pandas
PANDAS
1. Pandas简介
为什么要学习pandas
numpy已经能够帮助我们处理数据,能够结合matplotlib解决我们分析数据的问题,那么学习pandas的目的在什么地方呢?
numpy 能够帮助我们处理数值型数据,但是还不够,很多时候,饿哦们的数据除了数值以外,还有字符串,还有时间序列等
比如: 我们通过爬虫获取到了存储在数据库中的数据
所以,numpy能够帮助我们处理数值,但是Pandas除了处理数值之外(基于Numpy),还能够帮助我们处理其他类型的数据
- pandas常用数据类型有两种
- Series一维,带标签数组
- Dataframe二维,Series容器
1.1 pandas创建Series
pandas之 Series创建 ,pandas创建一维数组:
In [1]: import pandas as pd
In [2]: pd.Series([1,2,54,28,99])
Out[2]: 0 1 # 左侧是其索引
1 2
2 54
3 28
4 99
dtype: int64
# index指定其索引,可以通过list创建
In [3]: pd.Series([1,2,54,28,99],index=list("abcde"))
Out[3]: a 1
b 2
c 54
d 28
e 99
dtype: int64
In [8]: a = {string.ascii_uppercase[i]:i for i in range(5)}
In [9]: a # 字典式创建 :左右是键值
Out[9]: {'A': 0, 'B': 1, 'C': 2, 'D': 3, 'E': 4}
In [10]: pd.Series(a) #通过字典创建Series,字典键值就是Series键值
Out[10]: A 0
B 1
C 2
D 3
E 4
dtype: int64
In [11]: pd.Series(a,index=list(string.ascii_uppercase[5:15]))
Out[11]: F NaN # 创建大写的A到Z,取5:15封装为list,将此list作为索引
G NaN # 重新制定其他索引,如果能够对应上,就取其值,如果不能,就为nan
H NaN
I NaN
J NaN
K NaN
L NaN
M NaN
N NaN
O NaN
dtype: float64
In [12]: pd.Series(a,index=list(string.ascii_uppercase[0:5]))
Out[12]: A 0 # 重新制定其他索引,如果能够对应上,就取其值,如果不能,就为nan
B 1
C 2
D 3
E 4
dtype: int64
In [13]: pd.Series(a,index=list(string.ascii_uppercase[2:7]))
Out[13]: C 2.0 # 重新制定其他索引,如果能够对应上,就取其值,如果不能,就为nan
D 3.0
E 4.0
F NaN
G NaN
dtype: float64 #这里为什么为float类型,因为Numpy中的nan就是float类型
In [5]: temp_dict = {"name":"xiaohong","age":18,"tel":10086}
In [6]: pd.Series(temp_dict) # 通过字典创建索引
Out[6]: name xiaohong
age 18
tel 10086
dtype: object
In [1]: import pandas as pd
In [2]: import numpy as np
In [3]: import string # index是设置其索引,将其设置为大写的string,取10个,A到J
In [4]: t = pd.Series(np.arange(10), index=list(string.ascii_uppercase[:10]))
In [5]: t # string.ascii_upercase是A到Z的字符串
Out[5]: A 0
B 1
C 2
D 3
E 4
F 5
G 6
H 7
I 8
J 9
dtype: int64
In [6]: type(t)
Out[6]: pandas.core.series.Series
取值
In [13]: t3
Out[13]: name xiaohong
age 18
tel 10086
dtype: object
In [14]: t3["name"]
Out[14]: 'xiaohong'
In [15]: t3[0]
Out[15]: 'xiaohong'
In [19]: t3[:2] #取前两行
Out[19]: name xiaohong
age 18
dtype: object
In [20]: t3[["age","tel"]] #不连续取两行
Out[20]: age 18
tel 10086
dtype: object
In [23]: a = {string.ascii_uppercase[i]:i for i in range(5)}
In [24]: a = pd.Series(a,index=list(string.ascii_uppercase[0:5]))
In [25]: a
Out[25]: A 0
B 1
C 2
D 3
E 4
dtype: int64
In [26]: a[a>3] #取a>3的
Out[26]: E 4
dtype: int64
In [79]: t = pd.Series(np.arange(10),index=list(string.ascii_uppercase[:10]))
In [80]: t
Out[80]: A 0 In [81]: t[2:10:2] # 从2-9每隔两个取一个数
B 1 Out[81]: C 2
C 2 E 4 In [88]: t["F"]
D 3 G 6 Out[88]: 5
E 4 I 8 In [89]: t[["A","F","G"]]
F 5 dtype: int64 Out[89]: A 0
G 6 In [82]: t[1] --取第一个 F 5
H 7 Out[82]: 1 G 6
I 8 dtype: int64 dtype: int64
J 9 In [85]: t[t>4] # 大于4的
dtype: int64 Out[85]: F 5
In [84]: t[[2,3,6]] --不连续取 G 6
Out[84]: C 2 H 7
D 3 I 8
G 6 J 9
dtype: int64 dtype: int64
1.2 pandas索引和值
取索引和值
In [31]: t3.index
Out[31]: Index(['name', 'age', 'tel'], dtype='object')
In [32]: t3.values
Out[32]: array(['xiaohong', 18, 10086], dtype=object)
In [33]: type(t3.index)
Out[33]: pandas.core.indexes.base.Index
In [34]: type(t3.values)
Out[34]: numpy.ndarray
In [35]: list(t3.index) # 转为list
Out[35]: ['name', 'age', 'tel']
In [47]: t.index
Out[47]: Index(['A','B','C','D','E','F','G','H','I','J'],dtype='object')
In [48]: t.values
Out[48]: array([0,1,2,3,4,5,6,7,8,9])
In [49]: type(t.index)
Out[49]: pandas.core.indexes.base.Index
In [53]: type(t.values)
Out[53]: numpy.ndarray
说明:Series对象本质上是由两个数组构成的,一个数组构成对象的键(index,索引),一个数组构成对象的值(values),键—>值
ndarry的很多方法都可以运用series类型,比如argmax,clip
series具有where方法,但是结果和ndarry不同,可以具体查看官方文档 https://https😕/www.pypandas.cn/docs/
2. Pandas读取外部数据
现在假设有一组关于狗名字的统计数据,那么为了观察这组数据的情况,如何做?
数据来源:https://www.kaggle.com/new-york-city/nyc-dog-names
本地文件: ../数据文件/dogNames2.csv
import pandas as pd
df = pd.read_csv("../数据文件/dogNames2.csv")
print(df)
结果集:
Row_Labels Count_AnimalName
0 1 1
1 2 2
2 40804 1
... ...
16218 38948 1
16219 39743 1
读取剪切板数据clipboard()
In [36]: pd.read_clipboard # pd.read还可以读取很多类型数据,clipboard()是读取剪切板数据
read_clipboard() read_fwf() read_json() read_sas()
read_csv() read_gbq() read_orc() read_spss()
read_excel() read_hdf() read_parquet() read_sql()
read_feather() read_html() read_pickle() read_sql_query()
function(sep='\\s+', **kwargs)
读取数据库中的数据
pd.read_sql(sql_sentence.connection)
3. pandas的dataFrame
In [54]: t = pd.DataFrame(np.arange(12).reshape((3,4)))
In [55]: t
Out[55]: 0 1 2 3 # 这一行是列索引
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
DataFrame对象既有行索引,又有列索引
- 行索引,表明不同行,横向索引,叫index,0轴,axis=0
- 列索引,表明不同列,横向索引,叫colums,1轴,axis=1
指定 行 索引 和列 索引
In [61]: ind = list("abc")
In [62]: col = list("wxyz")
In [63]: t = pd.DataFrame(np.arange(12).reshape((3,4)),index=ind,columns=col)
In [64]: t
Out[64]: w x y z
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
引出问题:
- series和dataframe有什么关系: dataframe的列就是series
- Series能够传入字典,那么Dataframe能够传入字典作为数据么
In [67]: d1={"name":["xiaoming","xiaohong"],
"age" :[ 20 , 32 ],
"tel" :[ 10086 , 10010 ]}
In [68]: t1 = pd.DataFrame(d1)
In [69]: t1 # 可以看到,字典的键值变为列索引了
Out[69]: name age tel
0 xiaoming 20 10086
1 xiaohong 32 10010
In [70]: type(t1)
Out[70]: pandas.core.frame.DataFrame
In [72]: d2=[{"name":"xiaohong","age":32,"tel":10086},
{"name":"xiaogang", "tel":10000},
{"name":"xiaowang","age":22 }]
In [73]: d2
Out[73]: [{'name': 'xiaohong', 'age': 32, 'tel': 10086},
{'name': 'xiaogang', 'tel': 10000},
{'name': 'xiaowang', 'age': 22 }]
In [74]: t2 = pd.DataFrame(d2)
In [75]: t2
Out[75]: name age tel
0 xiaohong 32.0 10086.0
1 xiaogang NaN 10000.0 # 没有数值的 值 为 NaN
2 xiaowang 22.0 NaN
4. dataFrame操作(常用方法)
假设现在有一组2006-2016年的1000部最流行的电影数据,我们想知道这些电影数据中 评分的平均分 ,导演的人数等信息,如何获取?
