
聊聊分布式 SQL 数据库Doris(三)
在 Doris 的存储引擎规则:
- 表的数据是以分区为单位存储的,不指定分区创建时,默认就一个分区.
- 用户数据首先被划分成若干个分区(Partition),划分的规则通常是按照用户指定的分区列进行范围划分,比如按时间划分。
- 在每个分区内,数据被进一步的按照Hash的方式分桶,分桶的规则是要找用户指定的分桶列的值进行Hash后分桶。每个分桶就是一个数据分片(Tablet),也是数据划分的最小逻辑单元。
- Partition 可以视为是逻辑上最小的管理单元。数据的导入与删除,都可以或仅能针对一个 Partition 进行。
- Tablet直接的数据是没有交集的,独立存储的。Tablet也是数据移动、复制等操作的最小物理存储单元。
Table (逻辑描述) -- > Partition(分区:管理单元) --> Bucket/Tablet(分桶:存储,每个分桶就是一个数据分片:Tablet,数据划分的最小逻辑单元。称为子表) --> segment(Tablet会按照一定大小(256M)拆分为多个segment文件) ,如下图:
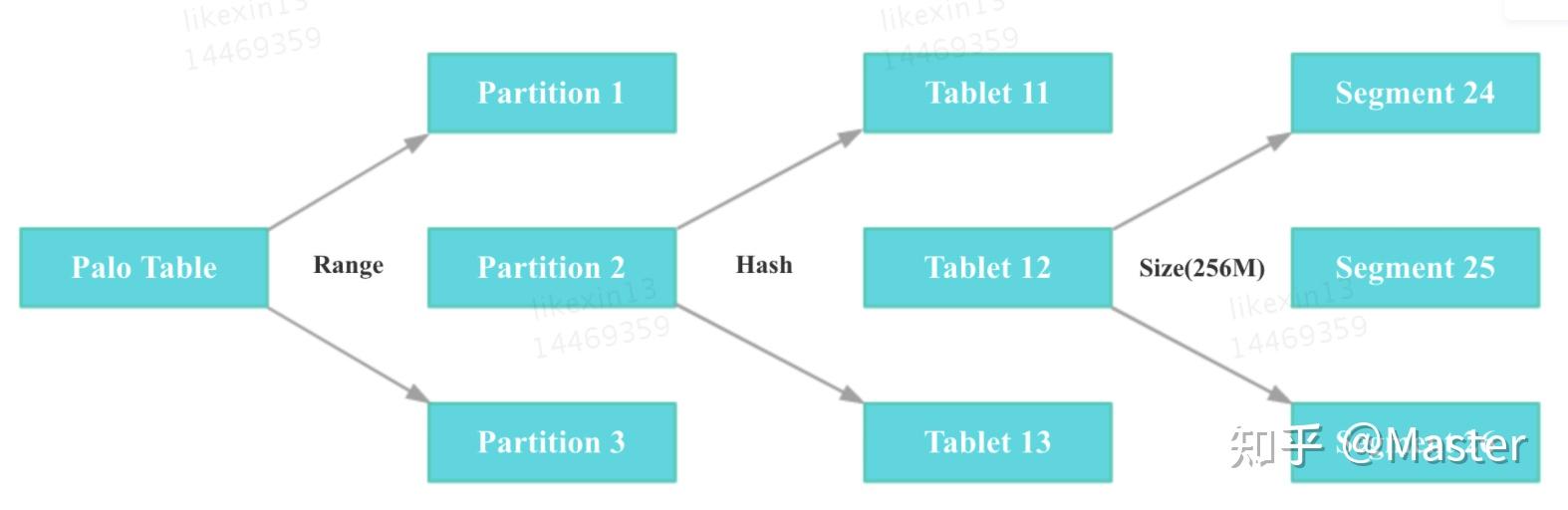
Doris的存储结构类似LSM,从存储结构展开来看两者的比对:
Doris MemTable --> LSM MemTable; Doris Rowset --> LSM SST;
Doris中的Segment是对Rowset文件的拆分。多个Segment组成Rowset。
Doris中的数据被组织成一个个 segment,这是数据写入和查询的基本单元。每个 segment 包含了数据页(page),而数据页是数据读取的最小单元。
语法与示例
语法:
-- 该表记录了某个时间点,在某个站点上各个用户的pv数据
CREATE TABLE demo.test_tbl(
sdate DATE, -- 日期
site INT, -- 站点id
city VARCHAR(64), -- 城市
user VARCHAR(32) DEFAULT '', -- 用户名
pv BIGINT -- pv量
) ENGINE=olap DUPLICATE KEY(sdate, site, city)
[PARTITION_DESC]
[BUCKET_DESC]
PROPERTIES ("replication_num" = "1");
[PARTITION_DESC] 表示创建分区的详细语句,[BUCKET_DESC] 表示创建分桶的语句.
