ARM体系架构--CPSR
转载:https://zhuanlan.zhihu.com/p/129035692#:~:text=APSR%2FCPSR%2C%20PSR%20%E5%8D%B3%20program%20status%20register%20%E7%A8%8B%E5%BA%8F%E7%8A%B6%E6%80%81%E5%AF%84%E5%AD%98%E5%99%A8%EF%BC%8CA%E5%8D%B3%20apilication,saved%20%E5%B7%B2%E4%BF%9D%E5%AD%98%E7%9A%84%EF%BC%8C%E6%89%80%E4%BB%A5%E5%85%A8%E7%A7%B0%20%E5%B7%B2%E4%BF%9D%E5%AD%98%E7%9A%84%E7%A8%8B%E5%BA%8F%E7%8A%B6%E6%80%81%E5%AF%84%E5%AD%98%E5%99%A8%20%EF%BC%8C%E6%9B%B4%E5%A5%BD%E5%90%AC%E4%B8%80%E7%82%B9%E7%A7%B0%E4%B8%BA%20%E5%AD%98%E5%82%A8%E7%A8%8B%E5%BA%8F%E7%8A%B6%E6%80%81%E5%AF%84%E5%AD%98%E5%99%A8%20%E6%88%96%E8%80%85%20%E5%A4%87%E4%BB%BD%E7%8A%B6%E6%80%81%E5%AF%84%E5%AD%98%E5%99%A8%20%E3%80%82
现在来说的话,嵌入式领域基本上ARM一家独大,所以学习嵌入式开发,对于ARM体系的了解必不可少,只有在了解ARM体系的基础上才能理解ARM汇编(GNU汇编),但是我之前跟了好几家的视频以及教程,对于ARM的了解还是一知半解,究其原因我觉得大家都在说怎么做,但是很少有说到为什么这么做,这篇文章以具体例子来说明一下这些概念与区别,然后我们就能顺其自然的直到为什么要这样做
所以在解决方案提出以前,我们需要恶补一下相关概念,以便我们更好的入门ARM的世界
文章内容为个人跟随视频教程、查阅资料和博客,所做笔记,所以水平有限,如有错误,欢迎指正
ARM处理器相关名词
流水线:
底层架构设计的术语。 CPU先fetch(取指令),然后decode(译码),然后excute(执行),称为基于F D E的三步操作,才能完成CPU的运算,这种三步完成的称为三级流水。
DSP:
数字信号处理,可以理解为一个单独的芯片或者协处理器来处理数字信号,比如说多媒体信号(因为对任务的独占性要求高,使用主CPU去处理的话,别的任务可能兼顾不过来)。
Jazelle:
arm中针对Java的编程模型,基本不会用到
半字: 默认情况下int占四个字节,单个字节存储容易将一个数据破坏,所以有时候将四个字节一起存储,称为一个字,半字就代表两个字节一起操作
