Python爬虫:基于Scrapy的爬取失踪人口数据小爬虫
Scrapy简介:
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
仓库地址:
https://github.com/XiaoZhong233/missingPerson_spider
说明:
1、数据来源:宝贝回家网
2、数据后处理中加入了经纬度坐标,方便在空间上定位,原始数据是没有这个信息的
技术点:
- scrapy爬虫框架
- mysql连接池技术
- 数据清洗(正则表达式)
- 百度API地理编码

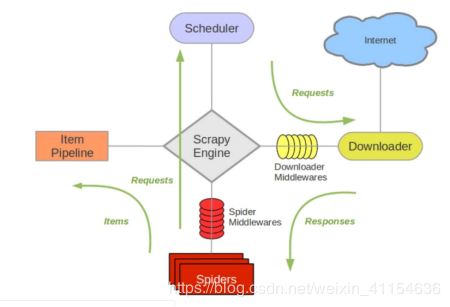
Spider的工作流程,就不具体说了,他是一个很强大的爬虫框架。
运行结果:


爬虫主要代码:
# -*- coding: utf-8 -*-
#更改搜索路径,但没有用哦
import random
import sys
import os
from PersonItem import PersonItem
curPath = os.path.abspath(os.path.dirname(__file__))
rootPath = os.path.split(curPath)[0]
sys.path.append(rootPath)
import scrapy
import json
import re
from urllib.request import urlopen, quote
import datetime
import time
#E:\Desktop\python\zhiyuan_test\zhiyuan_test
#
# PATH = os.environ
# for key in PATH:
# print(key, PATH[key])
#print(rootPath)
#百度坐标地理编码
def getBlnglat(address):
url = 'http://api.map.baidu.com/geocoder/v2/'
output = 'json'
ak = 'O8fpFPd6pw5VYK1uGsdMSAtL5MQRjAjs'
add = quote(address) #为防止乱码,先用quote进行编码
uri = url + '?' + 'address=' + add + '&output=' + output + '&ak=' + ak
req = urlopen(uri)
res = req.read().decode()
temp = json.loads(res)
# print(temp.keys())
# print(temp.values())
# print(type(temp['result']))
if temp['status'] == 0:
lng = temp['result']['location']['lng'] # 纬度
lat = (temp['result']['location']['lat']) # 经度
# print(lng, lat)
return str(lng) + "," + str(lat)
else:
# print(address+"没找到")
return "NULL"
#爬取失踪人口信息
class MissingpersonSpider(scrapy.Spider):
name = 'missingPerson'
allowed_domains = ['baobeihuijia.com']
#https://bbs.baobeihuijia.com/thread-402350-1-1.html
start_urls = []
#读取本地数据
# path = r".\missingUrl.json"
# with open(path, 'rb') as f:
# data = json.load(f)
# #print(type(data))
# len(data)
# for index in range(6, 20):
# #str = re.match('.*', url)
# start_urls.append(data[index]["detailUrl"])
# print(start_urls)
#读取url数据库
import MySQLdb
#打开数据库连接
db = MySQLdb.connect("localhost", "root", "root", "webgisdb", charset='utf8')
cursor = db.cursor()
sql = "select * from url"
try:
cursor.execute(sql)
results = cursor.fetchall()
for row in results:
start_urls.append(row[0])
print(row[0])
except:
print
"Error: unable to fecth data"
db.close()
def string_toDatetime(st):
print("2.把字符串转成datetime: ", datetime.datetime.strptime(st, "%Y-%m-%d"))
def parse(self, response):
mycsv = ['NULL', 'NULL', 'NULL', 'NULL', 'NULL',"NULL", 'NULL', 'NULL','NULL'] # 初始化提取信息列表
# 爬取图片url
imgurl=""
img = response.xpath('//body//div[@class="t_fsz"]//ul/li//ignore_js_op/img/@file').extract();
if len(img)>0:
#print(img, "图片")
#这里拉了多张图片
for s in img:
#str = img[0]
rs=s.split("forum")
tem = "https://youtu.baobeihuijia.com/forum" + rs[1]
if imgurl=="":
imgurl=tem
else:
from macpath import join
imgurl=join(",".join((imgurl,tem)))
#print(rs[1])
else:
imgurl="http://www.svmuu.com/img/4.0/backstage/no-data.jpg"
pass
#print(imgurl)
#爬取文字信息
for li in response.xpath('//body//div[@class="t_fsz"]//ul/li'):
# 伪装
from scrapy.conf import settings
origin = "User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/"
ran = random.randint(10, 100000)
origin += str(ran)
settings['BOT_NAME'] = origin
info = li.xpath('font/text()').extract()
#print(info)
if(info!=None):
for item in info:
if "失踪日期" in item[0:10] or "失踪日期" in item[0:10]:
index = item.find(":")
missingdate=item[index + 1:]
#正则化匹配
date_reg_exp = re.compile('\d{4}[-/年]\d{1,2}[-/月]\d{2}\s*')
matches_list = date_reg_exp.findall(missingdate)
#for match in matches_list:
match = None
