寒假作业2/2
| 这个作业属于哪个课程 | 2021春软件工程实践|W班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业2/2 |
| 这个作业的目标 | 阅读《构建之法》,学会怎样更好地提出问题;熟悉GitHub的运用以及git相关语法的使用;完成WordCount命令行程序 |
| 其他参考文献 | CSDN |
| 作业正文 | 寒假作业2/2 |
目录:
part1:阅读《构建之法并提问》
- 第二章2.1.3提到了回归测试,说到“如果一个模块或功能以前是正常工作的,但是在一个新的构建中除了问题,那么这个模块就出现了一个‘退步’”,下文又说“对于‘回归测试’中的‘回归’,我们可以将其理解为‘回归到以前不正
常的状态’”,那么回归测试到底是处理旧的未发现的问题,还是处理由于模块更新而产生的新的问题?我的理
解是在新版本上重新测试已经发现的bug,然后看是否引起了问题,需要进行相应的更新修改,查阅了资料之
后发现也有部分声音认为回归测试指对于以前曾经测试过的内容(未出现bug)在新版中的重复性测试,所以
应该怎么去理解?
- 第六章提到了敏捷流程,其中提到了敏捷的三个步骤,“第一步:找出完成产品需要做的事情;第二步:决定
当前的冲刺;第三步:冲刺”。从字面上理解来看,再和平时所认知的开发流程进行对比,感觉差别不是很大。
对敏捷还是无法理解,敏捷是不是就是要做什么事都要及早,及早发现问题,及早提交可运行的软件。我查
阅了相关资料,传统的瀑布模式和敏捷开发模式适用于不同程熟度的软件公司,“软件成熟度较好的手机软件
开发公司,引入了PM,按照CMM流程重视软件开发过程控制以及软件开发技术积累,同时为了能适应手机
软件开发需求变化比较快的特点,不采用传统瀑布模式软件开发,引入了敏捷开发模式,在软件实践过程中,
引入了FDD,ASD,XP的敏捷开发模式,在软件开发过程中,强调以构架为中心,以需求为驱动的迭代开发模
式,通过构架,确保软件的可扩展性和接口合理性,强调接口设计,方便于迭代和合作开发”。还是无法很好
地理解敏捷,那照查阅的资料来看,我们团队做普通的项目会有一些技术上的限制,是不是就无法采用敏捷
流程了?
- 第七章7.3提到了MSF团队模型,并且提到“在MSF团队模型中,人和技术项目都必须达到特定的关键质量目标,才能够被认为是成功的项目。任何一个角色无法实现其目标,都将危及整个项”,这个问题可能在我们后面团队合作的项目中都会遇到,每个人的能力不同,根据每个人的所长最初分配好了各自的职责,但是到最后可能由
于各种各样的原因而导致一部分目标无法完成,那这样是不是在最初分配任务的时候多强调能者多劳,但是那
样会给少部分人分配更多的工作时间,而且可能会让能力差的人产生依赖的心理,或者自身也可能会嫌弃自己
的团队成员,而使得团队的气氛下降。所以遇到这种角色无法实现其所分配的既定目标时该如何处理?作为成
员或者PM?
- 第十章10.4提到了功能驱动设计FDD,并且提到FDD适用于团队成员对于需求没有切身体会的情景,例如要实现不熟悉的行业(银行、证券、物流等)的业务系统,仅从纸面上看,FDD对单元测试之外的测试的讲述不足,那么有什么方法能在遇到这种情况下来替代FDD呢?查阅了资料,“PDD(Product-Feature Driven Design)产品特性驱动设计,我们可以将它使用在我们的日常设计工作中,它可以运用在你的大小设计项目中,这是一种行为模式,一种思考角度,或者我们把它作为一种指导方法.它依靠产品的自身特性来驱动设计”。我可以把它理解为更大众化的FDD,能够在不同规模的项目设计中进行使用,那么一些身在其中的行业的项目可能就可以换个思路,不知道我这样理解是否妥当?
