
新版本的GPT-SoVITS V2,带来了声音克隆技术的全新突破,无论是游戏角色还是现实明星,都能轻松实现声音定制。
游戏角色声音克隆

直面天命,最近黑神话悟空刷爆了各大平台,何不试试用GPT-SoVITS克隆悟空的声音?只需几步,你就能重现《大话西游》里那些令人难忘的经典台词!
[https://www.zhisk.com/wp-content/uploads/2024/08/heishenghua.mp3 播放MP3]
现实明星声音克隆
想象一下,每天早上都是你最喜欢的明星叫你起床。你准备好体验了吗?先来听听我的闹钟吧。
[https://www.zhisk.com/wp-content/uploads/2024/08/damimi.mp3 播放MP3]
听出来是谁在叫我起床了吗?没错,有了GPT-SoVITS V2,这一切都变得触手可及!只需提供一段简单的音频样本,再输入你想要她说的话,你也能拥有独一无二的声音体验。
心里是不是已经有了很多有趣的点子?赶快试试GPT-SoVITS V2,让你的创意变成现实吧!
GPT-SoVITS V2模型新特点(v2模型新特点)
(1)SoVITS:对低音质参考音频(尤其是来源于网络的高频严重缺失、听着很闷的音频)合成出来音质更好
SoVITS:提高了低质量参考音频(尤其是来自互联网的高频损失严重、声音低沉的音频)的合成质量。
(2)加大训练集到5k小时,零射击性能更好的音色基础
增加训练数据集:扩充至5k小时,增强零样本性能,使音色更加相似。
(3)增加2个语种,现在可训练5个语种之间相互跨语种合成(跨语种合成,指集、参考音频语种和需要合成的语种不同)
增加两种语言:现在支持五种语言之间的跨语言合成(跨语言合成意味着训练数据集、参考音频语言和要合成的语言都可以不同)。
(4)更好的文本前端:持续迭代更新。v2中英文加入了多音字优化。
改进的文本前端:持续更新。对于 v2,中文和英文已针对多音字符进行了优化。
获取指南:
- 一键整合包获取:关注公众好 InnoTechX,发送 “gsv” 获取。
- 一键启动,不用配置复杂环境。
- 下载不用开会员、取决你的网速
前置条件:
- 适用于 Windows 用户(Windows 10 及以上版本),英伟达显卡6G及以上。
使用步骤:
- 下载解压包并解压到本地目录。
- 进入目录后,点击 go-webui.bat 即可启动程序。
注意:程序运行期间,请勿关闭 cmd 命令窗口。