数据来源: https://www.kaggle.com/damianpanek/sunday-eda/data
本地数据: IMDB-Movie-Data.csv
对于这一组的电影数据中,如果我们希望统计电影分类(genre)的情况,应该如何处理数据
思路: 重新够早一个全为0的数组,列名为分类,如果某一条数据中分类出现过,就让0变为1
import pandas as pd
import numpy as np
df = pd.read_csv("../数据文件/IMDB-Movie-Data.csv")
print(df.info())
print(df.head(1))
print("电影平均分:", df["Rating"].mean())
print("导演人数:", len(set(df["Director"].tolist())))
# print(len(df["Director"].unique())) # 和上面一样,不重复提取
# 获取演员的人数
# 此时temp_actors是 [[...]...[...]...]这种类型
temp_actors = df["Actors"].str.split(",").values.tolist()
# 将temp_actors展开
temp_actors = [i for j in temp_actors for i in j] # 展开后是 [....] 类型
print("演员人数:", len(set(temp_actors)))
# 分类情况
# print(df["Genre"].head(3))
# 统计分类的列表,此时temp_list是[[],[],[]]这种类型
temp_list = df["Genre"].str.split(",").tolist()
# 将temp_list列表套列表展开
# temp_list = [i for j in temp_list for i in j]
genre_list = list(set([i for j in temp_list for i in j]))
# 创建全为0 的数组,行数是df的行数,列是所有的分类
zeros_df = pd.DataFrame(np.zeros((df.shape[0], len(genre_list))), columns=genre_list)
# 给每个电影出现分类的位置赋值1,根据行遍历
for i in range(df.shape[0]):
# zeros_df.loc[0, ["Sci-fi","Mucical"]] = 1
zeros_df.loc[i, temp_list[i]] = 1
print(zeros_df)
# 统计每一行的数据和,即列上相加
print(zeros_df.sum(axis=0))
运行结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Rank 1000 non-null int64
1 Title 1000 non-null object
2 Genre 1000 non-null object
3 Description 1000 non-null object
4 Director 1000 non-null object
5 Actors 1000 non-null object
6 Year 1000 non-null int64
7 Runtime (Minutes) 1000 non-null int64
8 Rating 1000 non-null float64
9 Votes 1000 non-null int64
10 Revenue (Millions) 872 non-null float64
11 Metascore 936 non-null float64
dtypes: float64(3), int64(4), object(5)
memory usage: 93.9+ KB
Rank Title ... Revenue (Millions) Metascore
0 1 Guardians of the Galaxy ... 333.13 76.0
[1 rows x 12 columns]
电影平均分: 6.723199999999999
导演人数: 644
演员人数: 2394
Family Crime Music Adventure ... Horror Sport Romance Sci-Fi
0 0.0 0.0 0.0 1.0 ... 0.0 0.0 0.0 1.0
1 0.0 0.0 0.0 1.0 ... 0.0 0.0 0.0 1.0
2 0.0 0.0 0.0 0.0 ... 1.0 0.0 0.0 0.0
.. ... ... ... ... ... ... ... ... ...
998 0.0 0.0 0.0 1.0 ... 0.0 0.0 0.0 0.0
999 1.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
[1000 rows x 20 columns]
Family 51.0
Crime 150.0
Music 16.0
Adventure 259.0
Animation 49.0
...
Horror 119.0
Sport 18.0
Romance 141.0
Sci-Fi 120.0
dtype: float64
In [37]: d = [{"name":"xiaohong","age":32,"tel":10086},
{"name":"dd", "tel":10086},
{"name":"fff", "age":22 }]
In [38]: t3 = pd.DataFrame(d);
In [39]: t3
Out[39]: name age tel
0 xiaohong 32.0 10086.0
1 dd NaN 10086.0
2 fff 22.0 NaN
In [40]: t3.index
Out[40]: RangeIndex(start=0, stop=3, step=1)
In [41]: t3.columns
Out[41]: Index(['name', 'age', 'tel'], dtype='object')
In [42]: t3.values
Out[42]: array([['xiaohong', 32.0, 10086.0],
['dd', nan , 10086.0],
['fff', 22.0, nan]], dtype=object)
In [43]: t3.shape
Out[43]: (3, 3)
In [44]: t3.dtypes
Out[44]: name object
age float64
tel float64
dtype: object
In [45]: t3.ndim #ndim是指维度,当前数组是二维的,所以ndim是2
Out[45]: 2
In [46]: t3.head() # 显示前几行,参数可以传,默认5行
Out[46]: name age tel
0 xiaohong 32.0 10086.0
1 dd NaN 10086.0
2 fff 22.0 NaN
In [47]: t3.tail(1) # 显示最后一行,默认5行
Out[47]: name age tel
2 fff 22.0 NaN
In [51]: t3.info() # 相关信息概览:行数,列数,列索引,列费空值个数,列类型,内存占用
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 3 non-null object
1 age 2 non-null float64
2 tel 2 non-null float64
dtypes: float64(2), object(1)
memory usage: 200.0+ bytes
In [52]: t3.describe() # 快速综合统计结果:计数,均值,标准差,最大值,四分位数,最小值
Out[52]: age tel
count 2.000000 2.0 # 行
mean 27.000000 10086.0 # 均值
std 7.071068 0.0 # 标准差
min 22.000000 10086.0 # 最小值
25% 24.500000 10086.0
50% 27.000000 10086.0 # 中位数
75% 29.500000 10086.0
max 32.000000 10086.0 # 最大值
排序:
import pandas as pd
df = pd.read_csv("./a.csv")
print(df.head())
print(df.info())
# 根据Count_AnimalName排序,ascending=False是降序
print(df.sort_values(by="Count_AnimalName", ascending=False))
# pandas 取行或者列注意几点
# - 方括号写数组,表示取行,对行进行操作
# - 写字符串,表示的取列索引,对列进行操作,一列就是一个Series类型
print(df[:20]) # 取前20行
print(df["Row_Labels"]) # 取Row_Labels列,类型是series
print(type(df["Row_Labels"])) # 结果 <class 'pandas.core.series.Series'>
# 取前10行的Row_Labels这列
var = df[:10]["Row_Labels"]
结果:
Row_Labels Count_AnimalName
0 657 67
1 345 4
2 123 88
3 12314 21
4 567 90
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20 entries, 0 to 19
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Row_Labels 20 non-null object
1 Count_AnimalName 20 non-null int64
dtypes: int64(1), object(1)
memory usage: 448.0+ bytes
None
Row_Labels Count_AnimalName
4 567 90
2 123 88
0 657 67
5 567 22
3 12314 21
9 sdf 10
....# 后面省略
pandas值loc和iloc
- df.loc 通过 标签 索引行数组
- df.iloc通过 位置 获取行数据
In [97]: ind = list("ABC")
In [98]: col = list("WXYZ")
In [99]: t = pd.DataFrame(np.arange(12).reshape((3,4)),index=ind,columns=col)
In [100]: t
Out[100]: W X Y Z In [104]: t.loc[["A","C"],["W","Z"]]
A 0 1 2 3 Out[104]: W Z # 选择间隔的多行多列
B 4 5 6 7 A 0 3
C 8 9 10 11 C 8 11
In [101]: t.loc["B","W"] In [105]: t.loc["A":,["W","Z"]]
Out[101]: 4 --取B行的W Out[105]: W Z # A行及其后面行的W,Z
In [102]: t.loc["A",["W","Z"]] A 0 3
Out[102]: W 0 --取A行的W,Z B 4 7
Z 3 C 8 11
Name: A, dtype: int64
In [103]: type(t.loc["A",["W","Z"]]) #A行W,Z的类型
Out[103]: pandas.core.series.Series
In [109]: t.loc["A":"C",["W","Z"]] #A到C行的W,Z.注意不能是["A":"C"]
Out[109]: W Z
A 0 3
B 4 7
C 8 11
In [110]: t.loc[:,"Y"] --取Y列 In [111]: t.loc[["A","C"],["W","Z"]] #取多行多列
Out[110]: A 2 Out[111]: W Z
B 6 A 0 3
C 10 C 8 11
In [116]: t.iloc[1:3,[2,3]] In [117]: t.iloc[1:3,1:3]
Out[116]: Y Z Out[117]: X Y
B 6 7 B 5 6
C 10 11 C 9 10
In [118]: t.loc["A","Y"] = 100 In [120]: t.iloc[1:2,0:2] = 200
In [119]: t In [121]: t
Out[119]: W X Y Z Out[121]: W X Y Z
A 0 1 100 3 A 0 1 100 3
B 4 5 6 7 B 200 200 6 7
C 8 9 10 11 C 8 9 10 11
pandas值bool索引
回到之前的问题,取Count_AnimalName大于50的数据
df[df["Count_AnimalName"]>50] # 先取Count_AnimalName列,然后再取>800的数据
# 结果:
Row_Labels Count_AnimalName
0 657 67
2 123 88
4 567 90
bool索引可以多个条件
df[(df["Count_AnimalName"]>50) & (df["Count_AnimalName"]<90)] # 大于50小于90
# 结果:
Row_Labels Count_AnimalName
0 657 67
2 123 88
pandas字符串方法
| 方法 | 说明 |
|---|---|
| cat | 实现元素级的字符串链接操作,可指定分隔符 |
| contains | 返回表示哥哥字符串是否含有指定模式的布尔型数组 |
| count | 模式的出现次数 |
| endswith,starswith | 相当于对各个元素执行x.endswith(pattern)或x.startswith(pattern) |
| findall | 计算字符串的模式列表 |
| get | 获取各个元素的第i个字符 |
| join | 根据指定的分隔符将Series中个元素的字符串连接起来 |
| len | 计算各字符串的长度 |
| lower,upper | 转换大小写,相当于对个元素执行x.lower()或x.upper() |
| match | 根据指定的正则表达式对各个元素执行re.match |
| pad | 在字符串的左边,右边或左右两边添加空白符 |
| center | 相当于pad(side='both') |
| repeat | 重复值,例如s.str.repeat(3)相当于对个字符串执行x*3 |
| replace | 用于指定字符串找到的模式 |
| slice | 对Series中各个字符串进行子串街区 |
| split | 根据分隔符或正则表达式对字符串进行拆分 |
| strip,rstrip,lstrip | 去除空白符,包括换行符,相当于对各个元素执行x.strip() ,x.rstring(),x.lstrip() |
4. pandas对于缺失数据的处理
比如说下面这组数据:
U V W X Y Z
