kmeans算法
本文总字数:6848,阅读预计需要:17分钟


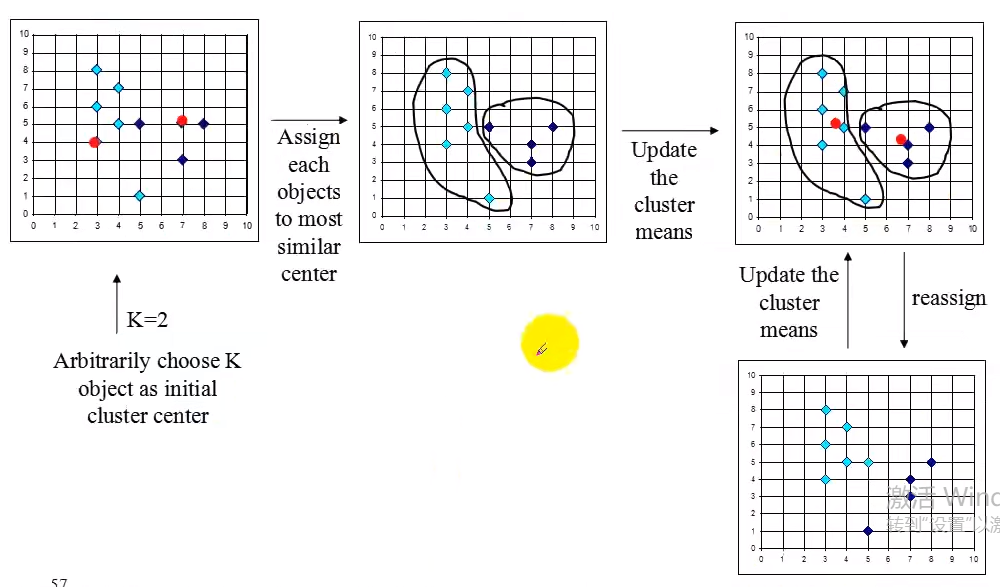
3.1划分方法

聚类算法距离——k-means算法

k-means算法

输入:簇的数;数据集;
输出:k个簇
方法:从数据集中找出k个对象当作原始的簇心;
k-means算法的再次解读

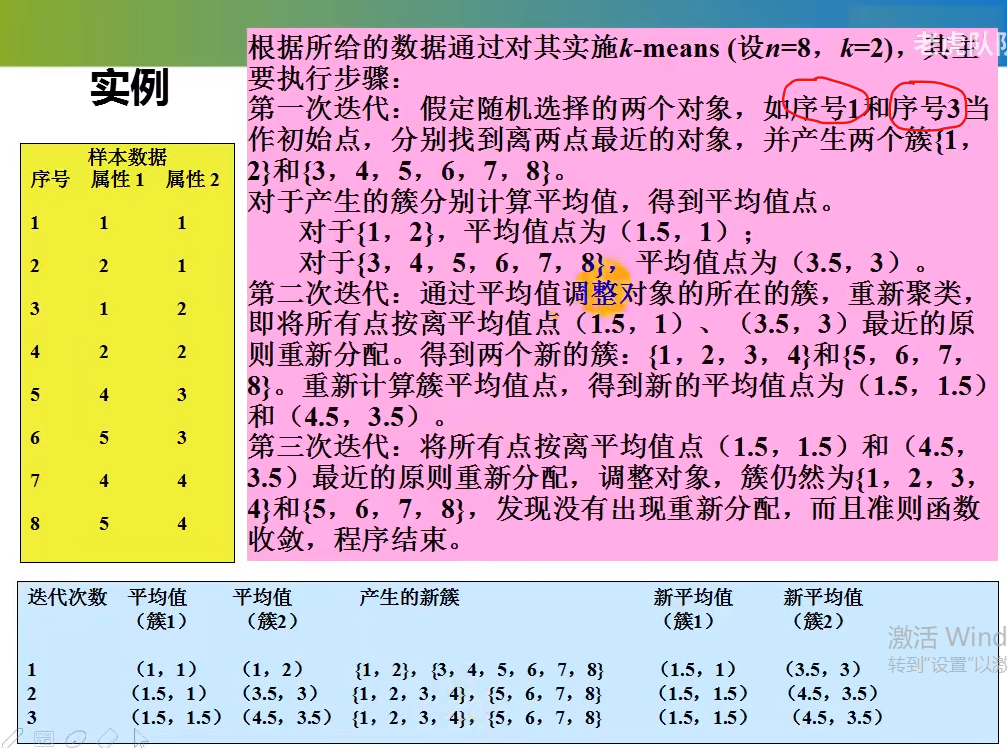
k-means聚类算法练习-1
下面10个样本进行簇划分
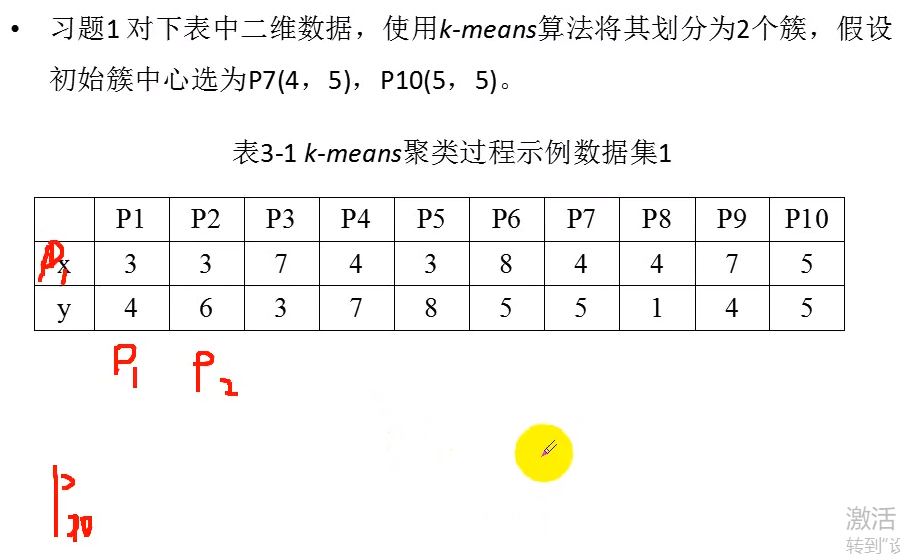
使用代码计算连续值属性距离