TTS 推理一条龙:
一、音频处理(音频有背景音乐的需要处理,如果是干声直接跳过看第二步)
首先要处理音频,保证音频只有人声。有两种方式,使用次数少直接使用第一种方式
①使用在线网站处理 https://vocalremover.org/zh/
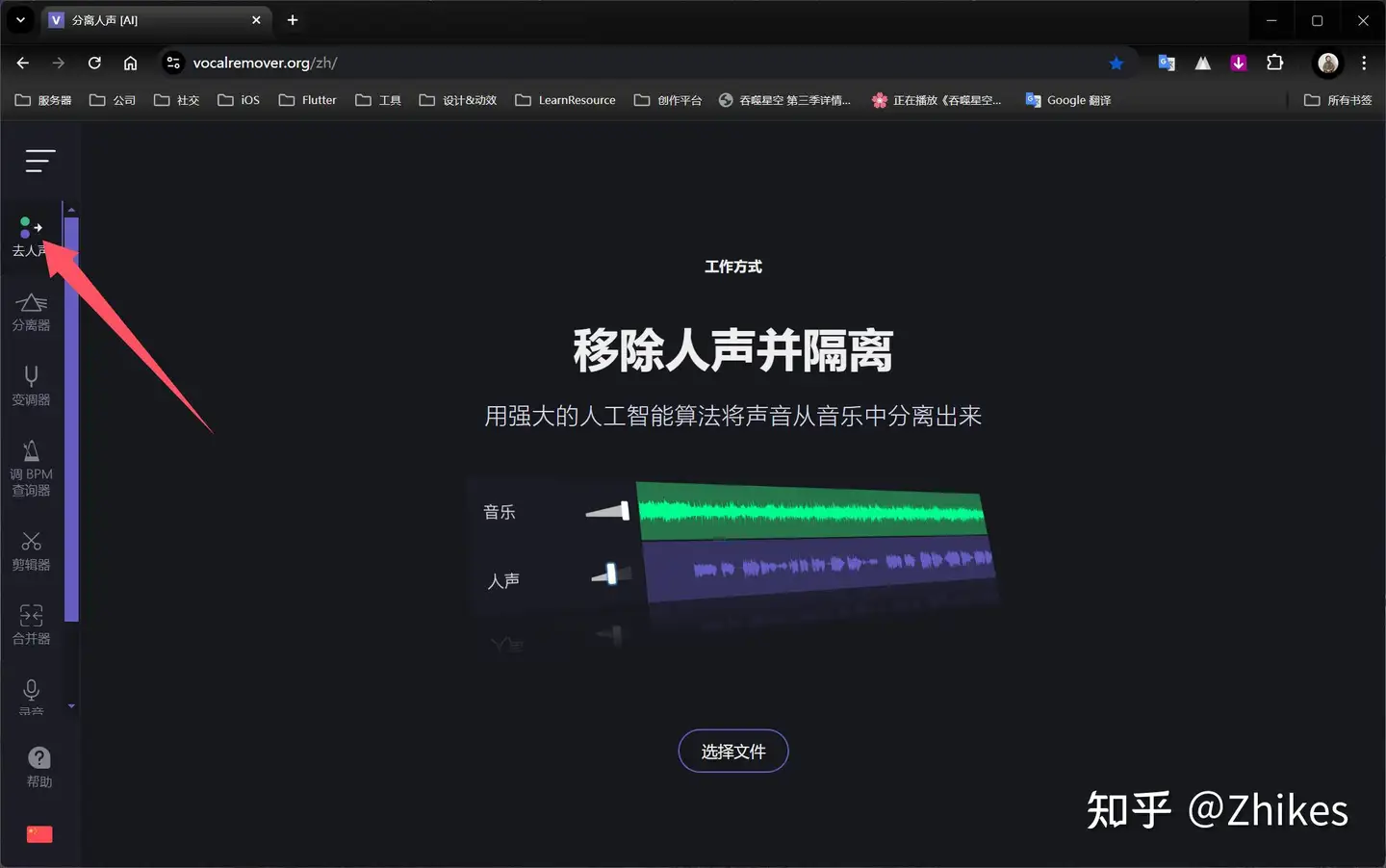
在去人声界面 选择音频文件上传
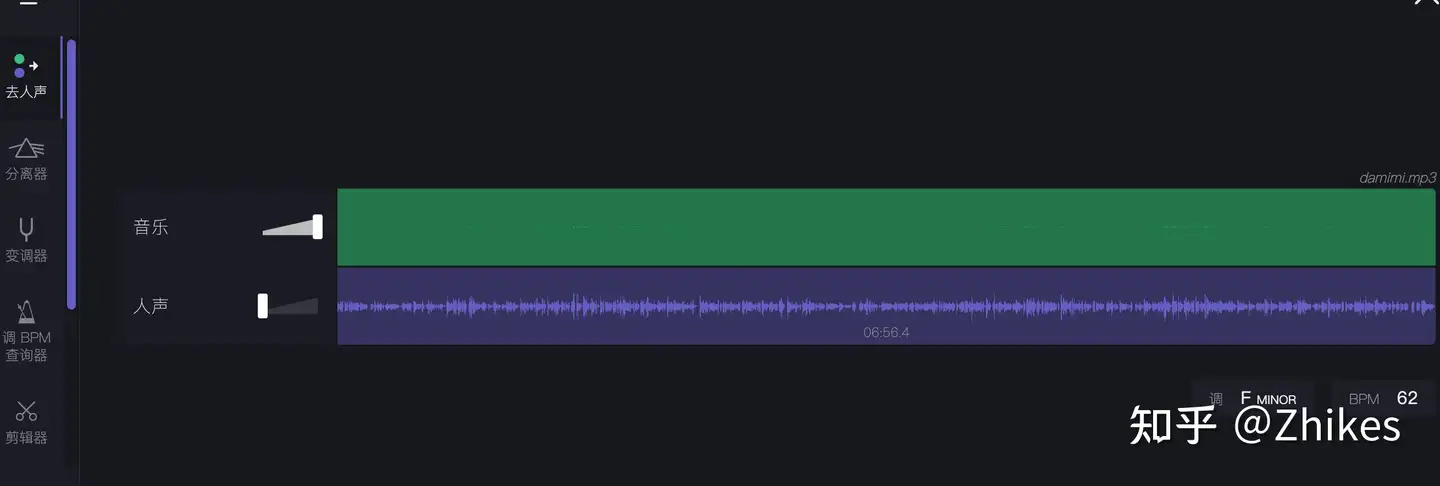
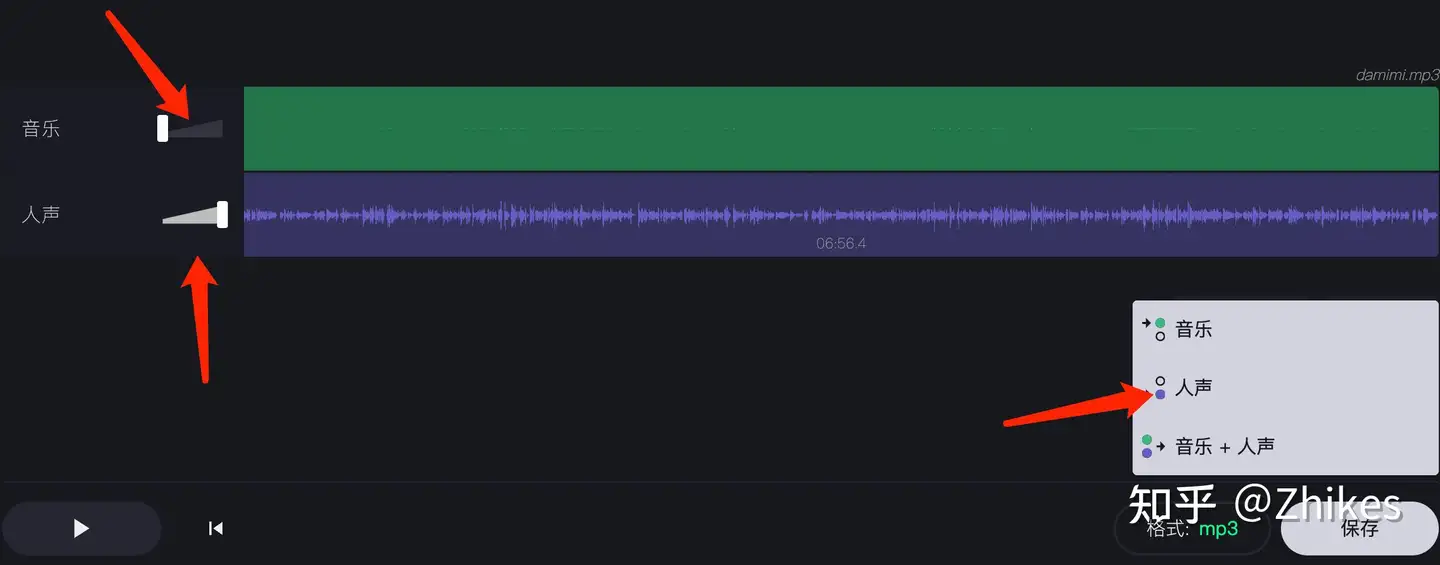
等待处理结束后,将音乐拉低,人声拉到最高,保存下载人声,即可进行第二步,无需再使用UVR5处理。这样直接获取比较纯净的人声
②使用GPT-SoVITS自带UVR5处理。(比较麻烦,如果使用次数少直接使用第一种方式)
1.点击 go-webui.bat 启动程序后,会有网页弹出
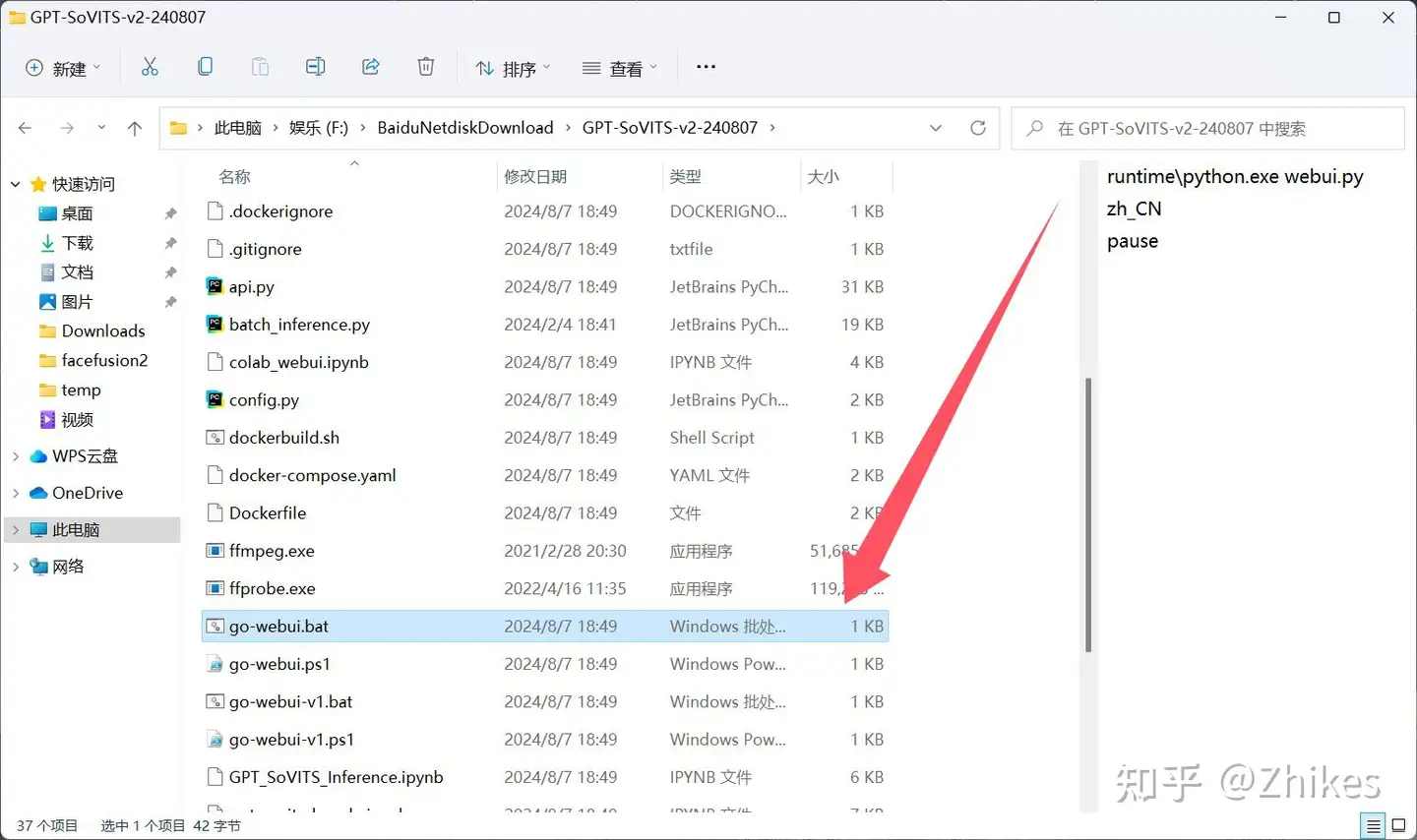
2.点击是否开启UVR5-WebUI,稍等查看cmd输出,没有报错,便会自动打开UVR5-WebUI网页
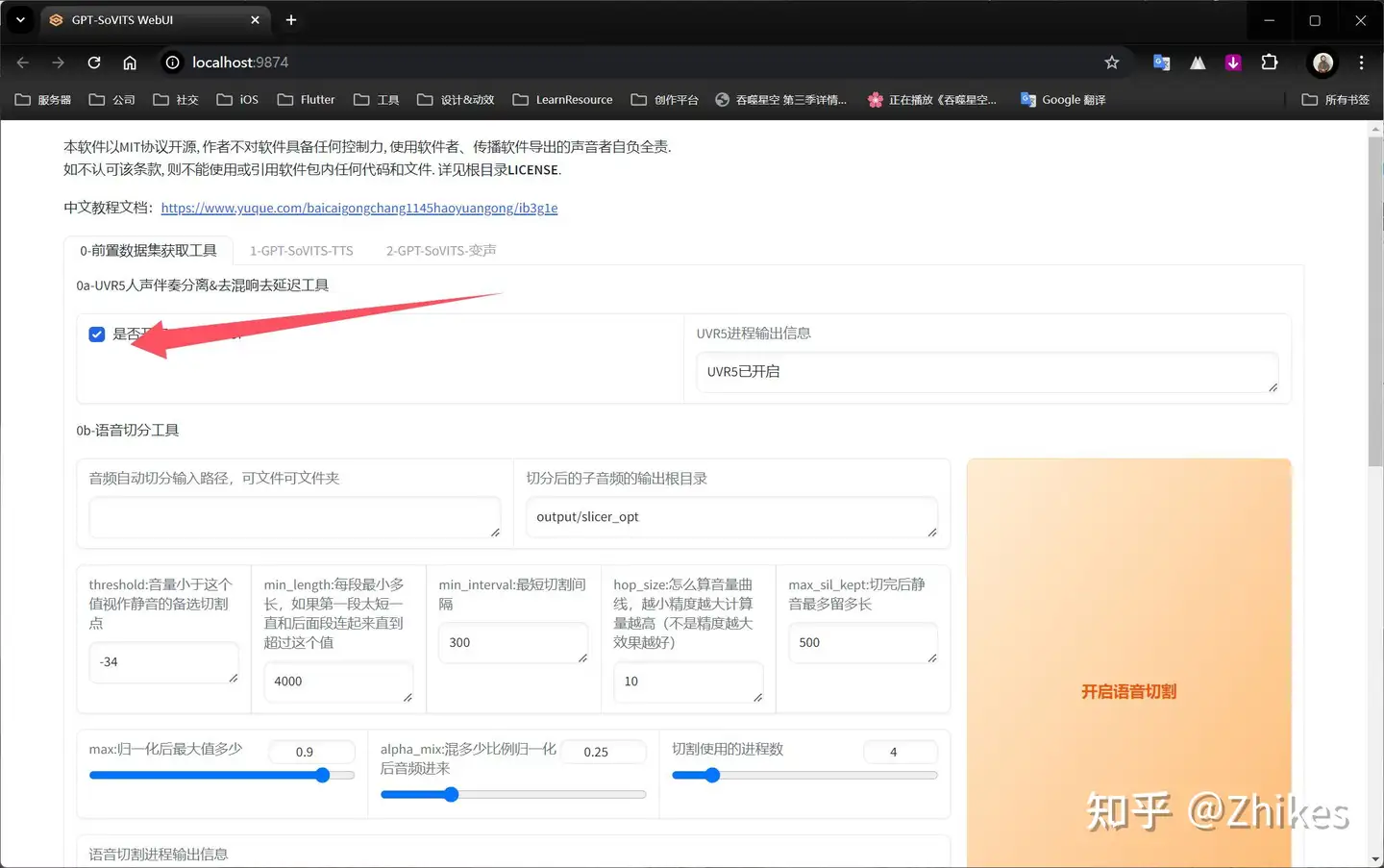
