Oracle JOB详解
Oracle job有定时执行的功能,可以在指定的时间点或每天的某个时间点自行执行任务。 而且oracle重新启动后,job会继续运行,不用重新启动。
一、相关视图
(1).dba_jobs显示的是所有用户下的job
注:dba_jobs_running 可以查看正在运行的JOB

(2).user_jobs和all_jobs差不多,一般显示当前用户下的job。
2.视图的相关字段简要描述
SQL> desc dba_jobs;
|
Name |
Type |
描述 |
|
JOB |
NUMBER |
JOB唯一标识号 |
|
LOG_USER |
VARCHAR2(128) |
创建用户 |
|
PRIV_USER |
VARCHAR2(128) |
赋权用户 |
|
SCHEMA_USER |
VARCHAR2(128) |
方案名(一般等同于用户名) |
|
LAST_DATE |
DATE |
最后一次成功执行job的日期 |
|
LAST_SEC |
VARCHAR2(16) |
最后一次成功执行job的日期(时分秒) |
|
THIS_DATE |
DATE |
正在运行job的开始时间 |
|
THIS_SEC |
VARCHAR2(16) |
正在运行job的开始时间(时分秒) |
|
NEXT_DATE |
DATE |
下一次执行的时间 |
|
NEXT_SEC |
VARCHAR2(16) |
下一次执行的时间(时分秒) |
|
TOTAL_TIME |
NUMBER |
该任务预计运行多少秒 |
|
BROKEN |
VARCHAR2(1) |
JOB是否中断(停止Y/运行N) |
|
INTERVAL |
VARCHAR2(200) |
下次运行时间表达式 |
|
FAILURES |
NUMBER |
JOB连续失败次数 |
|
WHAT |
VARCHAR2(4000) |
执行job的对象名称 |
|
NLS_ENV |
VARCHAR2(4000) |
会话的字符集 |
|
MISC_ENV |
RAW(32) |
其他参数 |
|
INSTANCE |
NUMBER |
|
3.JOB的执行频率interval
1.每天夜里24点 TRUNC(SYSDATE+1)
2.每天上午9:20 TRUNC(SYSDATE+1)+(9*60+20)/(24*60)
3.每周二下午1点 NEXT_DAY(TRUNC(SYSDATE ), ''''TUESDAY'''' ) + 13/24
4.每月15日夜里0点 TRUNC(LAST_DAY(SYSDATE ) + 15)
5.每个季度最后一天的晚上11点 ''TRUNC(ADD_MONTHS(SYSDATE + 2/24, 3 ), ''Q'' ) -1/24''
6.每星期六和日早上6点10分 ''TRUNC(LEAST(NEXT_DAY(SYSDATE, ''''SATURDAY"), NEXT_DAY(SYSDATE, "SUNDAY"))) + (6×60+10)/(24×60)''
7.每3秒钟执行一次 'sysdate+3/(24*60*60)'
8.每2分钟执行一次 'sysdate+2/(24*60)'
9.每分钟执行 TRUNC(sysdate,'mi') + 1/ (24*60)
interval => 'sysdate+1/(24*60)' --每分钟执行
interval => 'sysdate+1' --每天
interval => 'sysdate+1/24' --每小时
interval => 'sysdate+2/24*60' --每2分钟
interval => 'sysdate+30/24*60*60' --每30秒
10.每天定时执行
Interval => TRUNC(sysdate+1) --每天凌晨0点执行
Interval => TRUNC(sysdate+1)+1/24 --每天凌晨1点执行
Interval => TRUNC(SYSDATE+1)+(8*60+30)/(24*60) --每天早上8点30分执行
11.每周定时执行
Interval => TRUNC(next_day(sysdate,'星期一'))+1/24 --每周一凌晨1点执行
Interval => TRUNC(next_day(sysdate,1))+2/24 --每周一凌晨2点执行
12.每月定时执行
Interval =>TTRUNC(LAST_DAY(SYSDATE)+1) --每月1日凌晨0点执行
Interval =>TRUNC(LAST_DAY(SYSDATE))+1+1/24 --每月1日凌晨1点执行
13.每季度定时执行
Interval => TRUNC(ADD_MONTHS(SYSDATE,3),'q') --每季度的第一天凌晨0点执行
Interval => TRUNC(ADD_MONTHS(SYSDATE,3),'q') + 1/24 --每季度的第一天凌晨1点执行
Interval => TRUNC(ADD_MONTHS(SYSDATE+ 2/24,3),'q')-1/24 --每季度的最后一天的晚上11点执行
14.每半年定时执行
Interval => ADD_MONTHS(trunc(sysdate,'yyyy'),6)+1/24 --每年7月1日和1月1日凌晨1点
15.每年定时执行
Interval =>ADD_MONTHS(trunc(sysdate,'yyyy'),12)+1/24 --每年1月1日凌晨1点执行
二、JOB的创建
语法:
declare