Thumb:
即Thumb指令,辅助arm处理的指令,因为32位的机器上arm指令占32位即四个字节,但有时候为了减少指令所占用的空间,就引入了thumb(小拇指)指令,是一个16位的精简指令,再后来推出的Thumb2是16位与32位混合的指令。
VFP:
Vector Floating-Point矢量浮点运算机制
QEMU:
实际上是一个软件模拟器,模拟不同的架构体系(例如x86 arm),调试bootloader或者裸机程序的时候可以使用
GNU工具链:
既可以开发内核也可以用来开发应用程序 包含如下组件:
- GNU make
- GNU Compiler Collection (GCC)
- GNU binutils linker, assembler and other object/library manipulation tools
- GNU Debugger (GDB)
- GNU build system (autotools)
- GNU C Library (glibc or eglibc)
gnueabi的含义:
e 表示 embedded 嵌入式 a 表示 application 应用程序 b 表示 binary 二进制 i 表示 interface 接口 全称嵌入式应用程序二进制接口,所以它的作用就是编译生成嵌入式的二进制程序 下载网址可以去linaro
UEFI:
Unified Extensible Firmware Interface 统一可扩展的部件接口 相当于硬件与操作系统适配的标准,制定了操作系统可以扩展哪些硬件接口,但我们在做arm开发的时候可能硬件不是特别规范,那么就可以使用这个标准模拟出符合标准的硬件,绕过它。
TrustZone:
安全架构
LPAE:
Large Physical Address Extension(大物理地址扩展) 类似于虚拟化的技术 32位按理说最多只能寻址4G内存 但使用之后,内存可以虚拟为特别大,一个T也没有关系(硬件层面)
big LITTLE:
大小 处理器可能需要一个主处理器与协处理器 例如主处理器A15和协处理器A8 当任务量要求不大的时候,切换到协处理器,会降低功耗 主要是针对手持设备,解决费电的问题 官方宣称使用这种方式比完全使用主处理器可以省电70%
CPU组成:
- ALU单元(逻辑运算单元)
- 控制器,可以用来切换CPU状态
- 寄存器(小型的存储器)
- CPU内部总线 最最主要的是前三个 但是与我们写程序最最关心的就是CPU状态切换与寄存器
SIMD:
往后翻,单独讲
NEON:
往后翻,单独讲
MMU:
往后翻,单独讲
Cache:
往后翻,单独讲
arm处理器模式
