Numpy实现机器学习交叉验证的数据划分
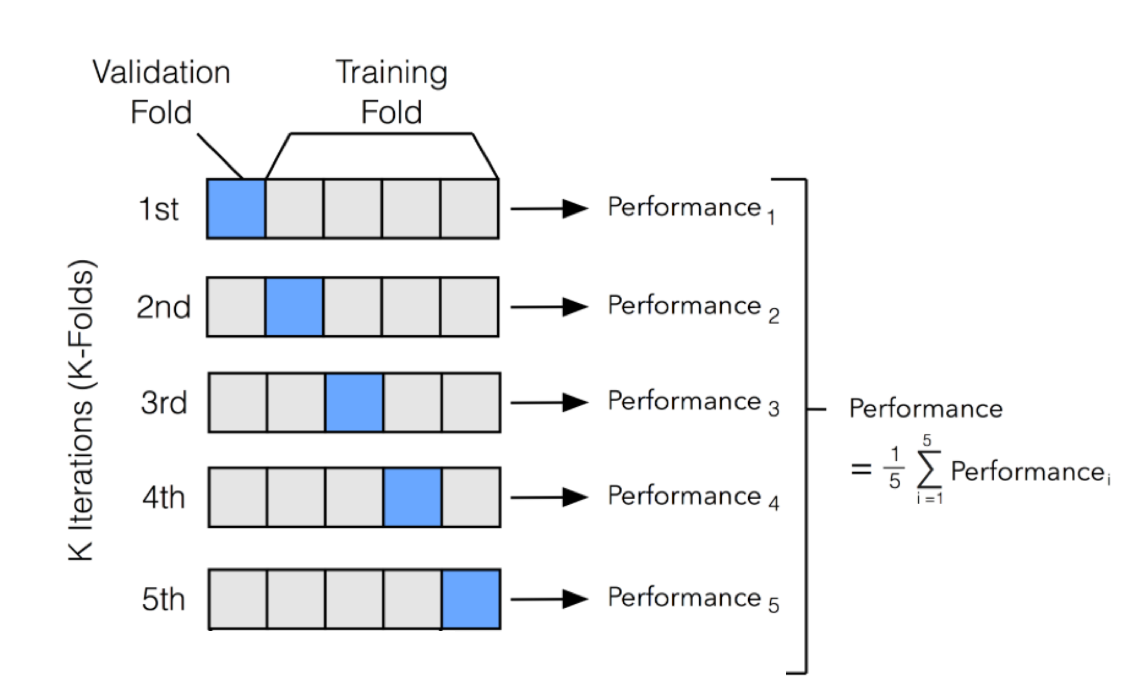
Numpy实现K折交叉验证的数据划分
本实例使用Numpy的数组切片语法,实现了K折交叉验证的数据划分
背景:K折交叉验证
为什么需要这个?
在机器学习中,因为如下原因,使用K折交叉验证能更好评估模型效果:
- 样本量不充足,划分了训练集和测试集后,训练数据更少;
- 训练集和测试集的不同划分,可能会导致不同的模型性能结果;
K折验证是什么
K折验证(K-fold validtion)将数据划分为大小相同的K个分区。
对每个分区i,在剩余的K-1个分区上训练模型,然后在分区i上评估模型。
最终分数等于K个分数的平均值,使用平均值来消除训练集和测试集的划分影响;
1. 模拟构造样本集合
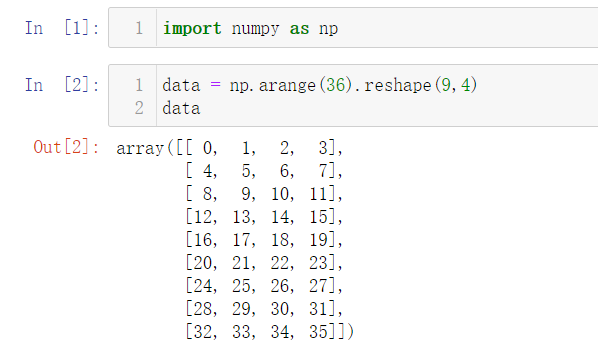
用样本的角度解释下data数组:
- 这是一个二维矩阵,行代表每个样本,列代表每个特征
- 这里有9个样本,每个样本有4个特征
这是scikit-learn模型训练输入的标准格式
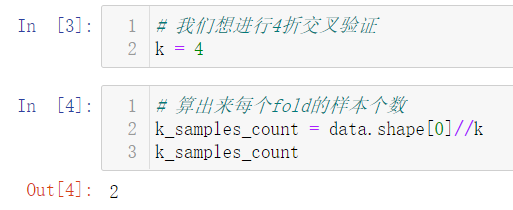
2. 使用Numpy实现K次划分
for fold in range(k):
validation_begin = k_samples_count*fold
validation_end = k_samples_count*(fold+1)
validation_data = data[validation_begin:validation_end]
# np.vstack,沿着垂直的方向堆叠数组
train_data = np.vstack([
data[:validation_begin],
data[validation_end:]
])
print()
print(f"#####第{fold}折#####")
print("验证集:\n", validation_data)
print("训练集:\n", train_data)
如果使用scikit-learn,已经有封装好的实现:
from sklearn.model_selection import cross_val_score
我们向往远方,却忽略了此刻的美丽

 浙公网安备 33010602011771号
浙公网安备 33010602011771号