lightdb并行执行及限制
postgresql已经支持很多的并行操作,包括表扫描、索引扫描、排序等,具体可见https://developer.aliyun.com/article/746200。
有几个参数控制并行执行的行为
zjh@postgres=# show %parallel%; name | setting | description ----------------------------------+---------+---------------------------------------------------------------------------------------------------- enable_parallel_append | on | Enables the planner's use of parallel append plans. enable_parallel_hash | on | Enables the planner's use of parallel hash plans. force_parallel_mode | off | Forces use of parallel query facilities. max_parallel_maintenance_workers | 8 | Sets the maximum number of parallel processes per maintenance operation. max_parallel_workers | 64 | Sets the maximum number of parallel workers that can be active at one time. max_parallel_workers_per_gather | 8 | Sets the maximum number of parallel processes per executor node. min_parallel_index_scan_size | 128MB | Sets the minimum amount of index data for a parallel scan. 如果不带单位,则默认以块为单位,也就是要乘以8192 min_parallel_table_scan_size | 2GB | Sets the minimum amount of table data for a parallel scan. 如果不带单位,则默认以块为单位,也就是要乘以8192
parallel_leader_participation | on | Controls whether Gather and Gather Merge also run subplans. parallel_setup_cost | 10000 | Sets the planner's estimate of the cost of starting up worker processes for parallel query. parallel_tuple_cost | 0.1 | Sets the planner's estimate of the cost of passing each tuple (row) from worker to master backend. (11 rows)
lightdb支持自动计算并行执行,也支持优化器提示。
select /*+ parallel(t 4 hard)*/ count(1) from big_table t;
lightdb也支持oracle兼容模式优化器提示,即parallel(t 4),详见Parallel(table [# of workers] [soft|hard])。
支持普通索引并行创建
drop index idx_file_name; CREATE INDEX idx_file_name ON big_search_doc_new_ic USING btree (filename);

create index concurrent不阻塞DML,其实现原理可以参考https://www.2ndquadrant.com/en/blog/create-index-concurrently/
GIN索引不支持并行执行,所以适合citus分布式架构做全文检索。
CREATE INDEX big_search_doc_new_ic_tsvector_content_idx ON big_search_doc_new_ic USING gin (tsvector_content);

并行执行不支持insert select,create table as select。其原因是可见性实现(也就是高并发下低成本的MVCC实现)还不太好:
- The combo CID mappings. This is needed to ensure consistent answers to
tuple visibility checks. The need to synchronize this data structure is
a major reason why we can't support writes in parallel mode: such writes
might create new combo CIDs, and we have no way to let other workers
(or the initiating backend) know about them.
除此之外,还包括函数、特性本身不支持,分为三种级别PROPARALLEL_UNSAFE, PROPARALLEL_RESTRICTED, PROPARALLEL_SAFE,可通过select proparallel from pg_catalog.pg_proc where proname ='floor'进行查询。详见https://www.hs.net/lightdb/docs/html/catalog-pg-proc.html
排序并行
