

scrapy -- 中间件
中间件的位置和作用
- 位置 : 在引擎和下载器之间
- 作用 : 批量拦截到整个工程所有的请求和响应
- 中间件的py文件:爬虫工程中, middlewares.py就是写中间件的文件,所有的中间件都写在这个文件中
一、拦截请求
- 通过请求中间件,把请求信息拦截到,可以修改请求信息后再发送给服务端
- 应用场景:
- UA伪装:在拦截到请求信息时,进行UA伪装,应对网站的反爬机制
- 代理IP:在拦截到请求信息时,通过代理IP,来改变请求信息的IP,防止一个IP多次高频爬取被加入黑名单
这里来一个实例,进行演示一下:
- 创建一个UA伪装池和IP池,来多次访问百度,获取一下响应信息,看看是否发生变化
1.中间件文件-- middlewares.py代码示例
import random
class MiddleproDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
#创建一个UA池,在拦截到请求信息是,随机取出一个,进行UA信息篡改
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 "
"(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
#创建一个http的IP池,在拦截到请求信息是,随机取出一个,进行IP信息篡改
PROXY_http = [
'153.180.102.104:80',
'195.208.131.189:56055',
]
#创建一个https的IP池,在拦截到请求信息是,随机取出一个,进行IP信息篡改
PROXY_https = [
'120.83.49.90:9000',
'95.189.112.214:35508',
]
#拦截请求
def process_request(self, request, spider):
#UA伪装
request.headers['User-Agent'] = random.choice(self.user_agent_list)
#为了验证代理的操作是否生效
request.meta['proxy'] = 'http://183.146.213.198:80'
return None
#拦截所有的响应
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
#拦截发生异常的请求
def process_exception(self, request, exception, spider):
if request.url.split(':')[0] == 'http':
#代理
request.meta['proxy'] = 'http://'+random.choice(self.PROXY_http)
else:
request.meta['proxy'] = 'https://' + random.choice(self.PROXY_https)
return request #将修正之后的请求对象进行重新的请求发送
2.爬虫文件.py代码示例
import scrapy
class MiddleSpider(scrapy.Spider):
#爬取百度
name = 'middle'
# allowed_domains = ['www.xxxx.com']
start_urls = ['http://www.baidu.com/s?wd=ip']
def parse(self, response):
page_text = response.text
#将获取到的响应信息,写入到本地一个HTML文件中,以便于待会查看
with open('./ip.html','w',encoding='utf-8') as fp:
fp.write(page_text)
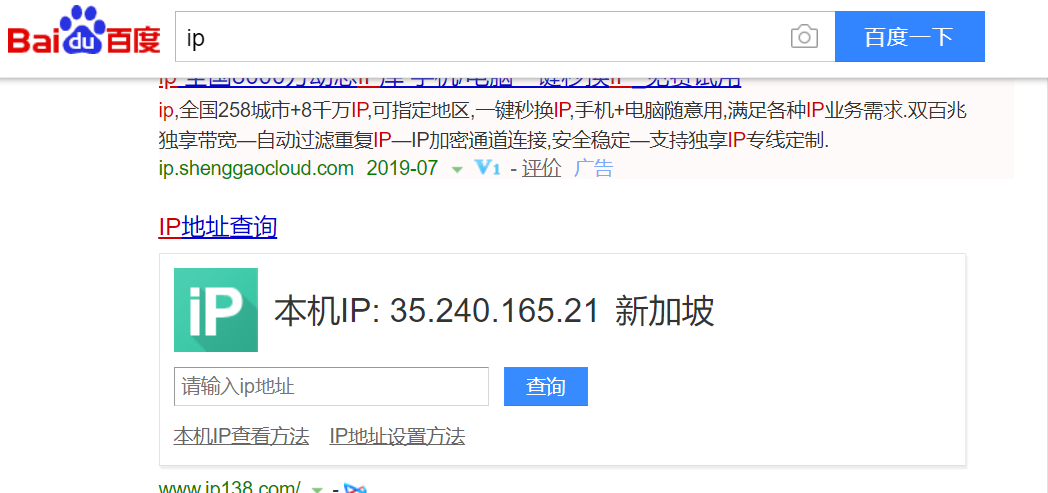
- 用命令执行该爬虫文件后,会在项目中生成一个 ip.html 的文件,打开文件,可以看到被篡改的IP信息,如图:
二、拦截响应
- 通过中间件,把响应信息拦截到,然后就进行篡改,再通过引擎返回修改过的响应信息
- 应用场景:
- 对于一些存在动态加载的数据,如果直接请求,是不能获取到加载后的数据,这个时候用selenium将动态加载后的数据获取到,再返回给爬虫文件
这里来一个实例,爬取网易新闻:
#1.爬虫文件.py代码示例:
import scrapy
from selenium import webdriver
from wangyiPro.items import WangyiproItem
class WangyiSpider(scrapy.Spider):
name = 'wangyi'
# allowed_domains = ['www.cccom']
start_urls = ['https://news.163.com/']
models_urls = [] #存储五个板块对应详情页的url
#解析五大板块对应详情页的url
#用selenium实例化一个浏览器对象,
def __init__(self):
self.bro = webdriver.Chrome()
def parse(self, response):
li_list = response.xpath('//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li')
alist = [3,4,6,7,8]
for index in alist:
model_url = li_list[index].xpath('./a/@href').extract_first()
self.models_urls.append(model_url)
#依次对每一个板块对应的页面进行请求
for url in self.models_urls:#对每一个板块的url进行请求发送
yield scrapy.Request(url,callback=self.parse_model)
#每一个板块对应的新闻标题相关的内容都是动态加载
def parse_model(self,response): #解析每一个板块页面中对应新闻的标题和新闻详情页的url
# response.xpath()
div_list = response.xpath('/html/body/div/div[3]/div[4]/div[1]/div/div/ul/li/div/div')
for div in div_list:
title = div.xpath('./div/div[1]/h3/a/text()').extract_first()
new_detail_url = div.xpath('./div/div[1]/h3/a/@href').extract_first()
item = WangyiproItem()
item['title'] = title
#对新闻详情页的url发起请求,并将item当做参数,传给下一个回调函数使用,确保数据都能再一个item里
yield scrapy.Request(url=new_detail_url,callback=self.parse_detail,meta={'item':item})
def parse_detail(self,response):#解析新闻内容
content = response.xpath('//*[@id="endText"]//text()').extract()
content = ''.join(content)
item = response.meta['item']
item['content'] = content
yield item
def closed(self,spider):
self.bro.quit()
#2.minddlewares.py文件代码示例:
from scrapy import signals
from scrapy.http import HtmlResponse
from time import sleep
class WangyiproDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
#该方法拦截五大板块对应的响应对象,进行篡改
def process_response(self, request, response, spider):#spider爬虫对象
bro = spider.bro#获取了在爬虫类中定义的浏览器对象
#挑选出指定的响应对象进行篡改
#通过url指定request
#通过request指定response
if request.url in spider.models_urls:
bro.get(request.url) #五个板块对应的url进行请求
sleep(3)
page_text = bro.page_source #包含了动态加载的新闻数据
#response #五大板块对应的响应对象
#针对定位到的这些response进行篡改
#实例化一个新的响应对象(符合需求:包含动态加载出的新闻数据),替代原来旧的响应对象
#如何获取动态加载出的新闻数据?
#基于selenium便捷的获取动态加载数据
new_response = HtmlResponse(url=request.url,body=page_text,encoding='utf-8',request=request)
return new_response
else:
#response #其他请求对应的响应对象
return response
分类:
scrapy -- 爬虫框架使用


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通