
flume常见的source、channel、sink
一、source
1、avro source
侦听Avro端口并从外部Avro客户端流接收事件。 当与另一个(上一跳)Flume代理上的内置Avro Sink配对时,它可以创建分层集合拓扑。
| channels | – | |
| type | – | The component type name, needs to be avro |
| bind | – | hostname or IP address to listen on |
| port | – | Port # to bind to |
使用场景:分层的数据收集。
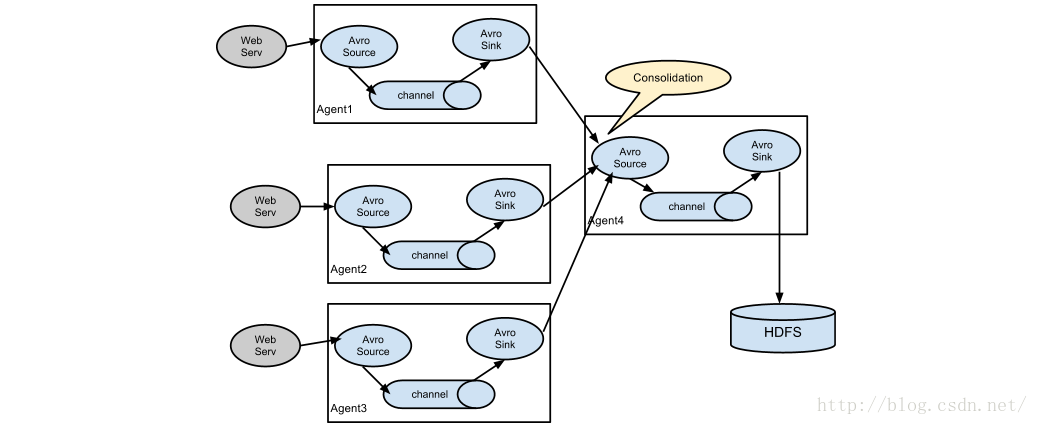
例如:两层的日志收集:
使用flume将Nginx日志文件上传到hdfs上,要求hdfs上的目录使用日期归档
Flume:
agent的配置 source channel sink
flume的部署模式:
两层模式:
第一层:Flume agent 与每台nginx部署在一起
exec source + memory channel/file channel + avro sink
第二层:(收集汇集层)
avro source + memory channel + hdfs sink
flume agent启动过程:
先启动第二层flume agent avro 服务端
先打印日志到控制台,检查是否报错:
$ bin/flume-ng agent --name a2 --conf conf/ --conf-file conf/agents/flume_a2.conf -Dflume.root.logger=INFO,console
查看端口:
$ netstat -tlnup | grep prot
再启动第一层 flume agent
其中第一层的conf-file如下:
a1.conf
# exec source + memory channel + avro sink # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/datas/nginx/user_logs/access.log # Describe the sink avro sink a1.sinks.k1.type = avro a1.sinks.k1.channel = c1 a1.sinks.k1.hostname = rainbow.com.cn a1.sinks.k1.port = 4545 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # combine Source channel sink a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
a2.conf
# avro source + memory channel + hdfs sink # Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source a2.sources.r1.type = avro a2.sources.r1.channels = c1 a2.sources.r1.bind = rainbow.com.cn a2.sources.r1.port = 4545 # hdfs sink a2.sinks.k1.type = hdfs a2.sinks.k1.channel = c1 a2.sinks.k1.hdfs.path = /nginx_logs/events/%y-%m-%d/ a2.sinks.k1.hdfs.filePrefix = events- # hfds上文件目录创建的频率 #a2.sinks.k1.hdfs.round = true #a2.sinks.k1.hdfs.roundValue = 10 #a2.sinks.k1.hdfs.roundUnit = minute # hfds上目录使用了时间转换符 %y-%m-%d a2.sinks.k1.hdfs.useLocalTimeStamp = true # 使用文本文件,不使用sequenceFile a2.sinks.k1.hdfs.fileType = DataStream # 多长时间写数据到新文件 a2.sinks.k1.hdfs.rollInterval = 0 # 文件达到多少数据量时 写新文件 # 文件大小 接近于一个Block的大小 128M ~ 120M左右 a2.sinks.k1.hdfs.rollSize = 10240 # 文件已经写了多次次之后,写新文件 a2.sinks.k1.hdfs.rollCount = 0 # Use a channel which buffers events in memory a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1
2、thrif source
监听Thrift端口并从外部Thrift客户端流接收事件。 当与另一(前一跳)Flume代理上的内置ThriftSink配对时,它可以创建分层集合拓扑。 Thrift源可以配置为通过启用kerberos身份验证在安全模式下启动。 agent-principal和agent-keytab是Thrift源用来向kerberos KDC进行身份验证的属性。
| channels | – | |
| type | – | The component type name, needs to be thrift |
| bind | – | hostname or IP address to listen on |
| port | – | Port # to bind to |
用法与avro类似。
3、exec source