- 第十六章16.2出现了一张技术采用生命周期图,到早期采用者会出现一个鸿沟,“大众平均值再往前一步就是‘早期采用者’那个区间,有时一个崭新的技术,推出的时机太早,它就跨不过那道沟”,如何理解?查阅了资料,“早期采用者是远见家,他们看的远,站的高,能够想到新科技产品带来的巨大影响,但这样的人又非常少,不可
能直接和早期大众交互。远见家通常扮演着成了都是自己的功劳,败了拍拍屁股走人的形象。所以和实用主义
者们并不是很协调。实用主义者选择接受一个新高科技产品,是要考虑它的实际价值的。因此,这两类人差异
比较大,很多东西在远见家眼里前途无量,在实用主义者眼里根本就没法落地”。按照我的理解,推出的时机太
早主要影响的是技术的可行性、适用性,而新产品一定要在解决实用的问题的前提下再进行推出工作才能够跨
越鸿沟。这样解决的是早期采用者与早期大众的跨越,那如何让更多的一部分人能够承担早期采用者的角色呢?
技术应该何时推出才能够更好地把握这个点?
附加题
在程序中bug一词用于技术错误。这一术语最初由爱迪生在1878年提出的,但当时并没有流行起来。在这的几年之后,美国上将Grace Hopper在她的日志本中,写下了她在Mark II电脑上发现的一项bug。不过实际上,她说的真的是“虫子”问题,因为一只蛾子被困在电脑的继电器中,导致电脑的操作无法正常运行。的确这样看来用bug来表示技术错误很是形象,技术错误和虫子相对应,程序项目和继电器相对应,也能更好地理解bug一词。
part2:WordCount编程
Github项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| ·Estimate | ·估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 720 | 780 |
| ·Analysis | ·需求分析(包括学习新技术) | 180 | 180 |
| ·Desgin Spec | ·生成设计文档 | 30 | 35 |
| ·Design Review | ·设计复审 | 30 | 20 |
| ·Coding Standard | ·代码规范(为目前的开发制定合适的规范) | 30 | 40 |
| ·Design | ·具体设计 | 60 | 60 |
| ·Coding | ·具体编码 | 300 | 360 |
| ·Code Review | ·代码复审 | 45 | 45 |
| ·Test | ·测试(自我测试,修改代码,提交修改) | 45 | 40 |
| Reporting | 报告 | 40 | 50 |
| ·Test Repor | ·测试报告 | 10 | 10 |
| ·Size Measurement | ·计算工作量 | 20 | 20 |
| ·Postmortem&Process Improvement Plan | ·事后总结,并提出过程改进计划 | 10 | 20 |
| 合计 | 770 | 840 |
解题思路描述
需要解决的问题:
1.解决文件数据的读入问题
2.解决字符数的统计
3.解决单词数的统计
4.解决有效行的统计
5.解决出现频率top10单词的统计
6.解决数据输出到指定文件的问题
如何去解决:
1.首先第一个问题,最初的版本没有考虑将文件数据的读入单独拿出来处理,而是在每个功能的实现下都增加了从文件读入的代码,就导致总体代码过长而且性能下降。最后考虑将其单独,拿出使得每次运行只需要读取数据一次。读取方法的考虑,选择的是BufferedReader,起初的想法使用readline方法去读取,然后发现难以处理一些特殊的文件数据,如最后一行只有单个'\n',后来的版本改成用read逐一读入。
2.解决字符数的统计,只需统计ASCII范围内的字符,直接进行范围的判断即可。
3.单词数的统计,先用正则表达式来分隔字符串,再用符合规则的正则表达式去匹配,最后用Map<String, Integer>来存储读取到的单词以及其对应的出现次数,为单词频率的排序提供数据。
4.有效行的统计需要忽略空行,所以用正则表达式去匹配符合条件的行并统计行数。
5.top10单词的统计需要用到第三步所得到的Map<String, Integer>对象,通过用比较器对Map.entrySet转换的list进行排序,按照value值大小以及key的字典序进行排序。
6.数据输出到指定文件,用BufferedWriter将拼接好的字符串按utf-8的方式输出到指定文件。
代码规范制定链接
设计与实现过程
主要的功能函数都放在Lib类中,对上述的六个问题用六个函数来解决
1.实现文件数据的读入,从最初的readline读入数据改为现在的read读入
public static String readFromFile(String filePath) {
int temp;
//创建输入流
BufferedReader br = null;
StringBuilder builder = null;
try {
br = new BufferedReader(new FileReader(filePath));
builder = new StringBuilder();
//按字符读入文件数据
while((temp = br.read()) != -1) {
builder.append((char)temp);
}
}catch(FileNotFoundException e) {
e.printStackTrace();
}catch(IOException e) {
e.printStackTrace();
}finally {
try {
br.close();
}catch(IOException e) {
e.printStackTrace();
}
}
return builder.toString();
}
2.字符数的判断只需判断其是否在ASCII的范围内即可
public static int getCharactersCount(String str) {
int count = 0;
char[] ch = str.toCharArray();
for(int i = 0; i < ch.length; i++) {
if(ch[i] >= 0 && ch[i] <= 127) {
count++;
}else continue;
}
return count;
}
3.单词数的统计以用split分割字符串,再用正则表达式匹配符合要求的单词,最后把单词存到Map中供排序使用,其中wordsMap是静态变量不用传入
public static int getWordsCount(String str) {
int count = 0;
//用正则表达式匹配分隔符分割字符串
String[] strs = str.split(BREAK_RE);
//遍历字符串数组,匹配符合正则表达式的单词
for(int i = 0; i < strs.length; i++) {
if(strs[i].matches(WORDS_RE)) {
//忽略大小写,添加单词到Map中
String temp = strs[i].toLowerCase();
if(wordsMap.containsKey(temp)) {
int num = wordsMap.get(temp);
wordsMap.put(temp, 1 + num);
}
else {
wordsMap.put(temp, 1);
}
count++;
}
}
return count;
}
4.行数的统计,也是用正则表达式去匹配即可
public static int getLineCount(String str) {
int count = 0;
Matcher matcher = Pattern.compile(LINE_RE).matcher(str);
while(matcher.find()) {
count++;
}
return count;
}
5.top10单词的排序,用比较器来实现
public static List<Map.Entry<String, Integer>> sortHashmap() {
//将words.entrySet()转换为list
List<Map.Entry<String, Integer>> list;
list = new ArrayList<Map.Entry<String, Integer>>(wordsMap.entrySet());
//通过比较器实现排序
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>(){
public int compare(Entry<String, Integer> m1, Entry<String, Integer> m2) {
//按照字典序以及value的值排序
if(m1.getValue().equals(m2.getValue())) {
return m1.getKey().compareTo(m2.getKey());
}else return m2.getValue()-m1.getValue();
}
});
return list;
}
6.用BufferedWriter将拼接的字符串传入指定文件
public static void writeToFile(int characters, int words, int lines, String filePath) {
//获取将要输出的字符串信息
String str = "characters: " + characters + "\nwords: " + words + "\nlines: " + lines +"\n";
List<Map.Entry<String, Integer>> list = sortHashmap();
int i = 0;
for(Map.Entry<String, Integer> map : list) {
if(i < 10) {
str += map.getKey() + ": " + map.getValue() + "\n";
i++;
}else break;
}
//得到输出流
FileOutputStream fos = null;
OutputStreamWriter writer = null;
BufferedWriter bw = null;
try {
fos = new FileOutputStream(filePath);
writer = new OutputStreamWriter(fos, "UTF-8");
bw = new BufferedWriter(writer);
bw.write(str);
bw.flush();
}catch(IOException e) {
e.printStackTrace();
}finally {
try {
fos.close();
writer.close();
bw.close();
}catch(IOException e) {
e.printStackTrace();
}
}
}
性能改进
性能的改进就是用了BufferedWriter和BufferedReader,使得对文件的读取和写入更快一些。另外从最初的的版本中把这两个方法单独拿出来而不用多次调用也会对性能有所提高。
运行10w+个单词的性能测试,以及输入和输出


单元测试
对字符数、行数、单词数以及单词的排序都进行了单元测试,并对所得值与期望值进行比较,选取的字符串也可以针对一些比较细节的问题,如空行,字母的大小等等,都可以通过修改其中的字符串进行测试,这里只取一部分有代表性的问题进行测试。
1.字符数的测试
@Test
void testGetCharactersCount() {
String str = "word\nfile\nFile\nwindows98\nwindows2000\n123file\r\nfil\n\n";
int loopTimes = 10000;
String testStr = "";
for(int i = 0; i < loopTimes; i++) {
testStr += str;
}
//调用Lib的字符数统计方法
assertEquals(Lib.getCharactersCount(testStr), 510000);
}
2.行数的测试
@Test
void testGetLineCount() {
String str = "word\nfile\nFile\nwindows98\nwindows2000\n123file\r\nfil\n\n";
int loopTimes = 10000;
String testStr = "";
for(int i = 0; i < loopTimes; i++) {
testStr += str;
}
//调用Lib的行统计方法
assertEquals(Lib.getLineCount(testStr), 70000);
}
3.单词数的测试
void testGetWordsCount() {
String str = "word\nfile\nFile\nwindows98\nwindows2000\n123file\r\nfil\n\n";
int loopTimes = 10000;
String testStr = "";
for(int i = 0; i < loopTimes; i++) {
testStr += str;
}
//调用Lib的单词统计方法
assertEquals(Lib.getWordsCount(testStr), 50000);
}
4.单词排序的测试
@Test
void testSortHashmap() {
//测试所用的不同形式字符串,用不同的循环次数以模拟单词出现的不同次数
/* 这里省略testStr1的构造方式 */
String[] result = {"bean", "boot", "course", "nike", "poor", "file", "windows2000",
"windows98", "word"};
Map<String, Integer> wordsMap = new HashMap<String, Integer>();
System.out.println(Lib.getWordsCount(testStr1));
List<Map.Entry<String, Integer>> list = Lib.sortHashmap();
int i = 0;
for(Map.Entry<String, Integer> map : list) {
assertEquals(map.getKey(),result[i]);
i++;
}
}
对于两个对文件的操作只是读入和输出,没有对所得数据做特殊的测试,下面是测试截图以及代码覆盖率
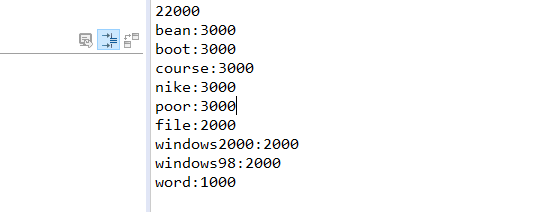
覆盖率截图,一些文件的异常的判断和输出会降低文件覆盖率,如读入和输出两个函数

提高代码覆盖率,要防止一个方法体过大,并且要尽可能的覆盖所有可能的路径,正确的、错误的都要包括在考虑的范围之内
异常处理说明
异常情况,没有添加自己构造的异常类,主要的异常有FileNotFoundException和IOException两种,但运行时出现异常会输出异常数据。
心路历程与收获
再一次熟悉了Java尤其是对文件的操作,数据的读入输出等相关知识,同时在不断地更新、调试的过程中学着用GitHub来存放和更新自己的代码,为今后的软件工程学习又添了一项新技能。当然,在完成作业的过程中,自己也会去查阅各种各样的资料,也是一个不断进步的过程,同时,在和大佬们的交流中也收获到了许多,认识到了自己的不足。项目难在不断的测试和优化,这是最深的体会,今后也会更加努力地完成每一个项目,尽力做到更好。

