

《算法》笔记 11 - 最小生成树
- 最小生成树的应用
- 切分定理
- 贪心算法
- 加权无向图的数据结构
- Prim算法
- Kruskal算法
最小生成树的应用
加权图是一种为每条边关联一个权值的图模型,这种图可以表示许多应用,比如在一副航空图中,边表示航线,权值就可以表示距离或费用;在一副电路图中,边表示导线,权值就可以表示导线的长度或成本。在这些情形中,最令人感兴趣的便是如何将成本最小化。最小生成树就是用于在加权无向图中解决这类问题的。最小生成树相关的算法在通信、电子、水利、网络、交通灯行业具有广泛的应用。
图的生成树是它的一颗含有其所有顶点的无环连通子图,一副加权无向图的最小生成树(Minimum spanning tree)是它的一颗权值(树中所有边的权值之和)最小的生成树。
切分定理
图的一种切分是将图的所有顶点分为两个非空且不重复的集合。横切边是一条连接两个属于不同集合顶点的边。
通常通过指定一个顶点集并隐式地认为它的补集为另一个顶点集来指定一个切分。这样,一条横切边就是连接该集合的一个顶点和不在该集合中的另一个顶点的一条边。
切分定理
切分定理的内容为:在一副加权图中,给定任意的切分,它的横切边中的权重最小者必然属于图的最小生成树。
切分定理是最小生成树算法的理论依据。
要证明切分定理,需要知道树的两个重要性质:
- 用一条边连接树中的任意两个顶点都会产生一个新的环;
- 从树中删去任意条边都将会得到两颗独立的树。
接下来用反证法证明切分定理:令e为权值最小的横切边,T为图的最小生成树,假设T不包含e,那么将e加入T得到的图必然含有一条经过e的环,且这个环至少还有另一条横切边——设为f,f的的权重必然大于e(因为e的权重是最小的且图中所有边的权值都不相同)。那么删去f保留e就可以得到一颗权值更小的树,这与假设矛盾。
贪心算法
切分定理是所有解决最小生成树问题算法的基础,这些算法都是一种贪心算法的特殊情况,贪心算法是一类在每一步选择中都采取在当前状态下最好或最优的选择,从而希望导致结果是最好或最优的算法。解决最小生成树问题时,会使用切分定理找到最小生成树的一条边,不断重复直到找到最小生成树的所有边。这些算法之间的区别之处在于保存切分和判定权重最小的横切边的方式。
最小生成树的贪心算法:一副加权无向图中,在初始状态下所有边均为灰色,找到一种切分,它产生的横切边均不为黑色,将它权重最小的横切边标记为黑色,如此反复,直到标记了V-1条黑色边为止。
其中V为图中顶点的数量,那么要将这些顶点全部连接,至少需要V-1条边。根据切分定理,所有被标记为黑色的边都属于最小生成树,如果黑色边的数量小于V-1,那么必然还存在不会产生黑色边的切分,只要找够V-1条黑色边,最小生成树就完成了。
加权无向图的数据结构
加权无向图的数据结构没有沿用之前无向图的数据结构,而是重新定义了Edge和EdgeWeightedGraph类,分别用于表示带权重的边和加权无向图。
带权重的边Edge的实现
public class Edge implements Comparable<Edge> {
private final int v;
private final int w;
private final double weight;
public Edge(int v, int w, double weight) {
this.v = v;
this.w = w;
this.weight = weight;
}
public double weight() {
return this.weight;
}
public int either() {
return this.v;
}
public int other(int vertex) {
if (v == vertex)
return w;
if (w == vertex)
return v;
else
throw new RuntimeException("Inconsistent edge");
}
public int compareTo(Edge that) {
if (this.weight() < that.weight())
return -1;
else if (this.weight() > that.weight())
return 1;
else
return 0;
}
public String toString() {
return String.format("%d-%d %.2f", v, w, weight);
}
}
either和other方法可以返回边连接的两个端点,weight表示边的权重。
加权无向图EdgeWeightedGraph的实现
public class EdgeWeightedGraph {
private static final String NEWLINE = System.getProperty("line.separator");
private final int V; // vertex
private int E; // edge
private Bag<Edge>[] adj;
public EdgeWeightedGraph(int V) {
this.V = V;
this.E = 0;
adj = (Bag<Edge>[]) new Bag[V];
for (int v = 0; v < V; v++) {
adj[v] = new Bag<Edge>();
}
}
public EdgeWeightedGraph(In in) {
this(in.readInt());