Exec源在启动时运行给定的Unix命令,并期望该进程在标准输出上连续产生数据(除非属性logStdErr设置为true,否则stderr将被丢弃)。 如果进程由于任何原因退出,源也会退出,并且不会产生进一步的数据。 这意味着诸如cat [named pipe]或tail -F [file]之类的配置将产生期望的结果,其中日期可能不会 - 前两个命令产生数据流,其中后者产生单个事件并退出。
| channels | – | |
| type | – | The component type name, needs to be exec |
| command | – | The command to execute |
例子详见上文件a1.conf
4、spooling directory source
此源允许您通过将要提取的文件放入磁盘上的“spooling”目录中来提取数据。此源将监视新文件的指定目录,并在新文件显示时解析新文件中的事件。事件解析逻辑是可插入的。在给定文件被完全读入通道之后,它被重命名以指示完成(或可选地被删除)。
与Exec源不同,该源是可靠的,并且不会错过数据,即使Flume被重新启动或被杀死。为了换取这种可靠性,只有不可变,唯一命名的文件必须放入spooling目录中。 Flume尝试检测这些问题条件,如果违反则会大声失败:
如果在放入spooling目录后写入文件,Flume将在其日志文件中打印一个错误并停止处理。
如果以后重新使用文件名,Flume会在其日志文件中打印一个错误并停止处理。
为了避免上述问题,向日志文件名添加一个唯一标识符(例如时间戳)将它们移动到spooling目录中可能是有用的
尽管该源的可靠性保证,仍然存在其中如果发生某些下游故障则事件可能被复制的情况。这与其他Flume组件提供的保证一致。
| Property Name | Default | Description |
|---|---|---|
| channels | – | |
| type | – | The component type name, needs to be spooldir. |
| spoolDir | – | The directory from which to read files from. |
例如:
a1.sources = s1 a1.channels = c1 a1.sinks = k1 # define source a1.sources.s1.type = spooldir a1.sources.s1.spoolDir = /opt/data/flume/log a1.sources.s1.ignorePattern = ([^ ]*\.tmp$) //正则表达式指定要忽略的文件(跳过)。 #define channel a1.channels.c1.type = file a1.channels.c1.checkpointDir = /opt/data/flume/check a1.channels.c1.dataDirs = /opt/data/flume/data #define sinks a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = hdfs://rainbow.com.cn:8020/flume/envent/%y-%m-%d //hdfs的全路径 a1.sinks.k1.hdfs.fileType = DataStream //文件格式、DataStream 不用设置压缩方式,CompressionStream需要设置压缩方式hdfs.codeC a1.sinks.k1.hdfs.useLocalTimeStamp = true a1.sinks.k1.hdfs.rollCount = 0 a1.sinks.k1.hdfs.rollSize = 10240 a1.sinks.k1.hdfs.rollInterval = 0 a1.sinks.k1.hdfs.filePrefix = rainbow # combine a1.sources.s1.channels = c1 a1.sinks.k1.channel = c1
5、kafka source
Kafka Source是一个从Kafka主题读取消息的Apache Kafka消费者。 如果您有多个Kafka源运行,您可以使用相同的Consumer Group配置它们,这样每个都将为主题读取一组唯一的分区。
| channels | – | |
| type | – | The component type name, needs to be org.apache.flume.source.kafka.KafkaSource |
| kafka.bootstrap.servers | – | List of brokers in the Kafka cluster used by the source |
| kafka.consumer.group.id | flume | Unique identified of consumer group. Setting the same id in multiple sources or agents indicates that they are part of the same consumer group |
| kafka.topics | – | Comma-separated list of topics the kafka consumer will read messages from. |
| kafka.topics.regex | – | Regex that defines set of topics the source is subscribed on. This property has higher priority than kafka.topicsand overrides kafka.topics if exists. |
Example for topic subscription by comma-separated topic list.