lightdb@oradb=# explain(verbose) /*+ parallel(p 4 hard) */select * from part_t p order by id; QUERY PLAN ------------------------------------------------------------------------------------------------------------ Gather Merge (cost=631550.03..1776711.16 rows=9677418 width=41) Output: p.id, p.v Workers Planned: 3 -> Sort (cost=630549.99..638614.51 rows=3225806 width=41) Output: p.id, p.v Sort Key: p.id -> Parallel Append (cost=0.00..168412.55 rows=3225806 width=41) -> Parallel Seq Scan on public."part_t$p3" p_4 (cost=0.00..38095.32 rows=1471532 width=41) Output: p_4.id, p_4.v -> Parallel Seq Scan on public."part_t$p1" p_2 (cost=0.00..38077.16 rows=1470816 width=41) Output: p_2.id, p_2.v -> Parallel Seq Scan on public."part_t$p0" p_1 (cost=0.00..38059.42 rows=1470142 width=41) Output: p_1.id, p_1.v -> Parallel Seq Scan on public."part_t$p2" p_3 (cost=0.00..38051.62 rows=1469862 width=41) Output: p_3.id, p_3.v (15 rows)
聚合并行
lightdb@oradb=# explain(verbose) /*+ parallel(p 4 hard) */select count(*) from part_t p where id in (0,1,3,4,5,6,7,8,9); QUERY PLAN ----------------------------------------------------------------------------------------------------------- Finalize Aggregate (cost=164873.12..164873.13 rows=1 width=8) Output: count(*) -> Gather (cost=55623.86..164873.11 rows=6 width=8) Output: (PARTIAL count(*)) Workers Planned: 2 -> Parallel Append (cost=54623.86..163872.51 rows=3 width=8) -> Partial Aggregate (cost=54650.07..54650.08 rows=1 width=8) Output: PARTIAL count(*) -> Parallel Seq Scan on public."part_t$p3" p_2 (cost=0.00..54650.06 rows=5 width=0) Filter: (p_2.id = ANY ('{0,1,3,4,5,6,7,8,9}'::integer[])) -> Partial Aggregate (cost=54623.86..54623.87 rows=1 width=8) Output: PARTIAL count(*) -> Parallel Seq Scan on public."part_t$p1" p_1 (cost=0.00..54623.85 rows=5 width=0) Filter: (p_1.id = ANY ('{0,1,3,4,5,6,7,8,9}'::integer[])) -> Partial Aggregate (cost=54598.52..54598.53 rows=1 width=8) Output: PARTIAL count(*) -> Parallel Seq Scan on public."part_t$p0" p (cost=0.00..54598.51 rows=5 width=0) Filter: (p.id = ANY ('{0,1,3,4,5,6,7,8,9}'::integer[])) (18 rows)
少量数据返回时的并行
lightdb@oradb=# explain(verbose) /*+ parallel(p 4 hard) */select * from part_t p where id in (0,1,3,4,5,6,7,8,9); QUERY PLAN ------------------------------------------------------------------------------------------------ Gather (cost=1000.00..164875.18 rows=27 width=41) Output: p.id, p.v Workers Planned: 2 -> Parallel Append (cost=0.00..163872.48 rows=12 width=41) -> Parallel Seq Scan on public."part_t$p3" p_3 (cost=0.00..54650.06 rows=5 width=41) Output: p_3.id, p_3.v Filter: (p_3.id = ANY ('{0,1,3,4,5,6,7,8,9}'::integer[])) -> Parallel Seq Scan on public."part_t$p1" p_2 (cost=0.00..54623.85 rows=5 width=41) Output: p_2.id, p_2.v Filter: (p_2.id = ANY ('{0,1,3,4,5,6,7,8,9}'::integer[])) -> Parallel Seq Scan on public."part_t$p0" p_1 (cost=0.00..54598.51 rows=5 width=41) Output: p_1.id, p_1.v Filter: (p_1.id = ANY ('{0,1,3,4,5,6,7,8,9}'::integer[])) (13 rows) Time: 1.671 ms