variable job number;
begin
sys.dbms_job.submit(job => :job,
what => 'prc_name;', --执行的存储过程的名字
next_date => to_date('22-11-201309:09:41', 'dd-mm-yyyy hh24:mi:ss'),
interval =>'sysdate+1/86400'); --每天86400秒钟,即一秒钟运行prc_name过程一次
commit;
end;
使用dbms_job.submit方法过程,这个过程有五个参数:job、what、next_date、interval与no_parse。
dbms_job.submit(
job OUT binary_ineger,
What IN varchar2,
next_date IN date,
interval IN varchar2,
no_parse IN booean:=FALSE)
job参数是输出参数,由submit()过程返回的binary_ineger,这个值用来唯一标识一个工作。一般定义一个变量接收,可以去user_jobs视图查询job值。
what参数是将被执行的PL/SQL代码块,存储过程名称等。
next_date参数指识何时将运行这个工作。
interval参数何时这个工作将被重执行。
no_parse参数指示此工作在提交时或执行时是否应进行语法分析——true,默认值false。指示此PL/SQL代码在它第一次执行时应进行语法分析,而FALSE指示本PL/SQL代码应立即进行语法分析。
其他job相关的存储过程
在dbms_job这个package中还有其他的过程:broken、change、interval、isubmit、next_date、remove、run、submit、user_export、what;
大致介绍下这些过程:
1、broken()过程更新一个已提交的工作的状态,典型地是用来把一个已破工作标记为未破工作。这个过程有三个参数:job、broken与next_date。
procedure broken (
job IN binary_integer,
broken IN boolean,
next_date IN date := SYSDATE
)
job参数是工作号,它在问题中唯一标识工作。
broken参数指示此工作是否将标记为破——true说明此工作将标记为破,而false说明此工作将标记为未破。
next_date参数指示在什么时候此工作将再次运行。此参数缺省值为当前日期和时间。
job如果由于某种原因未能成功执行,oracle将重试16次后,还未能成功执行,将被标记为broken,重新启动状态为broken的job,有如下两种方式;
(1)利用dbms_job.run()立即执行该job
begin
dbms_job.run(:job) --该job为submit过程提交时返回的jobnumber或是去dba_jobs去查找对应job的编号
end;
(2)利用dbms_job.broken()重新将broken标记为false
begin
dbms_job.broken (:job, false, next_date)
end;
2、change()过程用来改变指定job的设置。
这个过程有四个参数:job、what、next_date、interval。
procedure change (
job IN binary_integer,
what IN varchar2,
next_date IN date,
interval IN varchar2
)
这里,
job参数是一个整数值,它唯一标识此工作。
what参数是由此job运行的一块PL/SQL代码块。
next_date参数指示何时此job将被执行。
interval参数指示一个job重执行的频度。
3、interval()过程用来显式地设置重复执行一个job之间的时间间隔数。
这个过程有两个参数:job、interval。
procedure interval(
job IN binary_integer,
interval IN varchar2
)
job参数标识一个特定的工作。
interval参数指示一个工作重执行的频度。
4、isubmit()过程用来用特定的job号提交一个job。
这个过程有五个参数:job、what、next_date、interval、no_parse。
procedure isubmit (
job IN binary_ineger,
what IN varchar2,
next_date IN date,
interval IN varchar2,
no_parse IN booean := FALSE
)
这个过程与submit()过程的唯一区别在于此job参数作为IN型参数传递且包括一个由开发者提供的job号。如果提供的job号已被使用,将产生一个错误。
5、next_date()过程用来显式地设定一个job的执行时间。这个过程接收两个参数:job、next_date。
procedure next_date(
job IN binary_ineger,
next_date IN date
)
job标识一个已存在的工作。
next_date参数指示了此job应被执行的日期、时间。
6、remove()过程来删除一个已计划运行的job。这个过程接收一个参数:
procedure remove(job INbinary_ineger);
job参数唯一地标识一个工作这个参数的值是由为此工作调用submit()过程返回的job参数的值,已正在运行的job不能删除。
