
Name Disambiguaiton in Aminer论文解读
Name disambiguation in Aminer:Clustering, Maintenance, and Human in the loop
Aminer 是一个免费的在线学术搜索和挖掘系统,已经搜集了超过13亿研究者档案和超过20亿的论文。论文通过结合全局和局部的信息提出了一个新颖的表示学习方法。还提出了一个端到端簇大小估计方法,此方法明显优于传统基于BIC的方法。
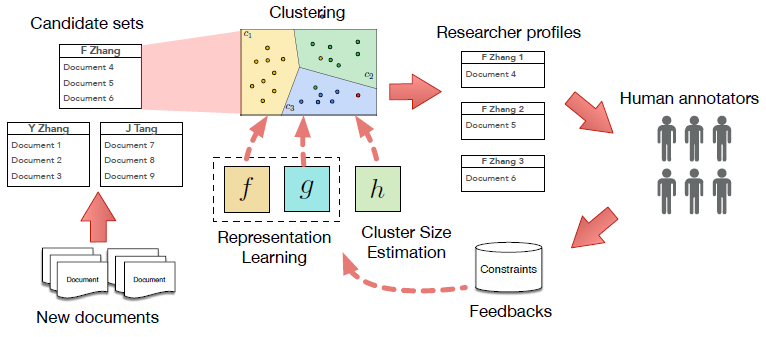
这张图是Aminer中作者名消歧框架的概览,本文介绍不包括人类注解反馈的部分。
处理作者名歧义问题主要有两个困难:
1. 如何量化来自不同数据源实体间的相似性
2. 如何确定具有相同姓名的作者的人数
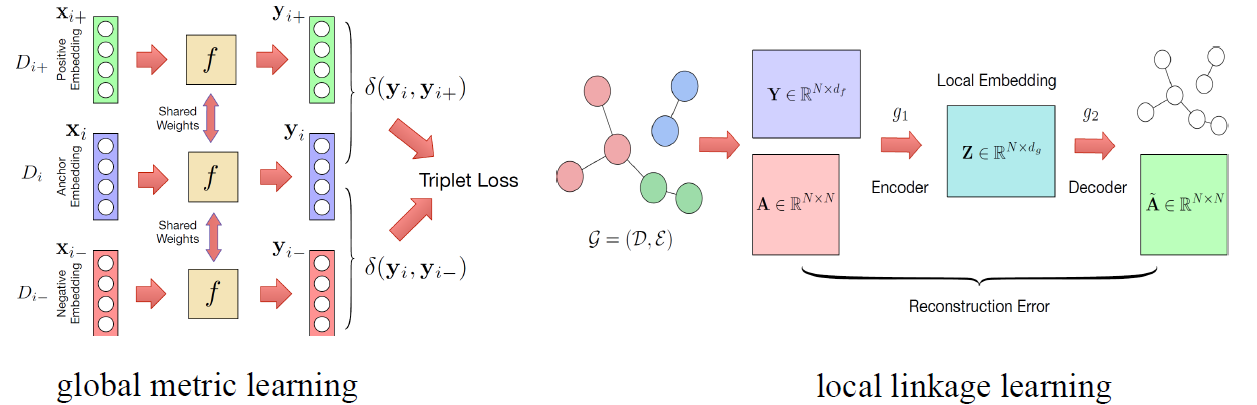
对于第一个问题,论文提出了全局度量(global metric)和局部链接(local linkage)学习算法,就是把每个实体映射到一个低维的潜在公共空间,这样就提供了一种方式来直接计算实体间的相似性。对于确定相同姓名的人数,提出了一个端到端模型使用RNN直接估计数据集中人数(也就是clusters)。
论文related work 部分将ANA方面的论文分类Feature-based和Linkage-based两类,还比较了Cluster size estimation的方法,这里不多做赘述。
论文则是结合了特征和连接来量化相似性,思路如下:首先将文档转换进一个嵌入空间(embedding space),如果两篇文档的作者是同一个人,则在嵌入空间中两篇文档距离相近。在本文的框架中,首先学习一个有监督的全局嵌入函数,然后基于局部环境(local context)为每个候选集改善全局嵌入。
首先介绍一下全局度量学习:输入文档Di被表示为一个不同长度的特征集Di = {x1,x2,...},其中特征是论文标题,合作者姓名,期刊/会议名,作者机构中的单词。每个特征是一个独热向量。对于每个特征xn用Word2Vec得到一个嵌入![]() ,将文档Di的特征嵌入定义为
,将文档Di的特征嵌入定义为![]() ,其中αn是特征xn的逆文档频率,xi基于每个单独文档的共现统计捕获特征特征之间的相关性,但其区分不同文档的能力有限,所以需要用标注数据来调整嵌入。
,其中αn是特征xn的逆文档频率,xi基于每个单独文档的共现统计捕获特征特征之间的相关性,但其区分不同文档的能力有限,所以需要用标注数据来调整嵌入。
文中的全局模型使用三元组损失:
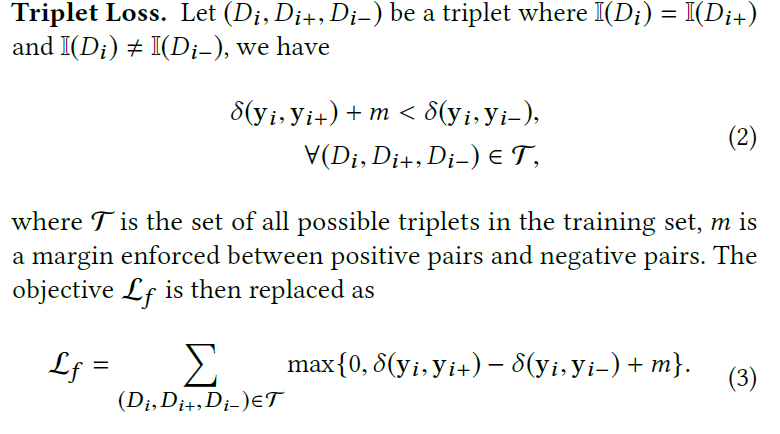
全局模型图如下:
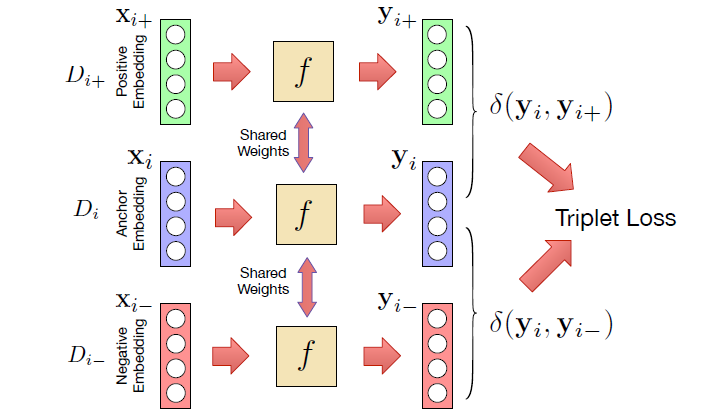
其中![]() 是欧式距离。模型输入X(input document embedding matrix),输出Y(learned global document embedding matrix)
是欧式距离。模型输入X(input document embedding matrix),输出Y(learned global document embedding matrix)
介绍完全局模型,下面介绍局部连接学习,首先定义局部连接图,这里说明一下,全局度量学习是在所有名字的所有文档的基础上,而局部连接图是在一个名字的基础上,也就是每个候选集内,对于一个给定的名字,构建一个局部连接图,其中节点为这个名字的文档,边是基于两篇文档的相似性定义的,基于两篇文档的共同特征来衡量相似性,即两篇文档特征集的交集,特征集在全局模型中提到过,将连接权重定义为![]()
wx是特征x的权重也定义为特征x的逆文档频率。如果W(Di,Dj)大于一个阈值则构建一条边。本文利用图结构来improve全局嵌入,采用一个无监督的图自动编码器结构来学习局部连接图。gae结构如下:

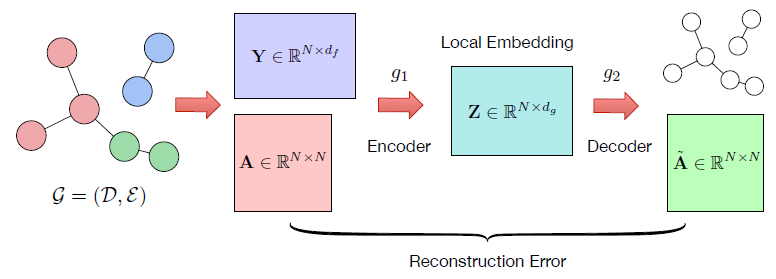
将两部分连接起来:
这样就得到了可以衡量相似性的论文的embedding。
下面就采用聚类算法来进行聚类得到最终的结果。文中采用HAC聚类算法,但需要指定聚类的数目K,传统的基于BIC的方法虽然不需要指定聚类的数目,但是对于大的数据集来说聚类明显偏少。文中使用RNN来指定聚类数目,结构如下:
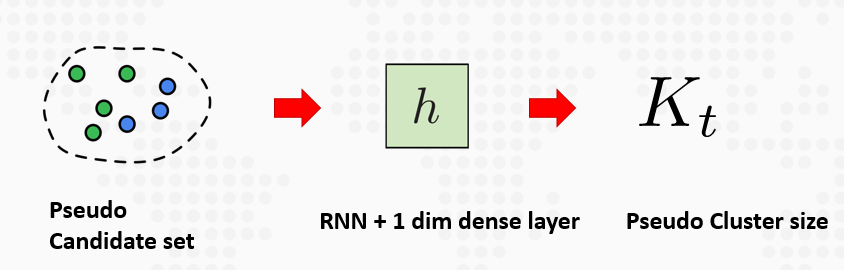
由于没有直接的训练数据,所以从标注数据中生成伪训练数据。算法如下:

最后通过优化均方对数误差来训练模型: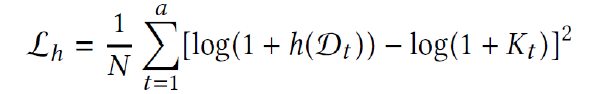 。
。
最后放一段唐杰教授对于此论文的评价:今年用表示学习做的关于Name Disambiguation(命名排歧)的工作被KDD接收《Name Disamibiguation in AMiner: Clustering, Maintenance, and Human in the Loop》,NA一直是一个很麻烦的问题,10年前刚毕业不久的时候给学生说,这个题目可以考虑做,30年前就有人在做,30年之后还会有人做。
最近关于GNN的工作比较多,可以考虑将gnn应用到局部连接学习中,其实文中的gae的编码层也就是gcn(图卷积神经网络)也属于gnn的范畴。图中权重的定义和图的学习都可以优化一下。