返回大部分数据且不排序不支持并行
lightdb@oradb=# explain(verbose) /*+ parallel(p 4 hard) */select * from part_t p where id not in (0,1,3,4,5,6,7,8,9); QUERY PLAN --------------------------------------------------------------------------------------- Append (cost=0.00..355959.79 rows=9999963 width=41) -> Seq Scan on public."part_t$p0" p_1 (cost=0.00..76466.87 rows=2499232 width=41) Output: p_1.id, p_1.v Filter: (p_1.id <> ALL ('{0,1,3,4,5,6,7,8,9}'::integer[])) -> Seq Scan on public."part_t$p1" p_2 (cost=0.00..76502.24 rows=2500379 width=41) Output: p_2.id, p_2.v Filter: (p_2.id <> ALL ('{0,1,3,4,5,6,7,8,9}'::integer[])) -> Seq Scan on public."part_t$p2" p_3 (cost=0.00..76451.76 rows=2498756 width=41) Output: p_3.id, p_3.v Filter: (p_3.id <> ALL ('{0,1,3,4,5,6,7,8,9}'::integer[])) -> Seq Scan on public."part_t$p3" p_4 (cost=0.00..76539.11 rows=2501596 width=41) Output: p_4.id, p_4.v Filter: (p_4.id <> ALL ('{0,1,3,4,5,6,7,8,9}'::integer[])) (13 rows)
从上可知,排序,聚合,返回的数据量都会影响执行计划的选择。统计信息和以及CBO在这其中的计算就非常重要了。
oracle并行执行

https://docs.oracle.com/database/121/VLDBG/GUID-2627DC19-7EBE-4C45-A758-711BDB5E37EC.htm
由于pg很大程度上利用linux pagecache,所以I/O这一块不是问题。
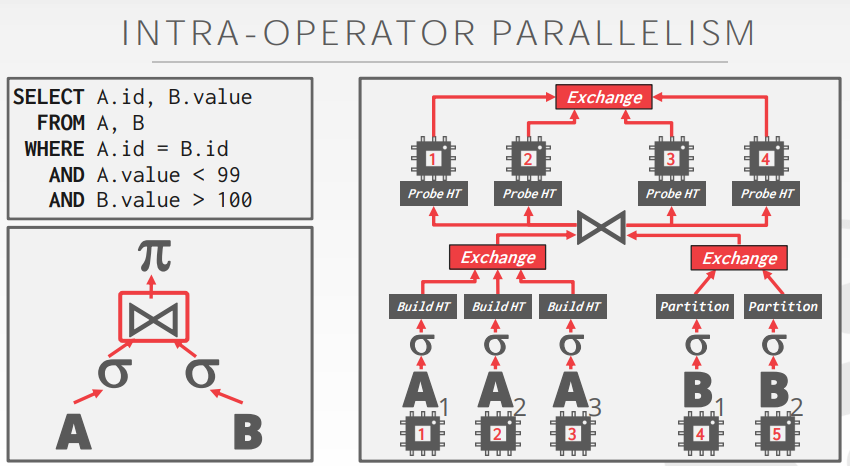
在SMP并行执行而言,有两种模式,在数据库中我们一般理解都是数据切片并行执行(intra-parallelism)。类似如下:
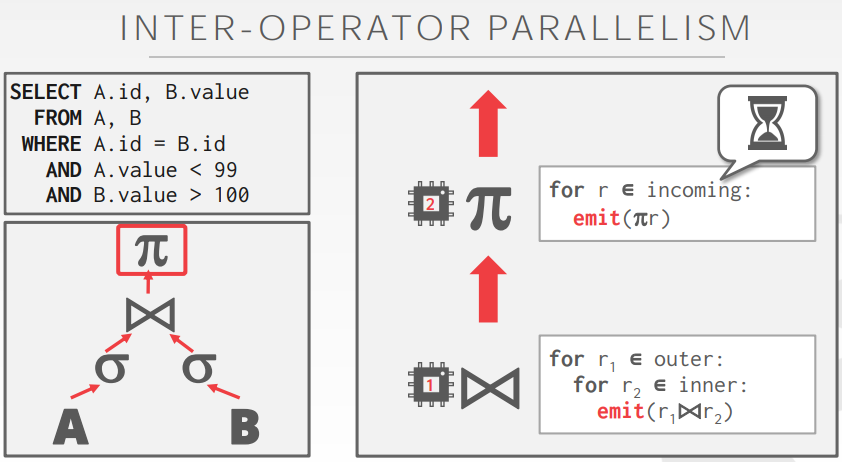
另外一种是操作间并行执行(也就是管道/ETL的模式,流式计算如spark、flink经常采用):
Postgresql内部并行执行的实现
if (heap_pages >= 0) { int heap_parallel_threshold; int heap_parallel_workers = 1; /* * Select the number of workers based on the log of the size of * the relation. This probably needs to be a good deal more * sophisticated, but we need something here for now. Note that * the upper limit of the min_parallel_table_scan_size GUC is * chosen to prevent overflow here. */ heap_parallel_threshold = Max(min_parallel_table_scan_size, 1); while (heap_pages >= (BlockNumber) (heap_parallel_threshold * 3)) { heap_parallel_workers++; heap_parallel_threshold *= 3; if (heap_parallel_threshold > INT_MAX / 3) break; /* avoid overflow */ } parallel_workers = heap_parallel_workers; } if (index_pages >= 0) { int index_parallel_workers = 1; int index_parallel_threshold; /* same calculation as for heap_pages above */ index_parallel_threshold = Max(min_parallel_index_scan_size, 1); while (index_pages >= (BlockNumber) (index_parallel_threshold * 3)) { index_parallel_workers++; index_parallel_threshold *= 3; if (index_parallel_threshold > INT_MAX / 3) break; /* avoid overflow */ } if (parallel_workers > 0) parallel_workers = Min(parallel_workers, index_parallel_workers); else parallel_workers = index_parallel_workers; }
进程之间通过信号进行通信,PROCSIG_PARALLEL_MESSAGE, /* message from cooperating parallel backend */