如果cmd窗口没有报错,但是浏览器没有弹出跳转,自己手动输入http://localhost:9873/ 到浏览器跳转
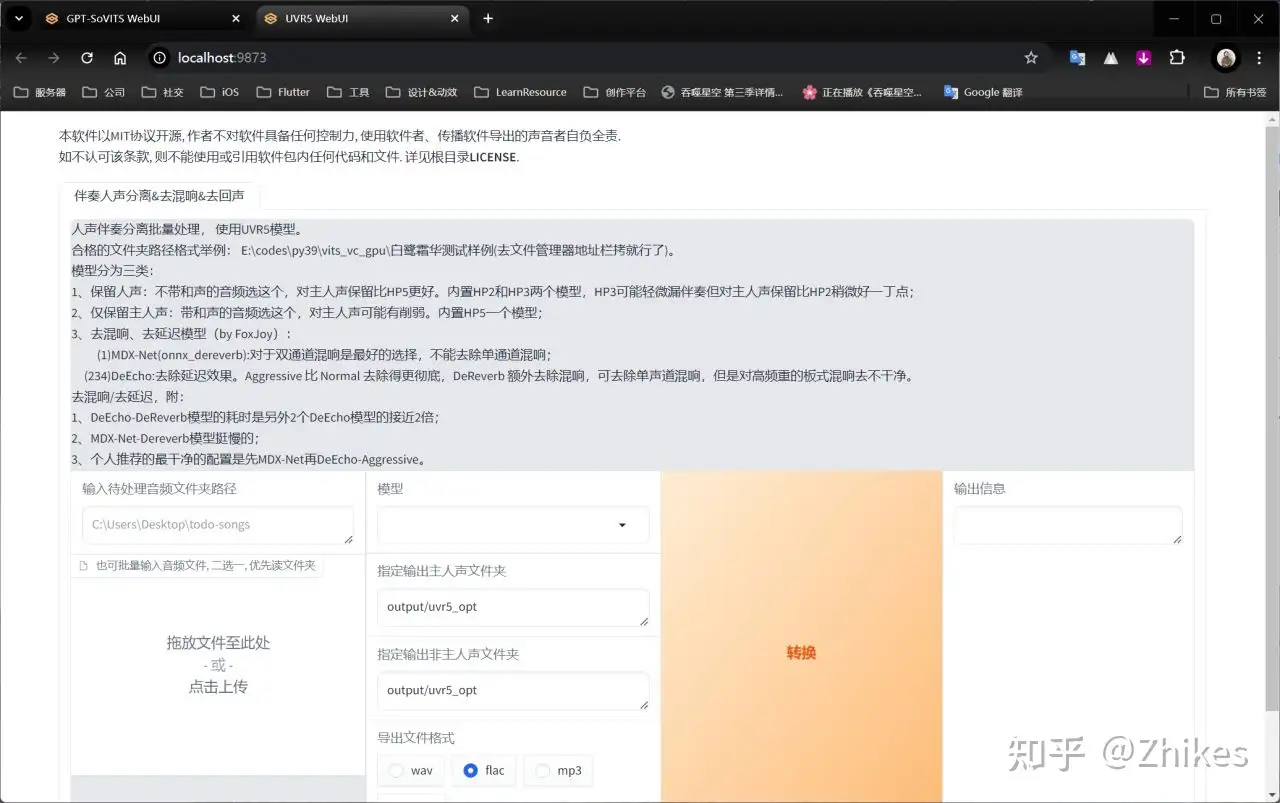
3.将自己准备好的音频文件的路径输入到路径输入框,或者直接拖拽到选择框
选择HP2_all_vocals处理,点击转换,等待处理完成
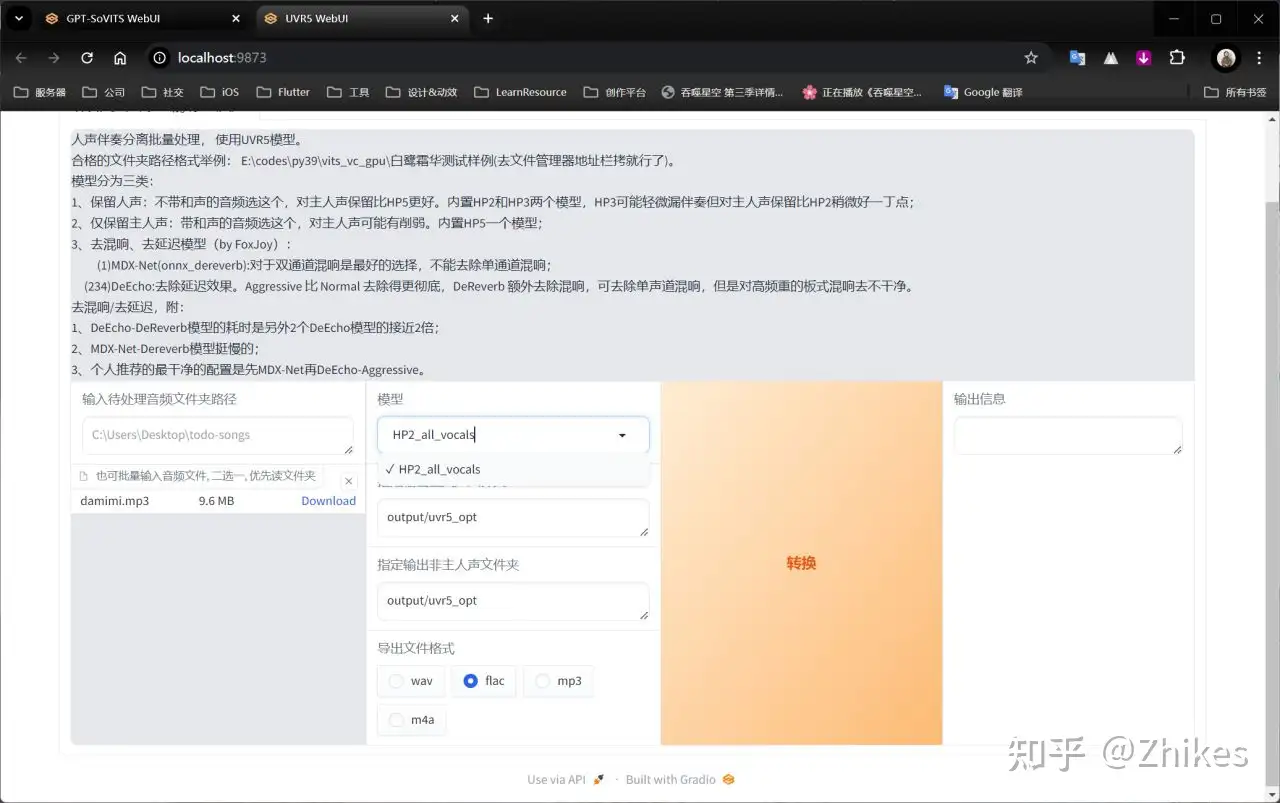
4.处理完后在输出目录会多两个文件,再次进行onnx_dereverb处理。将vocal开头的文件拖到文件选择框,选择onnx_dereverb处理
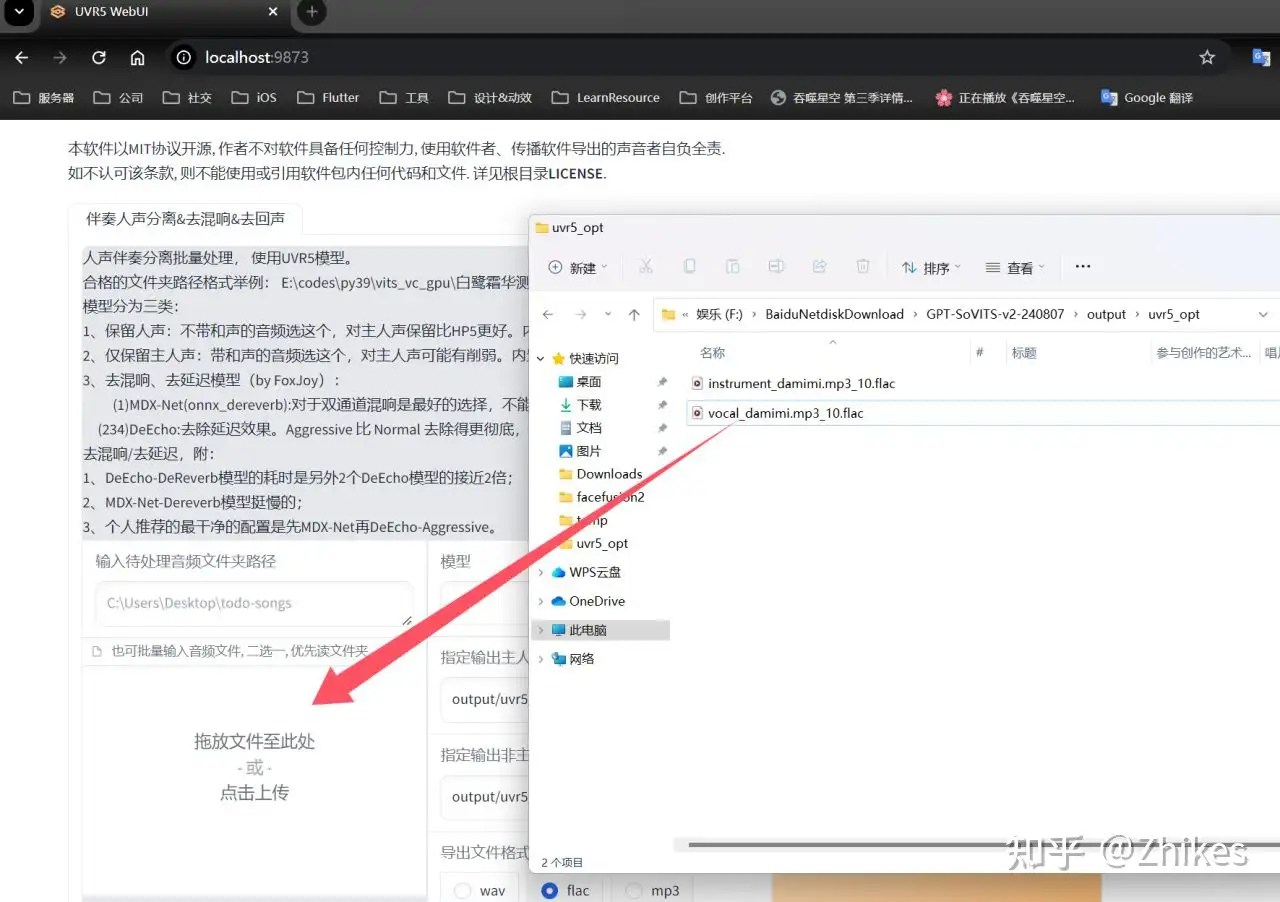
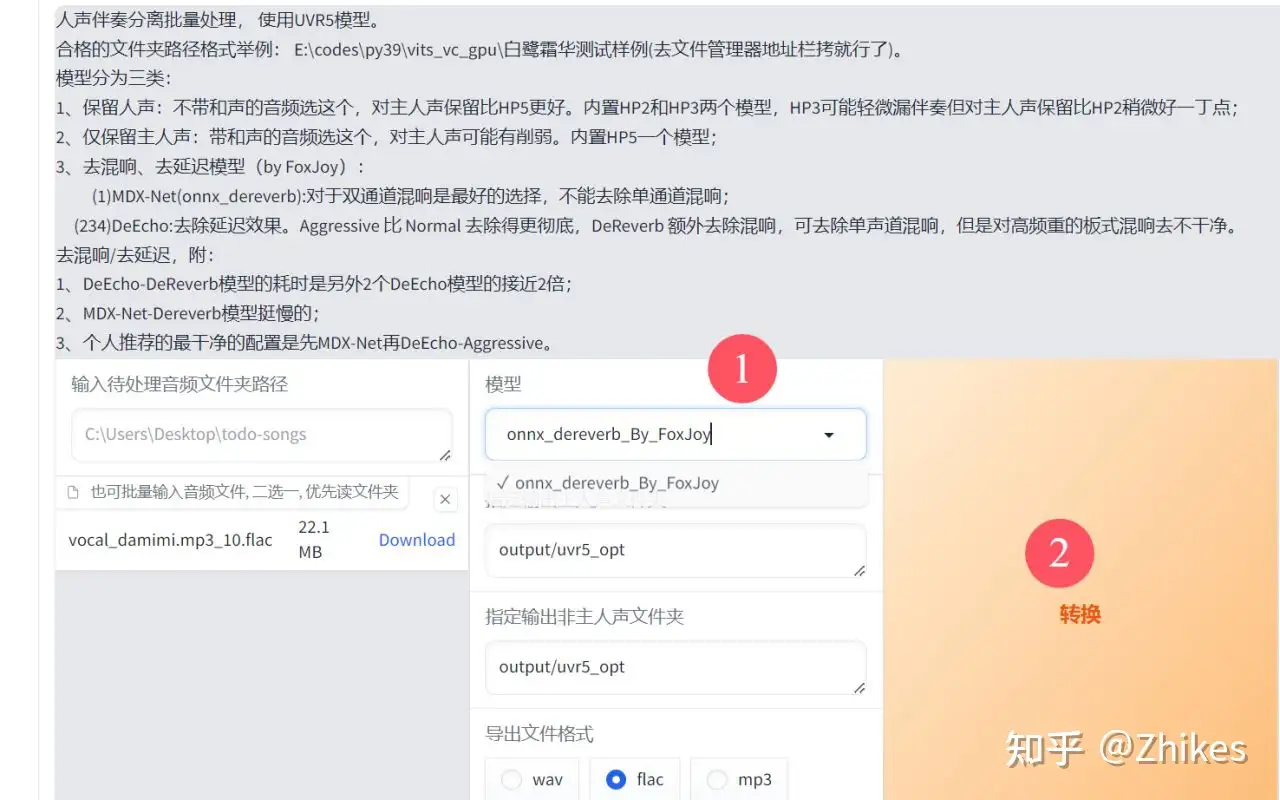
处理过程中,可能会卡住,比如我使用时在33%进度卡主,需要关掉cmd命令窗口,重新按之前步骤打开UVR5,继续把上面图片标注的文件拖进来重新处理
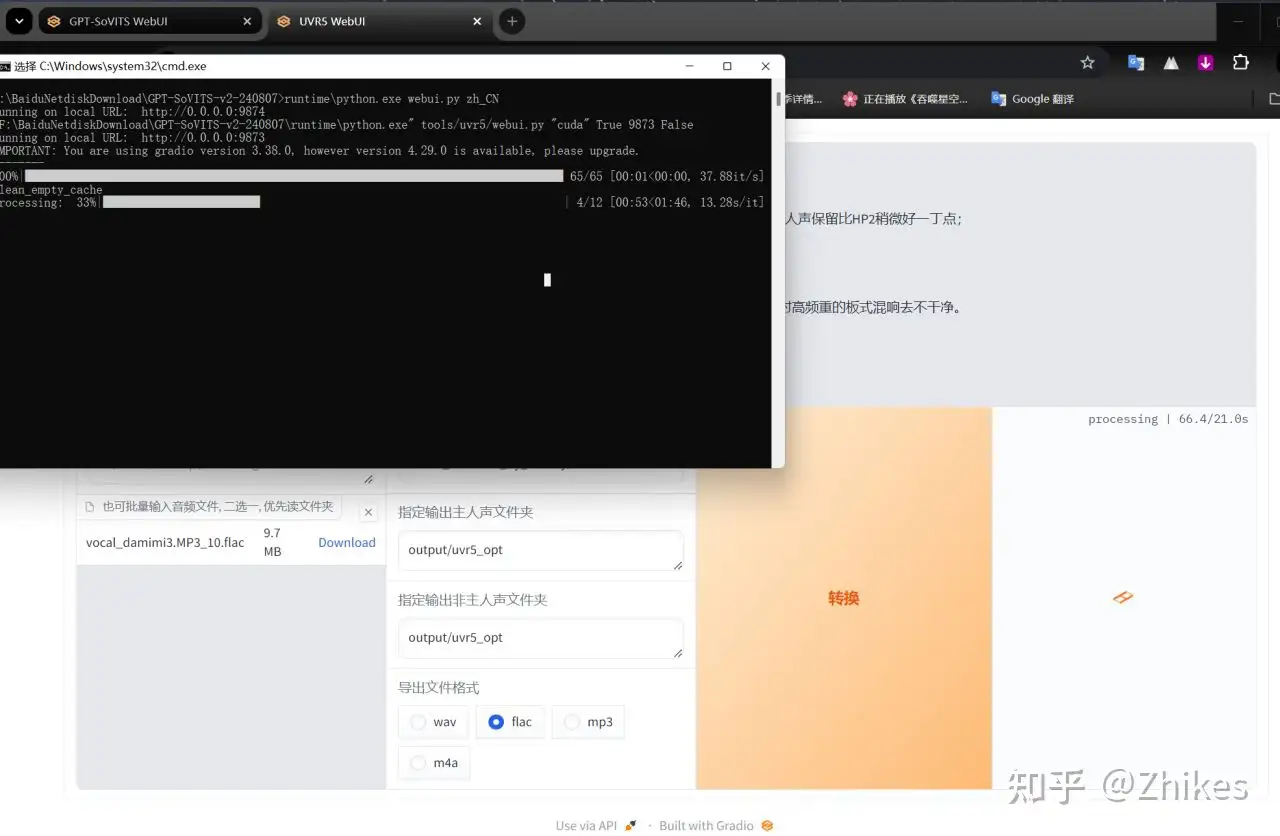
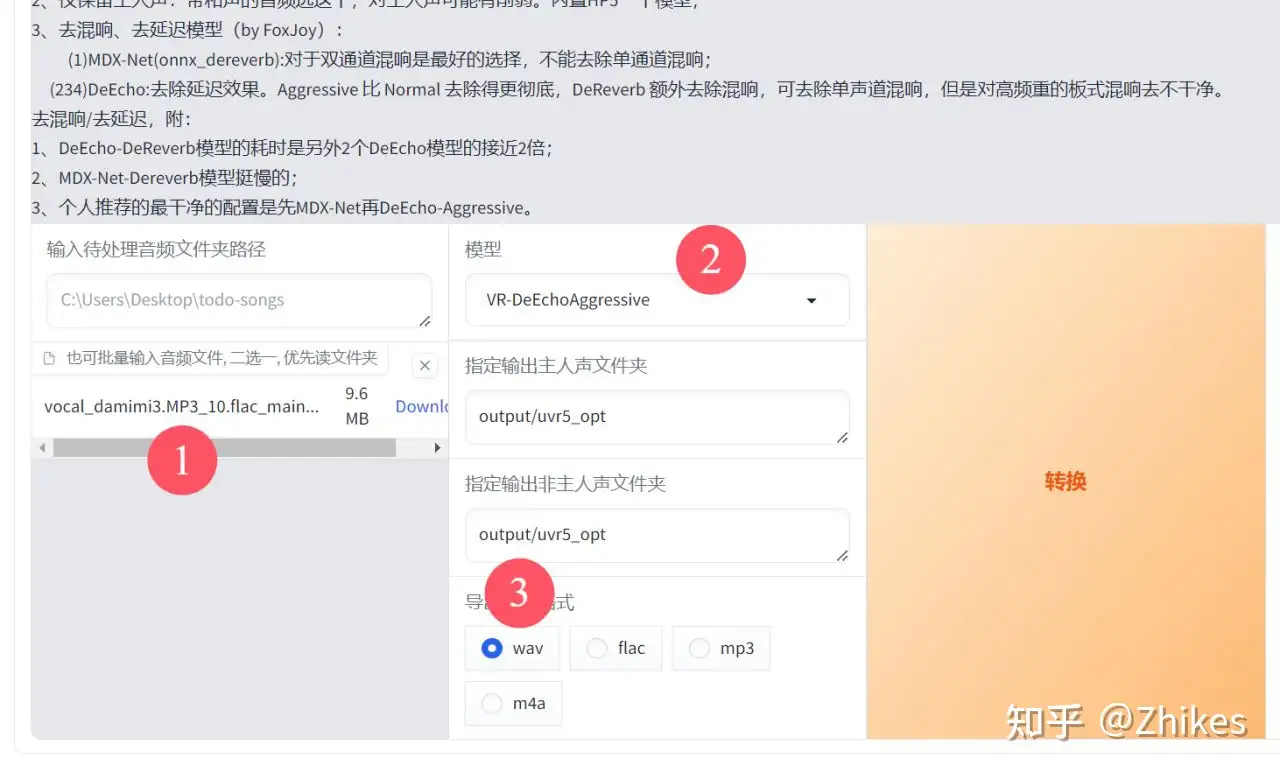
