对数几率回归(逻辑回归)
回归:连续值预测
逻辑回归:分类算法。–逻辑回归是干什么?
定义:对定性变量的回归分析;
定性:
定量:
之前的回归模型,处理的是因变量是数值型区间(负无穷到正无穷)变量,建立的模型描述的是因变量Y与自变量(X)之间的线性关系。
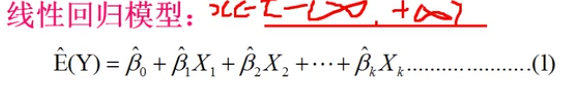
期望=期望参数与自变量的分别乘积和;
逻辑变换的公式:要记住
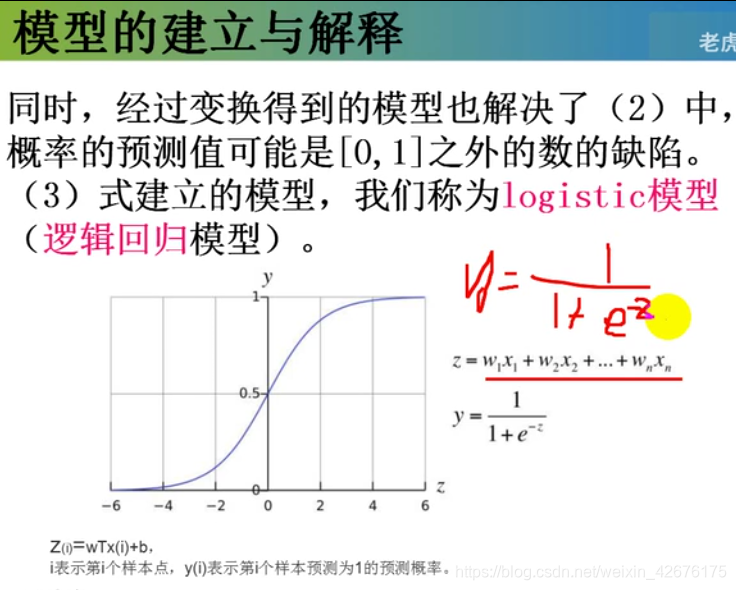

注:结果是对称的,一般情况是0.5;如果结果不是对称的,一般情况不是0.5


使用最小二乘法求:上面的函数服从正态分布,然后倒过来推。

对数似然函数为:
lnL=****
他是一个凸函数(相当于四个角的吊床)
g()是1/(1 + e^(-z))

第一个是批量;第二个是随机。----接下来写程序。
作业:
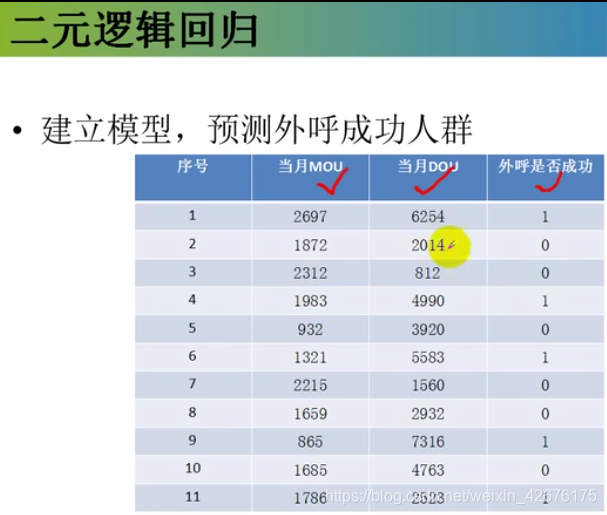
DOU是每个客户月均流量消费额,单位MB
MOU(minutes of usage)。平均每户每月通话时间(average communication time per one month per one user) 电信行业的一个衡量指标,单位:分钟
代码:
import numpy as np
def sigmoid(x):
return 1/(1+np.exp(-x))
def weights(x_train, y_train): # 获取权重
# 初始化参数
theta = np.random.rand(3) # 生成n个随机数
# 学习率
alpha = 0.001
# 迭代次数
cnt = 0
# 最大迭代次数
max_cnt = 50000
# 误差
# error0=error1=1
# 指定一个阈值,用于检查两次误差的差,以便停止迭代
threshold = 0.01
m,n = x_train.shape
while cnt <= max_cnt:
cnt += 1
diff = np.full(n, 0) # 梯度的初始值三个零
for i in range(m):
# diff=(y_train-1/(1+np.exp(-theta.T@x_train.T)))@x_train).T #@是矩阵点乘,批量梯度下降
diff = ((y_train[i]-sigmoid(theta.T@x_train[i]))
* x_train[i]).T # 外面的.T是表示所有的梯度去求解
print(diff)
theta = theta+alpha*diff
if (abs(diff) < threshold).all():
break
return theta
def predict(x_test,weights):
if sigmoid(weights.T@x_test)>0.5:
return 1
else:
return 0
if __name__ == "__main__":
x_train = np.array([[1, 2.697, 6.254],
[1, 1.872, 2.014],
[1, 2.312, 0.812],
[1, 1.983, 4.990],
[1, 0.932, 3.920],
[1, 1.321, 5.583],
[1, 2.215, 1.560],
[1, 1.659, 2.932],
[1, 0.865, 7.316],
[1, 1.685, 4.763],
[1, 1.786, 2.523]])
y_train = np.array([1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1])
weights=weights(x_train, y_train)
print(predict([1, 1.786, 2.523],weights))
·························································
输出:
[0.0003332 0.00089864 0.00208383]
[0.00033319 0.00089862 0.00208379]
1
最大迭代次数为5000的时候,预测结果为0,结果不理想:可能有几种情况。
1)weihts权重没有迭代到最理想的状态;
2)数据异常(收敛异常)
3)激活函数选取不理想(收敛不理想)
sklearn中也提供了这个包,如何使用?
# -*- coding: utf-8 -*-
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import numpy as np
dataset=np.loadtxt("C:/Users/yanruyu/Documents/code/python/GA/dataset.txt",delimiter=',')
x_train,x_test,y_train,y_test=train_test_split(dataset[:,0:-1],dataset[:,-1],test_size=0.3)
model=LogisticRegression(penalty="l2") #加入正则化参数,效率会提高很多。
model.fit(x_train,y_train)
print(y_test==model.predict(x_text))
输出:
[False True True True]
可以用线性模型中SGD分类模型试一下,不过要调参。
回归:连续值预测
逻辑回归:分类算法。–逻辑回归是干什么?
定义:对定性变量的回归分析;
定性:
定量:
之前的回归模型,处理的是因变量是数值型区间(负无穷到正无穷)变量,建立的模型描述的是因变量Y与自变量(X)之间的线性关系。
我们向往远方,却忽略了此刻的美丽

 浙公网安备 33010602011771号
浙公网安备 33010602011771号