import numpy as np
a=np.array([(3,4),(3,6),(7,3),(4,7),(3,8),(8,5),(4,5),(4,1),(7,4),(5,5)])
lines=""
for i in a:
for j in a:
dis=np.sqrt(np.sum((j-i)**2))
lines += "%.2f"%dis + "," #保留两位小数 #“str(dis)+","
lines+='\n'
file=open("result.csv",mode="w",encoding="utf-8")
file.write(lines)
file.close()
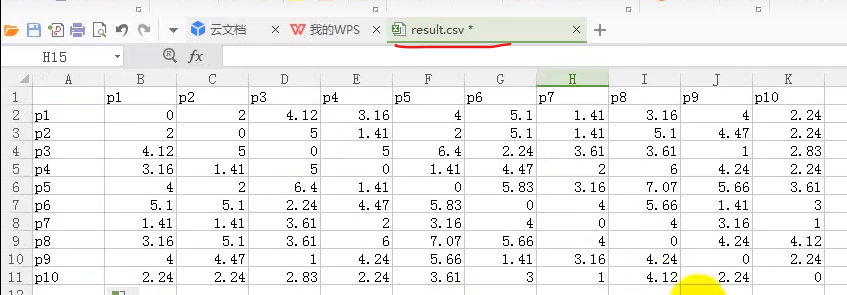
第一轮迭代完得到的分别以p7、p10为中心的两个簇
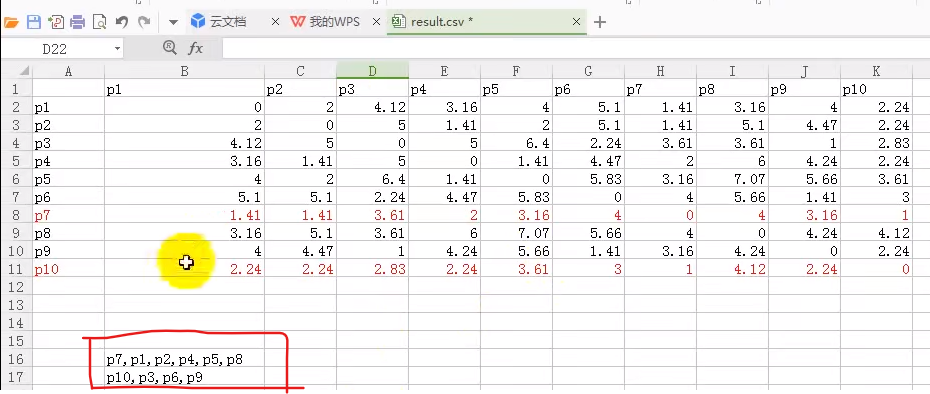
下面开始计算每个簇中心的均值
p7、p1、p2、p4、p5、p8样本点的x值相加求平均,y值相加求平均得到一个新的簇中心点
p10、p3、p6、p9样本点的x值相加求平均,y值相加求平均得到一个新的簇中心点
新的簇中心点再来和所有的样本数据点求距离