动态分区:
PARTITION BY RANGE(sdate)()
-- 剩余参数需要在PARTITION进行配置:
PROPERTIES (
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-30",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.create_history_partition"="true",
"replication_num" = "1"
);
分桶:
DISTRIBUTED BY HASH(site) BUCKETS 20
此时指定以 site 列的哈希值作为分桶,并且分桶个数设置为 20 个.
官方示例:
CREATE TABLE tbl1
(
k1 DATE,
-- ...
)
PARTITION BY RANGE(k1) ()
DISTRIBUTED BY HASH(k1)
PROPERTIES
(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-7",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "32"
);
批量分区与自动分桶
批量分区使得用户能够批量操作表的分区结构,一次性创建多个分区,而不是逐个单独创建。
-- 当然,分区创建个数受到max_multi_partition_num参数控制,该值默认为4096,有需求可以修改
PARTITION BY RANGE(sdate)
(
FROM ("2013-01-01") TO ("2023-01-01") INTERVAL 1 DAY
)
-- 从这个 case 来看,批量分区功能的语法更为简洁,但该功能的易用性和灵活性远不止于此。
自动分桶是基于表中某个列(或在创建表时指定咧)的值范围进行的。系统会根据该列的数据分布情况,将数据划分到不同的数据桶中。
-- 旧版本指定分桶个数的创建语法
DISTRIBUTED BY HASH(site) BUCKETS 20
-- 新版本使用自动分桶推算的创建语法
DISTRIBUTED BY HASH(site) BUCKETS AUTO
properties("estimate_partition_size" = "100G")
关键逻辑
查询路由
一个分区的数据不会跨多个不同的BE节点存储.
在 Apache Doris 中,当请求到来时,查询某个分区的数据时,Doris 使用以下的过程来定位到相应的 Backend(BE)节点:
-
分区键(Partition Key): 在 Doris 中,表的分区是按照某一列的值范围进行划分的,这个列通常被称为分区键。用户在创建表时可以选择分区键。
-
查询请求中的分区键值: 当查询请求到达 Doris 时,请求中通常包含了要查询的分区键值。
-
分区键值与分区映射关系: Doris 通过分区键值与分区的映射关系,确定具体的分区。这个映射关系通常存储在系统的元数据中,其中包括每个分区所在的 BE 节点信息。
-
BE 节点负责的分区: 根据分区键值的映射关系,Doris 确定了负责该分区的 BE 节点。
-
查询计划的生成和执行: Doris 生成查询计划,其中包含了具体的查询操作。该计划会被发送到负责该分区的 BE 节点上执行。
在 Apache Doris 中,一个表的多个分区数据通常会存储在不同的 Backend(BE)节点上,以实现分布式存储和查询的优势。每个分区的数据都会被划分并存储在负责该分区的一个 BE 节点上。具体来说:
-
表的分区: Doris 中的表通常根据某一列的值范围进行分区。每个分区是表的逻辑组织单元,用于提高查询性能、管理数据、支持按范围删除等操作。
-
分布式存储: Doris 的设计目标之一是分布式存储和查询。因此,一个表的多个分区数据会被分布存储在不同的 BE 节点上。这样的设计有助于提高系统的横向扩展性,允许系统有效地处理大规模数据和高并发的查询请求。
-
负责分区的 BE 节点: Doris 通过元数据信息记录每个分区所在的 BE 节点。当执行查询请求时,Doris 会根据查询涉及的分区,确定负责这些分区的 BE 节点。每个 BE 节点负责存储和管理分配给它的分区数据。
-
分布式计算: 查询请求在涉及多个分区时,Doris 可以通过分布式计算的方式,在多个 BE 节点上并行执行查询计划,以提高查询性能。
分桶算法
暂时只支持HASH.
分区算法
暂时只支持List, RANGE. 常用的有四种: (a) Round-Robin、(b) Range、(c) List、(d) Hash .