tier1.sources.source1.type = org.apache.flume.source.kafka.KafkaSource tier1.sources.source1.channels = channel1 tier1.sources.source1.batchSize = 5000 tier1.sources.source1.batchDurationMillis = 2000 tier1.sources.source1.kafka.bootstrap.servers = localhost:9092 tier1.sources.source1.kafka.topics = test1, test2 tier1.sources.source1.kafka.consumer.group.id = custom.g.id
Example for topic subscription by regex
tier1.sources.source1.type = org.apache.flume.source.kafka.KafkaSource tier1.sources.source1.channels = channel1 tier1.sources.source1.kafka.bootstrap.servers = localhost:9092 tier1.sources.source1.kafka.topics.regex = ^topic[0-9]$ # the default kafka.consumer.group.id=flume is used
_________________________________________________-
sink
1、HDFS sink
此接收器将事件写入Hadoop分布式文件系统(HDFS)。 它目前支持创建文本和序列文件。 它支持两种文件类型的压缩。 可以基于经过的时间或数据大小或事件数量来周期性地滚动文件(关闭当前文件并创建新文件)。 它还通过属性(例如事件发生的时间戳或机器)来对数据进行桶/分区。 HDFS目录路径可能包含将由HDFS接收器替换的格式化转义序列,以生成用于存储事件的目录/文件名。 使用此接收器需要安装hadoop,以便Flume可以使用Hadoop jar与HDFS集群进行通信
# hdfs sink a2.sinks.k1.type = hdfs a2.sinks.k1.channel = c1 a2.sinks.k1.hdfs.path = /nginx_logs/events/%y-%m-%d/ a2.sinks.k1.hdfs.filePrefix = events- # hfds上文件目录创建的频率 #a2.sinks.k1.hdfs.round = true #a2.sinks.k1.hdfs.roundValue = 10 #a2.sinks.k1.hdfs.roundUnit = minute # hfds上目录使用了时间转换符 %y-%m-%d a2.sinks.k1.hdfs.useLocalTimeStamp = true # 使用文本文件,不使用sequenceFile a2.sinks.k1.hdfs.fileType = DataStream # 多长时间写数据到新文件 a2.sinks.k1.hdfs.rollInterval = 0 # 文件达到多少数据量时 写新文件 # 文件大小 接近于一个Block的大小 128M ~ 120M左右 a2.sinks.k1.hdfs.rollSize = 10240 # 文件已经写了多次次之后,写新文件 a2.sinks.k1.hdfs.rollCount = 0
注意对于所有与时间相关的转义序列,必须在事件的标头中存在具有键“timestamp”的标题(除非将hdfs.useLocalTimeStamp设置为true)。 一种自动添加的方法是使用TimestampInterceptor
2、hive sink
此接收器将包含定界文本或JSON数据的事件直接传输到Hive表或分区。 事件使用Hive事务写入。 一旦将一组事件提交给Hive,它们就立即对Hive查询可见。 flume将流入的分区可以是预创建的,或者,如果缺少,Flume可以创建它们。 来自传入事件数据的字段映射到Hive表中的相应列。
| channel | – | |
| type | – | The component type name, needs to be hive |
| hive.metastore | – | Hive metastore URI (eg thrift://a.b.com:9083 ) |
| hive.database | – | Hive database name |
| hive.table | – | Hive table name |
a1.channels = c1 a1.channels.c1.type = memory a1.sinks = k1 a1.sinks.k1.type = hive a1.sinks.k1.channel = c1 a1.sinks.k1.hive.metastore = thrift://127.0.0.1:9083 a1.sinks.k1.hive.database = logsdb a1.sinks.k1.hive.table = weblogs a1.sinks.k1.hive.partition = asia,%{country},%y-%m-%d-%H-%M a1.sinks.k1.useLocalTimeStamp = false a1.sinks.k1.round = true a1.sinks.k1.roundValue = 10 a1.sinks.k1.roundUnit = minute a1.sinks.k1.serializer = DELIMITED a1.sinks.k1.serializer.delimiter = "\t" a1.sinks.k1.serializer.serdeSeparator = '\t' a1.sinks.k1.serializer.fieldnames =id,,msg
3、hbase sink
| channel | – | |
| type | – | The component type name, needs to be hbase |
| table | – | The name of the table in Hbase to write to. |
| columnFamily | – | The column family in Hbase to write to. |
a1.channels = c1 a1.sinks = k1 a1.sinks.k1.type = hbase a1.sinks.k1.table = foo_table a1.sinks.k1.columnFamily = bar_cf a1.sinks.k1.serializer = org.apache.flume.sink.hbase.RegexHbaseEventSerializer a1.sinks.k1.channel = c1
4、avro sink
avro sink形成了Flume分层收集支持的一半。 发送到此接收器的Flume事件将转换为Avro事件并发送到配置的主机名/端口对。 事件从已配置的通道以批量配置的批处理大小获取
| channel | – | |
| type | – | The component type name, needs to be avro. |
| hostname | – | The hostname or IP address to bind to. |
| port | – | The port # to listen on. |
例如:
# Describe the sink avro sink a1.sinks.k1.type = avro a1.sinks.k1.channel = c1 a1.sinks.k1.hostname = rainbow.com.cn a1.sinks.k1.port = 4545
5、kafka sink
这是一个Flume Sink实现,可以将数据发布到Kafka主题。 其中一个目标是将Flume与Kafka集成,以便基于pull的处理系统可以处理通过各种Flume源的数据。 这目前支持Kafka 0.9.x系列发行版。
| type | – | Must be set to org.apache.flume.sink.kafka.KafkaSink |
| kafka.bootstrap.servers | – | List of brokers Kafka-Sink will connect to, to get the list of topic partitions This can be a partial list of brokers, but we recommend at least two for HA. The format is comma separated list of hostname:port |
例如:
a1.sources = s1 a1.channels = c1 a1.sinks = k1 # define source a1.sources.s1.type = exec a1.sources.s1.command = tail -F /opt/modules/cdh5.3.6/Hive-0.13.1-cdh5.3.6/logs/hive.log a1.sources.s1.shell = /bin/sh -c #define channel a1.channels.c1.type = file a1.channels.c1.checkpointDir = /mnt/flume/checkpoint a1.channels.c1.dataDirs = /mnt/flume/data #define sinks a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.brokerList = rainbow.com.cn:9092 a1.sinks.k1.topic = testTopic # combination a1.sources.s1.channels = c1 a1.sinks.k1.channel = c1
3、channel
1、file channel
File Channel是一个持久化的隧道(channel),数据安全并且只要磁盘空间足够,它就可以将数据存储到磁盘上。
a1.channels = c1 a1.channels.c1.type = file a1.channels.c1.checkpointDir = /mnt/flume/checkpoint a1.channels.c1.dataDirs = /mnt/flume/data
2、memory channel
事件存储在具有可配置最大大小的内存队列中。 它是需要更高吞吐量并准备在代理故障的情况下丢失上载数据的流的理想选择。 Memory Channel是一个不稳定的隧道,它在内存中存储所有事件。如果进程异常停止,内存中的数据将不能让恢复。受内存大小的限制。
a1.channels = c1 a1.channels.c1.type = memory a1.channels.c1.capacity = 10000 a1.channels.c1.transactionCapacity = 10000 a1.channels.c1.byteCapacityBufferPercentage = 20 a1.channels.c1.byteCapacity = 800000
具体详情参照:
http://flume.apache.org/FlumeUserGuide.html#memory-channel
flume-ng-sqlSource
##name agent.channels = ch1 agent.sinks = HDFS agent.sources =sqlSource ##channel agent.channels.ch1.type = memory agent.sources.sqlSource.channels = ch1 ##source # For each one of the sources, the type is defined agent.sources.sqlSource.type = org.keedio.flume.source.SQLSource agent.sources.sqlSource.hibernate.connection.url = jdbc:mysql://192.168.222.222:3306/bigdata_lots # Hibernate Database connection properties agent.sources.sqlSource.hibernate.connection.user = bigd22ots agent.sources.sqlSource.hibernate.connection.password = Big22lots.2017 agent.sources.sqlSource.hibernate.connection.autocommit = true agent.sources.sqlSource.hibernate.dialect = org.hibernate.dialect.MySQLDialect agent.sources.sqlSource.hibernate.connection.driver_class = com.mysql.jdbc.Driver agent.sources.sqlSource.table = ecological_company # Columns to import to kafka (default * import entire row) agent.sources.sqlSource.columns.to.select = * # Query delay, each configured milisecond the query will be sent agent.sources.sqlSource.run.query.delay=10000 # Status file is used to save last readed row agent.sources.sqlSource.status.file.path = /var/lib/flume agent.sources.sqlSource.status.file.name = sqlSource.status agent.sources.sqlSource.hibernate.connection.provider_class = org.hibernate.connection.C3P0ConnectionProvider agent.sources.sqlSource.hibernate.c3p0.min_size=1 agent.sources.sqlSource.hibernate.c3p0.max_size=10 ##sink agent.sinks.HDFS.channel = ch1 agent.sinks.HDFS.type = hdfs agent.sinks.HDFS.hdfs.path = hdfs://nameservice1/flume/mysql agent.sinks.HDFS.hdfs.fileType = DataStream agent.sinks.HDFS.hdfs.writeFormat = Text agent.sinks.HDFS.hdfs.rollSize = 268435456 agent.sinks.HDFS.hdfs.rollInterval = 0