不同系列的处理器,处理器模式可能不一样 例如arm7与arm9有7种处理器模式 但是A系列的有9种处理器模式
处理器模式是指系统运行的时候如果出现崩溃的时候,切换CPU模式,来完成安全,效率,节能控制。因为系统崩溃的时候cpu的工作是没有意义的,所以这时候为了节能等其他方面的考虑,必须切换处理器模式。
下面以cotex A 系列的九种处理器模式进行介绍,
一种非特权模式,8种特权模式
模式编码也会存放在指令(也就是32位中占据5位)的某个区域
USR用户模式,大部分程序运行所处的模式,普通模式
FIQ为fast interrupt,快速中断模式,
SVC为超级管理员模式,当开机的时候cpu权限最高,按下reset键的时候,系统停下所有工作,执行reset,权限非常大,一般不能随便使用
MON是cotex A系列增加的,称为监视模式,相当于一个后台的服务
ABT退出模式,通常用户程序发生异常的时候,cpu停止代码运行,然后退出
HYP是超级的监视者,比超级管理员低一点,一般也不常用
SYS当系统自身异常的时候,有一个特点就是与用户模式寄存器共享 模式基本都用大写的简写来表示
USR FIQ IRQ SVC MON ABT HYP UND SYS
因为内存不稳定以及访问速度慢等原因,所以在cpu中需要寄存器。
USR模式下寄存器
r1到r12都是通用寄存器
r13为sp,即stack pointer 栈指针。存储栈地址,程序跳转的时候,保存程序跳转的目标地址标识
r14为lr,即link register链接寄存器。存储子程序的返回地址。
r15为pc,即program count程序计数器。
APSR/CPSR, PSR 即program status register程序状态寄存器,A即apilication应用,C即current当前,所以全称为应用/当前程序状态寄存器。
SPSR中 S 即saved已保存的,所以全称已保存的程序状态寄存器,更好听一点称为存储程序状态寄存器或者备份状态寄存器。
举例说明CPSR/APSR与SPSR寄存器: 当前程序状态假设是normal状态那么这个状态先保存到CPSR,但之后突然发生异常(exception),这时候exception会存到CPSR寄存器,但处理完异常以后想要返回normal状态,这时候原来的normal状态已经被冲掉了,所以就需要SPSR寄存器对原来状态进行保存,保证可以还原到原来状态。 正是因为我们的这种需求,所以处理器的 USR 模式下没有 SPSR 因为 USR模式是正常的模式,所以不需要记录异常模式,或者其他状态模式,这样知识就联系起来了,理解起来也就更容易了。
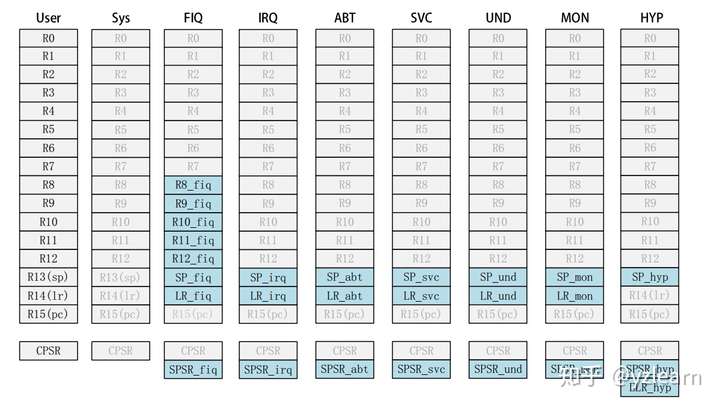
大约18个寄存器,分为通用寄存器与特殊寄存器