5.处理完后在输出目录又会多两个文件,再次进行VR-DeEcho-Aggressive处理。将后缀是flac_main_vocal.flac拖到文件选择框,下图已经标注,选择VR-DeEcho-Aggressive处理,导出文件格式 现在需要更改一下,不然等下难得找到,这里选择wav,不再是之前的flac格式
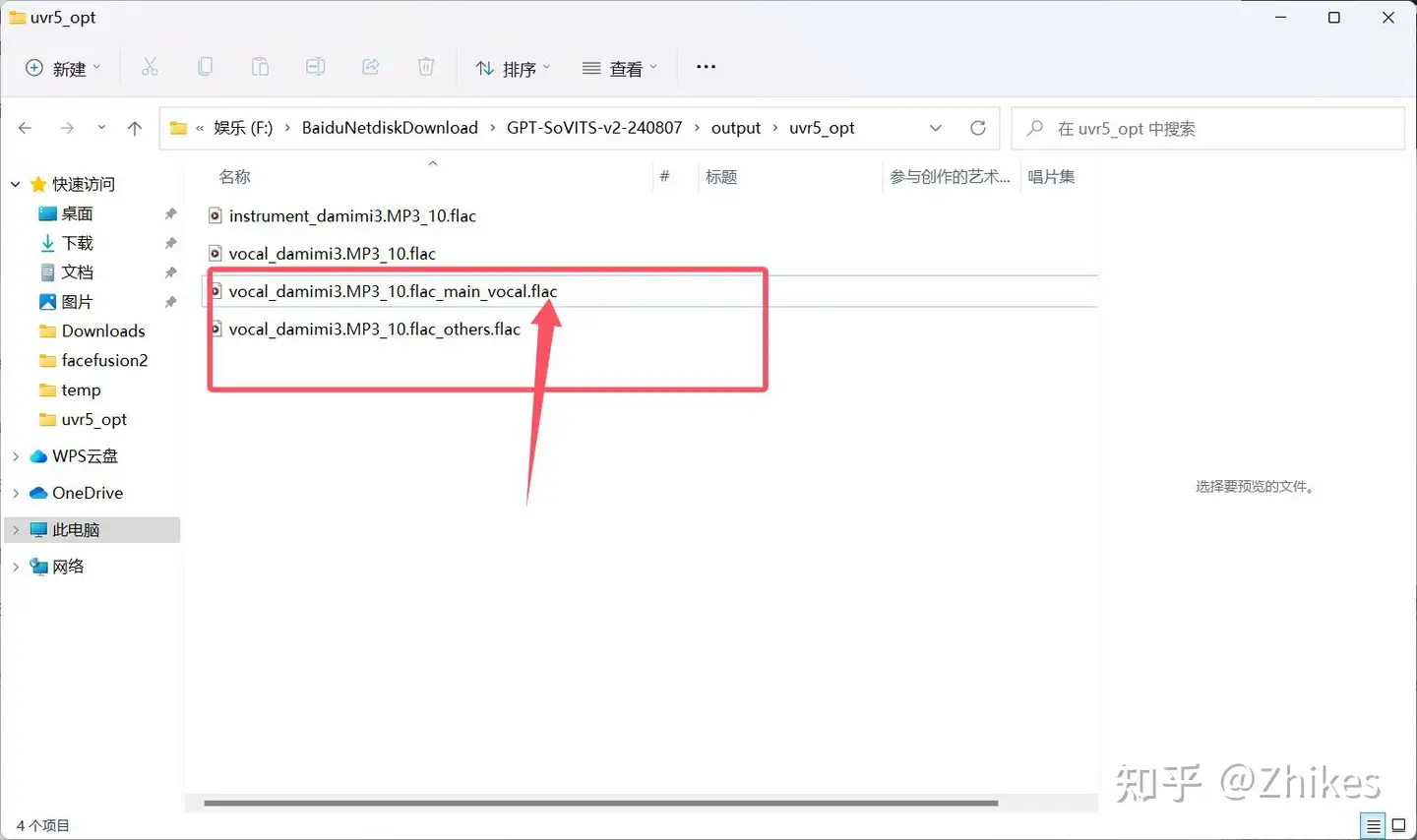
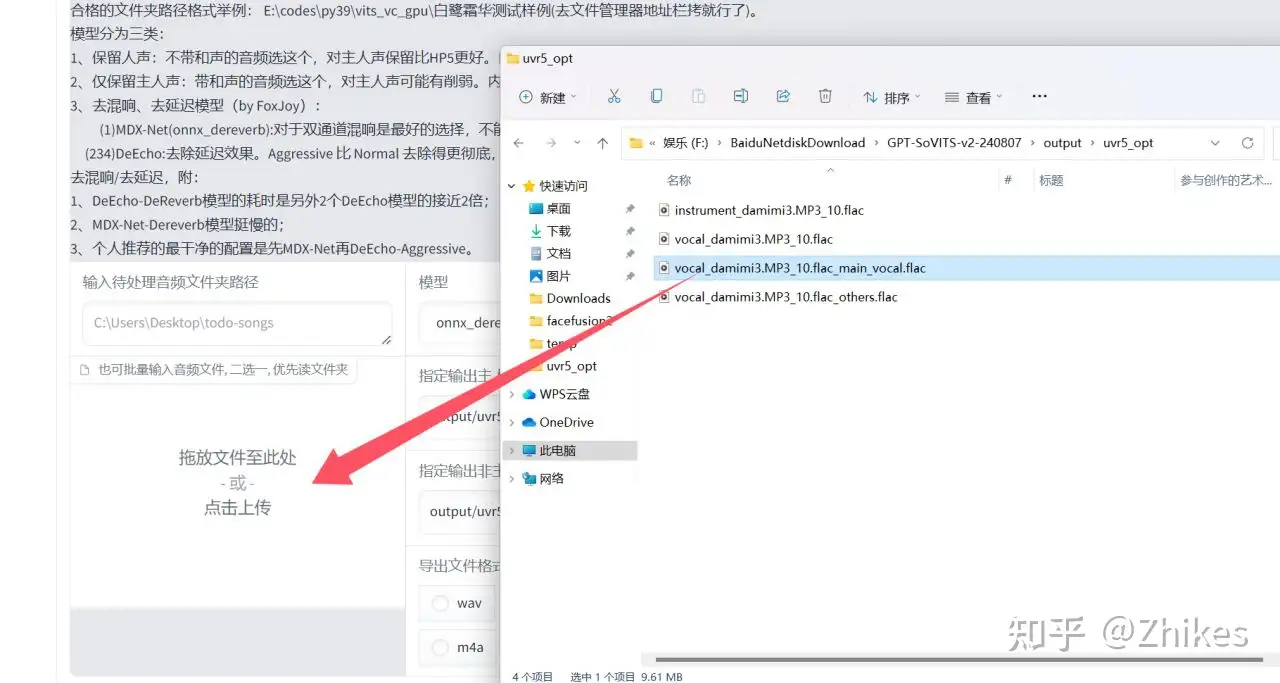
最后得到的这个文件,就是我们要使用的比较纯净的人声音频文件
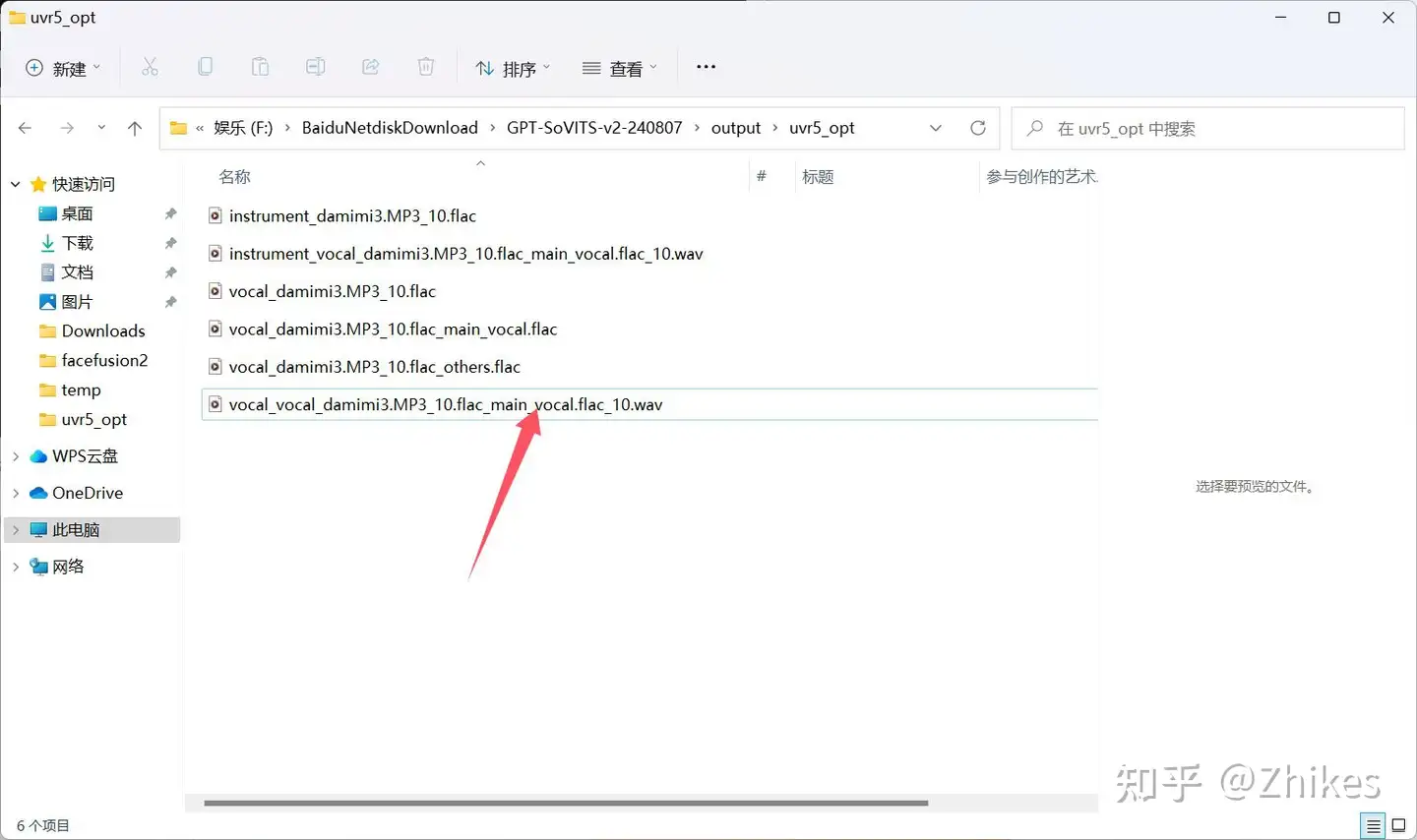
UVR5处理有点复杂,还是建议使用步骤①
二、语音切分
1.U回到之前的界面,也就是 http://localhost:9874/,勾选掉之前的UVR5处理,节省点显存
2.输入之前的音频文件目录,修改切分后的根目录,建议加入子目录。
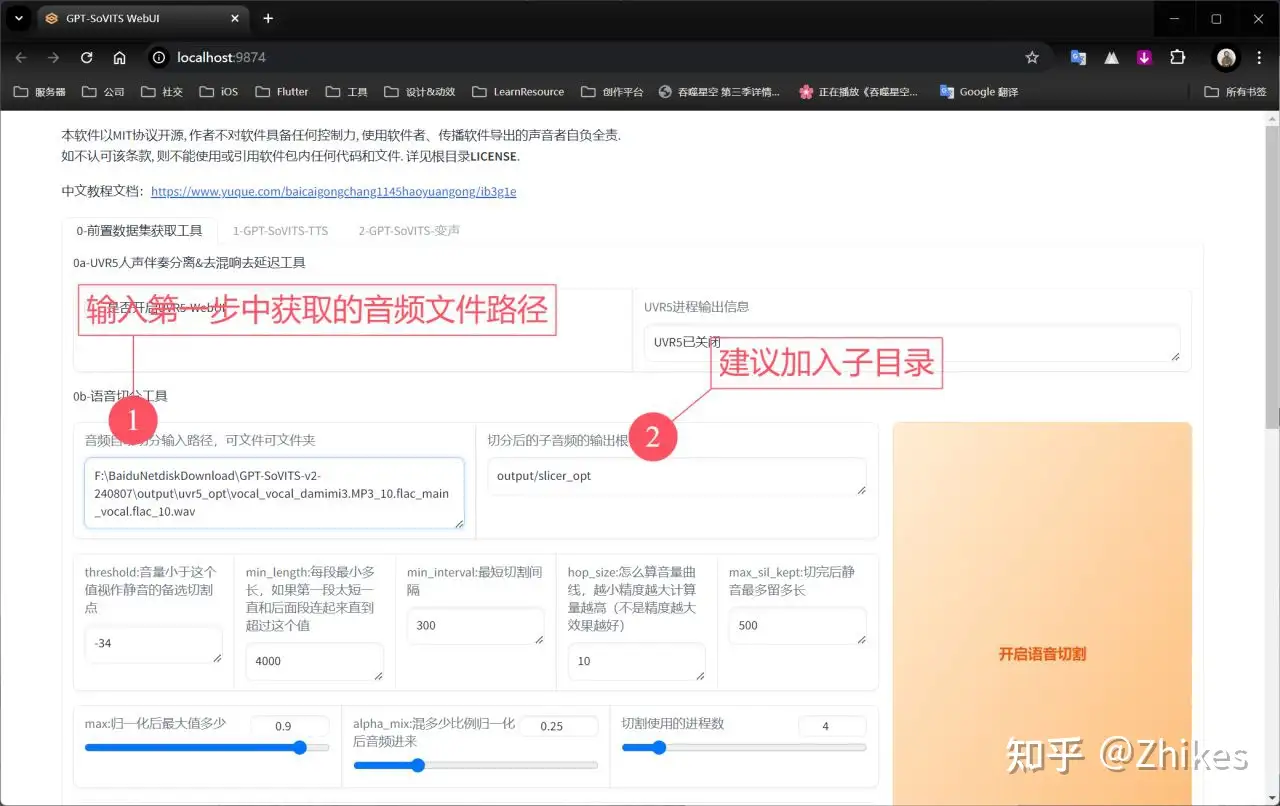
比如我在slicer_opt后面加入damimi子目录
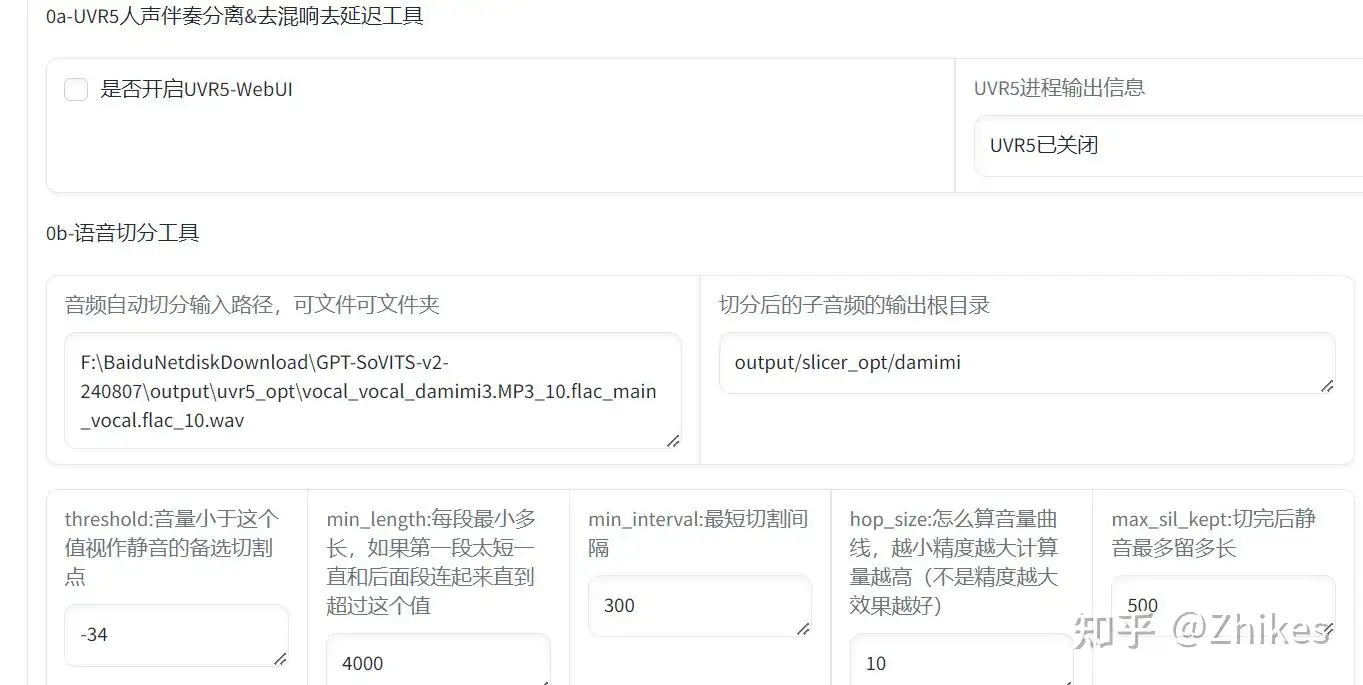