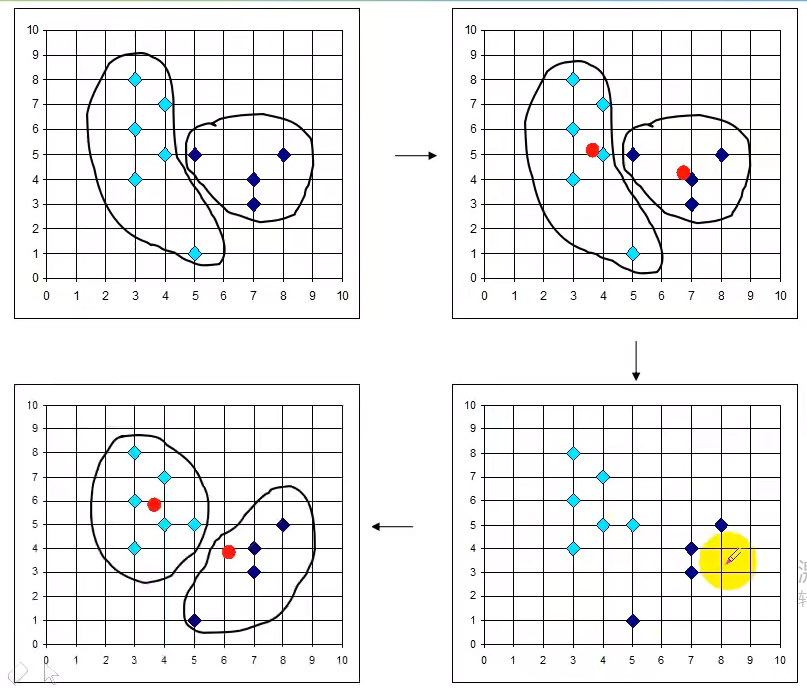
实例

问题一
序号4和7是一样的(巧合),其实换做其他的序号3和7,与之前的结果不一样
问题二
结论是:k-means算法 的初始中心点对k-means算法有极大的影响,不同的初始点可能最终聚类的结果不同,特别是数据样本比较少的情况下
代码演示k-means算法
数据样本
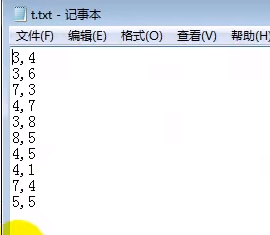
data.txt
3,4 3,6 7,3 4,7 3,8 8,5 4,5 4,1 7,4 5,5
"""
随机取k个中心点
计算所有点到中心点到距离
将所有点放入中心点所在到簇
更新中心点
如果中心点不变,结束迭代
迭代
"""
import numpy as np
#获取数据集
def loadDataSet(filename):
return np.loadtxt(filename,delimiter=',',dtype=np.float)
#取k个中心点
def initCenters(dataset,k):
"""
返回的k个中心点
dataset:数据集
k:中心点的个数
return:
"""
centersIndex=np.random.choice(len(dataset),k,replace=False)
return dataset[centersIndex]
#计算距离
def distance(x,y):
return np.sqrt(np.sum((x-y)**2))
#kmeans的核心算法
def kmeans(dataset,k):
"""
dataset:数据集
k:中心点的个数
return:k个簇
"""
#初始化中心点
# centers=initCenters(dataset,k)
centers=np.array([[4,5],[5,5]],dtype=np.float)
n,m=dataset.shape
#用于存储每个样本属于哪个簇
clusters=np.full(n,np.nan)
#迭代
flag=True
while flag:
flag=False
#计算所有点到簇中心的距离
for i in range(n):
minDist,clustersIndex=99999999,0
for j in range(len(centers)):
dist=distance(dataset[i],centers[j])
if dist<minDist:
#为样本分簇
minDist=dist
clustersIndex=j
#判断簇是否改变
if clusters[i]!=clustersIndex:
clusters[i]=clustersIndex
flag=True
print(centers)
print(clusters)
#更新簇中心
for i in range(k):
subdataset=dataset[np.where(clusters==i)] #得到下标
centers[i]=np.mean(subdataset,axis=0)
print("循环一次")
return clusters
if __name__=='__main__':
dataset=loadDataSet('data.txt')
print(kmeans(dataset,2))
结果

