

现如今,只需一张图片和任意一段音频,AI技术就能帮你生成栩栩如生、高度仿真的视频。无论是让虚拟角色演唱歌曲,还是模仿名人发声,甚至是制作说唱音乐视频,AI都能帮你轻松实现。
令人惊叹的生成效果
你可以让虚拟人物如歌手般演唱

或是模仿马斯克的声音表演脱口秀

甚至让爱坤风格说唱

生成的视频不仅在视觉上令人惊艳,而且可以与动态短视频无缝衔接,满足多样化的创意需求。
真人视频照样拿捏


下面括号中的一段全是废话可以直接滑动到软件 获取指南
(随着虚拟人物概念的兴起和生成技术的迅速发展,将图像中的人物与音频进行同步变得越来越容易。然而,目前仍面临一些挑战,比如头部运动的不自然、面部表情的失真以及图像和视频中人物面部的一致性问题。为了应对这些问题,来自西安交通大学等机构的研究团队提出了一个名为SadTalker的模型。
SadTalker模型通过学习三维运动场中的3D运动系数,从音频生成头部姿势和面部表情,并利用创新的三维面部渲染器来实现自然的头部运动。
为了准确学习运动系数,研究人员显式建模了音频与不同类型运动系数之间的关联。他们设计了一种蒸馏系数和三维渲染的人脸模型,以从音频中捕捉精确的面部表情。此外,他们还设计了条件变分自编码器(PoseVAE),用于生成多样化的头部运动风格。最终,生成的三维运动系数被映射到无监督的三维关键点空间,用于人脸渲染和视频合成。
实验结果表明,SadTalker模型在运动同步和视频质量方面取得了最先进的成果,提供了一种通过人脸图像和语音音频生成生动人物头像视频的有效方法。
SadTalker语音驱动图像生成视频
算法架构
在虚拟人物创建、视频会议等多个领域中,通过语音音频使静态照片中的人物动态化是一项具有挑战性的任务。以往的研究多集中于生成唇部运动,因为唇部动作与语音联系紧密。虽然有些研究尝试生成其他人脸运动如头部姿势,但生成的视频质量仍然存在不自然的现象,比如不协调的姿势、模糊、身份误判和面部变形等问题。