上图中的横向来看,灰色的都为不同模式之间共享的寄存器,空出来的都为对应模式下不存在的寄存器 主要是可以看明白这张图,不用记住这张图。 USR模式下(或者说非特权模式下)才有APSR寄存器,其他模式下叫做CPSR
总结:
- R0-R12是通用寄存器,放通用数据,32bit
- 各个模式的R0-R12与USR模式是共享的(除了FIQ,R8-R12独有),PC,CPSR共享
- USR模式没有CPSR
- R13是sp,R14是lr,R15是pc (这四句话尽量背过)
R0-R7被称为低寄存器组,R8-R15被称为高寄存器组,为什么会这样呢 这就回到了之前说的arm指令,Thumb指令以及ThumbEE指令,当使用arm指令的时候,这些寄存器都会被访问到,但是用Thumb指令指令的时候只能访问通用寄存器的寄存器组,不能访问R8-R12这些寄存器,会出错。当然,特殊寄存器还是可以访问到的,所以不同指令集下,寄存器也会进行相应的切换。
CPSR寄存器各个位的介绍:

- M[4:0] 是模式寄存器控制位,正好对应上面表格的处理器模式编码(知识又巧妙地联系在了一起)
- T 是 Thumb 的缩写,是否使用Thumb指令集,为1是yes,即使用Thumb指令集
- F 是 FIQ 的缩写,不是指当前章台是否处于FIQ,而是表示是否禁用FIQ模式,为1禁用,也可以称为屏蔽快速中断
- I 是 IRQ 的缩写,表示是否禁用(屏蔽)IRQ中断,为1禁止
- A 是 abort 的缩写,是否禁用
Abort模式,为1禁止 - E 是 endian 的缩写,表示大小端模式选择,因为是按一个字长(4个字节)或者半字来进行存储操作,必然会引入大小端模式的争论,为1表示大端
- IT[7:2] 是cotex A系列增加的,针对ThumbEE指令中一些条件判断的执行,就是通过位的方式将 IF-THEN 条件判断进行存储,但是我们使用arm指令的时候,可以不用管。
- GE[3:0] 是 SIMD 指令(单指令多数据流技术,主要用于多媒体加强)的使用
- [23:20]作为保留
- J 是 Jazelle 状态,表示是否启动对Java的加速,为1启用
- IT[1:0] 是针对ThumbEE指令中一些条件判断的执行
- Q=1 表示累计饱和
- V=1 表示ALU操作溢出
- C=1 表示ALU进位操作
- Z=1 表示ALU计算结果为零
- N=1 表示ALU计算结果为负数 数学运算的这些逻辑与之后的汇编指令相关
流水线
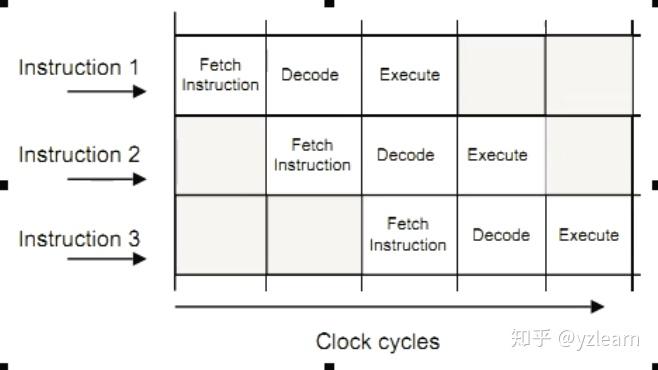
取指->译码->执行->存取->保存结果 像上面这些扩展可以称为五级流水。 流水越多,过程越细,处理能力越强,可控制的情况也就越多,也就越复杂,一般来说,流水越多,也就说明体系架构越强大。 分解指令过程:
- 指令预读取(决定从内存的哪儿取指令)--perfetch