加上簇点显示代码(相比上面只添加了红色字段部分)
"""
随机取k个中心点
计算所有点到中心点到距离
将所有点放入中心点所在到簇
更新中心点
如果中心点不变,结束迭代
迭代
"""
import numpy as np
import matplotlib.pyplot as plt
#获取数据集
def loadDataSet(filename):
return np.loadtxt(filename,delimiter=',',dtype=np.float)
#取k个中心点
def initCenters(dataset,k):
"""
返回的k个中心点
dataset:数据集
k:中心点的个数
return:
"""
centersIndex=np.random.choice(len(dataset),k,replace=False)
return dataset[centersIndex]
#计算距离
def distance(x,y):
return np.sqrt(np.sum((x-y)**2))
#kmeans的核心算法
def kmeans(dataset,k):
"""
dataset:数据集
k:中心点的个数
return:k个簇
"""
#初始化中心点
# centers=initCenters(dataset,k)
centers=np.array([[4,5],[5,5]],dtype=np.float)
n,m=dataset.shape
#用于存储每个样本属于哪个簇
clusters=np.full(n,np.nan)
#迭代
flag=True
while flag:
flag=False
#计算所有点到簇中心的距离
for i in range(n):
minDist,clustersIndex=99999999,0
for j in range(len(centers)):
dist=distance(dataset[i],centers[j])
if dist<minDist:
#为样本分簇
minDist=dist
clustersIndex=j
#判断簇是否改变
if clusters[i]!=clustersIndex:
clusters[i]=clustersIndex
flag=True
print(centers)
print(clusters)
#更新簇中心
for i in range(k):
subdataset=dataset[np.where(clusters==i)] #得到下标
centers[i]=np.mean(subdataset,axis=0)
print("循环一次")
return clusters,centers
#显示
def show(dataset,k,clusters,centers):
n,m = dataset.shape
if m>2:
print('维度大于2')
return 1
#根据簇的不同marker不同
colors = ["r","g","b","y"]
for i in range(n):
clusterIndex = clusters[i].astype(np.int)
plt.plot(dataset[i][0],dataset[i][1],color=colors[clusterIndex], marker='o')
pass
for i in range(k):
plt.scatter(centers[i][0],centers[i][1],marker='s')
pass
plt.show()
if __name__=='__main__':
dataset=loadDataSet('data.txt')
clusters,centers = kmeans(dataset,2)
show(dataset,2,clusters,centers)
显示结果
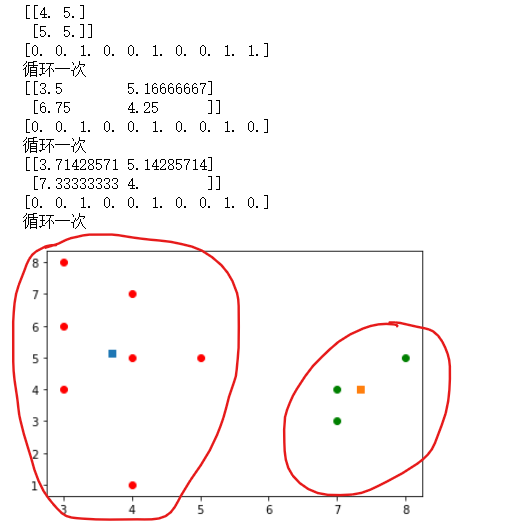
注意红色需要注释
"""
随机取k个中心点
计算所有点到中心点到距离
将所有点放入中心点所在到簇
更新中心点
如果中心点不变,结束迭代
迭代
"""
import numpy as np
import matplotlib.pyplot as plt
#获取数据集
def loadDataSet(filename):
return np.loadtxt(filename,delimiter=',',dtype=np.float)
#取k个中心点
def initCenters(dataset,k):
"""
返回的k个中心点
dataset:数据集
k:中心点的个数
return:
"""
centersIndex=np.random.choice(len(dataset),k,replace=False)
return dataset[centersIndex]
#计算距离
def distance(x,y):
return np.sqrt(np.sum((x-y)**2))
#kmeans的核心算法
def kmeans(dataset,k):
"""
dataset:数据集
k:中心点的个数
return:k个簇
"""
#初始化中心点
centers=initCenters(dataset,k)
# centers=np.array([[4,5],[5,5]],dtype=np.float)
n,m=dataset.shape
#用于存储每个样本属于哪个簇
clusters=np.full(n,np.nan)
#迭代
flag=True
while flag:
flag=False
#计算所有点到簇中心的距离
for i in range(n):
minDist,clustersIndex=99999999,0
for j in range(len(centers)):
dist=distance(dataset[i],centers[j])
if dist<minDist:
#为样本分簇
minDist=dist
clustersIndex=j
#判断簇是否改变
if clusters[i]!=clustersIndex:
clusters[i]=clustersIndex
flag=True
print(centers)
print(clusters)
#更新簇中心
for i in range(k):
subdataset=dataset[np.where(clusters==i)] #得到下标
centers[i]=np.mean(subdataset,axis=0)
print("循环一次")
return clusters,centers
#显示
def show(dataset,k,clusters,centers):
n,m = dataset.shape
if m>2:
print('维度大于2')
return 1
#根据簇的不同marker不同
colors = ["r","g","b","y"]
for i in range(n):
clusterIndex = clusters[i].astype(np.int)
plt.plot(dataset[i][0],dataset[i][1],color=colors[clusterIndex], marker='o')
pass
for i in range(k):
plt.scatter(centers[i][0],centers[i][1],marker='s')
pass
plt.show()
if __name__=='__main__':
dataset=loadDataSet('data.txt')
clusters,centers = kmeans(dataset,3) #分成3个簇
show(dataset,3,clusters,centers)
显示结果
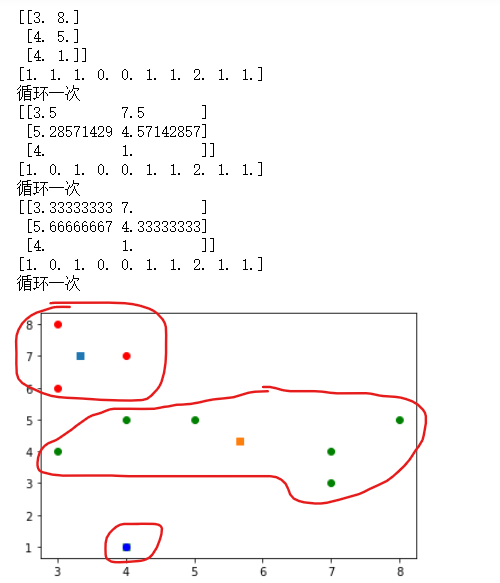



