

机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系?
原文:http://www.zhihu.com/question/20448464
5 个回答

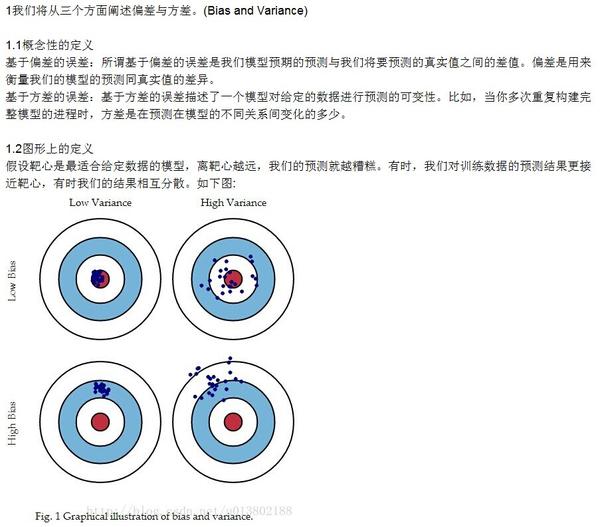
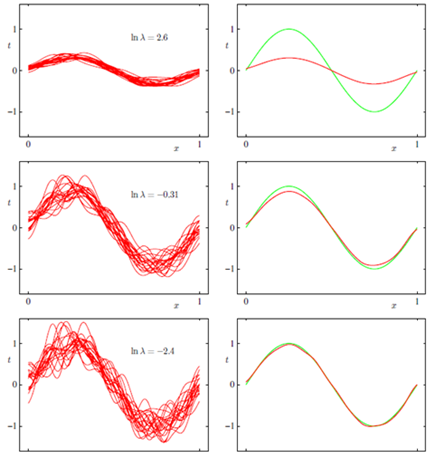
偏差:描述的是预测值(估计值)的期望与真实值之间的差距。偏差越大,越偏离真实数据,如下图第二行所示。
方差:描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散,如下图右列所示。 参考:Understanding the Bias-Variance Tradeoff
参考:Understanding the Bias-Variance Tradeoff
原文:http://www.zhihu.com/question/27068705
最近在学习机器学习,在学到交叉验证的时候,有一块内容特别的让我困惑,Error可以理解为在测试数据上跑出来的不准确率 ,即为 (1-准确率)。
在训练数据上面,我们可以进行交叉验证(Cross-Validation)。
一种方法叫做K-fold Cross Validation (K折交叉验证), K折交叉验证,初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测。
当K值大的时候, 我们会有更少的Bias(偏差), 更多的Variance。
当K值小的时候, 我们会有更多的Bias(偏差), 更少的Variance。
我十分不理解上述的描述,求大神来解释到底什么是Bias, Error,和Variance?
交叉验证,对于这三个东西到底有什么影响?修改
在训练数据上面,我们可以进行交叉验证(Cross-Validation)。
一种方法叫做K-fold Cross Validation (K折交叉验证), K折交叉验证,初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测。
当K值大的时候, 我们会有更少的Bias(偏差), 更多的Variance。
当K值小的时候, 我们会有更多的Bias(偏差), 更少的Variance。
我十分不理解上述的描述,求大神来解释到底什么是Bias, Error,和Variance?
