K近邻算法
本文总字数:2698,阅读预计需要:7分钟

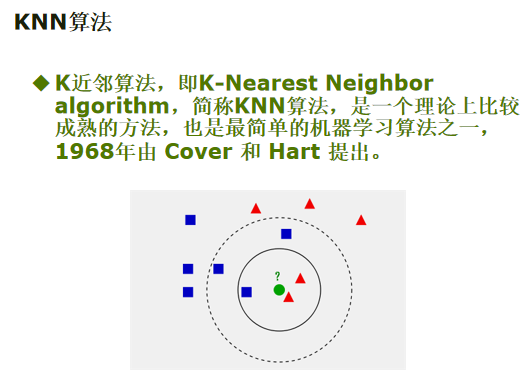
KNN:K-NearestNeighbor–K最近邻(原理)
K最近邻,就是k个最近的邻居的意思,即:每个样本都可以用他最近的k个邻居来代表。
核心思想:如果一个样本在特征空间中的K个最相邻的样本,并且最相邻样本中的大多数属于某一个类别(该样本也属于这个类别,并具有该类别上样本的特性)
KNN很大程度上取决于K的选择

算法三要素:
k值的选择
距离度量方式--------百度上很多
分类决策规制

距离度量:
欧氏距离():
曼哈顿距离(城市街区距离):

k值选择:
较小k值:相当于较小的领域中训练实例,训练误差减小,容易过拟合;
较大k值:较大领域训练实例进行预测,有点减少泛化误差,缺点训练误差增加。

分类决策规则:
分类:
多数表决法
回归:
平均值

如何实现KNN
补充知识:python中对字典进行排序

import operator
def SortDict():
dic={'a':1,'b':2,'c':3,'f':0}
#函数原型:sorted(dic,value,reverse)
#按字典中的键进行升序排序
print("按字典中的键进行升序排序:",\
sorted(dic.items(),key=operator.itemgetter(0),reverse=False))
#按字典中的键进行降序排序
print("按字典中的键进行降序排序:",\
sorted(dic.items(),key=operator.itemgetter(0),reverse=True))
#按字典中的值进行升序排序
print("按字典中的值进行升序排序:",\
sorted(dic.items(),key=operator.itemgetter(1),reverse=False))
#按字典中的值进行降序排序
print("按字典中的值进行降序排序:",\
sorted(dic.items(),key=operator.itemgetter(1),reverse=True))
SortDict()
································································
输出结果:
按字典中的键进行升序排序: [('a', 1), ('b', 2), ('c', 3), ('f', 0)]
按字典中的键进行降序排序: [('f', 0), ('c', 3), ('b', 2), ('a', 1)]
按字典中的值进行升序排序: [('f', 0), ('a', 1), ('b', 2), ('c', 3)]
按字典中的值进行降序排序: [('c', 3), ('b', 2), ('a', 1), ('f', 0)]
简单的knn实现的代码:
#-coding:utf-8-- """ 自定义实现KNN算法 给定一组数据集:其包括了(x,y) 给定一个预测的样本, 通过KNN来预测样本属于哪分类 样本集: 1,1,A 1,2,A 1.5,1.5,A 3,4,B 4,4,B 测试数据: 2,2 请通过KNN对该数据进行分类预测 算法实现思路: 1,计算预测样本和数据集中样本点距离 2,将所有距离从小到大排序 3,计算前K个最短距离类别的个数 4,返回前K个最小距离中个数最多的的分类 """ import numpy as np import operator def handle_data(dataset): """ dataset:样本集 return:输出x和y """ x=dataset[:,:-1].astype(float) y=dataset[:,-1] return x,y def knn_classifier(k,dataset,input): """ k:k个邻居 dataset:所有数据集 input:测试数据 return:输出预测类别 """ x,y=handle_data(dataset) #1,计算预测样本和数据集样本的距离 dist=np.sum((input-x)**2,axis=1)**0.5 #axis=1表示一维 #2,将所有距离从小到大排序 sortedDist=np.argsort(dist) #argsort 排序之后输出下标 #3,计算前K个最短距离类别的个数 countLable={} for i in range(k): label=y[sortedDist[i]] countLable[label]=countLable.get(label,0)+1 #4,返回前K个最小距离中个数最多的的分类(python中字典的排序) sortedLabel=sorted(countLable.items(),key=operator.itemgetter(1),reverse=True) return sortedLabel[0][0] if __name__ == "__main__": dataset = np.loadtxt("C:/Users/yanruyu/Documents/code/python/GA/dataset.txt",dtype="str",encoding='utf-8',delimiter=',') #默认为float,需要dtype x=dataset[:,:-1].astype(np.float) y=dataset[:,-1] test=[2,2] #预测数据 print(knn_classifier(3,dataset,test)) ··························································· 输出结果: PS C:\Users\yanruyu> & D:/Anaconda3/python.exe c:/Users/yanruyu/Documents/code/python/GA/text.py A
我们向往远方,却忽略了此刻的美丽


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