k-means算法无法探测凹形簇
打算分成左边形式,带对应缺点三,所以k-means只能分成有图形式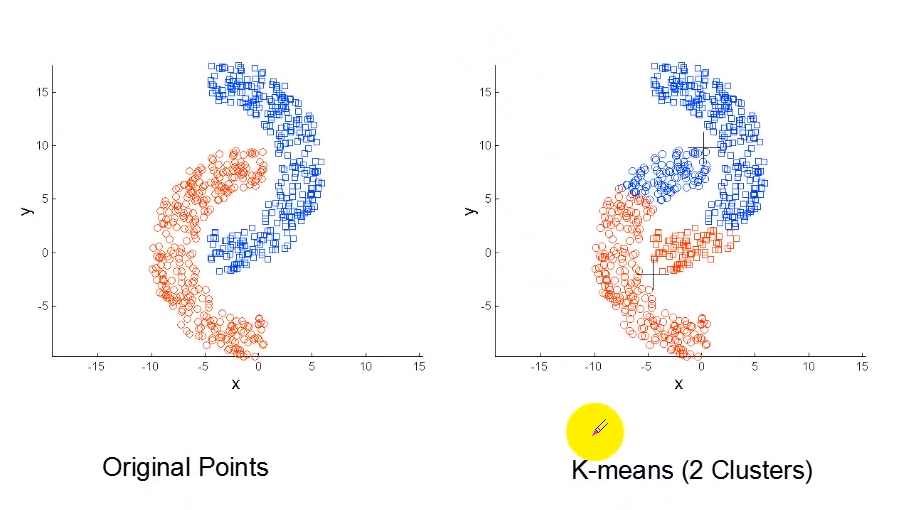

