
机器学习算法
1. 线性回归算法
1.1 线性回归简介
一个例子: 去银行贷款,银行给我贷款多少
银行需要你两个数据: 工资和年龄(两个特征值)
目标: 预测银行会贷多少钱给我(标签)
考虑: 工资和年龄都会影响最终银行贷款的结果,那么他们各自有多大的影响呢?
工资(x1) 年龄(x2) 额度(y) 4000 25 20000 8000 30 70000 5000 28 35000 7500 33 50000 12000 40 85000 上面每一行都是一个样本,每个样本有两个特征,工资与年龄。 最终我们预测的是一个值,通常机器学习的有监督算法当中,有回归和分类两种
- 回归是通过一个数据,最终预测出来一个值,这叫回归。比如说现在银行贷款,银行贷款给我的是一个具体的值,拿到的结果是一个完整的值,多少钱,一个数据
- 分类:比如说银行贷款,最终的结果是银行到底借不借你钱,是借和不借的概念,而不是具体的值
通俗解释:
x1,x2就是我们的两个特征(年龄,工资)
y是银行最终会借给我们多少钱
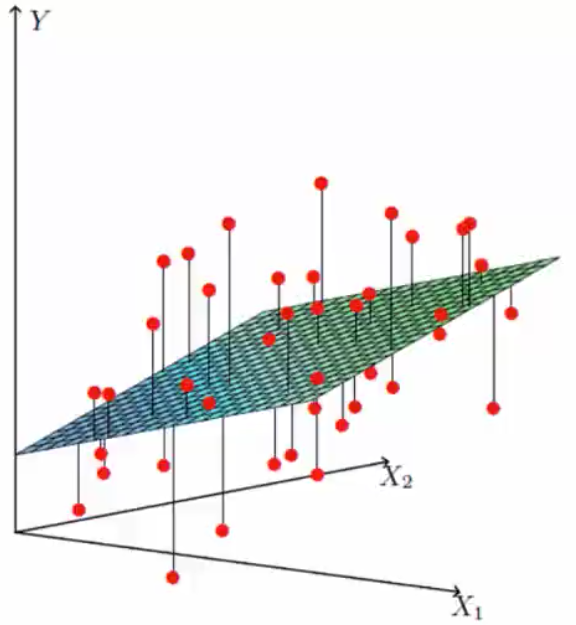
找到最合适的一条线(高维)来拟合我们的数据点 ,即什么样的y = wx+b;
偏置项:上下调整。最终上述公式会生成一个平面,如左坐标轴图。

1.2 误差项分析
真实值和预测值之间肯定要存在差异的,用∑来标识该误差,对于每个样本:
,也就是说,在上一章节中的坐标轴图中,上下浮动的红点就是误差值。
- 误差:误差
是独立并且具有相同的分布,并且服从均值为0方差为
的高斯分布
- 独立:张三和李四一起来贷款,他俩没关系
- 同分布:他俩都来的是我们假定的这家银行
- 高斯分布:银行可能会多给,也可能会少给,但绝大多数情况下,这个浮动不会太大,绩效情况下浮动会比较大,符合正常情况。
左图就是高斯分布,大多数情况都是在-1到1之间浮动。
预测值与误差:
由于误差服从高斯分布:(2)
将(1)式代入(2)式:
1.3 似然函数
什么是似然函数:
似然函数举例: 比如说今天我去赌场赌博,我不知道自己是输赢,可能我的输赢是服从赌场的某一种规则,但是我不知道这个规则是什么样的。那么我就问从赌场出来的人,问了10个人,九个人说赢了,1个人说没赢,那么我就不管赌场规则是怎么分布的,我就直接进赌场,我就认为概率是1/10。我认为我跟他们是一样的,我也能挣钱。这个就是似然函数,说白了,就是根据样板估计参数值,就是参数估计。 似然函数是根据你的样本去估计你的参数值。当我不知道什么样的参数的时候,就根据我的样本去找规则,由数据去推参数是什么。
极大似然估计: 什么样的概率能让结果越大越好。
对数似然:先看在似然函数公式中,进行了累乘,i从1开始一直到m,会整体考虑所有的样本,在数据当中,所有的 \theta 参数要和所有的样本进行代入,\theta 显然要尽可能满足所有的样本。而这个累乘算起来很慢,所以会引入对数似然。log(AB)=log(A)+log(B) 能够把乘法转换为加法,是在似然函数左右都取log。
将对数似然函数进行化简:
展开之后变换成加法,根据logA+logB进行化简,第一步
是一个常数项,对每个样本都要算这个常数项,从1开始一直到m,(
)对这个常数项从1到m算m次,算完之后,得到一个结果