if len(matches_list)==0:
#print("正则表达式1无匹配"+missingdate+",尝试2")
date_reg_exp1= re.compile('\d{4}[-/.,年]\d{1,2}[-/.,月]\s*')
matches_list = date_reg_exp1.findall(missingdate)
if len(matches_list)==0:
#print("正则表达式2无匹配"+missingdate+",尝试3")
date_reg_exp2 = re.compile('\d{4}[年]\s*')
matches_list = date_reg_exp2.findall(missingdate)
if len(matches_list)==0:
#print(missingdate+"无匹配")
match = None
else:
#print(matches_list[0])
match= matches_list[0]
times = None
#解析日期
if match!=None:
try:
times = time.strptime(match, "%Y年%m月%d")
except ValueError:
try:
times = time.strptime(match, "%Y-%m-%d")
except ValueError:
try:
times = time.strptime(match, "%Y/%m/%d")
except ValueError:
try:
times = time.strptime(match, "%Y年%m月%d日 ")
except ValueError:
try:
times = time.strptime(match, "%Y-%m-%d ")
except ValueError:
try:
times = time.strptime(match, "%Y/%m/%d ")
except ValueError:
#print("错误的日期格式或日期"+match)
times=None
mycsv[8] = times
#print(missingdate)
pass
if "姓 名" in item[0:6]:
index = item.find(":")
missingName= item[index + 1:]
mycsv[0]= missingName
if "性 别" in item:
index = item.find(":")
sex=item[index + 1:]
mycsv[1] = sex
if "出生日期" in item:
index = item.find(":")
birth = item[index + 1:]
#正则化匹配
date_reg_exp = re.compile('\d{4}[-/年]\d{1,2}[-/月]\d{2}\s*')
matches_list = date_reg_exp.findall(birth)
#for match in matches_list:
match = None
if len(matches_list) == 0:
#print("正则表达式1无匹配"+birth+",尝试2")
date_reg_exp1 = re.compile('\d{4}[-/年]\d{1,2}[-/月]\s*')
matches_list = date_reg_exp1.findall(birth)
if len(matches_list) == 0:
#print("正则表达式2无匹配"+birth+",尝试3")
date_reg_exp2 = re.compile('\d{4}[年]\s*')
matches_list = date_reg_exp2.findall(birth)
if len(matches_list) == 0:
#print(birth+"无匹配")
match = None
else:
#print(matches_list[0])
match= matches_list[0]
times = None
#解析日期
if match!=None:
try:
times = time.strptime(match, "%Y年%m月%d")
except ValueError:
try:
times = time.strptime(match, "%Y-%m-%d")
except ValueError:
try:
times = time.strptime(match, "%Y/%m/%d")
except ValueError:
try:
times = time.strptime(match, "%Y年%m月%d日 ")
except ValueError:
try:
times = time.strptime(match, "%Y-%m-%d ")
except ValueError:
try:
times = time.strptime(match, "%Y/%m/%d" )
except ValueError:
#print("错误是日期格式或日期")
times=None
#print(times)
#print(birth)
mycsv[2] = times
if "失踪时身高" in item:
index = item.find(":")
tall = item[index + 1:]
print("string:" + tall)
date_reg_exp = re.compile('\d{1,4}')
matches_list = date_reg_exp.findall(tall)
#print(matches_list)
matchTall = None
if len(matches_list) == 0:
print("身高正则匹配失败 string:"+ tall)
else:
matchTall=matches_list[0]
print("正则化字符串: "+matchTall)
mycsv[3] = matchTall
if "失踪地点" in item:
index = item.find(":")
adress = item[index + 1:]
mycsv[4] = adress
mycsv[5] = getBlnglat(adress)
if"失踪者特征描述" in item:
index = item.find(":")
describe = item[index + 1:]
mycsv[6] = describe
pattern = re.compile(r'^\d+')
detail = pattern.match(item)
if detail:
tem = mycsv[7]
if tem == "NULL":
tem = ""
s = tem+item
mycsv[7] = s
#and mycsv[1] != "NULL" and mycsv[2] != "NULL"
#整合信息
if mycsv[0]!="NULL" and mycsv[4]!="NULL" and mycsv[5]!="NULL" :
print(mycsv)
item = PersonItem() # 实例化item类
item['name'] = mycsv[0]
item['sex'] = mycsv[1]
item['birth'] = mycsv[2]
item['tall'] = mycsv[3]
item['adress'] = mycsv[4]
item['cor'] = mycsv[5]
item['describe'] = mycsv[6]
item['other'] = mycsv[7]
item['imgsrc'] = imgurl
item['missingdate'] = mycsv[8]
yield item

 浙公网安备 33010602011771号
浙公网安备 33010602011771号