A NaN 1.0 2.0 3.0 4.0 NaN
B 6.0 1.0 2.0 3.0 0.0 5.0
C 12.0 1.0 2.0 3.0 4.0 5.0
D 18.0 1.0 NaN 3.0 4.0 5.0
判断数据是否为NaN:
pd.isnull(df)或者pd.notnull(df)
处理方式1: 删除NaN所在行列dropna(axis=0,how='any',inplace=False)
处理方式2: 填充数据,t.fillna(t.mean() 填充均值,t.fialina(t.median()) 填充中位数,t.fillna(0)) 填充0
处理为0的数据:t[t==0]-np.nan将0的数据换为nan,当然并不是每次为0的数据都需要处理,计算平均值等情况,nan是不参与计算的,但是0不会
示例:
In [122]: t3
Out[122]: name age tel
0 xiaohong 32.0 10086.0
1 dd NaN 10086.0
2 fff 22.0 NaN
# 判断是否有Nan
In [123]: pd.isnull(t3)
Out[123]: name age tel
0 False False False
1 False True False
2 False False True
In [124]: pd.notnull(t3)
Out[124]: name age tel
0 True True True
1 True False True
2 True True False
# t3 w这一列部位nan的数据
In [125]: t3[pd.notnull(t3["age"])]
Out[125]: name age tel
0 xiaohong 32.0 10086.0
2 fff 22.0 NaN
# 将有nan的行全部删除 axis = 1是删除列
In [126]: t3.dropna(axis=0)
Out[126]: name age tel
0 xiaohong 32.0 10086.0
#当前行只要有nan就删除,默认how为any
In [127]: t3.dropna(axis=0,how="any")
Out[127]:
name age tel
0 xiaohong 32.0 10086.0
#当前行全部为nan时才删除,默认how为any
In [128]: t3.dropna(axis=0,how="all")
Out[128]:
name age tel
0 xiaohong 32.0 10086.0
1 dd NaN 10086.0
2 fff 22.0 NaN
# 直接改动t3,默认false,相当于t3=t3.dropna(axis=0,how="any")
In [129]: t3.dropna(axis=0,how="any",inplace=True)
In [130]: t3
Out[130]:
name age tel
0 xiaohong 32.0 10086.0
# 填充nan
In [133]: t2
Out[133]:
name age tel
0 xiaohong 32.0 10086.0
1 xiaogang NaN 10000.0
2 xiaowang 22.0 NaN
In [134]: t2.fillna(0) # 将t2中的Nan填充为0
Out[134]:
name age tel
0 xiaohong 32.0 10086.0
1 xiaogang 0.0 10000.0
2 xiaowang 22.0 0.0
# 对t2的其中一列进行填充
In [136]: t2["age"] = t2["age"].fillna(t2["age"].mean())
In [137]: t2
Out[137]:
name age tel
0 xiaohong 32.0 10086.0
1 xiaogang 27.0 10000.0
2 xiaowang 22.0 NaN
5. pandas常用方法统计
df["列"].unique() #转换成list并且没有重复数据
数组合并join的使用
join: 默认情况下他是把行索引相同的数据合并到一起
In [140]: df1=pd.DataFrame(np.ones((2,4)),index=["A","B"],columns=list("abcd"))
In [141]: df2=pd.DataFrame(np.zeros((3,3)),index=list("ABC"),columns=list("xyz"))
In [142]: df1
Out[142]:
a b c d
A 1.0 1.0 1.0 1.0
B 1.0 1.0 1.0 1.0
In [143]: df2
Out[143]:
x y z
A 0.0 0.0 0.0
B 0.0 0.0 0.0
C 0.0 0.0 0.0
In [144]: df1.join(df2)
Out[144]:
a b c d x y z
A 1.0 1.0 1.0 1.0 0.0 0.0 0.0
B 1.0 1.0 1.0 1.0 0.0 0.0 0.0
In [145]: df2.join(df1)
Out[145]:
x y z a b c d
A 0.0 0.0 0.0 1.0 1.0 1.0 1.0
B 0.0 0.0 0.0 1.0 1.0 1.0 1.0
C 0.0 0.0 0.0 NaN NaN NaN NaN
数组合并merge的使用
merge相当于数据库的链接
默认的合并方式是inner
merge left,左链接,NaN补空
merge right,右链接,Nan补空
In [147]: df3
Out[147]:
f a x
0 0.0 0.0 0.0
1 0.0 0.0 0.0
2 0.0 0.0 0.0
In [148]: df1
Out[148]:
a b c d
A 1.0 1.0 1.0 1.0
B 1.0 1.0 1.0 1.0
In [149]: df1.merge(df3,on="a") # 因为df3,a列没有和df1中a一样的,所以不能链接
Out[149]:
Empty DataFrame
Columns: [a, b, c, d, f, x]
Index: []
In [150]: df3.loc[1,"a"]=1
In [151]: df3
Out[151]:
f a x
0 0.0 0.0 0.0
1 0.0 1.0 0.0
2 0.0 0.0 0.0
In [152]: df1.merge(df3,on="a")
Out[152]:
a b c d f x
0 1.0 1.0 1.0 1.0 0.0 0.0
1 1.0 1.0 1.0 1.0 0.0 0.0
In [158]: df1
Out[158]:
a b c d
A 100.0 1.0 1.0 1.0
B 1.0 1.0 1.0 1.0
In [159]: df3
Out[159]:
f a x
0 0 1 2
1 3 4 5
2 6 7 8
In [160]: df1.merge(df3,on="a",how="outer") # 相当于外链接
Out[160]:
a b c d f x
0 100.0 1.0 1.0 1.0 NaN NaN
1 1.0 1.0 1.0 1.0 0.0 2.0
2 4.0 NaN NaN NaN 3.0 5.0
3 7.0 NaN NaN NaN 6.0 8.0
In [161]: df1.merge(df3,on="a",how="left") # 相当于左链接 df1 left join df3
Out[161]:
a b c d f x
0 100.0 1.0 1.0 1.0 NaN NaN
1 1.0 1.0 1.0 1.0 0.0 2.0
In [162]: df1.merge(df3,on="a",how="right")# 相当于左链接 df1 right join df3
Out[162]:
a b c d f x
0 1.0 1.0 1.0 1.0 0 2
1 4.0 NaN NaN NaN 3 5
2 7.0 NaN NaN NaN 6 8
In [171]: t1
Out[171]:
M N O P
A 1.0 1.0 a 1.0
B 1.0 1.0 b 1.0
C 1.0 1.0 c 1.0
In [172]: t2
Out[172]:
V W X Y Z
A 0.0 0.0 c 0.0 0.0
B 0.0 0.0 d 0.0 0.0
In [173]: t1.merge(t2,left_on="O",right_on="X") #t1中的O和t2中的X,进行合并,不指定
Out[173]: # how默认inner
M N O P V W X Y Z
0 1.0 1.0 c 1.0 0.0 0.0 c 0.0 0.0
In [174]: t1.merge(t2,left_on="O",right_on="X",how="inner")# t1中的O和t2中的X
Out[174]: #进行合并,内链接
M N O P V W X Y Z
0 1.0 1.0 c 1.0 0.0 0.0 c 0.0 0.0
In [175]: t1.merge(t2,left_on="O",right_on="X",how="outer") # t1中的O和t2中的X
Out[175]: #进行合并,外链接
M N O P V W X Y Z
0 1.0 1.0 a 1.0 NaN NaN NaN NaN NaN
1 1.0 1.0 b 1.0 NaN NaN NaN NaN NaN
2 1.0 1.0 c 1.0 0.0 0.0 c 0.0 0.0
3 NaN NaN NaN NaN 0.0 0.0 d 0.0 0.0
In [176]: t1.merge(t2,left_on="O",right_on="X",how="left") # t1中的O和t2中的X
Out[176]: #进行合并,左连接
M N O P V W X Y Z
0 1.0 1.0 a 1.0 NaN NaN NaN NaN NaN
1 1.0 1.0 b 1.0 NaN NaN NaN NaN NaN
2 1.0 1.0 c 1.0 0.0 0.0 c 0.0 0.0
In [177]: t1.merge(t2,left_on="O",right_on="X",how="right") # t1中的O和t2中的X
Out[177]: #进行合并,右连接
M N O P V W X Y Z
0 1.0 1.0 c 1.0 0.0 0.0 c 0.0 0.0
1 NaN NaN NaN NaN 0.0 0.0 d 0.0 0.0
数组分组聚合的使用
案例: 现在我们有一组关于全球星巴克店铺的统计数据,如果我想知道 美国的星巴克数量和中国的星巴克数量 哪个多,或者我想知道 中国每个省份星巴克的数量的情况 如何处理
思路:遍历一遍,每次加1
数据来源: https://www.kaggle.com/starbucks/store-locations/data
本地数组: directory.csv
import pandas as pd
file_path = "../数据文件/directory.csv"
df = pd.read_csv(file_path)
print(df.head(1))
print(df.info())
# pandas中分组使用groupby df.groupby(by="columns_name")
country_grouped = df.groupby(by="Country")
# country_grouped是一个DataFrameGroupBy对象
province = ""
# 可以对country_grouped进行遍历
for i, j in country_grouped:
# i 是分组类型,这里是各个国家,j是对应的数据,每一个j都是DataFrame对象
if i == "CN":
print("j====================")
print(j) # 这里就是拿到中国的数据
# 注意,这里等同于: df[df["Country"] == "CN"]
print("df[df[\"Country\"] == \"CN\"]=======")
print(df[df["Country"] == "CN"])
province = j.groupby(by="State/Province")
# 聚合方法
print("聚合方法,统计每个国家对应的数目=========")
print(country_grouped.count())#每个国家的Brand有多少,StoreNumber有多少,每一列都统计了
print("聚合统计,取Brand列数据===========")
country_count = country_grouped["Brand"].count()
print(country_count) # 也可以统计中位数,平均值等
# 取中国的数据和
print("中国星巴克数量:", country_count["CN"])
# 取美国的数据和
print("美国星巴克数量:", country_count["US"])
# 统计中国每个省份星巴克数量
country_grouped = province["Brand"].count()
print("统计中国每个省份星巴克数量=====")
print(country_grouped)
运行结果:
Brand Store Number ... Longitude Latitude
0 Starbucks 47370-257954 ... 1.53 42.51
[1 rows x 13 columns]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 25600 entries, 0 to 25599
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Brand 25600 non-null object
1 Store Number 25600 non-null object
2 Store Name 25600 non-null object
3 Ownership Type 25600 non-null object
4 Street Address 25598 non-null object
5 City 25585 non-null object
6 State/Province 25600 non-null object
7 Country 25600 non-null object
8 Postcode 24078 non-null object
9 Phone Number 18739 non-null object
10 Timezone 25600 non-null object
11 Longitude 25599 non-null float64
12 Latitude 25599 non-null float64
dtypes: float64(2), object(11)
memory usage: 2.5+ MB
None
j====================
Brand Store Number ... Longitude Latitude
2091 Starbucks 22901-225145 ... 116.32 39.90
2092 Starbucks 32320-116537 ... 116.32 39.97
... ... ... ... ...