7、run()过程用来立即执行一个指定的job。这个过程只接收一个参数:
procedure run(job INbinary_ineger)
job参数标识将被立即执行的工作。
8、使用submit()过程,job被正常地计划。
9、user_export()过程返回一个命令,此命令用来安排一个存在的job以便此job能重新提交。此程序有两个参数:job、my_call。
procedure user_export(
job IN binary_ineger,
my_call IN OUT varchar2
)
job参数标识一个安排了的工作。
my_call参数包含在它的当前状态重新提交此job所需要的正文。
10、what()过程应许在job执行时重新设置此正在运行的命令。这个过程接收两个参数:job、what。
procedure what (
job IN binary_ineger,
what IN OUT varchar2
)
job参数标识一个存在的工作。
what参数指示将被执行的新的PL/SQL代码。实现的功能:每隔一分钟自动向getSysDate表中插入当前的系统时间。
三、示例
1./* 每10秒钟执行一次 插入一条时间 */
-- 创建table
create table tab_time(
current_time timestamp
);
-- 创建存储过程
create or replace procedure pro_job_print
as
begin
--dbms_output.put_line('系统时间:' ||to_char(sysdate, 'dd-mm-yyyy hh24:mi:ss'));
insert into tab_time values(sysdate);
end;
-- 调用过程测试
begin
pro_job_print;
end;
--select 24 * 60 * 60 from dual; --得出一天的秒数
-- 创建job
declare
job1 number;
begin
dbms_job.submit(job1, 'pro_job_print;',sysdate, 'sysdate+10/86400'); --每10插入一条记录
end;
--相关视图
select * from dba_jobs;
select * from all_jobs;
select * fromuser_jobs;
-- 正在运行job
select * fromdba_jobs_running;
-- 运行job
begin
dbms_job.run(26); --和select * from user_jobs;中的job值对应,看what对应的过程
end;
-- 查询是否插入数据
select to_char(current_time, 'dd-mm-yyyy hh24:mi:ss') current_time from tab_time orderby current_time;
-- 删除一个job
begin
dbms_job.remove(26);--和select * fromuser_jobs; 中的job值对应,看what对应的过程
end;
四、关于设置job任务数量和控制并发
初始化相关参数job_queue_processes
alter system setjob_queue_processes = 39 scope = spfile;//最大值不能超过1000;
job_queue_interval =10; //调度作业刷新频率秒为单位
job_queue_process表示oracle能够并发的job的数量,sqlplus中可以通过语句
show parameterjob_queue_process; 来查看oracle中job_queue_process的值。
select * from v$parameter;
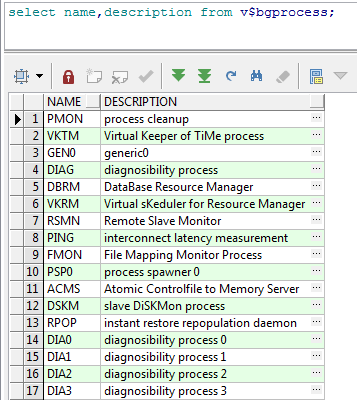
select name,description from v$bgprocess;
当job_queue_process值为0时表示全部停止oracle的job,可以通过语句 alter system setjob_queue_processes = 10; 来调整启动oracle的job。
如果将job_queue_processes的值设置为1的话,那就是串行运行,即快速切换执行一个job任务。
五、job不运行的大概原因
(1)、上面讲解了job的参数:与job相关的参数一个是job_queue_processes,这个是运行job时候所起的进程数,当然系统里面job大于这个数值后,就会有排队等候的,最小值是0,表示不运行job,最大值是1000,在OS上对应的进程时SNPn,9i以后OS上管理job的进程叫CJQn。可以使用下面这个SQL确定目前有几个SNP/CJQ在运行。
select * fromv$bgprocess,这个paddr不为空的snp/cjq进程就是目前空闲的进程,有的表示正在工作的进程。
另外一个是job_queue_interval,范围在1--3600之间,单位是秒,这个是唤醒JOB的process,因为每次snp运行完他就休息了,需要定期唤醒他,这个值不能太小,太小会影响数据库的性能。
先确定上面这两个参数设置是否正确,特别是第一个参数,设置为0了,所有job就不会自动运行了。
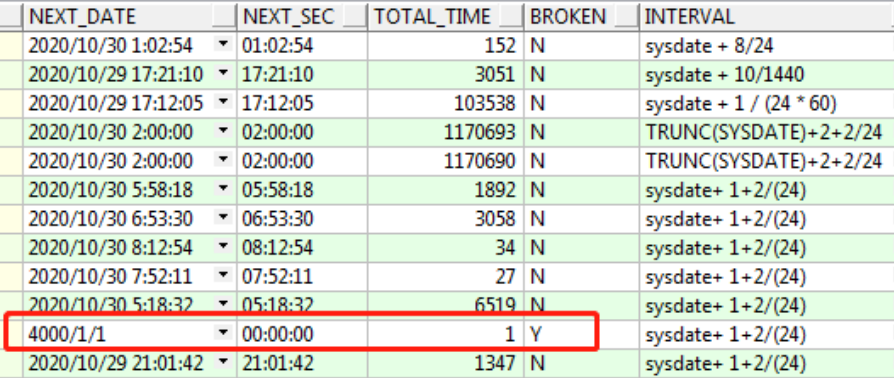