这里的其他参数基本可以不做修改,点击 开始语音切割,在设置好的输出目录就可以看到切分好的音频文件。
三、语音打标
打标就是给每个音频配上文字,这样才能让AI学习到每个字该怎么读。这里的标指的是标注
1.先对声音进行识别,生成对印的文本内容。
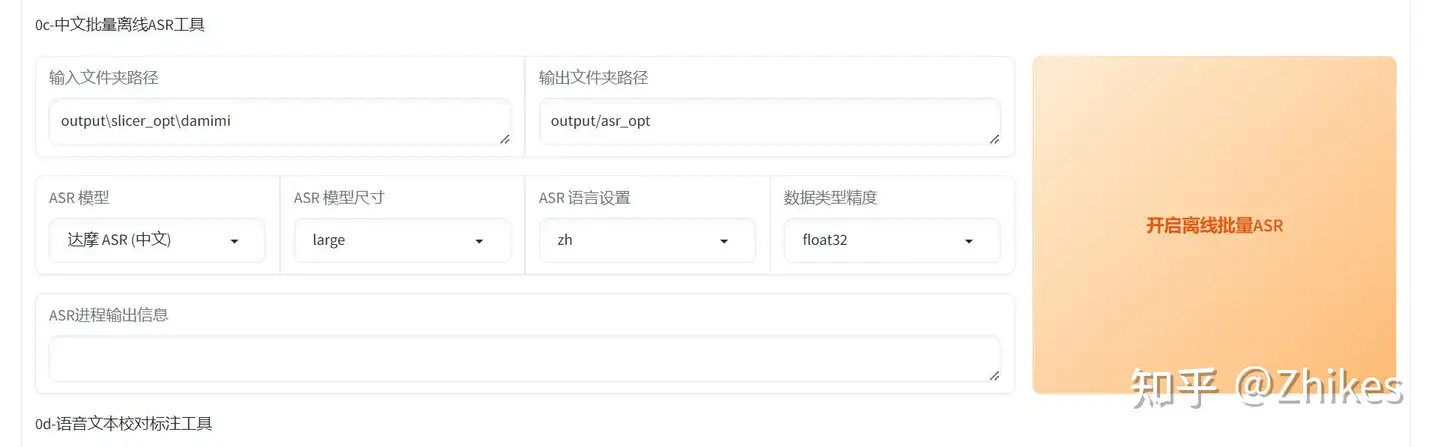
这里的 输入文件夹路径 需要修改成第二步中的语音分段路径,你的要填入你对应的全路径。ASR模型,是中文就选择中文,是其他语言选择Whisper多语种即可。
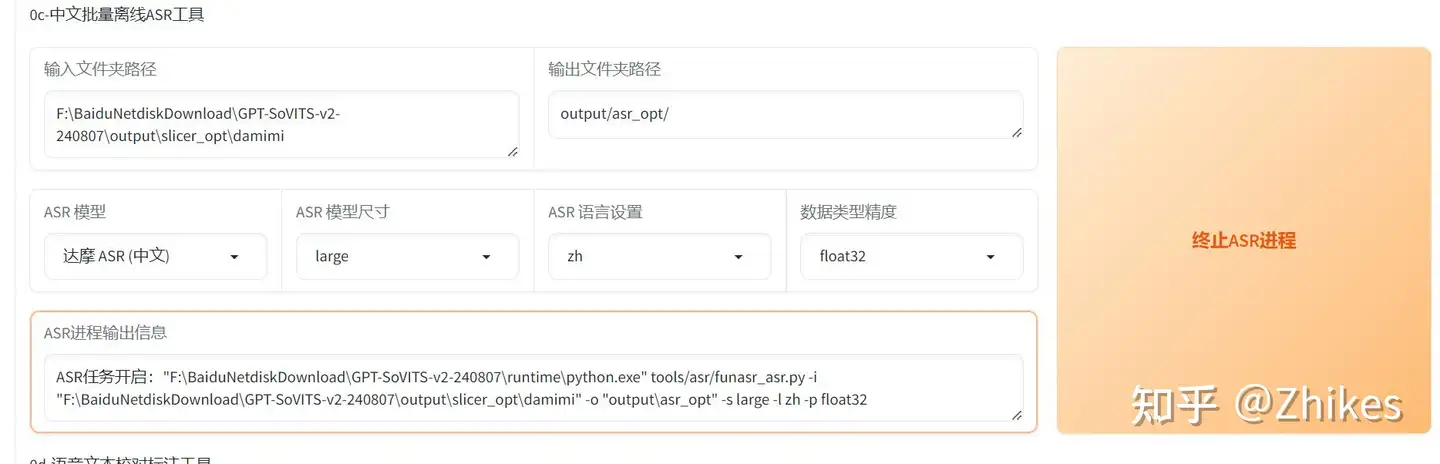
点击开启离线批量ASR,可以在cmd查看进度信息。
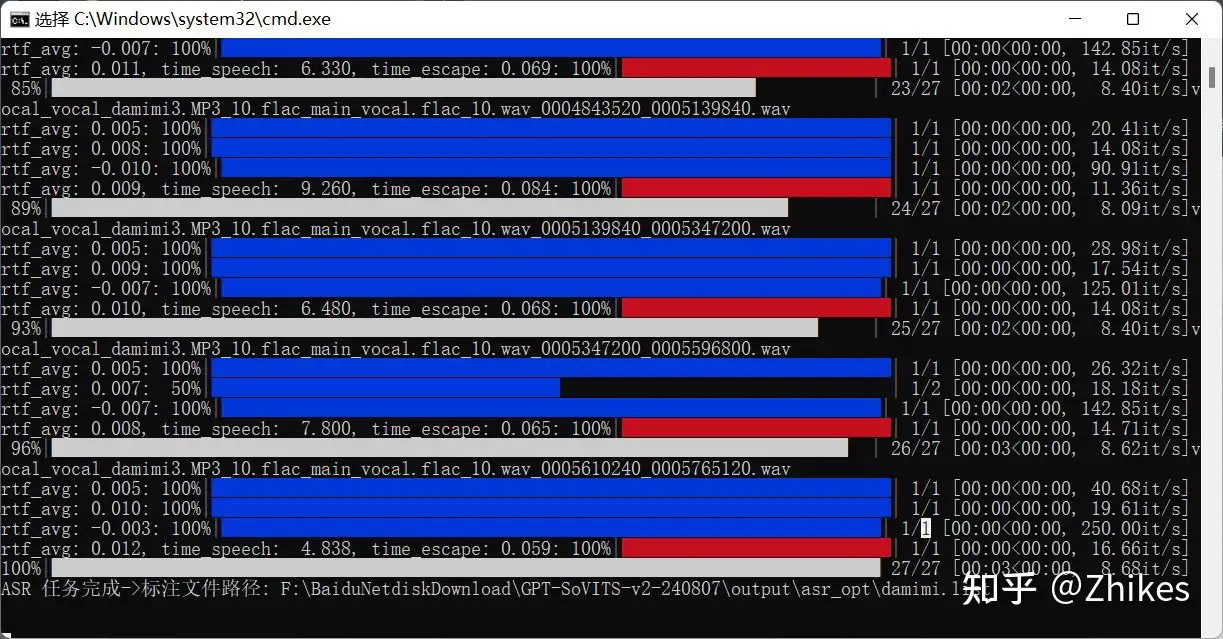
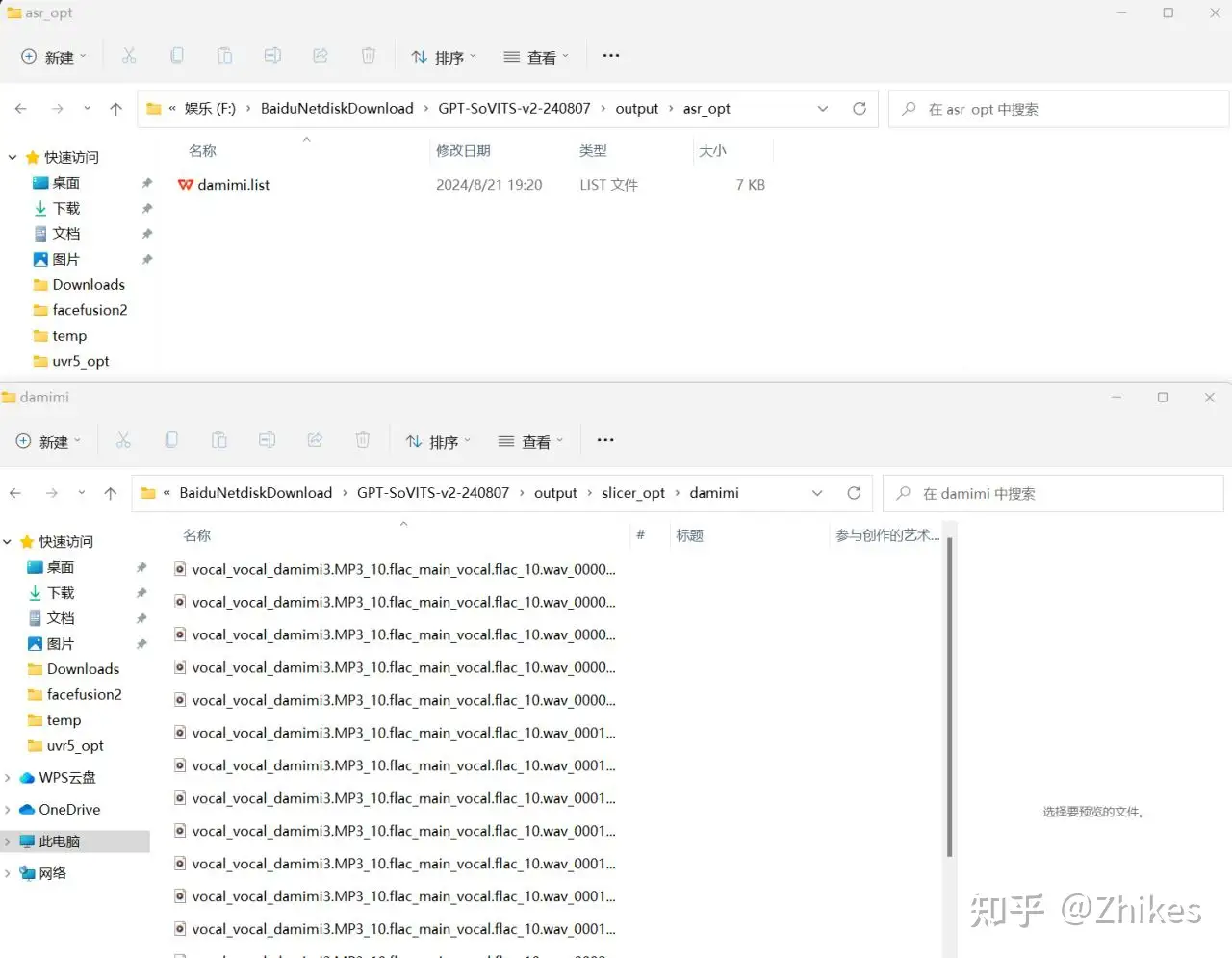
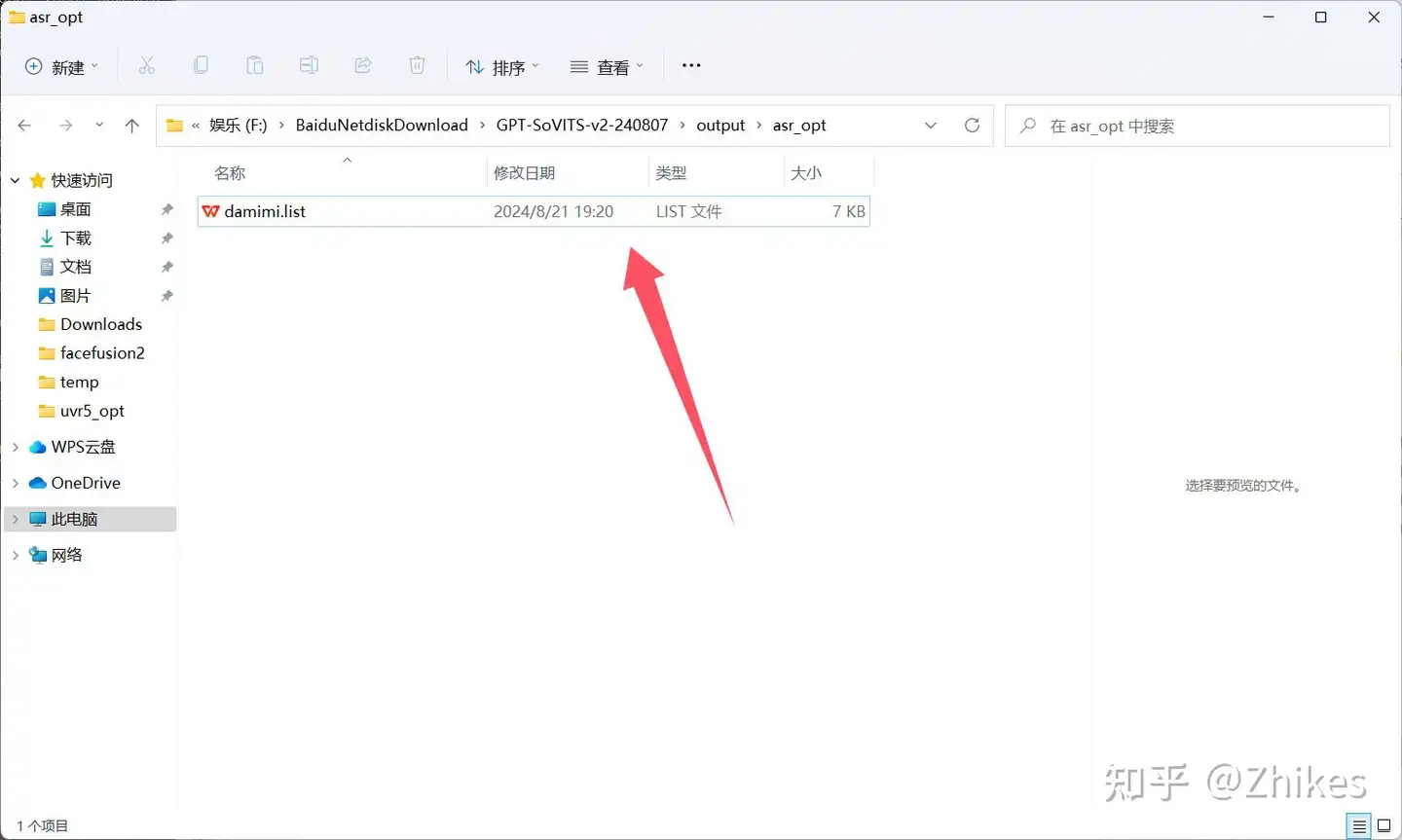
显示任务完成,就可以在输出目录 output/asr_opt/ 看到 damimi.list文件
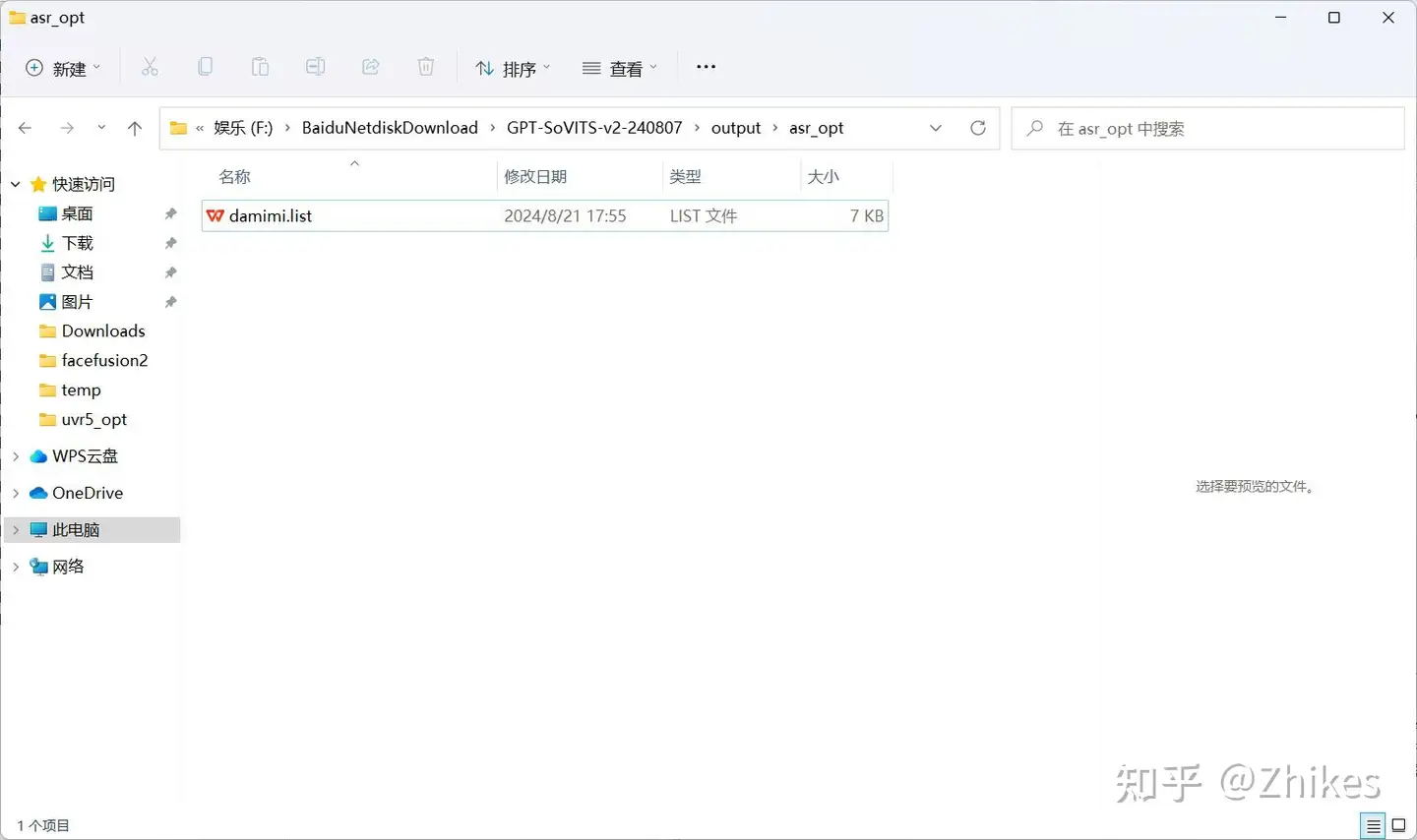