4823 Starbucks 22210-218665 ... 113.56 22.15
4824 Starbucks 17108-179449 ... 113.55 22.19
[2734 rows x 13 columns]
df[df["Country"] == "CN"]=======
Brand Store Number ... Longitude Latitude
2091 Starbucks 22901-225145 ... 116.32 39.90
2092 Starbucks 32320-116537 ... 116.32 39.97
... ... ... ... ...
4823 Starbucks 22210-218665 ... 113.56 22.15
4824 Starbucks 17108-179449 ... 113.55 22.19
[2734 rows x 13 columns]
聚合方法,统计每个国家对应的数目=========
Brand Store Number Store Name ... Timezone Longitude Latitude
Country ...
AD 1 1 1 ... 1 1 1
AE 144 144 144 ... 144 144 144
... ... ... ... ... ... ...
VN 25 25 25 ... 25 25 25
ZA 3 3 3 ... 3 3 3
[73 rows x 12 columns]
聚合统计,取Brand列数据===========
Country
AD 1
AE 144
AR 108
AT 18
AU 22
...
Name: Brand, Length: 73, dtype: int64
中国星巴克数量: 2734
美国星巴克数量: 13608
统计中国每个省份星巴克数量=====
State/Province
11 236
12 58
13 24
14 8
15 8
...
Name: Brand, dtype: int64
说明:
grouped = df.groupby(by="columns_name")
grouped是一个DataFrameGroupBy对象,是可迭代的
grouped中的每一个元素是一个元组
元组里面是(索引(分组的值),分组之后的Dataframe)
DataFrameGroupBy对象有很多经过优化的方法:
| 函数名 | 说明 |
|---|---|
| count | 分组中非Nan值得数量 |
| sum | 非Na值得和 |
| mean | 非Na值得平均值 |
| median | 非Na值算数中位数 |
| std,var | 无偏(分母为n-1)标准差和方差 |
| min,max | 非Na值得最小值和最大值 |
在上述的groupby中里面的by写的是列名,但是除了可以写列名之外,也可以写列表,比如说按照两个字段进行分组,就可以把两个列放进去,当然也可以把df["Country"],df["State/Province"]写进去,例如:
df["Country"].groupby(by=[df["Country"],df["State/Province"]]).count()
数据按照多个条件进行分组:
import pandas as pd
file_path = "../数据文件/directory.csv"
df = pd.read_csv(file_path)
brand_ = df["Brand"] # 这样取的是series
brand_data = df[["Brand"]] # 这样取的是dataframe
print(brand_)
# print(type(brand_)) # 这是一个Series类型,不能进行分组<class 'pandas.core.series.Series'>
# print(type(brand_data)) # 这是一个Dataframe类型
# brand_.groupby(by=["Country", "State/Province"]) Series类型,不能进行分组
brand__groupby = brand_.groupby(by=[df["Country"], df["State/Province"]])
brand__groupby_data = brand_data.groupby(by=[df["Country"], df["State/Province"]])
# print(brand__groupby) # <pandas.core.groupby.generic.SeriesGroupBy object at 0x7f8e871d9d90>
# print(brand__groupby_data) # DataFrameGroupBy 类型
# print(type(brand__groupby.count())) #Series类型
# print(type(brand__groupby_data.count())) # DataFrame类型
# brand_groupby.count() 是一个Series类型
print(brand__groupby.count())
# brand_groupby.count() 是一个DataFrame类型
print(brand__groupby_data.count())
上述两个最终显示类型相同,运行结果:
0 Starbucks
1 Starbucks
2 Starbucks
3 Starbucks
4 Starbucks
...
Name: Brand, Length: 25600, dtype: object
Country State/Province
AD 7 1
AE AJ 2
AZ 48
DU 82
FU 2
...
Name: Brand, Length: 545, dtype: int64
import sys; print('Python %s on %s' % (sys.version, sys.platform))
Brand
Country State/Province
AD 7 1
AE AJ 2
AZ 48
DU 82
FU 2
... ...
[545 rows x 1 columns]
但是上述的Series类型有两个索引,一个Country和State/Provice两个索引,是符合索引
获取分组之后的某一部分数据:
df.groupby(by=["Country","State/Province"])["Country"].count()
对几列数据进行分组:
df["Country"].groupby(by=[df["Country"],df["State/Province"]]).count()
6. pandas复合索引
前一章节中的 Series中有两个索引,这个就是复合索引
import pandas as pd
file_path = "../数据文件/directory.csv"
df = pd.read_csv(file_path)
brand_ = df["Brand"] # 这样取的是series
brand__groupby = brand_.groupby(by=[df["Country"], df["State/Province"]])
count = brand__groupby.count()
print(count)
print("*"*100)
print(count.index)
运行结果:
Country State/Province
AD 7 1
AE AJ 2
AZ 48
DU 82
FU 2
..
Name: Brand, Length: 545, dtype: int64
*****************************************************************
MultiIndex([('AD', '7'), # 这个MultiIndex就是复合索引
('AE', 'AJ'),
('AE', 'AZ'),
('AE', 'DU'),
('AE', 'FU'),
('AE', 'RK'),
('AE', 'SH'),
('AE', 'UQ'),
('AR', 'B'),
('AR', 'C'),
...
('ZA', 'GT')],
names=['Country', 'State/Province'], length=545)
索引操作:
获取index: df.index
指定index: df.index = ['x','y']
重新设置index: df.reindex(list("abcdef"))
指定某一列作为index: df.set_index("Country",drop=False)
返回index的唯一值: df.set_index("Country").index.unique()
In [5]: df1
Out[5]:
a b c d
A 100.0 1.0 1.0 1.0
B 1.0 1.0 1.0 1.0
In [6]: df1.index
Out[6]: Index(['A', 'B'], dtype='object')
In [7]: df1.index = ["a","b"] # 索引更改赋值
In [8]: df1
Out[8]:
a b c d
a 100.0 1.0 1.0 1.0
b 1.0 1.0 1.0 1.0
In [10]: df1
Out[10]:
a b c d
a 100.0 1.0 1.0 1.0
b 1.0 1.0 1.0 1.0
In [11]: df1.reindex(["a","f"]) # 取了a这行,f这行
Out[11]: #重新赋值,因为原来f没有,所以直接赋值Nan
a b c d
a 100.0 1.0 1.0 1.0
f NaN NaN NaN NaN
In [12]: df1.set_index("a") # 把 a 作为索引
Out[12]:
b c d
a
100.0 1.0 1.0 1.0
1.0 1.0 1.0 1.0
In [13]: df1.set_index("a").index
Out[13]: Float64Index([100.0, 1.0], dtype='float64', name='a')
In [14]: df1.set_index("a",drop=False) # a作为索引,同时在表里保留a
Out[14]:
a b c d
a
100.0 100.0 1.0 1.0 1.0
1.0 1.0 1.0 1.0 1.0
In [15]: df1.set_index("a").index.unique() # 不重复取索引的值
Out[15]: Float64Index([100.0, 1.0], dtype='float64', name='a')
In [18]: a
Out[18]:
a b c d
0 0 7 one h
1 1 6 one j
2 2 5 one k
3 3 4 two l
4 4 3 two m
5 5 2 two n
6 6 1 two o
In [19]: b=a.set_index(["c","d"]) # 把cd列作为索引
In [20]: b
Out[20]:
a b
c d
one h 0 7
j 1 6
k 2 5
two l 3 4
m 4 3
n 5 2
o 6 1
In [21]: c=b["a"] # 取a这一列
In [22]: c
Out[22]:
c d
one h 0
j 1
k 2
two l 3
m 4
n 5
o 6
Name: a, dtype: int64
In [23]: type(c)
Out[23]: pandas.core.series.Series
In [24]: c["one"]["j"]
Out[24]: 1
In [25]: c["one"]
Out[25]:
d
h 0
j 1
k 2
Name: a, dtype: int64
In [26]: d=a.set_index(["d","c"])["a"]
In [27]: d
Out[27]:
d c
h one 0
j one 1
k one 2
l two 3
m two 4
n two 5
o two 6
Name: a, dtype: int64
In [28]: d.index
Out[28]:
MultiIndex([('h', 'one'),
('j', 'one'),
('k', 'one'),
('l', 'two'),
('m', 'two'),
('n', 'two'),
('o', 'two')],
names=['d', 'c'])
In [29]: d.swaplevel()["one"] # 取索引one
Out[29]: # swaplevel相当于复合索引的里外层进行交换,交换完毕之后再取["one"]
d
h 0
j 1
k 2
Name: a, dtype: int64
In [31]: b.loc["one"].loc["h"]
Out[31]:
a 0
b 7
Name: h, dtype: int64
In [32]: b.swaplevel().loc["h"]
Out[32]: # swaplevel相当于复合索引的里外层进行交换,交换完毕之后再取["h"]
a b
c
one 0 7
7. pandas练习
练习:
- 使用matplotlib呈现出店铺总数排名前10的国家
import pandas as pd
from matplotlib import pyplot as plt
file_path = "../数据文件/directory.csv"
df = pd.read_csv(file_path)
# 使用matplotlib呈现出店铺总数排名前10的国家
values = df.groupby(by="Country")["Brand"].count().