int E = in.readInt();
for (int i = 0; i < E; i++) {
int v = in.readInt();
int w = in.readInt();
double weight = in.readDouble();
Edge e = new Edge(v, w, weight);
addEdge(e);
}
}
public int V() {
return V;
}
public int E() {
return E;
}
public void addEdge(Edge e) {
int v = e.either(), w = e.other(v);
adj[v].add(e);
adj[w].add(e);
E++;
}
public Iterable<Edge> adj(int v) {
return adj[v];
}
public String toString() {
StringBuilder s = new StringBuilder();
s.append(V + " vertices, " + E + " edges " + NEWLINE);
for (int v = 0; v < V; v++) {
s.append(v + ": ");
for (Edge w : adj[v]) {
s.append(w + " | ");
}
s.append(NEWLINE);
}
return s.toString();
}
public Bag<Edge> edges() {
Bag<Edge> b = new Bag<Edge>();
for (int v = 0; v < V; v++) {
for (Edge w : adj[v]) {
b.add(w);
}
}
return b;
}
EdgeWeightedGraph与无向图中的Graph非常类似,只是用Edge对象替代了Graph中的整数来作为链表的结点。adj(int v)方法可以根据顶点而索引到对应的邻接表,每条边都会出现两次,如果一条边连接了顶点v和w,那么这条边会同时被添加到v和w对应的领接表中。
Prim算法
将要学习的第一种计算最小生成树的方法叫做Prim算法,它的每一部都会为一颗生长中的树添加一条边。一开始这棵树只有一个顶点,然后会向它添加V-1条边,每次总是将下一条连接树的顶点与不在树中的顶点且权重最小的边加入树中。
但如何才能高效地找到权重最小的边呢,使用优先队列便可以达到这个目的,并且保证足够高的效率。因为要寻找的是权重最小的边,所以这里将使用查找最小元素的优先队列MinPQ。
此外,Prim算法还会使用一个由顶点索引的boolean数组marked[],和一条名为mst的队列,前者用来指示已经加入到最小生成树中的顶点,队列则用来保存包含在最小生成树中的边。
每当在向树中添加了一条边时,也向树中添加了一个顶点。要维护一个包含所有横切边的集合,就要将连接这个顶点和其他所有不在树中的顶点的边加入优先队列,通过marked[]数组可以识别这样的边。需要注意的是,随着横切边的不断加入,之前加入的边中,那些连接新加入树中的顶点与其他已经在树中顶点的所有边都失效了,因为这样的边都已经不是横切边了,它的两个顶点都在树中,这样的边是不会被加入到mst队列中的。
接下来用tinyEWG.txt的数据来直观地观察算法的轨迹,tinyEWG.txt的内容如下:
8
16
4 5 0.35
4 7 0.37
5 7 0.28
0 7 0.16
1 5 0.32
0 4 0.38
2 3 0.17
1 7 0.19
0 2 0.26
1 2 0.36
1 3 0.29
2 7 0.34
6 2 0.40
3 6 0.52
6 0 0.58
6 4 0.93
它表示的图包含8个顶点,16条边,末尾的double数值表示边的权重。
下图是算法在处理tinyEWG.txt时的轨迹,每一张图都是算法访问过一个顶点之后(被添加到树中,邻接链表中的边也已经被处理完成),图和优先队列的状态。优先队列的内容被按照顺序显示在一侧,树中的新顶点旁边有个星号。
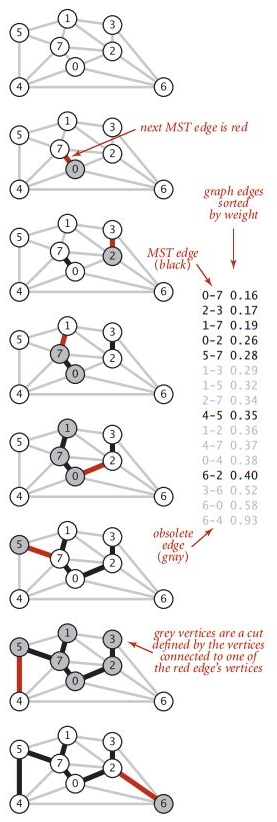
算法构造最小生成树的过程为:
- 将顶点0添加到最小生成树之中,将它的邻接链表中的所有边添加到优先队列之中。
- 将顶点7和边0-7添加到最小生成树之中,将顶点的邻接链表中的所有边添加到优先队列之中。
- 将顶点1和边1-7添加到最小生成树之中,将顶点的邻接链表中的所有边添加到优先队列之中。
- 将顶点2和边0-2添加到最小生成树之中,将边2-3和6-2添加到优先队列之中。边2-7和1-2失效。
- 将顶点3和边2-3添加到最小生成树之中,将边3-6添加到优先队列之中。边1-3失效。
- 将顶点5和边5-7添加到最小生成树之中,将边4-5添加到优先队列之中。边1-5失效。
- 从优先队列中删除失效的边1-3、1-5和2-7。
- 将顶点4和边4-5添加到最小生成树之中,将边6-4添加到优先队列之中。边4-7和0-4失效。
- 从优先队列中删除失效的边1-2、4-7和0-4。
- 将顶点6和边6-2添加到最小生成树之中,和顶点6相关联的其他边均失效。
算法的具体实现:
public class LazyPrimMST {
private boolean[] marked;
private Queue<Edge> mst;
private MinPQ<Edge> pq;
public LazyPrimMST(EdgeWeightedGraph G) {