- 指令读取(从内存系统中读取指令)--fetch
- 指令译码(解读指令,并且生成控制信号)
- 寄存器读取(提供寄存器的值给操作单元)
- 分配(分配指令给执行单元,也就是分配给ALU)
- 执行(实际的ALU单元处理)
- 内存访问(数据的存取)
- 寄存器回写(更新运行结果到寄存器)
SIMD
Single Instruction Multiple Data, 单指令多数据流 在SIMD之前,也就是ARMv5之前有一个SISD的概念(Single Instruction Single Data, 单指令单数据流)
# 例如下面这条指令每个数据都会执行一遍取指->译码->执行 这三个流程
# 这样效率就比较低
LDMIA R0, {R1-R8}所以就有了 单指令多数据流 的概念 所以针对多个数据先在内存中建立一个向量表vector,然后将向量表一次读出,相当于多次取指,多次译码,最后一次性执行,这样大大提高cpu的效率 用在浮点运算和多媒体运算,依据此诞生了GPU相关的技术 以图形运算或者视频运算来说,需要强大的浮点运算能力 相当于取多个数据一次性交给CPU,提升效率 SIMD 效率相比于 SISD 提升四倍左右 所以在ARMv6以后基本都使用了SIMD
# 这是一个单指令单操作数
# LDR 称为指令
# R0 R1 称为操作数
LDR R0, R1以下图为例,未使用SIMD之前相当于进行四次运算,使用SIMD以后相当于只进行了一次运算
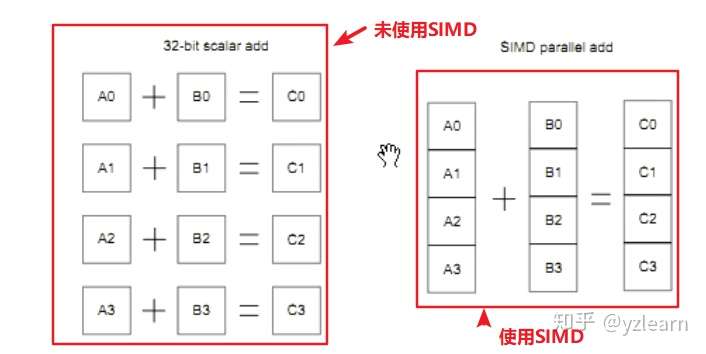
上图来自ARM Cortex-A(armV7)编程手册V4.0中的7.1章节 SIMD
只限于了解,因为这是片内架构设计方面的东西,不需要编程控制
只需要知道为什么经过架构的迭代,ARMv7会快于ARMv6,ARMv6会快于ARMv5 只有在自己生产芯片的时候才会用到这些东西
NEON
ARMv7之后,将SIMD升级为 NEON技术 相当于扩展了浮点运算向量表 有一个VFS的二维向量表,将数据存放到这个表中,cpu可以一次性取某个区域进行执行,NEON就是SIMD的升级 相当于将上面SIMD执行指令的表格长度与宽度进行扩展,提升了数据集的压缩算法。 NENO可以进行指令扩展来实现相关功能,但我们一般不使用,如果做一些GPU相关的工作就需要利用NENO的浮点运算特性。 可用于加速多媒体和信号处理算法(如视频编码/解码)、2D/3D图形、游戏、音频和语音处理、图像处理技术、电话和声音合成,其性能至少为ARMv5的3倍,为ARMv6 SIMD性能的两倍 在SIMD的基础上提升了两倍效率 所以运算速度的加快不是单纯的提升CPU的频率 通过这两个技术提升指令执行的方式,还有其他的方法(比如增加二级缓存)