sort_values(ascending=False)[:10]
print(values)
# 画图
data1 = values
_x = data1.index
_y = data1.values
plt.figure(figsize=(20, 8), dpi=80)
plt.bar(range(len(_x)), _y)
plt.xticks(range(len(_x)), _x)
plt.show()
运行结果:
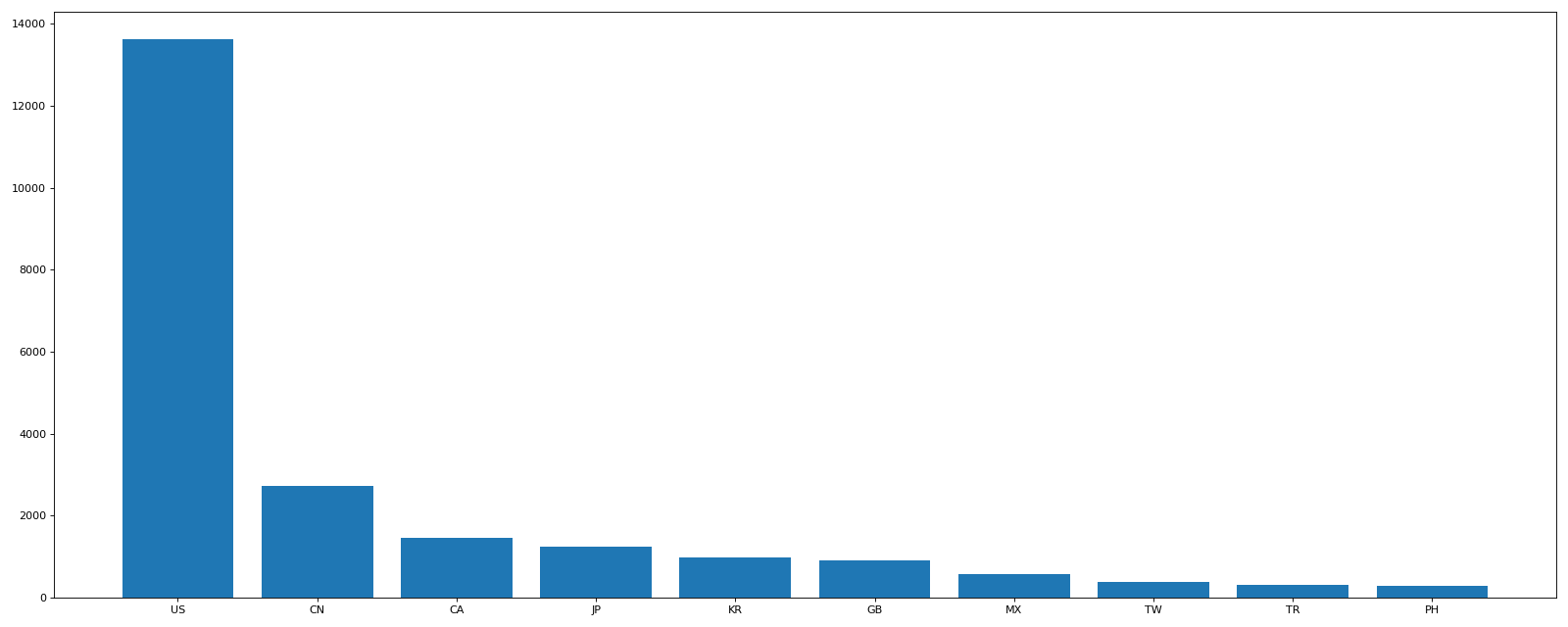
Country
US 13608
CN 2734
CA 1468
JP 1237
KR 993
GB 901
MX 579
TW 394
TR 326
PH 298
Name: Brand, dtype: int64
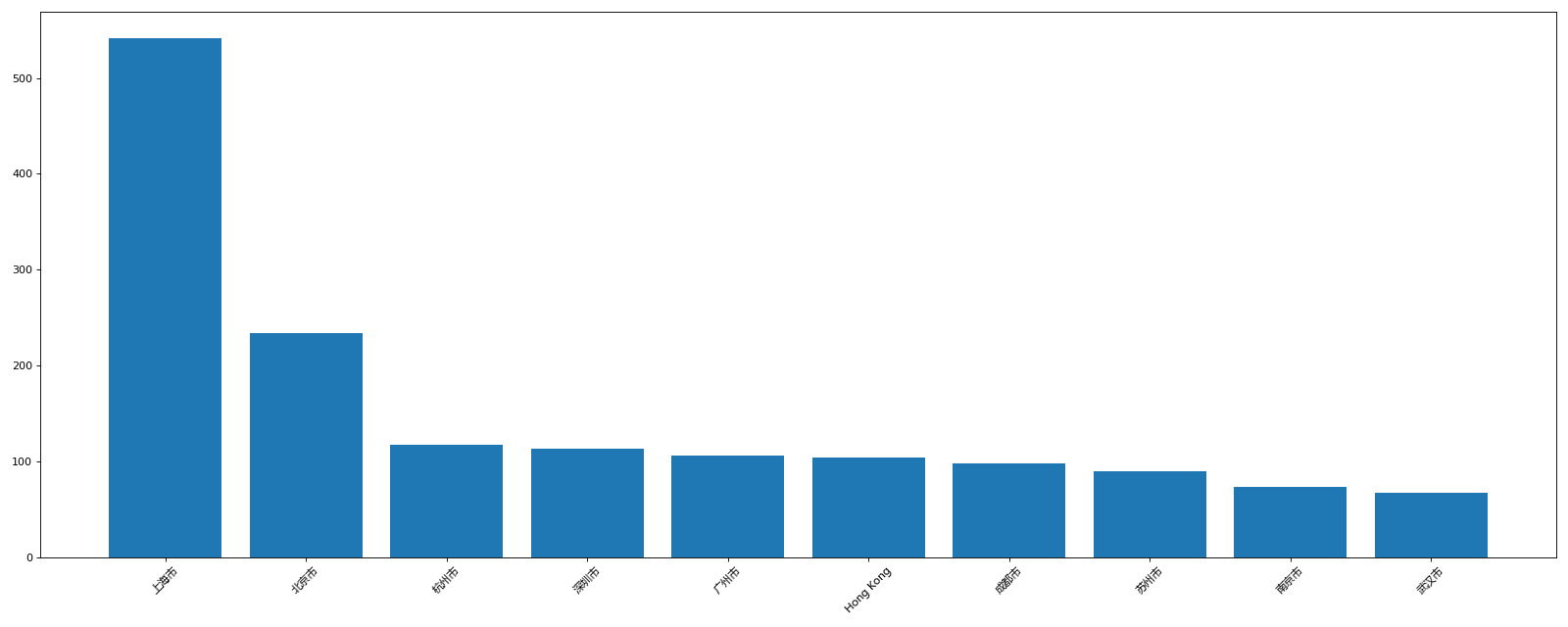
- 使用matplotlib呈现出中国前10城市的店铺数量
import pandas as pd
from matplotlib import pyplot as plt, font_manager
file_path = "../数据文件/directory.csv"
df = pd.read_csv(file_path)
df = df[df["Country"]=="CN"]
my_font = font_manager.FontProperties(fname="/home/zhiwei/.deepinwine/Deepin-QQ/drive_c/windows/Fonts/msyh.ttc")
# 使用matplotlib呈现出中国店铺总数排名前10的城市
# 准备数据
values = df.groupby(by="City")["Brand"].count().