pq = new MinPQ<Edge>();
marked = new boolean[G.V()];
mst = new Queue<Edge>();
visit(G, 0);
while (!pq.isEmpty()) {
Edge e = pq.delMin();
int v = e.either(), w = e.other(v);
if (marked[v] && marked[w])
continue;
mst.enqueue(e);
if (!marked[v])
visit(G, v);
if (!marked[w])
visit(G, w);
}
}
public void visit(EdgeWeightedGraph G, int v) {
marked[v] = true;
for (Edge e : G.adj(v)) {
if (!marked[e.other(v)]) {
pq.insert(e);
}
}
}
public Iterable<Edge> edges() {
return mst;
}
// cmd /c --% java algs4.four.LazyPrimMST ..\..\..\algs4-data\tinyEWG.txt
public static void main(String[] args) {
In in = new In(args[0]);
EdgeWeightedGraph ewg = new EdgeWeightedGraph(in);
LazyPrimMST lazyPrim = new LazyPrimMST(ewg);
double weight=0;
for (Edge e : lazyPrim.edges()) {
weight += e.weight();
StdOut.println(e);
}
StdOut.println(weight);
}
}
visit()方法的作用是为树添加一个顶点,将它标记为“已访问”,并将与它关联的所有未失效的边加入优先队列中。在while循环中,会从优先队列取出一条边,如果它没有失效,就把它添加到树中,否则只是将其从优先队列删除。然后再根据添加到树中的边的顶点,更新优先队列中横切边的集合。
Kruskal算法
Prim算法是一条边一条边地来构造最小生成树,每一步都为一棵树添加一条边。接下来要学习的Kruskal算法处理问题的方式则是按照边的权重顺序,从小到大将边添加到最小生成树中,加入的边不会与已经加入的边构成环,直到树中含有V-1条边为止。从一片由V颗单结点的树构成的森林开始,不断将两棵树合并,直到只剩下一颗树,它就是最小生成树。
同样是处理tinyEWG.txt,Kruskal算法的轨迹如下图:
【】
该算法首先会将所有的边加入到优先队列并按权重顺序排列,然后依次从优先队列拿到最小的边加入到最小生成树中,然后轮到处理1-3、1-5、2-7这三条边时,发现它们会使最小生成树形成环,说明这些顶点已经被包含到了最小生成树中,属于失效的边;接着继续处理4-5,随后1-2、4-7、0-4又被丢弃,把6-2加入树中后,最小生成树已经有了V-1条边,最小生成树已经形成,查找结束。
算法的具体实现为:
public class KruskalMST {
private Queue<Edge> mst;
private double _weight = 0;
public KruskalMST(EdgeWeightedGraph G) {
mst = new Queue<Edge>();
MinPQ<Edge> pq = new MinPQ<Edge>();
UF uf = new UF(G.V());
for (Edge e : G.edges()) {
pq.insert(e);
}
while (!pq.isEmpty() && mst.size() < G.V() - 1) {
Edge e = pq.delMin();
int v = e.either(), w = e.other(v);
if (uf.connected(v, w))
continue;
uf.union(v, w);
mst.enqueue(e);
_weight += e.weight();
}
}
public Iterable<Edge> edges() {
return mst;
}
public double weight() {
return _weight;
}
// cmd /c --% java algs4.four.KruskalMST ..\..\..\algs4-data\tinyEWG.txt
public static void main(String[] args) {
In in = new In(args[0]);
EdgeWeightedGraph ewg = new EdgeWeightedGraph(in);
KruskalMST kruskalMST = new KruskalMST(ewg);
for (Edge e : kruskalMST.edges()) {
StdOut.println(e);
}
StdOut.println(kruskalMST.weight());
}
}
这里同样使用了MinPQ来为边排序,并使用了之前Union-Find算法中实现的的Quick Union数据结构,用它可以方便地识别会形成环的边,最终生成的最小生成树同样保存在名为mst的队列中。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具