只限于了解,因为这是片内架构设计方面的东西,不需要编程控制 只需要知道为什么经过架构的迭代,ARMv7会快于ARMv6,ARMv6会快于ARMv5 只有在自己生产芯片的时候才会用到这些东西
总结来说NEON快于SIMD快于SISD,正常按三级流水来说的话,每个指令都要执行一遍,但现在可以多个指令一块执行,降低CPU负荷,提升运行效率
Cache
高速缓存机制 与上面的 SIMD/NENO 都是为了提升速度而设计的,但是 不是重点编程控制的地方。只有在做一些视频库或者DSP芯片的时候,需要深入研究这几个地方。 只有做一些操作系统或者操作系统引导(bootloader)相关的时候会接触到 Cache是一种SRAM片内存储器,特点就是速度快,容量小 Cache横向划分可以分为Cache1,Cache2,Cache3... 纵向划分可以划分为L1 Cache, L2 Cache ...(多级缓存)
为什么需要Cache? I/O向主存请求的级别高于CPU访问内存 主存速度跟不上cpu的发展 主存一般都是片外的,频繁进出速度慢,能耗高 CPU的速度已经足够快了,但是内存速度不够快 所以在片上放一块存储器,因为cpu有预测机制,所以将某个地方的数据全部搬运到片内SRAM缓存中,也不需要软件驱动程序,从而大大加快访问速度。 这个搬运的过程是由Cache Controler(缓存控制器) 来完成的
缓存工作原理 局部性原理,复杂的程序都是存储在相邻空间的 采用了SRAM 命中率是衡量缓存优劣的 缓存与主存的比例一般是4:1000,例如:缓存是128K对应主存32M
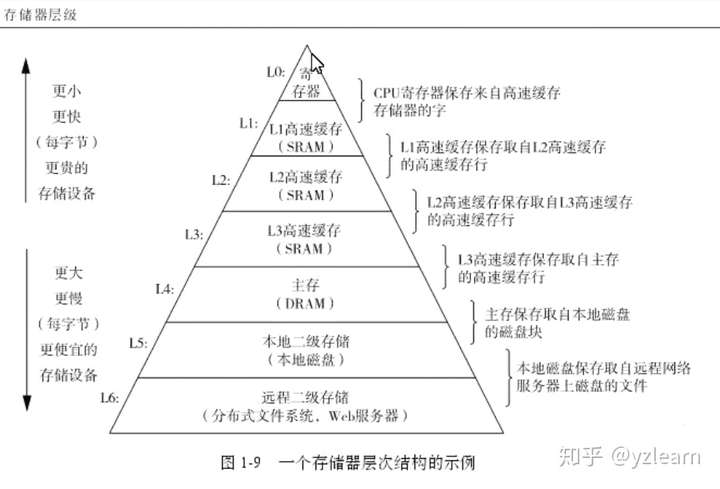
内存层级 随着内存增大,命中率会下降,所以需要加入二级缓存 二级缓存可以更大,既可以在片内也可以在片外 也可以分为数据缓存DCache与指令缓存ICache 这是属于纵向划分,也可以进行横向划分,使用多块缓存
缓存搬移规则 分为直接映射缓存(Direct Mapped Cache)与联合缓存(Set-associative Cache)
直接映射缓存
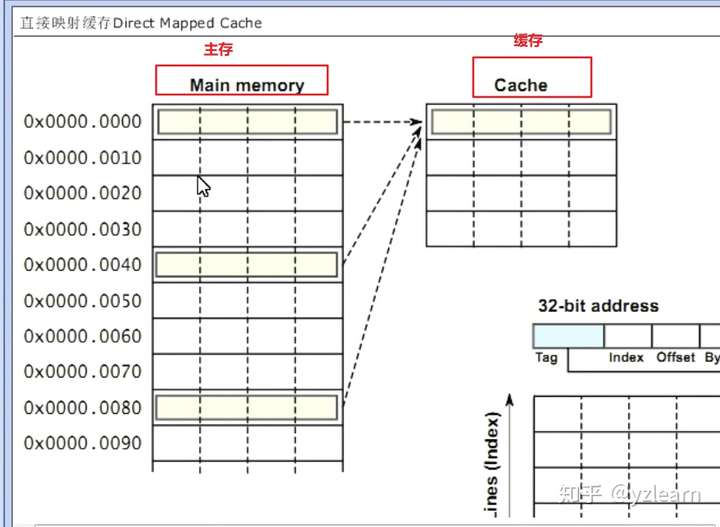
主存中的连续好多行直接对应到缓存中的一行,也就是多行对应一行 缓存中有tag与offset记录数据是从哪里搬移过来的 效率并不是特别高,适合缓存简单的情况,当数据在不同地方存放的时候,比较快速 以下面程序为例,可能两个数据都会被搬移到缓存的不同位置(如果命中率高的话)
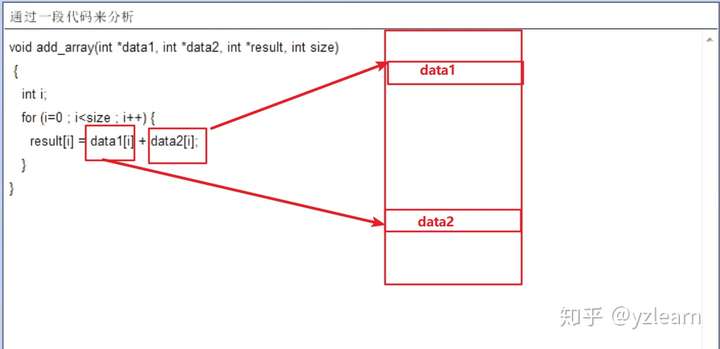
缓存是相对的,L1 是 L2 的缓存,L2是内存的缓存,内存是硬盘的缓存,以此类推,如下图所示 (此图来自深入理解计算机系统)
联合映射缓存

因为哈佛体系分为数据缓存与指令缓存 不能直接进行搬移,需要将数据与指令分离开 这个过程是由缓存控制器完成的,这个规则是由芯片决定的,需要查看芯片手册
缓存结构
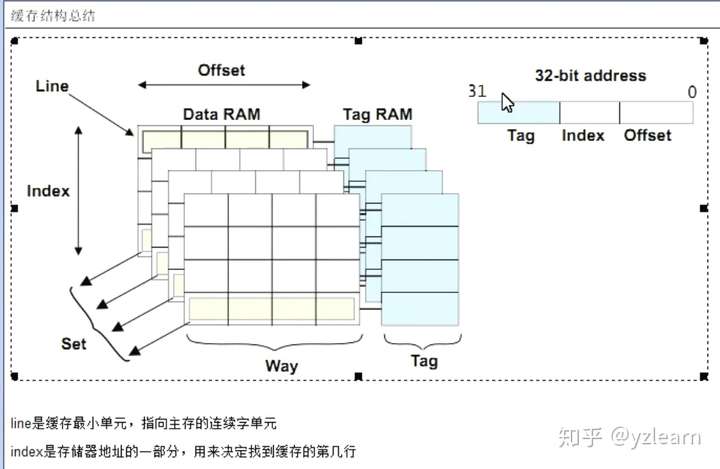
tag表明从哪里搬过来的
理解Cache,必须理解两个原则:局部性(时间与空间) 以及 层级原则
MMU
Memory Management Unit存储器管理单元 因为32位的cpu最大的寻址空间最大只有4G。 但有的程序需要较大的内存,另一方面不同进程内存之间需要隔绝 基于以上两个问题,所以提出虚拟存储器的概念 windows中有虚拟内存的设置(环境变量中)
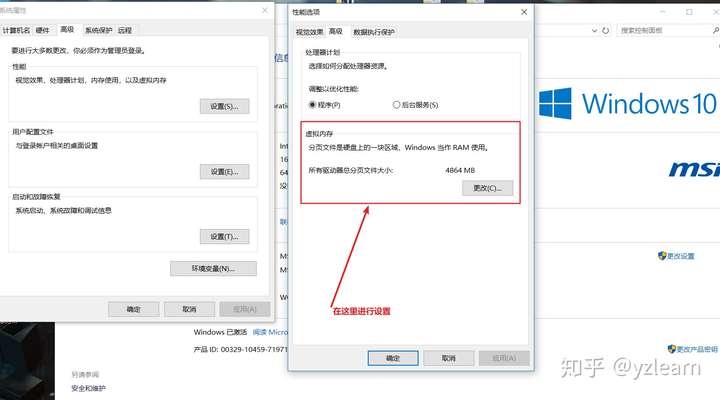
内存条太小的时候,磁盘可以拿出一块虚拟为内存,初始大小设置为安装内存的一半,最大值可以设置为安装内存的两倍。 内存中开辟一块空间作为硬盘的Cache,达到增大内存的目的 这跟之前提到的局部性有关。
虚拟存储器作用:
- 允许多个程序之间有效而安全的共享存储器
- 消除一个小而受限的主存容量对程序设计造成的影响
页: 内存空间中存储的最小单元,称为Page,或者称为bank(块) 再软件方面称为Page,硬件方面称为bank 每一页一般是4k-16k左右 每一页还会有行line,列offset 这与之前说的Cache联系在一起 每个页类似于表状的一个结构 多个页组成段,多个段组成存储空间
命中率: 虚拟内存也存在命中率,如果没有找到对应的物理内存的页,称为缺页 因为存储的时候是按页存储的
页保护与锁定机制来保证不同程序之间数据不冲突
分段: 代码段,数据段,bss段等 按功能将内存进行分段,物理内存也进行分段 统一只会使用这一段的页,不会使用其他段的页,所以就更加结构化,更加合理。 MMU有一个寄存器专门 记录物理地址映射的首地址
怎么根据虚拟地址找到物理地址? 在物理内存中开辟一段空间,称为(index)索引,相当于一个键值对哈希表 一个虚拟地址对应一个物理地址,称为Page table (页表) MMU有一个页表寄存器,专门存放页表所在位置
当缺页(找不到对应的物理内存)的时候,则把控制权交给操作系统,操作系统去磁盘取数据
加快地址转换(TLB)(也相当于一个缓存)是为了更快的找到对应的物理地址,类似于树形的结构,层层往下查找,直到找到虚拟内存对应的物理内存, TLB相当于把哈希表拆分,将若干次查询简化。 当TLB找不到页的时候,控制权交给操作系统来解决缺页
所以,从虚拟地址找到一个物理地址过程如下: CPU -> MMU -> TLB ->Page Table-> 物理内存 逐步建立索引
虚拟内存地址不一定要比物理内存地址大
关于MMU,虚拟内存,Cache相关的看上面提到的 ARM 编程手册

 浙公网安备 33010602011771号
浙公网安备 33010602011771号