sort_values(ascending=False)[:10]
frame = values.to_frame()
print(type(frame))
frame.to_excel('data2.xlsx','Sheet1')
# 画图
data1 = values
_x = data1.index
_y = data1.values
plt.figure(figsize=(20, 8), dpi=80)
plt.bar(range(len(_x)), _y)
plt.xticks(range(len(_x)), _x,rotation=45, fontproperties=my_font)
plt.show()
运行结果:
City
上海市 542
北京市 234
杭州市 117
深圳市 113
广州市 106
Hong Kong 104
成都市 98
苏州市 90
南京市 73
武汉市 67
Name: Brand, dtype: int64
案例:
现在有全球排名靠前的1万本书的数据,那么清统计一下下面几个问题:
- 不同年份书的数量
- 不同年份书的平均评分情况
收集数据来源: https://www.kaggle.com/zygmunt/goodbooks-10k
import pandas as pd
from matplotlib import pyplot as plt, font_manager
df = pd.read_csv("../数据文件/books.csv")
my_font = font_manager.FontProperties(fname="/home/zhiwei/.deepinwine/Deepin-QQ/drive_c/windows/Fonts/msyh.ttc")
plt.figure(figsize=(20, 8), dpi=80)
print(df.head(2))
print(df.info())
# 到此可以看到年份original_publication_year这里栏有雀氏数据一共9979行
# 因此要删除缺失数据,通过做nan,删除original_publication_year中nan的行
data1 = df[pd.notnull(df["original_publication_year"])]
count = data1.groupby(by="original_publication_year")["title"].count()
print("统计年份总量------------")
print(count)
print("不同年份书的平均评分情况")
data2 = df[pd.notnull(df["original_publication_year"])]
groupby = data2["average_rating"].groupby(by=data2["original_publication_year"]).mean()
print(groupby)
_x = groupby.index
_y = groupby.values
plt.plot(range(len(_x)),_y)
plt.xticks(list(range(len(_x)))[::10],_x[::10].astype(int),rotation=45)
plt.show()
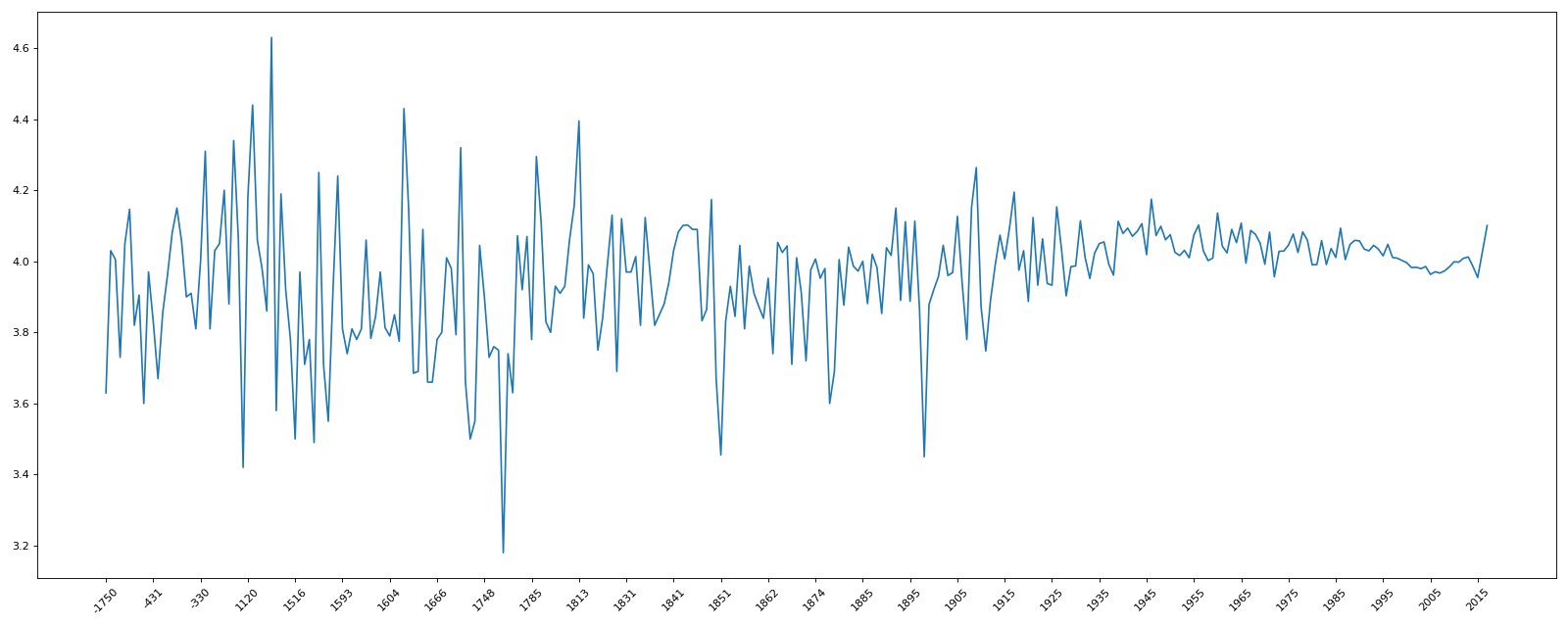
运行结果:
id ... small_image_url
0 1 ... https://images.gr-assets.com/books/1447303603s...
1 2 ... https://images.gr-assets.com/books/1474154022s...
[2 rows x 23 columns]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10000 entries, 0 to 9999
Data columns (total 23 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 10000 non-null int64
1 book_id 10000 non-null int64
...
20 ratings_5 10000 non-null int64
21 image_url 10000 non-null object
22 small_image_url 10000 non-null object
dtypes: float64(3), int64(13), object(7)
memory usage: 1.8+ MB
None
统计年份总量------------
original_publication_year
-1750.0 1
-762.0 1
...
2016.0 198
2017.0 11
Name: title, Length: 293, dtype: int64
不同年份书的平均评分情况
original_publication_year
-1750.0 3.630000
-762.0 4.030000
-560.0 4.050000
...
2013.0 4.012297
2017.0 4.100909
Name: average_rating, Length: 293, dtype: float64
8. pandas时间序列
动手案例: 现在我们有2015到2017年25万条911的紧急电话的数据,请统计出这些数据中 不同类型的紧急情况的次数,如果我们还想统计出 不同月份紧急电话的次数的变化情况 ,还想统计 不同月份不同类型电话次数情况,如何做?
数据来源: https://www.kaggle.com/mchirico/montcoalert/data
本地数据: 911.csv
不同类型的紧急情况的次数
import pandas as pd
from matplotlib import pyplot as plt, font_manager
import numpy as np
df = pd.read_csv("../数据文件/911.csv")
my_font = font_manager.FontProperties(
fname="/home/zhiwei/.deepinwine/Deepin-QQ/drive_c/windows/Fonts/msyh.ttc")
plt.figure(figsize=(20, 8), dpi=80)
print(df.head())
#数据中lan,lng是当前经纬度,twp列是位置,title是情况分类EMS紧急情况,fire火灾
print(df.info())
# title中的前缀是分类
# 获取分类
# 这里是个series转list,格式是[[分类,名称]...[]]
temp_list = df["title"].str.split(": ").tolist()
# 只要取每一个小[]第0各数据,即分类
cate_list = list(set([i[0] for i in temp_list]))
print("分类::::")
print(cate_list)
# 统计分类,先构造全为0的数组,行是数据所有行,列是分类
zero_df = pd.DataFrame(np.zeros((df.shape[0], len(cate_list))), columns=cate_list)
# 赋值
for cate in cate_list:
zero_df[cate][df["title"].str.contains(cate)] = 1
print(zero_df)
# 也可以这样赋值,但是很慢,不如上述pandas操作
# for i in range(df.shape[0]):
# zero_df.loc[i, temp_list[i][0]] = 1
sum_ret = zero_df.sum(axis=0)
print("统计结果:::")
print(sum_ret)
运行结果:
lat lng ... addr e
0 40.297876 -75.581294 ... REINDEER CT & DEAD END 1
1 40.258061 -75.264680 ... BRIAR PATH & WHITEMARSH LN 1
2 40.121182 -75.351975 ... HAWS AVE 1
3 40.116153 -75.343513 ... AIRY ST & SWEDE ST 1
4 40.251492 -75.603350 ... CHERRYWOOD CT & DEAD END 1
[5 rows x 9 columns]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 663522 entries, 0 to 663521
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 lat 663522 non-null float64
1 lng 663522 non-null float64
...
6 twp 663229 non-null object
7 addr 663522 non-null object
8 e 663522 non-null int64
dtypes: float64(3), int64(1), object(5)
memory usage: 45.6+ MB
None
分类::::
['EMS', 'Traffic', 'Fire']
EMS Traffic Fire
0 1.0 0.0 0.0
1 1.0 0.0 0.0
... ... ...
663520 0.0 0.0 1.0
663521 0.0 1.0 0.0
[663522 rows x 3 columns]
统计结果:::
EMS 332700.0
Traffic 230208.0
Fire 100622.0
dtype: float64
不同月份电话次数变化情况
注意,月份这个在df中["timeStamp"]这个字段,表现形式是"2020-07-29 15:46:51",需要使用时间序列进行截取
df["timeStamp"]=pd.to_datetime(df["timeStamp"],format="格式化")
import pandas as pd
from matplotlib import pyplot as plt, font_manager
import numpy as np
"""
动手案例: 现在我们有2015到2017年25万条911的紧急电话的数据,请统计出这些数据中统计出 **不同月份紧急电话的次数的变化情况** ,如何做?