交叉验证,对于这三个东西到底有什么影响?修改
按投票排序按时间排序
12 个回答

首先 Error = Bias + Variance
Error反映的是整个模型的准确度,Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,Variance反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。
举一个例子,一次打靶实验,目标是为了打到10环,但是实际上只打到了7环,那么这里面的Error就是3。具体分析打到7环的原因,可能有两方面:一是瞄准出了问题,比如实际上射击瞄准的是9环而不是10环;二是枪本身的稳定性有问题,虽然瞄准的是9环,但是只打到了7环。那么在上面一次射击实验中,Bias就是1,反应的是模型期望与真实目标的差距,而在这次试验中,由于Variance所带来的误差就是2,即虽然瞄准的是9环,但由于本身模型缺乏稳定性,造成了实际结果与模型期望之间的差距。
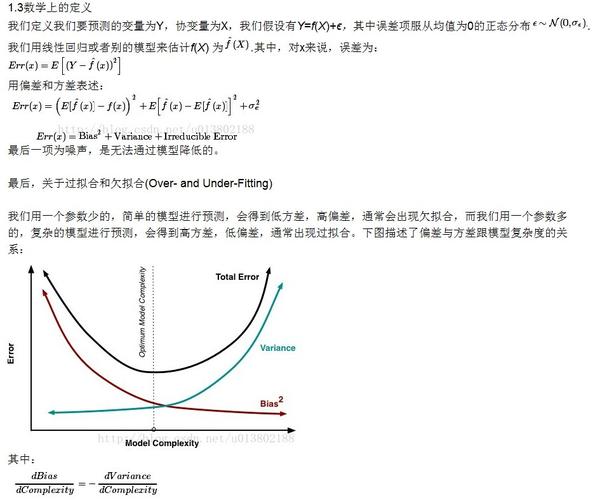
在一个实际系统中,Bias与Variance往往是不能兼得的。如果要降低模型的Bias,就一定程度上会提高模型的Variance,反之亦然。造成这种现象的根本原因是,我们总是希望试图用有限训练样本去估计无限的真实数据。当我们更加相信这些数据的真实性,而忽视对模型的先验知识,就会尽量保证模型在训练样本上的准确度,这样可以减少模型的Bias。但是,这样学习到的模型,很可能会失去一定的泛化能力,从而造成过拟合,降低模型在真实数据上的表现,增加模型的不确定性。相反,如果更加相信我们对于模型的先验知识,在学习模型的过程中对模型增加更多的限制,就可以降低模型的variance,提高模型的稳定性,但也会使模型的Bias增大。Bias与Variance两者之间的trade-off是机器学习的基本主题之一,机会可以在各种机器模型中发现它的影子。
具体到K-fold Cross Validation的场景,其实是很好的理解的。首先看Variance的变化,还是举打靶的例子。假设我把抢瞄准在10环,虽然每一次射击都有偏差,但是这个偏差的方向是随机的,也就是有可能向上,也有可能向下。那么试验次数越多,应该上下的次数越接近,那么我们把所有射击的目标取一个平均值,也应该离中心更加接近。更加微观的分析,模型的预测值与期望产生较大偏差,在模型固定的情况下,原因还是出在数据上,比如说产生了某一些异常点。在最极端情况下,我们假设只有一个点是异常的,如果只训练一个模型,那么这个点会对整个模型带来影响,使得学习出的模型具有很大的variance。但是如果采用k-fold Cross Validation进行训练,只有1个模型会受到这个异常数据的影响,而其余k-1个模型都是正常的。在平均之后,这个异常数据的影响就大大减少了。相比之下,模型的bias是可以直接建模的,只需要保证模型在训练样本上训练误差最小就可以保证bias比较小,而要达到这个目的,就必须是用所有数据一起训练,才能达到模型的最优解。因此,k-fold Cross Validation的目标函数破坏了前面的情形,所以模型的Bias必然要会增大。
Error反映的是整个模型的准确度,Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,Variance反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。
举一个例子,一次打靶实验,目标是为了打到10环,但是实际上只打到了7环,那么这里面的Error就是3。具体分析打到7环的原因,可能有两方面:一是瞄准出了问题,比如实际上射击瞄准的是9环而不是10环;二是枪本身的稳定性有问题,虽然瞄准的是9环,但是只打到了7环。那么在上面一次射击实验中,Bias就是1,反应的是模型期望与真实目标的差距,而在这次试验中,由于Variance所带来的误差就是2,即虽然瞄准的是9环,但由于本身模型缺乏稳定性,造成了实际结果与模型期望之间的差距。
在一个实际系统中,Bias与Variance往往是不能兼得的。如果要降低模型的Bias,就一定程度上会提高模型的Variance,反之亦然。造成这种现象的根本原因是,我们总是希望试图用有限训练样本去估计无限的真实数据。当我们更加相信这些数据的真实性,而忽视对模型的先验知识,就会尽量保证模型在训练样本上的准确度,这样可以减少模型的Bias。但是,这样学习到的模型,很可能会失去一定的泛化能力,从而造成过拟合,降低模型在真实数据上的表现,增加模型的不确定性。相反,如果更加相信我们对于模型的先验知识,在学习模型的过程中对模型增加更多的限制,就可以降低模型的variance,提高模型的稳定性,但也会使模型的Bias增大。Bias与Variance两者之间的trade-off是机器学习的基本主题之一,机会可以在各种机器模型中发现它的影子。
具体到K-fold Cross Validation的场景,其实是很好的理解的。首先看Variance的变化,还是举打靶的例子。假设我把抢瞄准在10环,虽然每一次射击都有偏差,但是这个偏差的方向是随机的,也就是有可能向上,也有可能向下。那么试验次数越多,应该上下的次数越接近,那么我们把所有射击的目标取一个平均值,也应该离中心更加接近。更加微观的分析,模型的预测值与期望产生较大偏差,在模型固定的情况下,原因还是出在数据上,比如说产生了某一些异常点。在最极端情况下,我们假设只有一个点是异常的,如果只训练一个模型,那么这个点会对整个模型带来影响,使得学习出的模型具有很大的variance。但是如果采用k-fold Cross Validation进行训练,只有1个模型会受到这个异常数据的影响,而其余k-1个模型都是正常的。在平均之后,这个异常数据的影响就大大减少了。相比之下,模型的bias是可以直接建模的,只需要保证模型在训练样本上训练误差最小就可以保证bias比较小,而要达到这个目的,就必须是用所有数据一起训练,才能达到模型的最优解。因此,k-fold Cross Validation的目标函数破坏了前面的情形,所以模型的Bias必然要会增大。


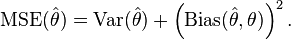


最开始学统计的时候,会觉得R-square (adjusted, AIC, BIC, etc)解释模型越多越好,但这样就会有overfitting的的问题。就是说模型解释training data巨牛啊,但testing data就不行了。overfitting就是字面的意思,模型是无偏了,但variance过大。所以需要把数据分成subset。variance-bias balance之类。具体怎么权衡就可以写一本书了。。。
那为什么又要cross-validation呢,很大一个好处是避免对test dataset的二次overfitting。每次留一个的那个是LOOCV啦,k-fold一般取k=5/10比较常见,当然也可以根据你的需要(看样本量怎么可以整除啦之类的),当然再具体选几又可以探讨很多了,也要看电脑和软件的运算能力。。。
那为什么又要cross-validation呢,很大一个好处是避免对test dataset的二次overfitting。每次留一个的那个是LOOCV啦,k-fold一般取k=5/10比较常见,当然也可以根据你的需要(看样本量怎么可以整除啦之类的),当然再具体选几又可以探讨很多了,也要看电脑和软件的运算能力。。。

Danning Wang、路远之、小感 赞同
Error就像一楼说的 = Bias + Variance
通常而言,机器学习会选一个函数空间,这个函数空间可能并不包含最优的函数,这样即使学习出来这个函数空间中损失函数最小的那个也会和真正最优的函数存在差别,这个差别就是Bias。此外,由于我们并不知道训练数据的联合分布p(x,y),当然,知道了就不用学了,可以直接推导出p(y|x)了。所以我们在学习的时候往往是从存在但未知的p(x,y)中随机出训练数据集,因为训练数据集不能无限,这样训练数据的分布和真实的p(x,y)也存在不一致,所以在原来的Bias的基础上又增加了Variance。
以上就是误差的两个来源了。
例如我们要做数据拟合,这里我们假设真实的数据是指数分布,但是我们不知道,所以我们选择使用线性函数去拟合数据,这样函数空间中的模型只有线性模型,和真实的指数分布有差距,选择线性空间的时候带入了Bias。另外,我们只能通过有限的观测点去学习线性模型的参数,有限的观测点来自总体分布的抽样,并不是完全符合总体数据的p(x,y)分布,这就是Variance的来源了。
为了更形象的说明,我们可以这么理解:假设我们要测量一个物体的长度,我们会选一把尺子去测量,这把尺子可能不是百分之百的准确,选择尺子不同会带来Bias。然后我们用尺子测的时候人去估计又会带来误差,这就是所谓的Variance了。
不知道这样解释你能否理解?
通常而言,机器学习会选一个函数空间,这个函数空间可能并不包含最优的函数,这样即使学习出来这个函数空间中损失函数最小的那个也会和真正最优的函数存在差别,这个差别就是Bias。此外,由于我们并不知道训练数据的联合分布p(x,y),当然,知道了就不用学了,可以直接推导出p(y|x)了。所以我们在学习的时候往往是从存在但未知的p(x,y)中随机出训练数据集,因为训练数据集不能无限,这样训练数据的分布和真实的p(x,y)也存在不一致,所以在原来的Bias的基础上又增加了Variance。
以上就是误差的两个来源了。
例如我们要做数据拟合,这里我们假设真实的数据是指数分布,但是我们不知道,所以我们选择使用线性函数去拟合数据,这样函数空间中的模型只有线性模型,和真实的指数分布有差距,选择线性空间的时候带入了Bias。另外,我们只能通过有限的观测点去学习线性模型的参数,有限的观测点来自总体分布的抽样,并不是完全符合总体数据的p(x,y)分布,这就是Variance的来源了。
为了更形象的说明,我们可以这么理解:假设我们要测量一个物体的长度,我们会选一把尺子去测量,这把尺子可能不是百分之百的准确,选择尺子不同会带来Bias。然后我们用尺子测的时候人去估计又会带来误差,这就是所谓的Variance了。
不知道这样解释你能否理解?
