
clickhouse的kafka引擎优化使用
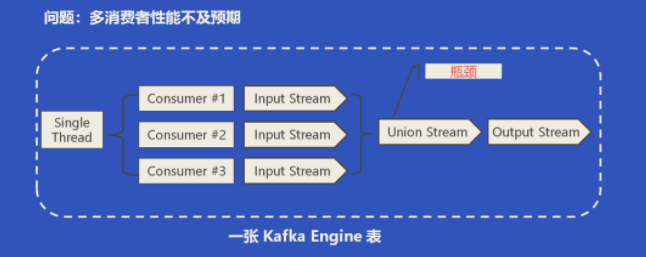
目前实现的 Kafka 表,内部默认只会有一个消费者,这样会比较浪费资源并且性能达不到性能要求。一开始我们可以通过增大消费者的个数来增大消费能力,但社区的实现一开始是由一个线程去管理多个的消费者,多个的消费者各自解析输入数据并生成的 Input Stream 之后,会由一个 Union Stream 将多个 Input Stream 组合起来。这里的 Union Stream 会有潜在的性能瓶颈,多个消费者消费到的数据最后仅能由一个输出线程完成数据构建,所以这里没能完全利用上多线程和磁盘的潜力。
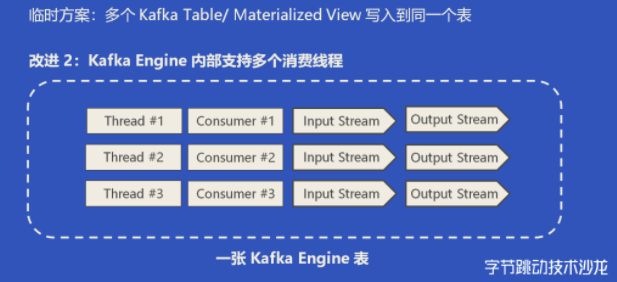
一开始的解决方法,是建了多张 Kafka Table 和 Materialized View 写入同一张表,这样就有点近似于多个 INSERT Query 写入了同一个 MergeTree 表。当然这样运维起来会比较麻烦,最后我们决定通过改造 Kafka Engine 在其内部支持多个消费线程,简单来说就是每一个线程它持有一个消费者,然后每一个消费者负责各自的数据解析、数据写入,这样的话就相当于一张表内部同时执行多个的 INSERT Query,最后的性能也接近于线性的提升。
资料引自:https://mp.weixin.qq.com/s/hqUCFSr8cu3x3u8HCA6WYg