"""
df = pd.read_csv("../数据文件/911.csv")
my_font = font_manager.FontProperties(
fname="/home/zhiwei/.deepinwine/Deepin-QQ/drive_c/windows/Fonts/msyh.ttc")
plt.figure(figsize=(20, 8), dpi=80)
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
df.set_index("timeStamp", inplace=True)
print(df.head(5))
print("不同月份紧急电话的次数的变化情况====")
count_by_month = df.resample("M")["title"].count()
print(count_by_month)
# 画折线图
_x = count_by_month.index
_x = [i.strftime("%Y%m%d") for i in _x]
# 下面效果和上面一样
# list_x = []
# for i in _x:
# list_x.append(i.strftime("%Y%m%d"))
# _x = list_x
_y = count_by_month.values
plt.plot(range(len(_x)), _y)
plt.xticks(range(len(_x)),_x,rotation=45)
plt.show()
运行结果:
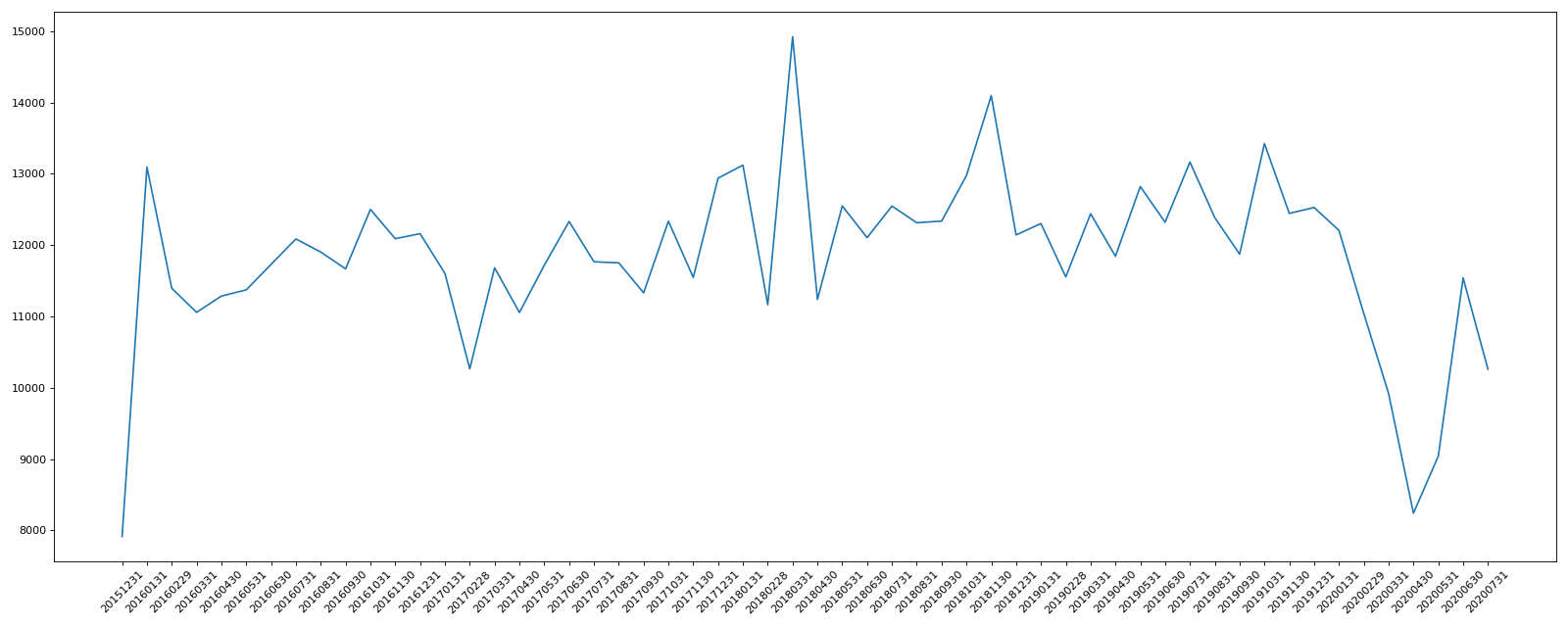
lat lng ... addr e
timeStamp ...
2015-12-10 17:10:52 40.297876 -75.581294 ... REINDEER CT & DEAD END 1
2015-12-10 17:29:21 40.258061 -75.264680 ... BRIAR PATH & WHITEMARSH LN 1
2015-12-10 14:39:21 40.121182 -75.351975 ... HAWS AVE 1
2015-12-10 16:47:36 40.116153 -75.343513 ... AIRY ST & SWEDE ST 1
2015-12-10 16:56:52 40.251492 -75.603350 ... CHERRYWOOD CT & DEAD END 1
[5 rows x 8 columns]
不同月份紧急电话的次数的变化情况====
timeStamp
2015-12-31 7916
2016-01-31 13096
2016-02-29 11396
...
不同月份不同类型紧急电话的次数的变化情况
import pandas as pd
from matplotlib import pyplot as plt, font_manager
import numpy as np
"""
动手案例: 现在我们有2015到2017年25万条911的紧急电话的数据,请统计出这些数据中统计出 **不同月份不同类型紧急电话的次数的变化情况** ,如何做?
"""
df = pd.read_csv("../数据文件/911.csv")
my_font = font_manager.FontProperties(
fname="/home/zhiwei/.deepinwine/Deepin-QQ/drive_c/windows/Fonts/msyh.ttc")
plt.figure(figsize=(20, 8), dpi=80)
# 把时间字符串转为时间类型设置为索引
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
# 添加列表示分类,在df上面加一个cate列
temp_list = df["title"].str.split(": ").tolist()
cate_list = [i[0] for i in temp_list]
df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0], 1)))
df.set_index("timeStamp", inplace=True)
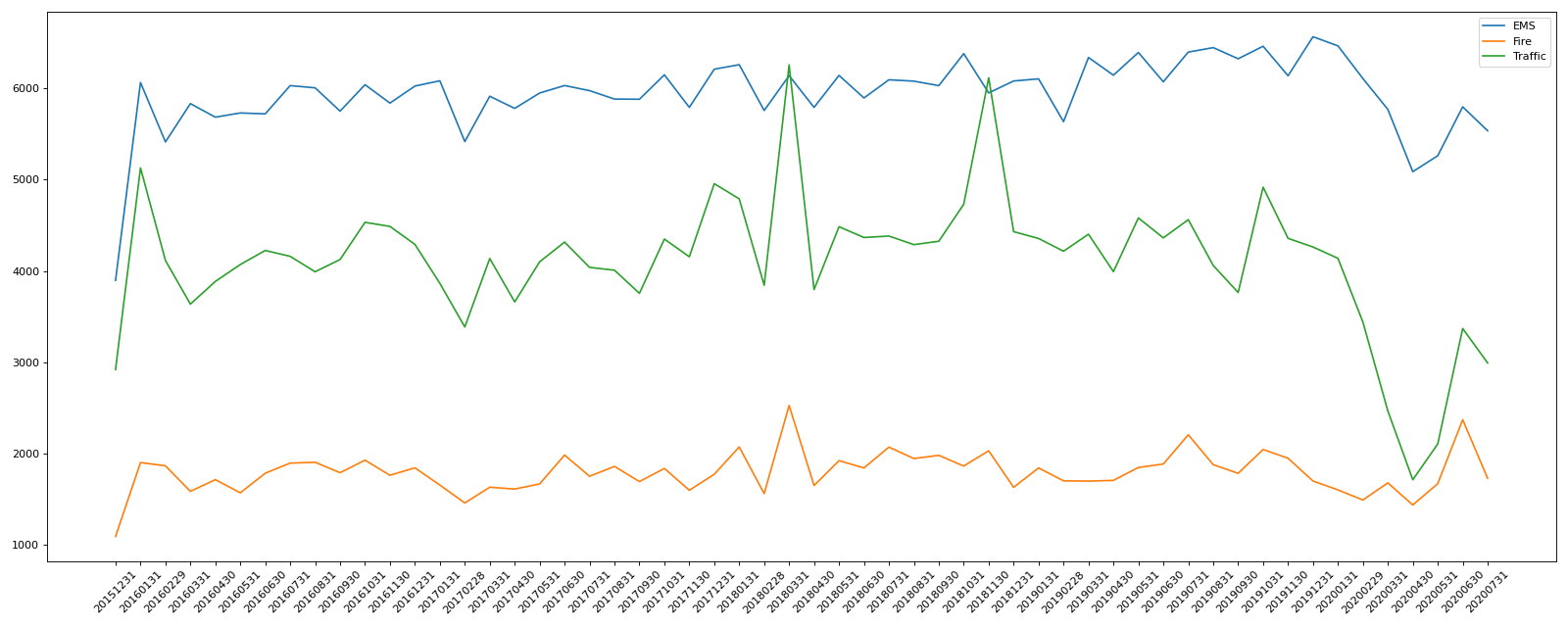
# 进行分组
cate_group = df.groupby(by="cate")
for group_name, group_data in cate_group:
count_by_month = group_data.resample("M")["title"].count()
# 画折线图
_x = count_by_month.index
_x = [i.strftime("%Y%m%d") for i in _x]
_y = count_by_month.values
plt.plot(range(len(_x)), _y, label=group_name)
plt.xticks(range(len(_x)), _x, rotation=45)
plt.legend(loc="best")
plt.show()
运行结果:
9. pandas时间序列-案例
pd.date_range(start=None,end=None,periods=None,freq='D')
start和end以及freq配合能够生成start和end范围内以频率freq的一组时间索引
start和periods以及freq配合能够生成从start开启的频率为freq的periods个时间索引
periods就是取多少个
freq的取值:
| 别名 | 偏移量类型 | 说明 |
|---|---|---|
| D | Day | 每日历日 |
| B | BusinessDay | 每工作日 |
| H | Hour | 每工作日 |
| T或min | Minute | 每分 |
| S | Second | 每秒 |
| L或ms | Milli | 每毫秒(即千分之一秒) |
| U | Micro | 每微秒(即每百万分之一秒) |
| M | MonthEnd | 每月最后一个日历日 |
| BM | BusinessMonthEnd | 每月最后一个工作日 |
| MS | MonthBegin | 每月第一个日历日 |
| BMS | BusinessMonthBegin | 每月第一个工作日 |
案例:
In [3]: pd.date_range(start="20200101",end="20201117")
Out[3]:
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04',
'2020-01-05', '2020-01-06', '2020-01-07', '2020-01-08',
'2020-01-09', '2020-01-10',
...