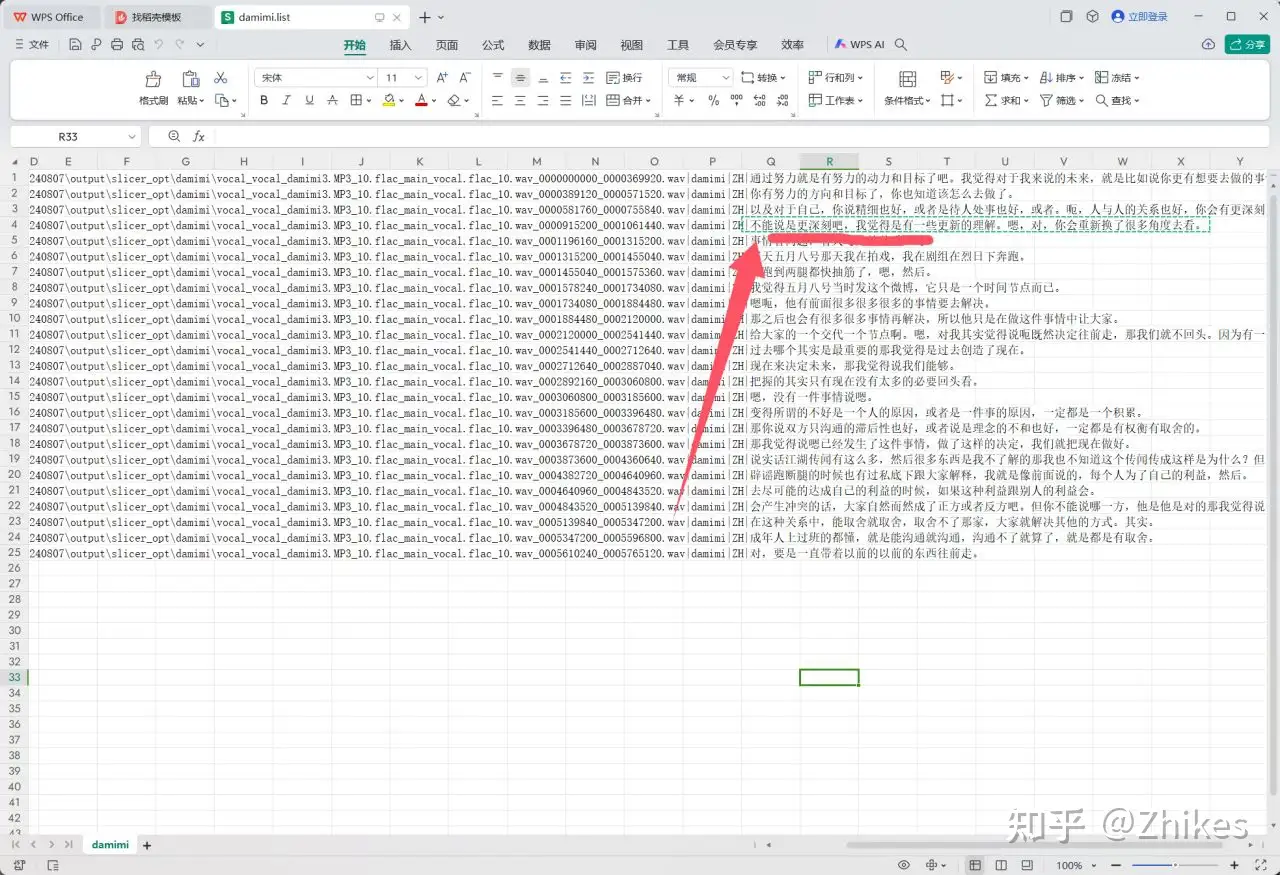
可以打开浏览,发现都是音频文件对应的文本内容。
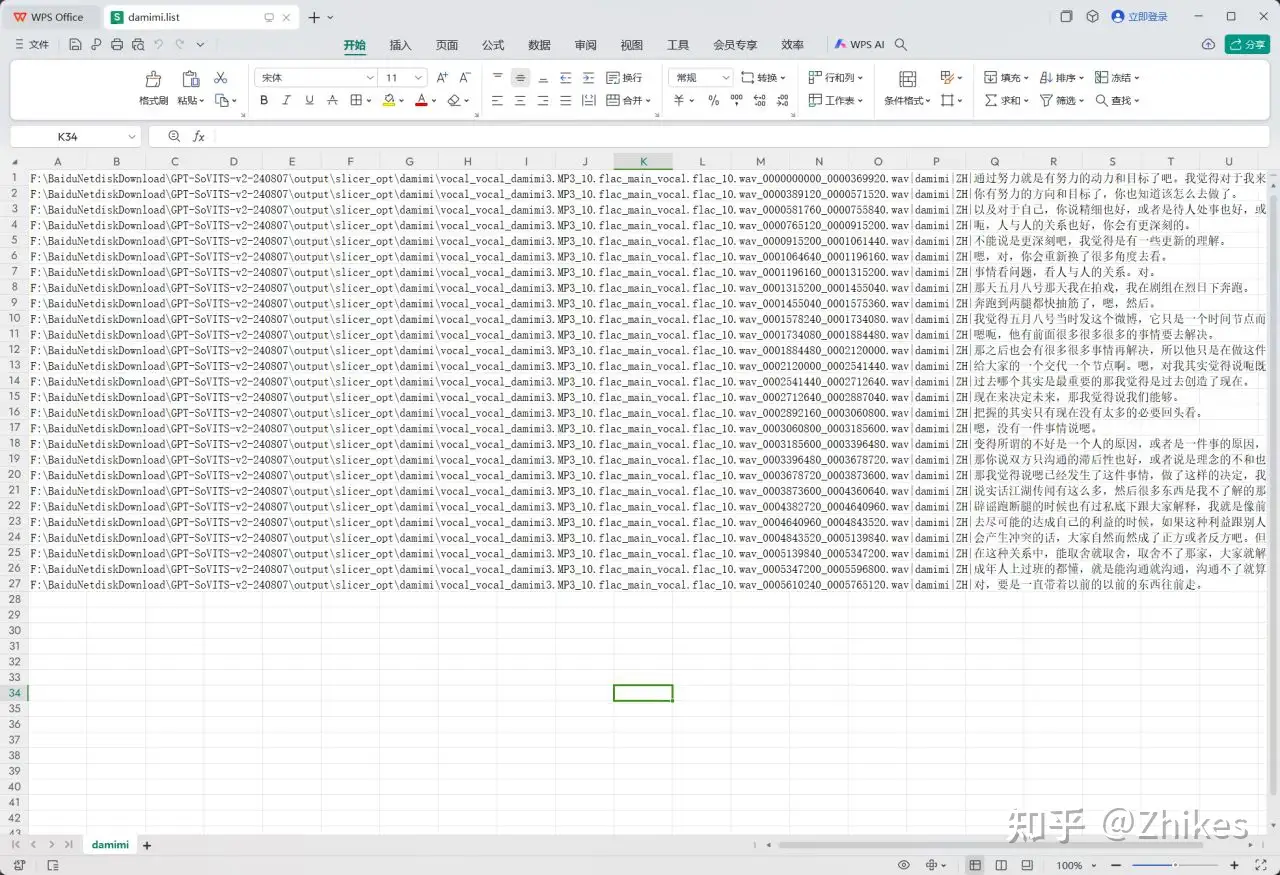
2.打标注(如果你想快速体验效果,不追求质量,也可以直接跳过)

这里一般会自动喂饭,不用输入list标注文件路径,没有就自己输入,点击 勾选 是否开启打标WebUI,稍等几秒会弹出一个新的网页。有的时候会抽风,关掉cmd,重新输入list标注文件地址,重新勾选勾选是否开启打标WebUI,等待网页打开即可。
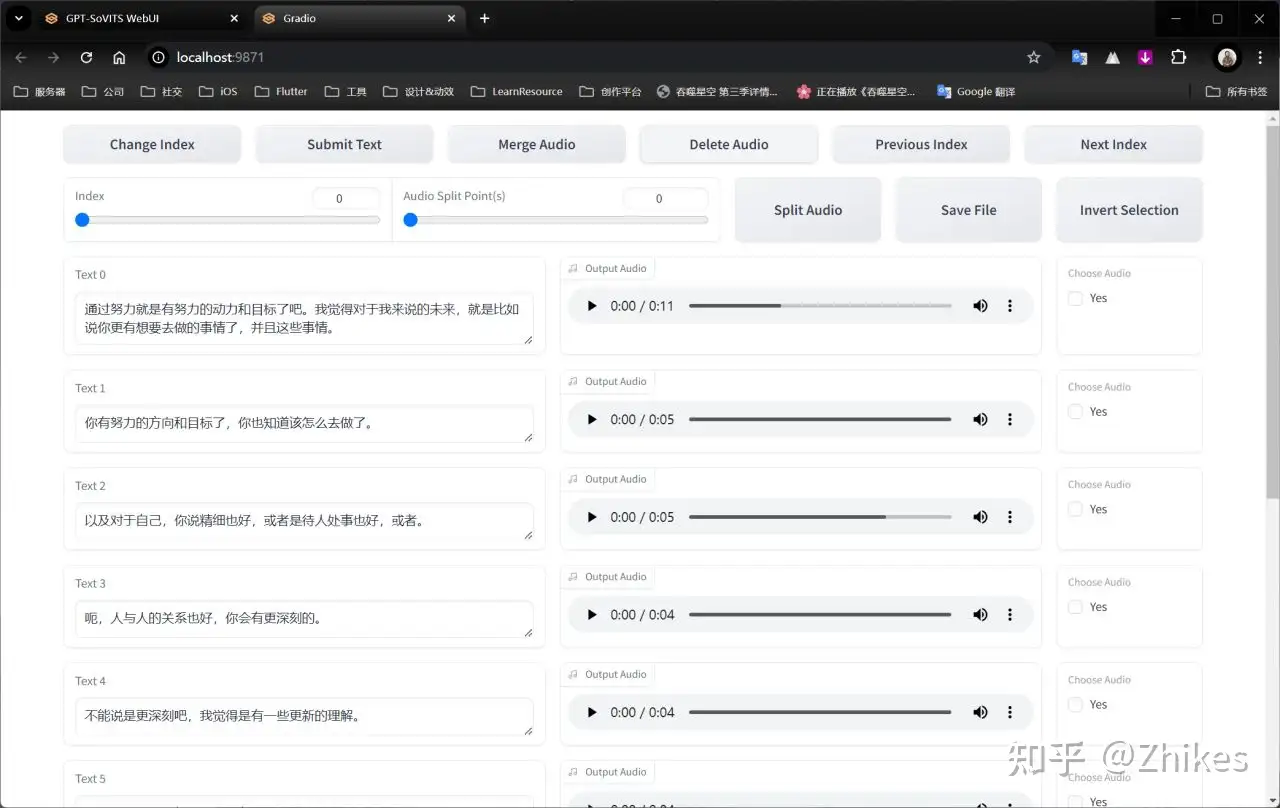
对于上图的英文翻译,从左到右
跳转页码(Change Index)、保存修改(Submit Text)、合并音频(Merge Audio)、删除音频(Delete Audio)、上一页(Previous Index)、下一页(Next Index)、分割音频(Split Audio)、保存文件(Save File)、反向选择(Invert Selection)。
3.校对标注