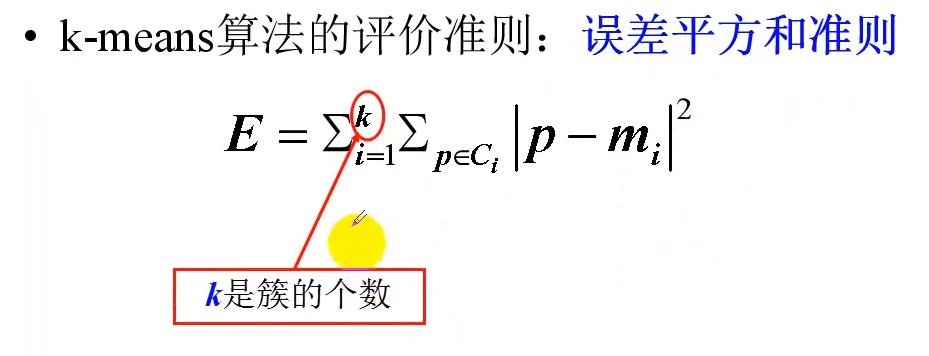
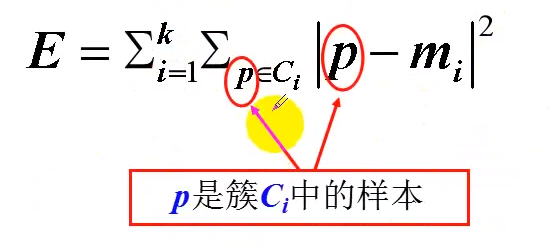
聚簇结果的评价标准(二)

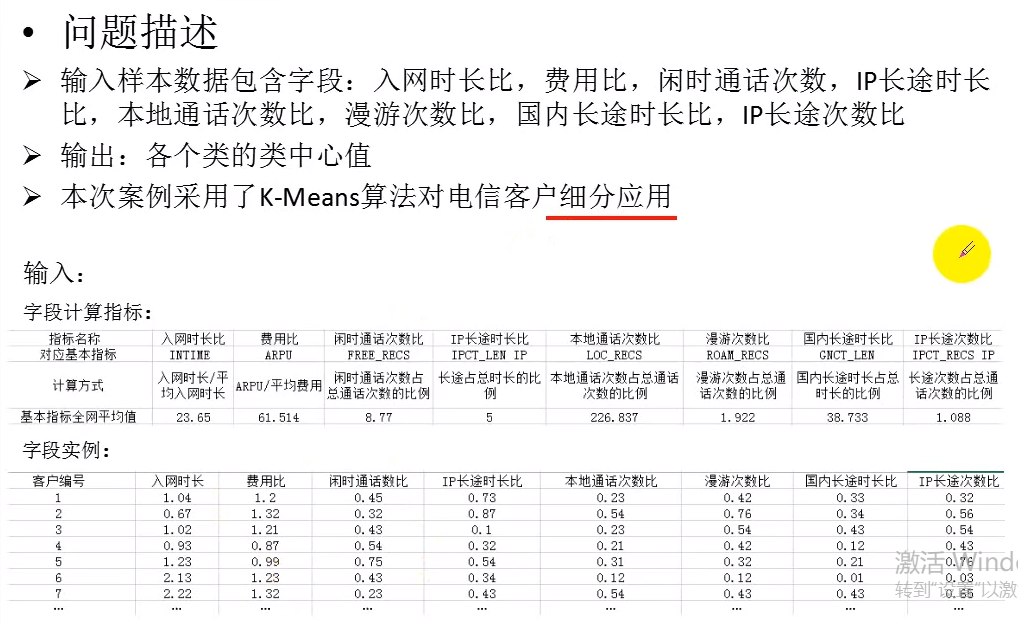
k-means算法在电信运营中的应用案例

我们向往远方,却忽略了此刻的美丽


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