
什么是机器学习
除去一些无关紧要的情况,人们很难从原始数据本身找到有效的信息。例如,对于垃圾邮件的检测,检测一个单词是否存在没有太大作用,然而当某个特定的单词(垃圾邮件的关键词)同时出现时,再辅助其他因素,人们就可以判断出该邮件是否为垃圾邮件。
简单的说,机器学习就是把无序的数据转换成为有用的信息,是一种数据分析的方法。

机器学习的主要任务
机器学习的两大分类:
- 监督学习
- 非监督学习
监督学习的主要任务是分类和回归,因为这类算法必须要知道预测什么,也就是目标的分类信息。
非监督学习的主要任务是聚类和密度估计,没有类别信息,也不会有给定目标的值。
可以理解为监督学习可以得到的是一个结果,而非监督学习是一个过程。
监督学习-分类
机器学习主要任务之一分类。
这让我想到了香港电影《赌侠》里面有段视频,通过摄像机把对方的牌照下来并识别。
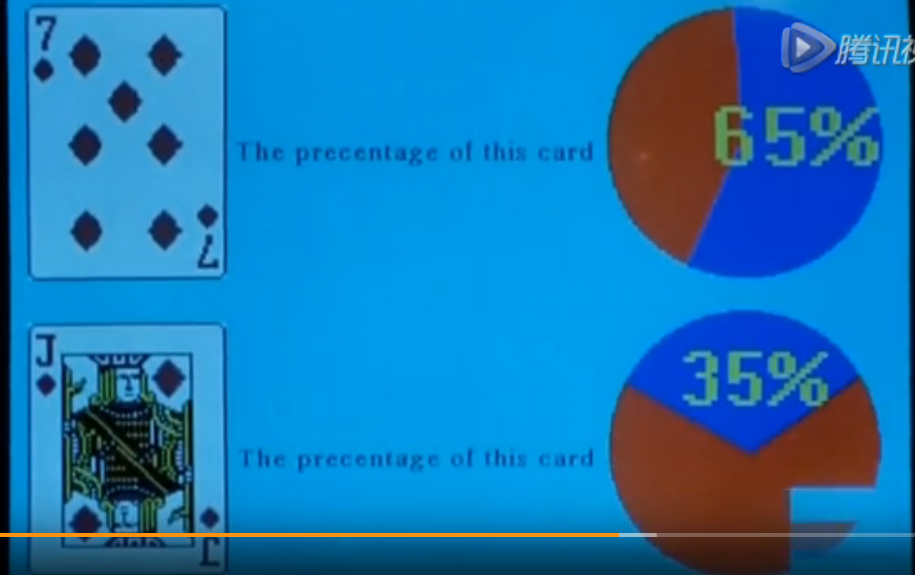
看到上图,摄像机把设别的图片分类两类:65%是方块7, 35%是方块J。这个意思就是大概就是分类了。
机器学习的一些术语(在监督学习中)
1 特征:也叫作属性,比如鸟有体重,翼展,脚蹼和后背颜色,我们可以通过这些特征来区分是哪些鸟。
2 算法训练:其实就是通过一定的算法来学习如何分类,比如给我们一个新的特征值,我们如何判断是哪种鸟?
3 训练集:训练机器学习算法的数据样本集合,这些训练集需要知道分类的结果,也就是说我们要知道100个鸟的名字和每个鸟的特征数据。
4 目标变量:每个训练集都有特征和目标变量,目标变量是机器学习算法的预测结果。
5 测试集:测试机器学习算法的样本数据。此数据没有分类结果,需要输入特征值通过机器学习得到目标变量。
开发机器学习的几个步骤
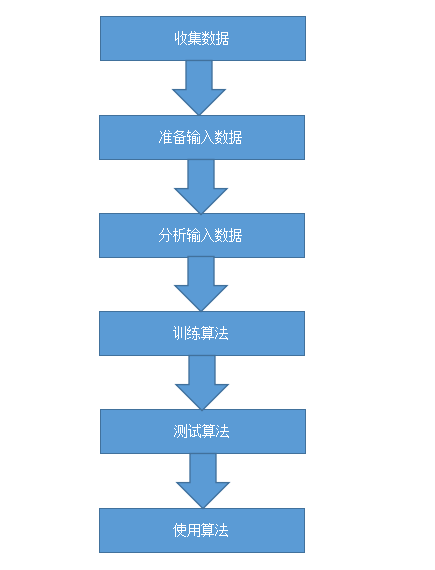
1 收集数据。我们可以使用客户提供的数据源也可以自己写网络爬虫找到自己想要的数据,数据越干净越好。
2 准备输入数据。得到数据后,通过一定方法需要把数据处理成程序能识别能分析的数据格式。
3 分析输入数据。这个主要是人工分析准备输入的数据是否有问题,确保前两步都有效,最简单的方法是打开到文笔编辑器看数据是否有空值。这步骤主要确保数据中没有脏数据。
4 训练算法。我们将前两部得到的格式化数据输入到算法中运算,从中抽取信息并存储为计算机可处理的格式,方便后续使用。无监督学习没有这个步骤。
5 测试算法。实际运用第四部得到的信息,通过一些方法对算法做评估。若对算法不满意则可以回到第4步或者更钱一步进行重复执行。
6 使用算法。将机器学习算法转换为应用程序,执行实际任务。来检查上述步骤是否可以在实际环境中正常工作。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?