typedef struct ParallelExecutorInfo { PlanState *planstate; /* plan subtree we're running in parallel */ ParallelContext *pcxt; /* parallel context we're using */ BufferUsage *buffer_usage; /* points to bufusage area in DSM */ WalUsage *wal_usage; /* walusage area in DSM */ SharedExecutorInstrumentation *instrumentation; /* optional */ struct SharedJitInstrumentation *jit_instrumentation; /* optional */ dsa_area *area; /* points to DSA area in DSM */ dsa_pointer param_exec; /* serialized PARAM_EXEC parameters */ bool finished; /* set true by ExecParallelFinish */ /* These two arrays have pcxt->nworkers_launched entries: */ shm_mq_handle **tqueue; /* tuple queues for worker output */ struct TupleQueueReader **reader; /* tuple reader/writer support */ } ParallelExecutorInfo;
reader负责从worker产生结果存储的共享队列(在shm_mq中,由ExecParallelSetupTupleQueues创建共享内存队列,并设置接收者和发送者)读取记录,通过Latch进行相互通知。
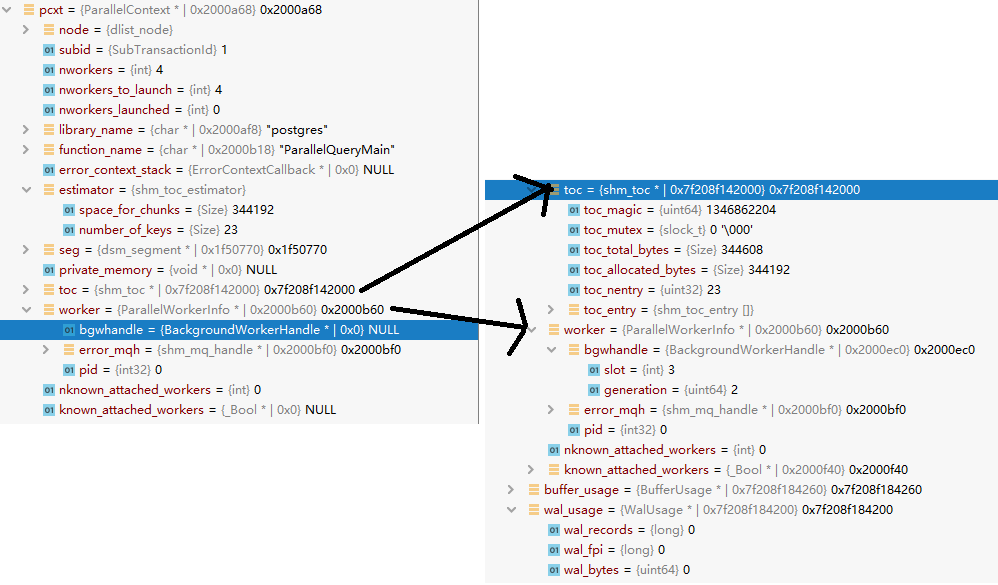
typedef struct ParallelWorkerInfo { BackgroundWorkerHandle *bgwhandle; shm_mq_handle *error_mqh; int32 pid; } ParallelWorkerInfo; typedef struct ParallelContext { dlist_node node; SubTransactionId subid; int nworkers; /* Maximum number of workers to launch */ int nworkers_to_launch; /* Actual number of workers to launch */ int nworkers_launched; char *library_name; char *function_name; ErrorContextCallback *error_context_stack; shm_toc_estimator estimator; dsm_segment *seg; void *private_memory; shm_toc *toc; ParallelWorkerInfo *worker; int nknown_attached_workers; bool *known_attached_workers; } ParallelContext; typedef struct ParallelWorkerContext { dsm_segment *seg; shm_toc *toc; } ParallelWorkerContext;
在pg中,并行执行的时候,子进程并非由leader进程直接fork,而是通过给postmaster进程发送PMSIGNAL_BACKGROUND_WORKER_CHANGE信号、统一由postmaster进行fork,成功之后通过信号告知leader,子进程的pid,这样pg_stat_activity里面leadPid就有了。
SendPostmasterSignal(PMSIGNAL_BACKGROUND_WORKER_CHANGE); /* * SendPostmasterSignal - signal the postmaster from a child process */ void SendPostmasterSignal(PMSignalReason reason) { /* If called in a standalone backend, do nothing */ if (!IsUnderPostmaster) return; /* Atomically set the proper flag */ PMSignalState->PMSignalFlags[reason] = true; /* Send signal to postmaster */ kill(PostmasterPid, SIGUSR1); }
/* * sigusr1_handler - handle signal conditions from child processes */ static void sigusr1_handler(SIGNAL_ARGS) { int save_errno = errno; /* * We rely on the signal mechanism to have blocked all signals ... except * on Windows, which lacks sigaction(), so we have to do it manually. */ #ifdef WIN32 PG_SETMASK(&BlockSig); #endif /* * RECOVERY_STARTED and BEGIN_HOT_STANDBY signals are ignored in * unexpected states. If the startup process quickly starts up, completes * recovery, exits, we might process the death of the startup process * first. We don't want to go back to recovery