(2)、使用下面的SQL查看job的的broken,last_date和next_date,last_date是指最近一次job运行成功的结束时间,next_date是根据设置的频率计算的下次执行时间,根据这个信息就可以判断job上次是否正常,还可以判断下次的时间对不对,SQL如下:
select * from dba_jobs;
有时候我们发现他的next_date是4000年1月1日,说明job要不就是在running,要不就是状态是break(broken=Y),如果发现job的broken值为Y,找用户了解一下,确定该job是否可以broken,如果不能broken,那就把broken值修改成N,修改再使用上面的SQL查看就发现它的last_date已经变了,job即可正常运行,修改broken状态的SQL如下:
begin
DBMS_JOB.BROKEN(<JOB_ID>, FALSE);
end;
(3)、使用下面的SQL查询是否job还在running
select * fromdba_jobs_running;
如果发现job已经Run了很久了还没有结束,就要查原因了。一般的jobrunning时会锁定相关的相关的资源,可以查看一下v$access和v$locked_object这两个view。如果发现其他进程锁定了与job相关的object,包括package/function/procedure/table等资源,那么就要把其他进程删除,有必要的话,把job的进程也删除,再重新执行看看结果。
(4)、如果上面都正常,但是job还不run,怎么办?那我们要考虑把job进程重启一次,防止是SNP进程死了造成job不跑,指令如下:
alter system setjob_queue_processes = 0; --关闭job进程,等待5--10秒钟
alter system setjob_quene_processes = 5; --恢复原来的值
(5)、Oracle的BUG:Oracle9i里面有一个BUG,当计数器到497天时,刚好达到它的最大值,再计数就会变成-1,继续计数就变成0了,然后计数器将不再跑了。如果碰到这种情况就得重启数据库,但是其他的Oracle7345和Oracle8i的数据库没有发现这个问题。
(6)、数据库上的检查基本上就这多,如果job运行还有问题,那需要看一下是否是程序本身的问题,比如处理的资料量大,或者网络速度慢等造成运行时过长,那就需要具体情况具体分析了。我们可以通过下面的SQL手工执行一下job看看:
begin
dbms_job.run(<job>_ID)
end;
如果发现job执行不正常,就要结合程序具体分析一下。
2、JOB锁处理方法:
找出正在执行的JOB编号及其会话编号
SELECT SID,JOB FROM DBA_JOBS_RUNNING;
停止该JOB的执行
SELECT SID,SERIAL# FROM V$SESSION WHERE SID='&SID';
ALTER SYSTEM KILL SESSION '&SID,&SERIAL';
EXEC DBMS_JOB.BROKEN(&JOB,TRUE);
实例:
1,查询正在运行的Job,通过查询有两个,和进程占用较多的是两个Oracle进程符合。
SQL> SELECT SID,JOB FROM DBA_JOBS_RUNNING;
SID JOB
---------- ----------
12 116
16 117
2,查询正在运行的job的信息
SQL> SELECT SID,SERIAL# FROM V$SESSION WHERE SID='12';
SID SERIAL#
---------- ----------
12 4
SQL> SELECT SID,SERIAL# FROM V$SESSION WHERE SID='16';
SID SERIAL#
---------- ----------
16 1
3,利用查询出来的job信息将job结束掉
SQL> ALTER SYSTEM KILL SESSION '12,4';
System altered.
SQL> ALTER SYSTEM KILL SESSION '16,1';
System altered.
4,如果不希望运行上述job的话,可以将job设置为broken.
EXEC DBMS_JOB.BROKEN(116,TRUE);
EXEC DBMS_JOB.BROKEN(117,TRUE);
根据个人经验,这种方法并不会立即中断job的运行。最好是找到job对应的线程kill掉。
删除JOB方法:注:BROKEN值如果为TRUE则为停用,FALSE为启用,默认FALSE。
begin
DBMS_JOB.BROKEN(JOB编号,TRUE);
dbms_job.remove(JOB编号);
commit;
end;
以下是只执行stop job的效果
begin
DBMS_JOB.BROKEN(83,TRUE);
--dbms_job.remove(JOB编号);
commit;
end;
如果需要同时删除几个job
begin
--DBMS_JOB.BROKEN(43,TRUE);
dbms_job.remove(43);
--DBMS_JOB.BROKEN(44,TRUE);
dbms_job.remove(44);
--DBMS_JOB.BROKEN(45,TRUE);
dbms_job.remove(45);
commit;
end;
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号