'2020-11-08', '2020-11-09', '2020-11-10', '2020-11-11',
'2020-11-12', '2020-11-13', '2020-11-14', '2020-11-15',
'2020-11-16', '2020-11-17'],
dtype='datetime64[ns]', length=322, freq='D')
In [4]: pd.date_range(start="20200101",end="20201117",freq="BM")
Out[4]:
DatetimeIndex(['2020-01-31', '2020-02-28', '2020-03-31', '2020-04-30',
'2020-05-29', '2020-06-30', '2020-07-31', '2020-08-31',
'2020-09-30', '2020-10-30'],
dtype='datetime64[ns]', freq='BM')
In [5]: pd.date_range(start="20200101",periods=10,freq="WOM-3FRI")
Out[5]:
DatetimeIndex(['2020-01-17', '2020-02-21', '2020-03-20', '2020-04-17',
'2020-05-15', '2020-06-19', '2020-07-17', '2020-08-21',
'2020-09-18', '2020-10-16'],
dtype='datetime64[ns]', freq='WOM-3FRI')
In [6]: pd.date_range(start="20200101",end="20201117",freq="10D") # 每隔十天取一次
Out[6]:
DatetimeIndex(['2020-01-01', '2020-01-11', '2020-01-21', '2020-01-31',
'2020-02-10', '2020-02-20', '2020-03-01', '2020-03-11',
'2020-03-21', '2020-03-31', '2020-04-10', '2020-04-20',
'2020-04-30', '2020-05-10', '2020-05-20', '2020-05-30',
'2020-06-09', '2020-06-19', '2020-06-29', '2020-07-09',
'2020-07-19', '2020-07-29', '2020-08-08', '2020-08-18',
'2020-08-28', '2020-09-07', '2020-09-17', '2020-09-27',
'2020-10-07', '2020-10-17', '2020-10-27', '2020-11-06',
'2020-11-16'],
dtype='datetime64[ns]', freq='10D')
#10D每隔10天取一个,取10个
In [10]: pd.date_range(start="20200101",periods=10,freq="10D")
Out[10]:
DatetimeIndex(['2020-01-01', '2020-01-11', '2020-01-21', '2020-01-31',
'2020-02-10', '2020-02-20', '2020-03-01', '2020-03-11',
'2020-03-21', '2020-03-31'],
dtype='datetime64[ns]', freq='10D')
In [14]: index = pd.date_range(start="20200101",periods=10) #生成时间序列为索引的df
In [15]: df=pd.DataFrame(np.random.rand(10),index=index) #生成时间序列为索引的df
In [16]: df
Out[16]:
0
2020-01-01 0.793690
2020-01-02 0.084362
2020-01-03 0.257524
2020-01-04 0.073121
2020-01-05 0.060269
2020-01-06 0.189405
2020-01-07 0.872039
2020-01-08 0.924744
2020-01-09 0.544311
2020-01-10 0.272481
在上面的911案例中,取不同月份的时候,我们可以使用pandas提供的方法吧时间字符串转化为时间序列
df["timeStamp"]=pd.to_datetime(df["timeStamp"],format="")
pandas重采样
概念: 重采样指的是将时间序列从 一个频率转化为另一个频率进行处理的过程 ,将高频率数据转化为低频率数据为 降采样,低频率转化为高频率为 升采样
使用resample方法实现频率转化
比如说从2015-12-10 17:10:52 将秒转化到天,这叫低采样
In [17]: t=pd.DataFrame(np.random.uniform(10,50,(100,1)),index=pd.date_range("20200101",periods=100))
In [18]: t
Out[18]:
0
2020-01-01 45.596503
2020-01-02 14.231531
2020-01-03 29.238553
2020-01-04 17.048257
2020-01-05 18.741801
... ...
2020-04-05 13.349457
2020-04-06 46.103361
2020-04-07 18.023228
2020-04-08 15.545227
2020-04-09 28.464122
[100 rows x 1 columns]
In [19]: t.resample("M").mean() # 将日转化为月统计
Out[19]:
0
2020-01-31 30.747602
2020-02-29 30.882151
2020-03-31 27.194648
2020-04-30 28.130996
In [20]: t.resample("10D").count() # 转化成每10天统计
Out[20]:
0
2020-01-01 10
2020-01-11 10
2020-01-21 10
2020-01-31 10
2020-02-10 10
2020-02-20 10
2020-03-01 10
2020-03-11 10
2020-03-21 10
2020-03-31 10
In [21]: t.resample("QS-JAN").count()
Out[21]:
0
2020-01-01 91
2020-04-01 9
10. PM2.5数据练习
现在有北上广,深圳和沈阳5个城市空气质量数据,请绘制出5个城市的pm2.5随时间变化情况
观察这组数据中的时间结构,并不是字符串,这个时候怎么处理?
数据来源: https://www.kaggle.com/uciml/pm25-data-for-five-chinese-cities
本地数据 ../数据文件/pm2.5/..
通过读取数据,可以看到时间格式是分开的:
No year month day hour ... TEMP cbwd Iws precipitation Iprec
0 1 2010 1 1 0 ... -22.0 NE 1.0289 NaN NaN
1 2 2010 1 1 1 ... -23.0 NE 2.5722 NaN NaN
2 3 2010 1 1 2 ... -23.0 NE 5.1444 NaN NaN
3 4 2010 1 1 3 ... -23.0 NE 7.7166 NaN NaN
4 5 2010 1 1 4 ... -23.0 NE 9.7744 NaN NaN
上图中 year,month,day是分开的,可以使用
PeriodIndex进行转换
之前学习的DatetimeIndex可以理解为时间戳,那么现在学习的Periodindex可以理解为时间段
periods=pd.PeriodIndex(year=data["year"],month=data["month"],day=["day"],hour=data["hour"],freq="H")
那么如果给这个时间段降采样呢 ->data=df.set_index(periods).resample("10D").mean()
import pandas as pd
from matplotlib import pyplot as plt, font_manager
# 显示所有列
# pd.set_option('display.max_columns', None)
my_font = font_manager.FontProperties(
fname="/home/zhiwei/.deepinwine/Deepin-QQ/drive_c/windows/Fonts/msyh.ttc")
plt.figure(figsize=(20, 8), dpi=80)
df_beijing = pd.read_csv("../数据文件/pm2.5/BeijingPM20100101_20151231.csv")
df_chengdu = pd.read_csv("../数据文件/pm2.5/ChengduPM20100101_20151231.csv")
df_guangzhou = pd.read_csv("../数据文件/pm2.5/GuangzhouPM20100101_20151231.csv")
df_shanghai = pd.read_csv("../数据文件/pm2.5/ShanghaiPM20100101_20151231.csv")
df_shenyang = pd.read_csv("../数据文件/pm2.5/ShenyangPM20100101_20151231.csv")
my_font = font_manager.FontProperties(
fname="/home/zhiwei/.deepinwine/Deepin-QQ/drive_c/windows/Fonts/msyh.ttc")
plt.figure(figsize=(20, 8), dpi=80)
print(df_beijing.head())
print(df_beijing.info())
# 把分开的时间字符串通过periodIndex方法转化为时间类型
period = pd.PeriodIndex(year=df_beijing["year"], month=df_beijing["month"], day=df_beijing["day"],hour=df_beijing["hour"], freq="D")
# 将时间作为索引,df中首先添加一列datetime
df_beijing["datetime"] = period
print(df_beijing.head())
# datetime设置为索引
df_beijing.set_index("datetime", inplace=True)
# 进行降采样,按月份进行统计
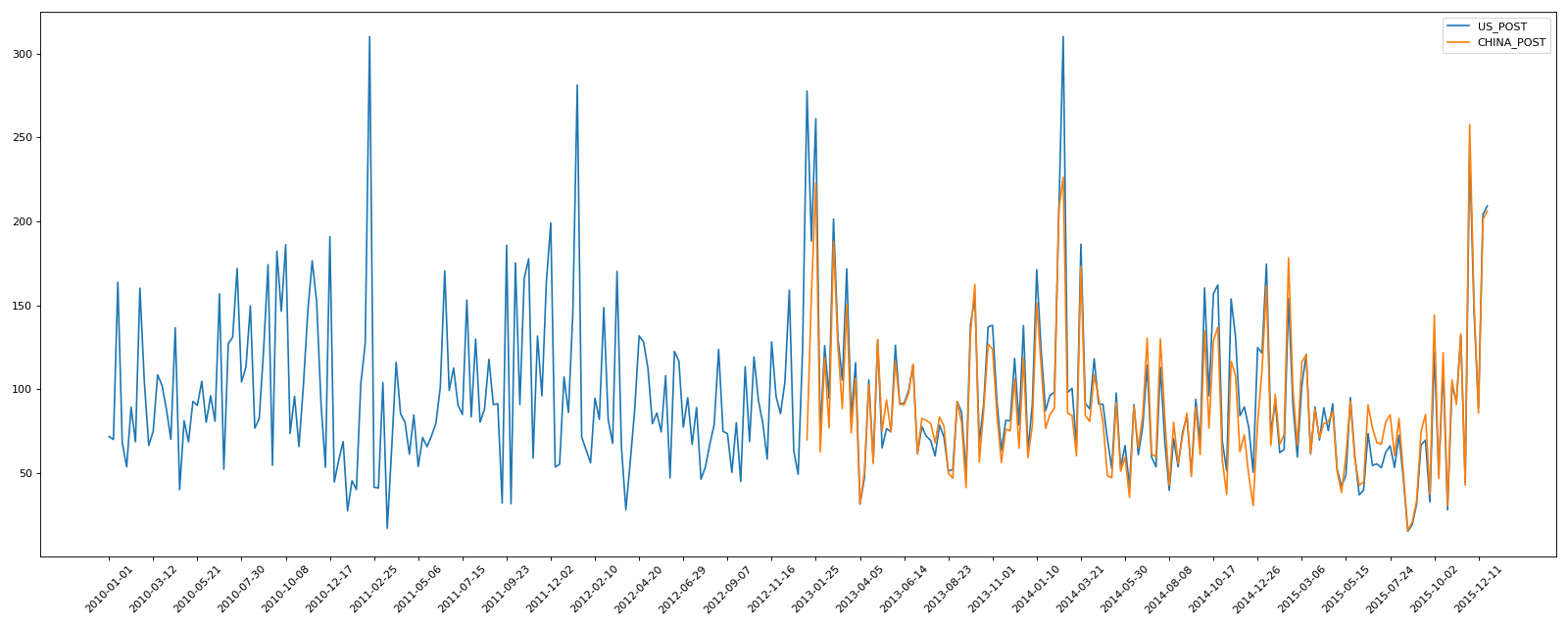
df_beijing = df_beijing.resample("7D").mean()
data = df_beijing["PM_US Post"]
data_china = df_beijing["PM_Dongsi"]
_x = data.index
_y = data.values
china_x = data_china.index
china_y = data_china.values
plt.plot(range(len(_x)),_y,label="US_POST")
plt.plot(range(len(china_x)),china_y,label="CHINA_POST")
plt.xticks(range(0,len(_x),10),list(_x)[::10],rotation=45)
plt.legend(loc="best")
plt.show()
运行结果: