一、Optional类
讲到这个,我们先从Optional类讲起,什么是Optional类,Optional<T>是一种包装器对象,他可以对空值进行了处理,比直接
使用某个对象更加安全。例如,我们如果现在有个函数int a(int x),和函数int b(int y),如果一个函数的返回值作为另一个函数的参数
,就比如a(b(x))吧 b(x)的返回值要保证不是空值才行,否则会抛出空指针异常。简而言之,Optional是一个可以允许所包含的对象
为null的的容器。
创建Optional类:
- Optional.of(T value)
- Optional.ofNullable(T value)
- Optional.empty();
第一种方法接收一个对象,返回一个含义该对象的Optional对象,但他不接收null,否则会抛出NullPointerException异常
第二种方法接收一个对象,也接收null,返回一个含义该对象的Optional对象,这个Optional对象可以是空的。
第三种方法就直接创建一个空的Optional
举个栗子:
public static void main(String[] args) {
Optional<String> optional1=Optional.ofNullable(null);
System.out.println(optional1);
try {
Optional<String> optional2=Optional.of(null);
System.out.println(optional2);
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
输出:
Optional.empty
java.lang.NullPointerException
at java.base/java.util.Objects.requireNonNull(Objects.java:221)
at java.base/java.util.Optional.<init>(Optional.java:106)
at java.base/java.util.Optional.of(Optional.java:119)
at 创建流.OptionalUse.main(OptionalUse.java:10)
可以看到,当使用第二种方法也就是ofNullable方法时,如果传入的对象为空,就直接返回一个空的Optional对象,避免了空指针对象
而使用of方法时,传入的对象为null时,则会抛出NullPointerException异常
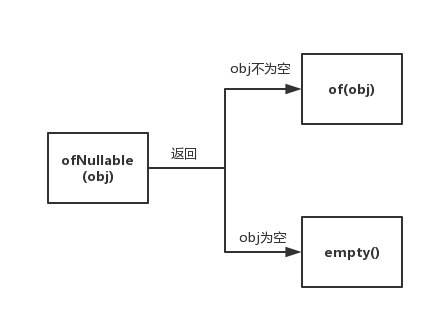
实际上,我们通过ofNullable()方法的源码也可以发现,它被用来作为可能出现null值和可选值之间的桥梁。他在传入的值不为空的时候
返回Option.of(obj),在传入的值为空时则,返回Optional.empty();
ofNullable源码:
public static <T> Optional<T> ofNullable(T value) {
return value == null ? empty() : of(value);
}
现在我们已经会创建Optional对象了,那接下来就要看看他是如何使用的
使用Optional对象
我们已经知道Optional对象是一种更加安全的对象,因为他对空值进行了处理,那也就是说,他的使用方法
得像这样:他会在值不存在的情况下产生一个“替代物”代替null,在值存在的情况下则使用该值
我们先看下第一种情况,在值不存在的时候怎么办:
当值不存在时:
1、给默认值
public class OptionalUse {
public static void main(String[] args) {
Optional<String> optional=Optional.ofNullable(null);
String result=optional.orElse("empty String");
System.out.println(result);
}
}
输出:
empty String
可以看到,利用orElse()方法,我们为没有Optional对象为空的情况指定了一个默认值,调用时若为空则返回指定的
默认值。
2、给处理方法得出默认值
public class OptionalUse {
public static void main(String[] args) {
Optional<String> optional=Optional.ofNullable(null);
String result=optional.orElseGet(()->Locale.getDefault().getDisplayName());
System.out.println(result);
}
}
输出:
中文 (中国)
同样的,我们指定了一个方法为默认方法(上面那个方法的作用是返回本地语言和国家)
3、抛出某个异常
public class OptionalUse {
public static void main(String[] args) {
Optional<String> optional=Optional.ofNullable(null);
String result=optional.orElseThrow(RuntimeException::new);
System.out.println(result);
}
}
输出:
Exception in thread "main" java.lang.RuntimeException
at java.base/java.util.Optional.orElseThrow(Optional.java:385)
at 创建流.OptionalUse.main(OptionalUse.java:9)
这个应该就没什么好解释了的,默认指定为抛出一个异常
当值存在时:
当值存在时,我们可以对值进行操作,注意:这种操作是可能改变Optional本身包含的值的。
1、利用void ifPresent(Supplier <? extemds T> s)
Supplier有点熟悉吧,他其实就是一个Lambda表达式,我们在创建流的generate()方法中有看到过。
public class OptionalUse {
public static void main(String[] args) {
Optional<String> optional=Optional.ofNullable("XiaoZhong");
String result=optional.orElseThrow(RuntimeException::new);
optional.ifPresent(w->System.out.println(w.toUpperCase()));
//这个get()是获取Optional对象中的元素
System.out.println(optional.get());
}
}
输出:
XIAOZHONG
XiaoZhong
前面说到,这种操作是可能改变Optional本身包含的值的。
可以看到,在ifPresent()方法里,我们对该值进行了大小写转换并作出了打印操作,然后再一次的在ifParesent()外面
验证了一下Optional中的值是否被改变了。发现值并没有被改变。
但你有可能会想,ifPresent()把参数传递给某个函数的时候是值传递,如果传递某个具体的对象呢(其实这个String已经是个对象了),
保险起见,我们再验证一下。
public class OptionalUse {
public static class Id {
private static int count=0;
private final int id=count++;
public String name="Zhong";
public Id() {
// TODO Auto-generated constructor stub
}
@Override
public String toString() {
// TODO Auto-generated method stub
return "ID: "+ id +"\nNAME: " + name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
public static void main(String[] args) {
Optional<Id> optional=Optional.ofNullable(new Id());
//这个get()是获取Optional对象中的元素
System.out.println(optional.get());
optional.ifPresent(w->w.setName("you name"));
System.out.println(optional.get());
}
}
输出:
ID: 0
NAME: Zhong
ID: 0
NAME: you name
这里简单地写了一个内部类,这个内部类用来记录一个人ID和名字,名字默认是Zhong,我们想通过在ifPresent()中调用内部类的
set方法,来看是否发生了改变,结果显而易见,的确发生了改变
其实我们在传递参数的时候,当传入的基本数据类型时,是值传递,而传入的是数组,对象时则是引用传递,这一点同样适用于在
ifPresent()中参数的传递
2、利用map()对值进行操作
先上代码
Optional<String> optional2=Optional.ofNullable(null);
List<String> list=new ArrayList<String>();
optional2.map(list::add);
System.out.println(list);
optional2=Optional.of("Hello World");
optional2.map(list::add);
System.out.println(list);
输出:
[]
[Hello World]
map()对Optional中的值进行操作,这里是把值加入到list中,list的add有两种情况,当Optional为空时,则返回空的Optional,不为空则返回某个字符串。
这里的”::“操作符,是lambda表达式对方法的调用,叫做method reference。大家可以看看这两个资料:
中文版:http://zh.lucida.me/blog/java-8-lambdas-insideout-language-features/
英文版:http://www.techempower.com/blog/2013/03/26/everything-about-java-8/
这里有详细地讲述,JAVA8中Lambda表达式的用法。
3、利用flatMap()来构建Optional值的函数
假设你有一个可以产生Optional<T>的f方法,泛型T又有一个可以产生Optional<U>的方法g,你想通过f获得U目标对象
很自然地会想到 这样组合 s.f().g(),然而这样无法工作,因为s.f()是Optional<T>类型的,而不是T类型的

可以使用Optional<U>=s.f().flatMap(T::g) 来获得U,这和之前的stream.flatMap()很类似,也类似把一些嵌套给“拍扁”了,直接取用他们的值
再举个例子:
private static Optional<Double> sum(Double a,Double b){
return Optional.of(a+b);
}
private static Optional<Double> squareRoot(Double x){
return x<0?Optional.empty():Optional.of(Math.sqrt(x));
}
main方法中:
//Optional<Double> result=sum(1.0,1.0).map(a->squareRoot(a)); 不行,编译器会报错,不能把Optional<Double>转换为Double
//flatMap示例
Optional<Double> result=sum(1.0,1.0).flatMap(a->squareRoot(a));
System.out.println(result.get());
输出:
1.4142135623730951
二、收集结果
1、forEach(),将函数应用于每个元素
例如:stream.forEach(System.out::print);
2、iterator(),用来访问元素的迭代器
没错,JAVA8也有迭代器,使用方法和以前的一样,就不写例子了
3、toArray(),将流中的元素转换为数组对象
但是stream.toArray()返回的是Object[]类型的数组,要得到正确类型的数组,我们就得传数组构造器到参数中
例如:String[] result=stream.toArray(String[]::new);
4、转换成Collection
(1)转换成List,利用stream.collect(Collectors.toList())
例如List<String> result=stream.collect(Collectors.toList())
(2)转换成set,利用stream.collect(Collectors.toSet())
例如Set<String> result=stream.collect(Collectors.toSet())
(3)转换成Map,这个要重点记下笔记
a、利用Collectors.toMap()方法
这一种是最简单的,直接指定键和值就可以了
例如:
假设我们有个Stream<Employee>对象stream,Employee有name,city的实例变量,并且具有相对应的get和set方法
现在我们要生成一个Map,以city为键,name为值
Map<String,String> map=stream.collect(Collectors.toMap(Employee:getCity,Employee::getName));
这样就行了,十分简单
但是如果键冲突了怎么办,即一个键对应了多个元素,编译器会抛出IllegalStateException
我们要为toMap再新添一个参数,说明这种情况怎么办
例如:
Map<String,String> map=stream.collect(Collectors.toMap(Employee:getCity,Employee::getName,(existingValue,newValue)->existingValue));
(existingValue,newValue)->existingValue指出了这种情况怎么办,即以原先的元素为准,不添加新元素
或者你也可以选择抛出异常
Map<String,String> map=stream.collect(Collectors.toMap(Employee:getCity,Employee::getName,(existingValue,newValue)->{throw new RuntimeException("SomethingWrong")}));
如果要得到TreeSet,那么再加一个构造参数在收集器中就可以了
Map<String,String> map=stream.collect(Collectors.toMap(Employee:getCity,Employee::getName,(existingValue,newValue)->{throw new RuntimeException("SomethingWrong")},TreeMap::new));
b、利用Collectors.groupingBy()分组获得Map
groupingBy的基本使用方法:
goupingBy方法会产生一个映射表,它的每一个值都对应一个列表

顾名思义,它实际上起的作用就是根据某个关键字进行分类的作用
举个栗子:
下面是用来记录员工的类
public static class Person{
private String name;
public Person(String name) {
// TODO Auto-generated constructor stub
this.name=name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
// TODO Auto-generated method stub
return name;
}
}
public static class Employee{
private Person person;
private String city;
public Employee(Person person, String city) {
this.person = person;
this.city = city;
}
public Employee(String name, String city) {
this.person = new Person(name);
this.city = city;
}
public Person getPerson() {
return person;
}
public void setPerson(Person person) {
this.person = person;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
@Override
public String toString() {
// TODO Auto-generated method stub
return person.toString();
}
}
在main方法中:
List<Employee> employees=Arrays.asList(new Employee("小钟","深圳"),new Employee("小红", "深圳"),new Employee("小齐", "广州"));
//键为城市,list为员工列表
Map<String, List<Employee>> employeeMap= new HashMap<String,List<Employee>>();
//根据城市对员工进行分类
//传统分类
for (Employee employee : employees) {
String city=employee.getCity();
if(employeeMap.get(city)==null) {
List<Employee> employeeList=new ArrayList<Employee>();
employeeList.add(new Employee(employee.getPerson().getName(), city));
employeeMap.put(city,employeeList);
}
else {
List<Employee> employeeList=employeeMap.get(city);
employeeList.add(employee);
}
}
System.out.println(employeeMap);
输出:
{广州=[小齐], 深圳=[小钟, 小红]}
可以看到,如果用传统方法分类步骤繁琐,写代码还有思考一下怎么写
如果我们用groupingBy方法,那就变得直观,而且简单了
//使用groupingBy方法进行分类
Stream<Employee> stream=employees.stream();
employeeMap = stream.collect(Collectors.groupingBy(Employee::getCity));
输出:
{广州=[小齐], 深圳=[小钟, 小红]}
我们只需要短短一行代码,就把stream分好类了,并装入了map中
另外,groupingBy方法和SQL中的group by很类似,不知道大家有没有发现
就相当于 select city from XXX group by city
groupingBy的进一步使用:
利用groupingBy我们还可以进行更进一步的分类操作
在数据库中,我们可以这样来对统计分组中的元素
例如:select city,count(*) from XXX group by city
同样我们用groupingBy也可以做到类似的效果
Map <String,Long> map=stream2.collect(Collectors.groupingBy(Employee::getCity,Collectors.counting()));
System.out.println(map);
输出:
{广州=1, 深圳=2}
这一种东西在SQL中叫做聚合函数,在JAVA8中叫做“下游收集器”。这些函数一般在groupingBy中使用
下面列举一些常见的
- counting 对组中的元素个数进行统计
这个例子上面那个stream2就是。
- summingInt、summingLong、summingDouble,接收组中元素的一个函数(该函数返回值必须是对应类型),产生这些函数返回值的和
例如:
Map<String,Integer> map=stream.collect(Collectors.groupingBy(Employee::getCity,Collectors.summingInt(Employee::getAge)));
这里我在Employee并没有加入age字段,只是为了单纯地想说明一下,我们就假设每个Employee都有一个age字段并且有对应的get,set方法表示他们的年龄
这样我们就获得了每一个城市为键和该城市对应的员工的年龄总和为值的Map
在SQL中,它相当于 select city,sum(age) from XXX group by city
- maxBy,minBy会接收一个比较器,并比较器中相应的值,产生一个拥有最大值或最小值的Optional的对象(Optional用来包装分组元素)
例如:
Map<String,Optional<Employee>> map=stream.collect(Collectors.groupingBy(Employee::getCity,Collectors.maxBy(Comparator.comparing(Employee::getAge)));
这里的map出来的结果是,每个城市为键和该城市对应年龄最大的员工
换成SQL语句就是:select city,employee from XXX where age in (select max(age) from XXX) group by city,employee
minBy也是同理
- mapping方法会产生将函数应用到下游结果上的收集器,并将函数值传递到另一个收集器
举个例子:刚刚我们通过maxby把每个城市年龄最大的员工选出来了,如果在此基础上我们要得到该年龄最大的员工的各种属性,比如ID,性别,电话等等
我们就可以用mapping
语句如下:
假设我们要获得每个城市年龄最大的员工的电话(电话是String 类型,我在类中同样没写这个字段,但假设它有这个字段和相应的get和set)
Map<String,Optional<String>> map=stream.collect(Collectors.groupingBy(Employee::getCity,Collectors.mapping(Employee::getTel,Collectors.maxBy(Comparator.comparing(Employee::getAge)))));
咋一看很复杂,其实理清思路了还是很清晰的,先按City分类,然后在分的组里按照年龄选出最大年龄的员工的电话
对应的SQL语句为
select city,tel from XXX where age in (select max(age) from XXX) group by city,tel