in that case. */ if (CheckPostmasterSignal(PMSIGNAL_RECOVERY_STARTED) && pmState == PM_STARTUP && Shutdown == NoShutdown) { /* WAL redo has started. We're out of reinitialization. */ FatalError = false; AbortStartTime = 0; /* * Crank up the background tasks. It doesn't matter if this fails, * we'll just try again later. */ Assert(CheckpointerPID == 0); CheckpointerPID = StartCheckpointer(); Assert(BgWriterPID == 0); BgWriterPID = StartBackgroundWriter(); /* * Start the archiver if we're responsible for (re-)archiving received * files. */ Assert(PgArchPID == 0); if (XLogArchivingAlways()) PgArchPID = pgarch_start(); /* * If we aren't planning to enter hot standby mode later, treat * RECOVERY_STARTED as meaning we're out of startup, and report status * accordingly. */ if (!EnableHotStandby) { AddToDataDirLockFile(LOCK_FILE_LINE_PM_STATUS, PM_STATUS_STANDBY); #ifdef USE_SYSTEMD sd_notify(0, "READY=1"); #endif } pmState = PM_RECOVERY; } if (CheckPostmasterSignal(PMSIGNAL_BEGIN_HOT_STANDBY) && pmState == PM_RECOVERY && Shutdown == NoShutdown) { /* * Likewise, start other special children as needed. */ Assert(PgStatPID == 0); PgStatPID = pgstat_start(); ereport(LOG, (errmsg("database system is ready to accept read only connections"))); /* Report status */ AddToDataDirLockFile(LOCK_FILE_LINE_PM_STATUS, PM_STATUS_READY); #ifdef USE_SYSTEMD sd_notify(0, "READY=1"); #endif pmState = PM_HOT_STANDBY; connsAllowed = ALLOW_ALL_CONNS; /* Some workers may be scheduled to start now */ StartWorkerNeeded = true; } /* Process background worker state changes. */ if (CheckPostmasterSignal(PMSIGNAL_BACKGROUND_WORKER_CHANGE)) { /* Accept new worker requests only if not stopping. */ BackgroundWorkerStateChange(pmState < PM_STOP_BACKENDS); StartWorkerNeeded = true; } if (StartWorkerNeeded || HaveCrashedWorker) maybe_start_bgworkers(); if (CheckPostmasterSignal(PMSIGNAL_WAKEN_ARCHIVER) && PgArchPID != 0) { /* * Send SIGUSR1 to archiver process, to wake it up and begin archiving * next WAL file. */ signal_child(PgArchPID, SIGUSR1); } /* Tell syslogger to rotate logfile if requested */ if (SysLoggerPID != 0) { if (CheckLogrotateSignal()) { signal_child(SysLoggerPID, SIGUSR1); RemoveLogrotateSignalFiles(); } else if (CheckPostmasterSignal(PMSIGNAL_ROTATE_LOGFILE)) { signal_child(SysLoggerPID, SIGUSR1); } } if (CheckPostmasterSignal(PMSIGNAL_START_AUTOVAC_LAUNCHER) && Shutdown <= SmartShutdown && pmState < PM_STOP_BACKENDS) { /* * Start one iteration of the autovacuum daemon, even if autovacuuming * is nominally not enabled. This is so we can have an active defense * against transaction ID wraparound. We set a flag for the main loop * to do it rather than trying to do it here --- this is because the * autovac process itself may send the signal, and we want