roach sinai 赞同
推荐一篇博文:《机器学习中的数学(2)-线性回归,偏差、方差权衡》
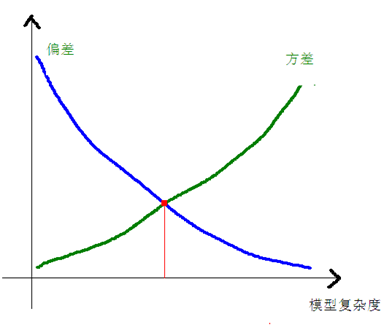
方差和偏差一般来说,是从同一个数据集中,用科学的采样方法得到几个不同的子数据集,用这些子数据集得到的模型,就可以谈他们的方差和偏差的情况了。方差和偏差的变化一般是和模型的复杂程度成正比的,就像本文一开始那四张小图片一样,当我们一味的追求模型精确匹配,则可能会导致同一组数据训练出不同的模型,它们之间的差异非常大。这就叫做方差,不过他们的偏差就很小了,如下图所示:
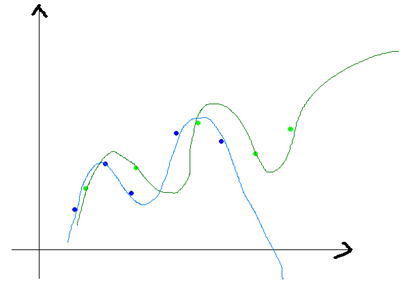 上图的蓝色和绿色的点是表示一个数据集中采样得到的不同的子数据集,我们有两个N次的曲线去拟合这些点集,则可以得到两条曲线(蓝色和深绿色),它们的差异就很大,但是他们本是由同一个数据集生成的,这个就是模型复杂造成的方差大。模型越复杂,偏差就越小,而模型越简单,偏差就越大,方差和偏差是按下面的方式进行变化的:
上图的蓝色和绿色的点是表示一个数据集中采样得到的不同的子数据集,我们有两个N次的曲线去拟合这些点集,则可以得到两条曲线(蓝色和深绿色),它们的差异就很大,但是他们本是由同一个数据集生成的,这个就是模型复杂造成的方差大。模型越复杂,偏差就越小,而模型越简单,偏差就越大,方差和偏差是按下面的方式进行变化的:
方差和偏差一般来说,是从同一个数据集中,用科学的采样方法得到几个不同的子数据集,用这些子数据集得到的模型,就可以谈他们的方差和偏差的情况了。方差和偏差的变化一般是和模型的复杂程度成正比的,就像本文一开始那四张小图片一样,当我们一味的追求模型精确匹配,则可能会导致同一组数据训练出不同的模型,它们之间的差异非常大。这就叫做方差,不过他们的偏差就很小了,如下图所示:
上图的蓝色和绿色的点是表示一个数据集中采样得到的不同的子数据集,我们有两个N次的曲线去拟合这些点集,则可以得到两条曲线(蓝色和深绿色),它们的差异就很大,但是他们本是由同一个数据集生成的,这个就是模型复杂造成的方差大。模型越复杂,偏差就越小,而模型越简单,偏差就越大,方差和偏差是按下面的方式进行变化的:
最后还是用数学的语言来描述一下偏差和方差:
E(L)是损失函数,h(x)表示真实值的平均,第一部分是与y(模型的估计函数)有关的,这个部分是由于我们选择不同的估计函数(模型)带来的差异,而第二部分是与y无关的,这个部分可以认为是模型的固有噪声。
对于上面公式的第一部分,我们可以化成下面的形式:
这个部分在PRML的1.5.5推导,前一半是表示偏差,而后一半表示方差,我们可以得出:损失函数=偏差^2+方差+固有噪音。