另一种流行的方法是基于潜在空间的人脸动画,主要关注对话式人脸动画中特定类别的运动。然而,生成高质量视频仍然是一个难题。尽管三维面部模型包含高度解耦的表示,可以独立学习面部不同区域的运动轨迹,但依然可能产生不准确的表情和不自然的运动序列。
基于上述观察,研究团队提出了SadTalker系统。该系统通过隐式三维系数调制实现风格化音频驱动的视频生成。
)
获取指南
要开始使用这项技术,只需简单几步:
- 一键启动:无需复杂配置,解压下载包后直接点击 一键启动.exe,即可启动程序。
- 下载速度取决于您的网速,无需开通会员。

发送文字内容
前置条件
此工具专为 Windows 用户(Windows 10 及以上版本)设计,并且需要配备至少6GB显存的 NVIDIA 显卡。
- CUDA 版本: 11.3
- 你可以通过以下CMD命令检查当前安装的 CUDA 版本:
nvcc --version
或:
nvidia-smi
如发现 CUDA 版本低于 11.3,建议升级 CUDA 和/或 NVIDIA 驱动程序以确保兼容性。
使用步骤
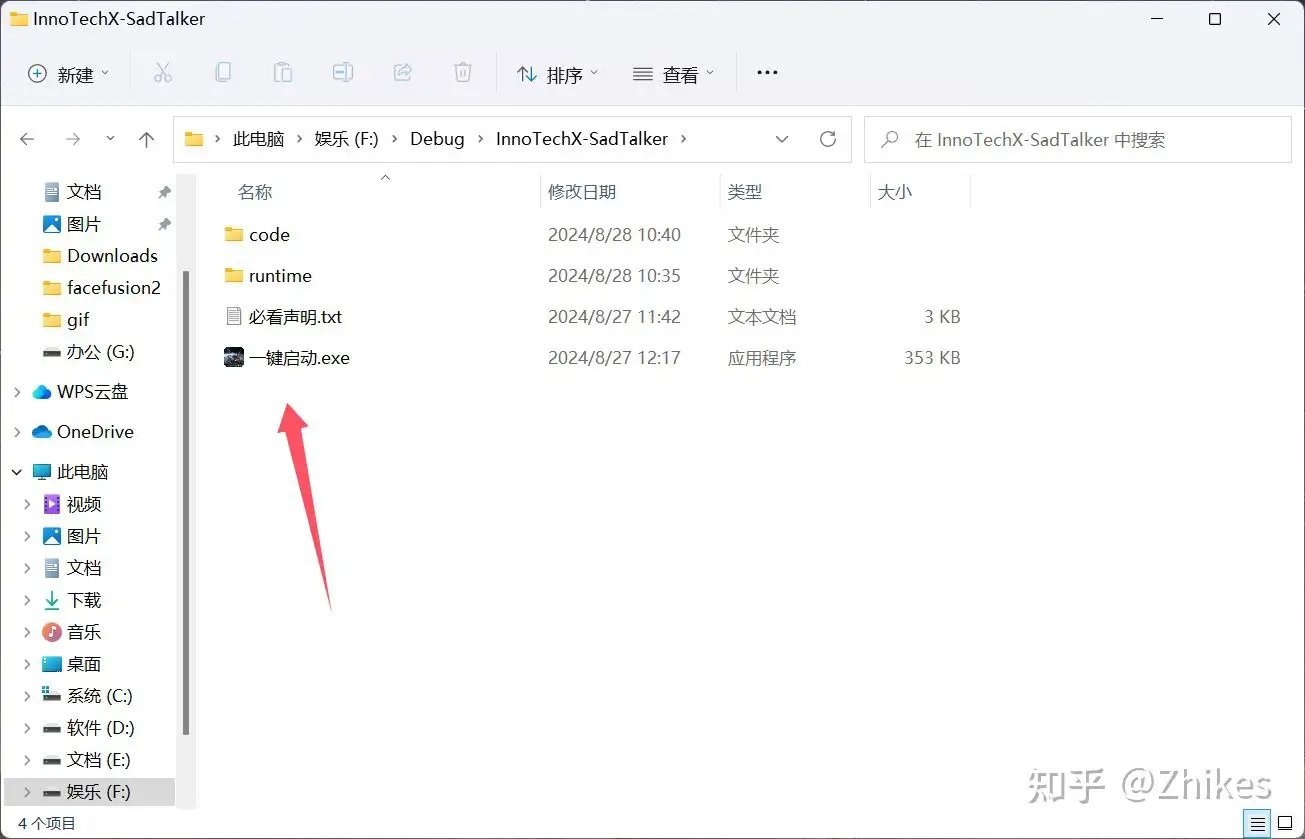
- 下载并解压整合包到本地目录。
- 进入目录后,点击 一键启动.exe 启动程序。
- 注意:程序运行期间,请勿关闭 CMD 命令窗口。
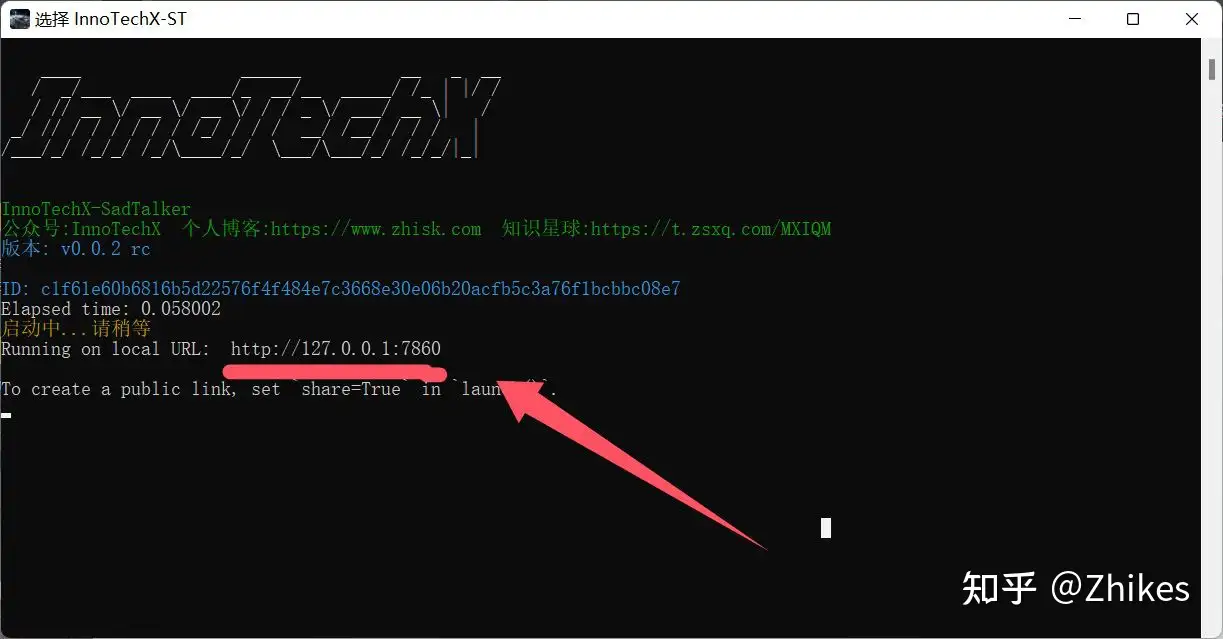
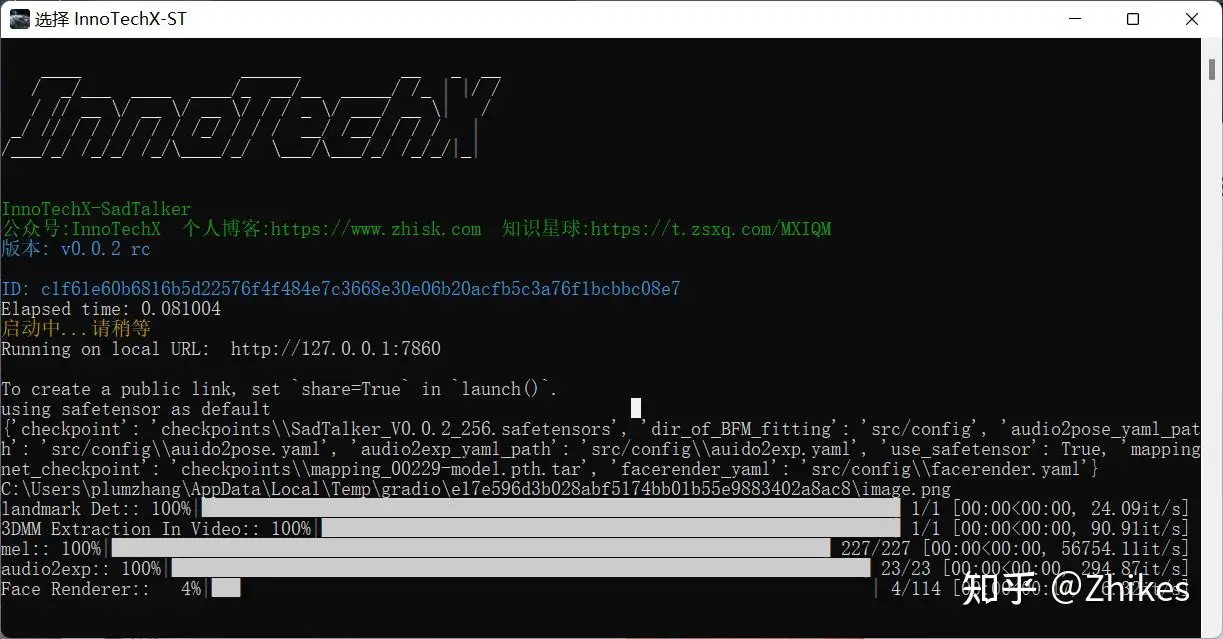
程序正常执行cmd输出
程序会自动弹出网页,如果没有,就自己手动输入 http://127.0.0.1:7860 到浏览器打开
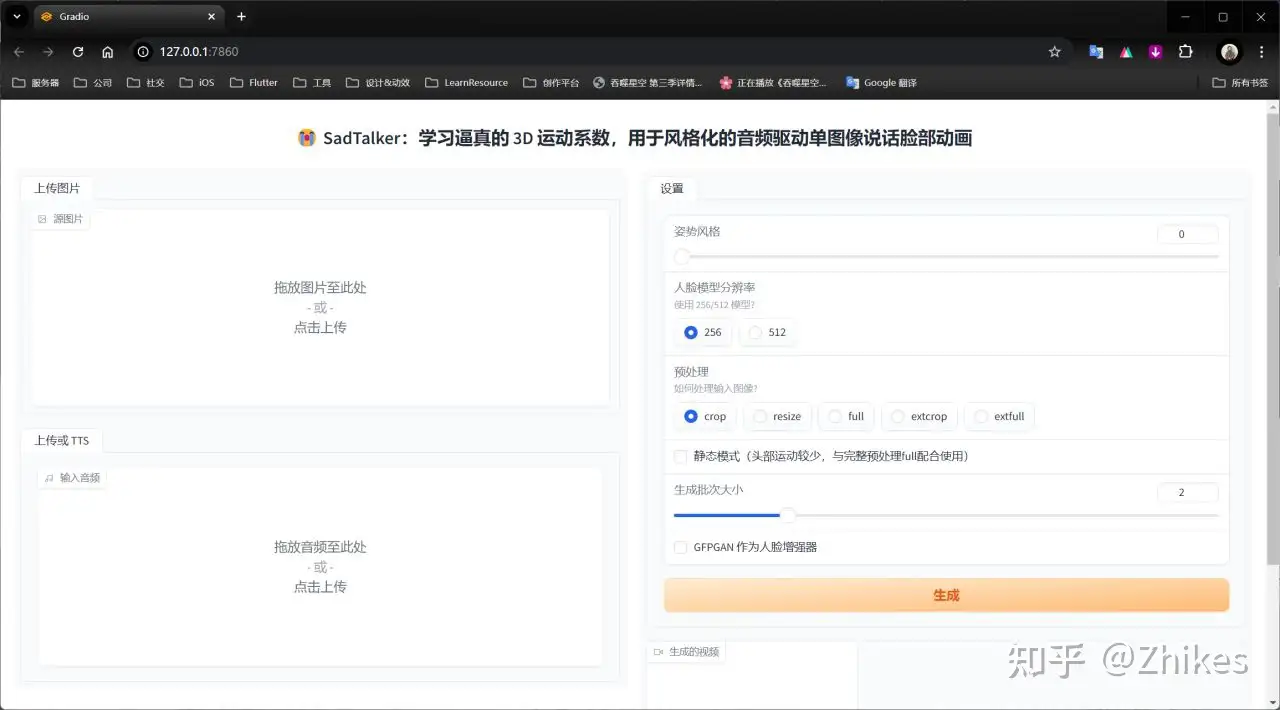
具体参数设置,如下图标注
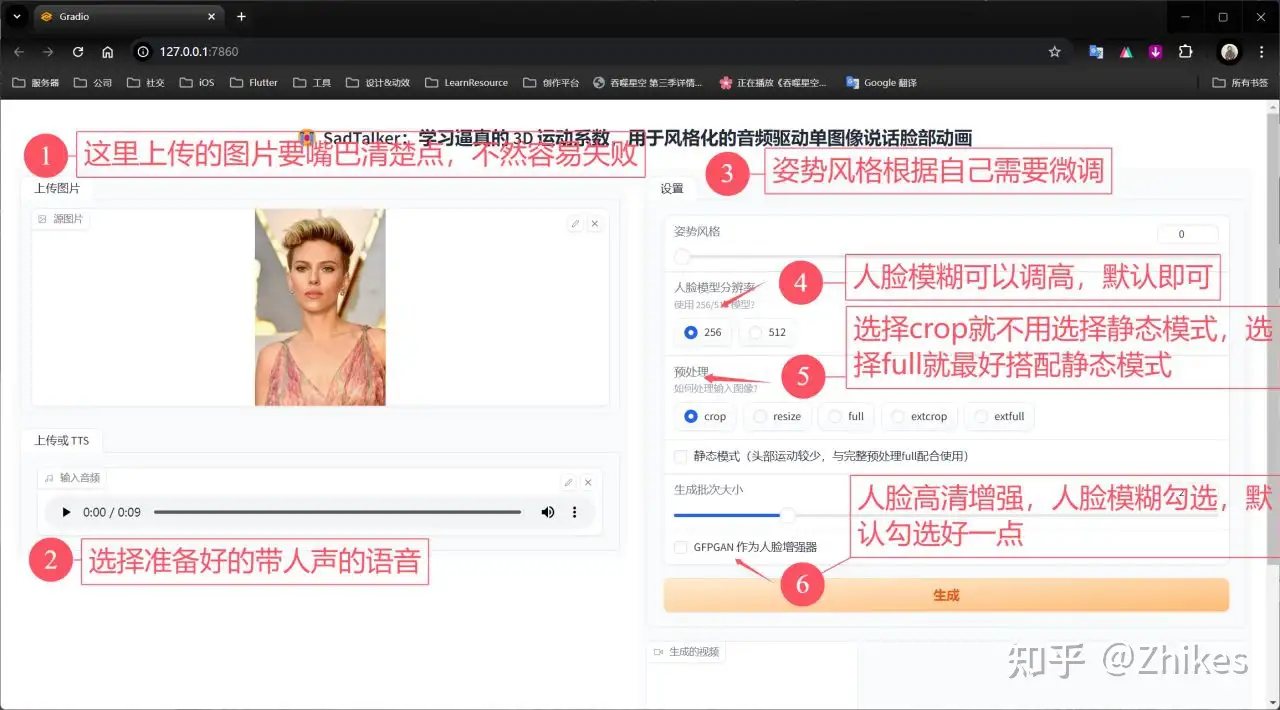
最后点击生成,可查看cmd输出进度。
稍作等待,便会生成视频结果。
好的,教程到此结束,谢谢大家的观看。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号