to handle * that by launching another iteration as soon as the current one * completes. */ start_autovac_launcher = true; } if (CheckPostmasterSignal(PMSIGNAL_START_AUTOVAC_WORKER) && Shutdown <= SmartShutdown && pmState < PM_STOP_BACKENDS) { /* The autovacuum launcher wants us to start a worker process. */ StartAutovacuumWorker(); } if (CheckPostmasterSignal(PMSIGNAL_START_WALRECEIVER)) { /* Startup Process wants us to start the walreceiver process. */ /* Start immediately if possible, else remember request for later. */ WalReceiverRequested = true; MaybeStartWalReceiver(); } /* * Try to advance postmaster's state machine, if a child requests it. * * Be careful about the order of this action relative to sigusr1_handler's * other actions. Generally, this should be after other actions, in case * they have effects PostmasterStateMachine would need to know about. * However, we should do it before the CheckPromoteSignal step, which * cannot have any (immediate) effect on the state machine, but does * depend on what state we're in now. */ if (CheckPostmasterSignal(PMSIGNAL_ADVANCE_STATE_MACHINE)) { PostmasterStateMachine(); } if (StartupPID != 0 && (pmState == PM_STARTUP || pmState == PM_RECOVERY || pmState == PM_HOT_STANDBY) && CheckPromoteSignal()) { /* Tell startup process to finish recovery */ signal_child(StartupPID, SIGUSR2); } #ifdef WIN32 PG_SETMASK(&UnBlockSig); #endif errno = save_errno; }
/* * CheckPostmasterSignal - check to see if a particular reason has been * signaled, and clear the signal flag. Should be called by postmaster * after receiving SIGUSR1. */ bool CheckPostmasterSignal(PMSignalReason reason) { /* Careful here --- don't clear flag if we haven't seen it set */ if (PMSignalState->PMSignalFlags[reason]) { PMSignalState->PMSignalFlags[reason] = false; return true; } return false; }
数据交互全部是通过shmq进行轮训拉取,因为是实时轮训拉取,所以shmq按说不会很大。
从lightdb 23.1开始,还支持pg_distribute优化器提示,详细使用可见https://blog.csdn.net/qq_17713935/article/details/128935591。
并行执行本身的入口函数在ParallelQueryMain(dsm_segment *seg, shm_toc *toc)。
https://www.cnblogs.com/lightdb/p/16182376.html
https://tada.github.io/pljava/use/parallel.html
https://www.postgresql.eu/events/pgconfeu2018/sessions/session/2140/slides/141/PQ_PGCON_EU_2018.pdf
https://wiki.postgresql.org/images/9/92/Parallel-query-in-postgresql.pdf
https://pgconf.in/files/presentations/2019/02-0301-Dilip_Kumar-PGConfIndiaParallelQuery_Dilip.pdf
https://wiki.postgresql.org/wiki/Parallel_Recovery
https://wiki.postgresql.org/wiki/Parallel_Internal_Sort
https://wiki.postgresql.org/wiki/Parallel_Query_Execution
最后,讲分区,pg分区不支持parallel,即使理论上可以使用并行执行(假设没有不支持的函数和操作符的情况下),此时建议使用lightdb单实例分布式版,参见lightdb分布式版使用入门及性能提升对比。
对于GPORCA而言,默认支持union/union all并行执行,由参数optimizer_parallel_union控制。
测试下来,到目前为止,opengauss、tbase不支持并行执行。