。然后再看后面的
,可以直接给exp(就是e)给省略掉,后面的
可以直接给落下来。后面的
也直接落下来。最后变成
这种形式。而对于之前的似然估计,是越大越好的,即对这组样本的概率越大越好,那么把左面的式子看做A,即把
看做A,把后面那部分看做B,即
看做B。对A来说,是一个恒正的数,而右面的B有一个平方,也是一个恒正数,让一个正数减去一个正数,如何让他越大越好,所以只有让B越小越好,所以让B越小越好。所以不看A(A是常数),而
也是一个常数,所以也不看,最终要看的是:
这一项。用一个变量,
来表示这个式子,这个
作为真实值,将
作为预测值,真实值减去预测值为最小二乘法。
为什么似然函数越大越好,因为是要让预测值成为真实值的可能性,越大越好。现在有了目标函数,那么什么样的能让目标函数
越小越好呢,(注意上述1/2前面有个-号,所以越小越好)


1.4 线性回归求解
有了目标函数之后,对目标函数进行展开:
,如何进行展开的:对
来说,有一个平方项,对矩阵来说可以进行转置,所以转置之后变为:
。再将其进行展开,得到:
,然后再将其展开,得到:
。然后对其求偏导(为什么求偏导,因为偏导=0的状态下,是最小值,类似斜率等于0的情况下,最小值点),求偏导之后可以得到最小值点。即对
偏导等于0,即让等于0,得到最终结果值:
,现在算出来θ的最终结果。现在X是年龄,工资,y是最终银行给予的贷款数,那么θ就可求了。
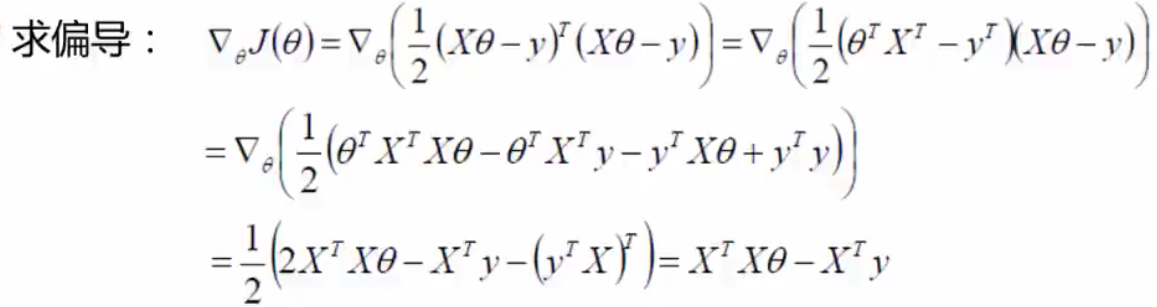
1.5常用评估方法
在机器学习中,用的最多的评估方法是R方项评估。
上述公式中,分子用的是残差平方和,残差平方和是预测值和真实值之间的差异,分母类似方差项,分子预测值和真实值的差异是越小越好,残差平方和越小越好。分子越小约好,那么的值则是越接近于1,那么
约等于1是最好的,
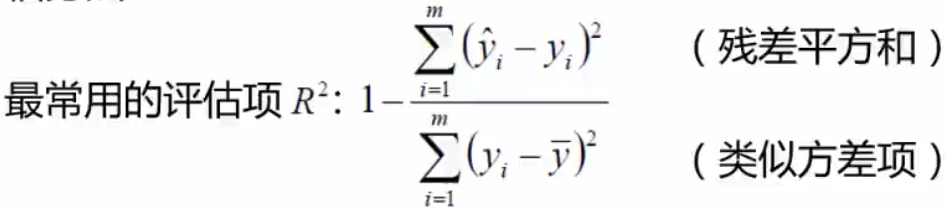
2.逻辑回归
逻辑回归:逻辑回归做的是分类的任务,是一个二分类算法。分类算法中还有知识相机,神经网络等。逻辑回归算法应用比较广泛,在机器学习建模的时候,首选逻辑回归算法。
逻辑回归的决策边界:可以是非线性的
2.1 Sigmoid函数
公式:
自变量取值为任意实数,值域[0,1]。即
取值范围为0到1。函数图像:
在负无穷到正无穷的范围中,
解释:将任意的输入映射到了[0,1]区间,我们在线性回归中可以得到一个预测值,再将该值映射到Sigmoid函数中,这样就完成了由值到概率的转换,也就是分类任务。例如,狼人杀中,晚上被刀,女巫有30%的概率救我,有70%的概率不救我。那么这个概率值相当于一个分类值,也就是这些概率就是一个类别。而Sigmoid函数的值域在0到1之间,就相当于概率。预测函数:
其中:
假设有10个样本(特征),那么就有10个θ参数。而入参:
就是前一章中线性回归的求解,根据求解将值转换为概率。
分类任务:对于这个分类任务,首先做一个基本的假设,假设是一个二分类,类似抛硬币,要么是1,要么是0,只有两种可能性。当抛硬币是正面,也就是1的时候,那么他就是上面式子中的
,而等于0的情况就是上述式子中的
,两个式子进行整合:
解释:对于二分类任务(0 , 1),整合后y取0只保留:。y取1只保留:
