

关于为什么使用 ASCII GBK Unicode编码
关于为什么使用 ASCII GBK Unicode编码#
由来:大家都知道计算机最早是美国人为了更加便捷的存储和计算数据发明的,但是呢计算机底层都是硬件,只能存储像0101这样的二进制数据,那美国人为了让计算机能够存储他们所使用的字符(字母,数字,标点符号,特殊字符等),他们就对这些字符进行了编号,从0 开始一直到127,一共128个字符。 比如字符0的十进制编码就是48,字符a的十进制编码是97,字符A十进制编码为65。我们把这些字符称之为码点,可以理解为是字符的唯一标识,那么这一套码点下来,也就组成了一个字符集,就是我们使用ascii字符集。
ASCII(美国信息交换标准代码)#
接着上面说,但是上面的十进制字符集还是不能在计算机中进行存储,所以美国人对这些码点进行了编码,直接把这些码点转成了他们对应的二进制形式,也就是7 位01组合 'xxxxxxx' ,但是这样就不能满足计算机的最小01组合(计算机的最小存储单元就是1byte 8位01组合 ),所以在这些码点的二进制前面补了一位0,正好变成了1字节用来表述字符。
标准的ASCII使用一个字节存储一个字符,首位是 0 (0 被当作标识符),总共可以表示128个字符,这些对美国人来说完全是够用了
ascii编码形式:0xxxxxxx
GBK(汉字内码扩展规范)#
接着上面说,随着计算机普及和发展,我们中国人也开始使用计算机。那么当我们中国人看到这个ASCII字符表的时候,只说了一句话,emmm,"还不够我塞牙缝的!" ,这是由于我们的字符实在是太多了,ASCII没有办法再包含我们的字符,所以我们中国人就自己研发了一种新的GBK编码,叫做 汉字编码字符集。
GBK字符集包含二万多个汉字等字符,GBK一个中文字符编码是以两个字节的形式存储。
注意:这里需要注意GBK字符集是需要去兼容ascii的。
GBK编码后的形式:1xxxxxxx xxxxxxxx 十五位 32768个字符,其中有二万多个汉字字符
那么在GBK中,英文字符和汉字在计算机中如何进行解码。比如:你h啊
编码之后:xxxxxxxx xxxxxxxx|0xxxxxxx|xxxxxxxx xxxxxxxx
那么计算机在对底层的01比特解码的时候如何去识别汉字和字母的编码呢??
这里规定汉字的第一个字节的第一位必须是 1 ,ascii字节是第一位是0 ,那么计算机在解码时就会根据字节的首位去判断,当字节的第一位是1之后,就知道接下来的15位01比特表示了一个汉字,当字节的第一位是0时,就知道接下来的7位01比特表示一个ascii中的一个字符。
Unicode字符集(统一码,也叫万国码)#
接着上面说,当我们中国人看到ascii字符集无法表示中国汉字,就研发了GBK,那么当世界上其他国家也为他们的语言进行编码之后,就会出现各种各样的字符集编码。 这样的话,当计算机在世界流通,信息交换的时候,就会很麻烦。比如:当我们把用GBK编码的字符发给美国,美国人用ascii编码打开的时候,就会产生乱码,无法解析我们的内容。
此时国际组织就站出来了,并且搞了一套全世界通用的字符集编码unicode,也就是最早的是UTF-32 ,并且国际组织,呼吁各个国家使用unicode编码,这样就可以解决交流不通的问题了。
//utf-32
Unicode是国际组织制定的编码,可以容纳世界上所有的文字,符号的字符集
最早的 UTF-32
用4个字节表示32位表示一个字符,当初这样设计的思想就是有容乃大(2^32足矣表示世界上的所以文字,想法很狂野,但不现实)
但是这样以32位编码的字符集并不被其他国家所认可,大家都认为这种编码方案过太于"奢侈!" ,因为四个字节表示一个字符的编码方式,占用存储空间,并且使通信效率变低。比如:我们要表示一个字母就是 xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx,那么这样的编码方案,最终没有被各个国家采用。
紧接着就诞生了 一个非常重要的 字符集编码 UTF-8 (目前我们在使用的编码一般都是这个编码,比我我们在使用编译器的时候默认就是使用utf-8)
UTF-8
utf-8 是Unicode字符集的一种编码方案,采取可变长编码方案,一共分为四个长度区 :1个字节,2个字节,3个字节,4个字节(按照需要去相应的使用)
那么英文字符、数字、汉字字符,在unicode中如何编码呢?
在unicode中英文字符、数字 只占用一个字节(兼容ascii),汉字占用三个字节。
比如:n好a 0xxxxxxx|1110xxxxx 10xxxxxx 10xxxxxx|0xxxxxxx
那么解码的时候如何区分呢?
这里规定的是,英文字符在进行存储的时候就是一个以 0 开头的字节,如果是两个字节存储时候,要求第一个字节是以110 第二个字节需要以10开头,以此类推,至此我要讲的编码原理就结束了。

注意1:我们程序员一般使用 utf-8编码
注意2:字符的编码解码需要使用同一种字符集,否则解码的时候会出现乱码的请
注意3: 英文和数字,一般不会乱码,因为很多字符都兼容了ascii编码
比如在pycharm编码的时候使用的就是 utf-8
测试:使用不兼容编码解析文本#
在pycharm中对 你h啊 进行解码(编码使用的是unicode--utf-8)#
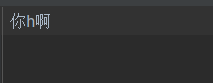
我们用ascii进行解码
出现提示,我们是否要用ascii解析Unicode编码
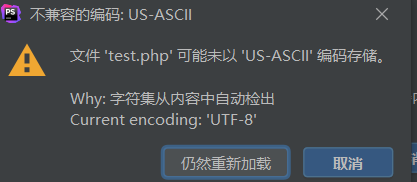
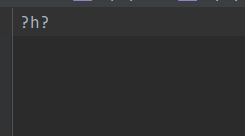
解析结果就出现了 ?h?,由于ascii不兼容Unicode编码,所以在解码的时候出现了乱码。在ctf比赛中因解析问题出现的 ?就是这个原因


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具