这个页面看起来按钮比较多,但是常用的也就那几个。我们需要检查Text文本和音频内容是否相同,如果有错误的地方,就需要人工修改。部分音频太短的,没有参考价值可以直接删除。不建议使用合并功能,有bug。。。
下面举例如何合并

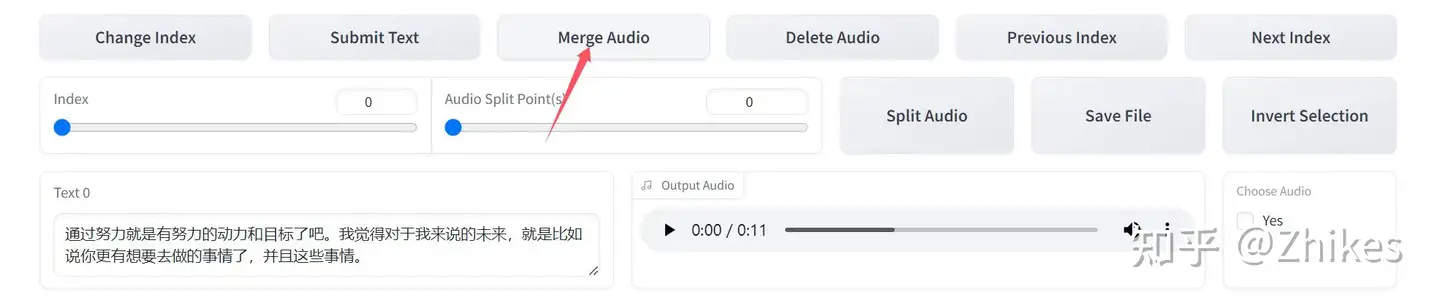
按照上图顺序就可以合并音频。
假设现在你已经完成了校对标注,点击 Save File保存标注文件。回到之前的界面,将打标注界面关掉,节省显存,当然显存大也可以不管

四、训练数据集格式化
切换到分栏 1.GPT-SoVITS-TTS进行训练模型
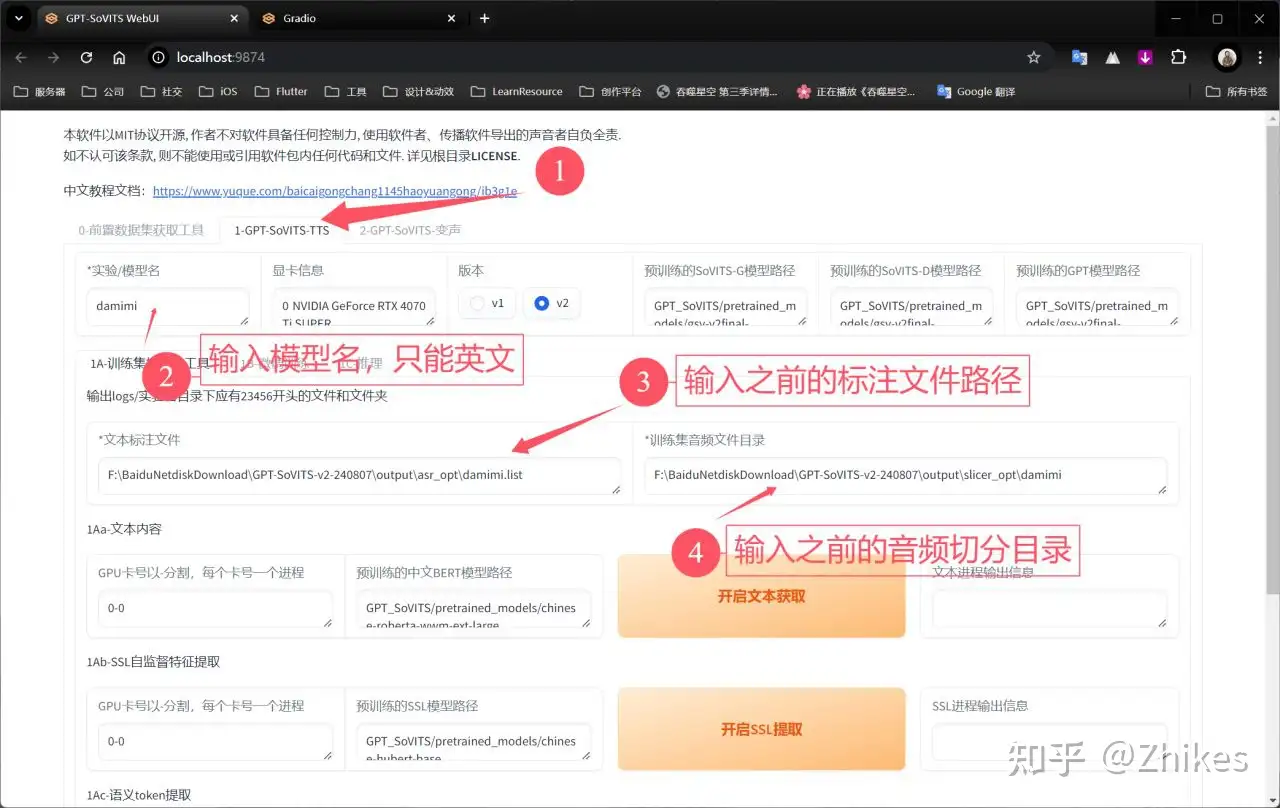
按照上述步骤操作设置,设置完毕,滑动到网页最底部,点击 开启一键三连
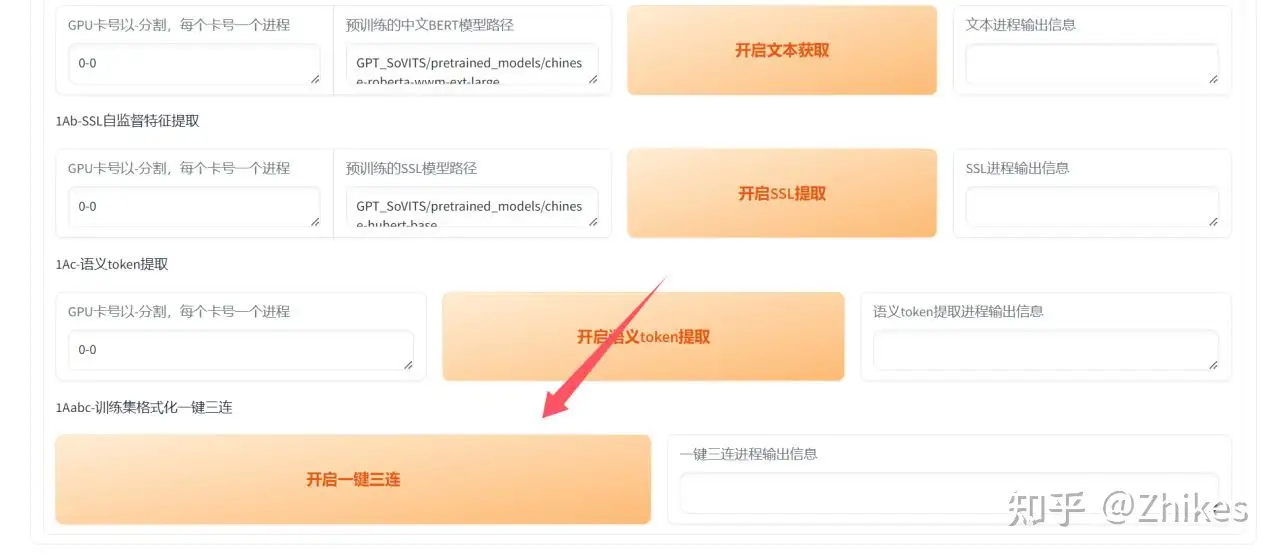
查看cmd进程,软件本身有一些bug,有时可能会卡主不动。
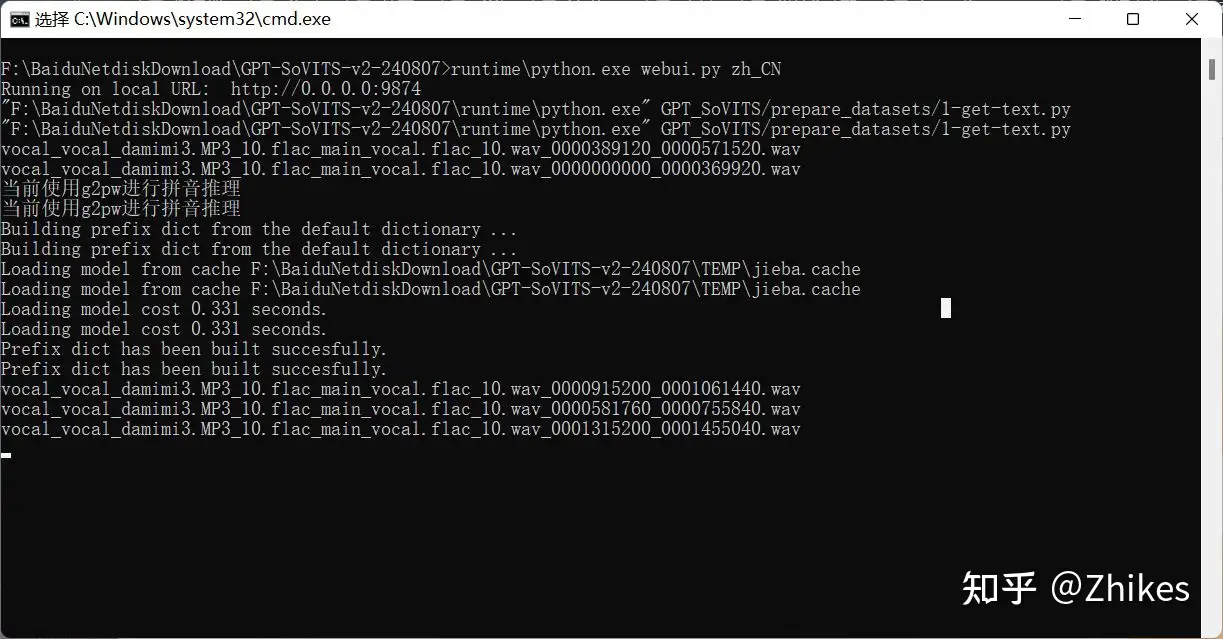
比如我这里cmd长时间停止在这个界面,肯定是不对的,关闭cmd窗口,按照上文说的重新启动go-webui.bat,再次进入这一步即可。
类似这种输出代表执行成功
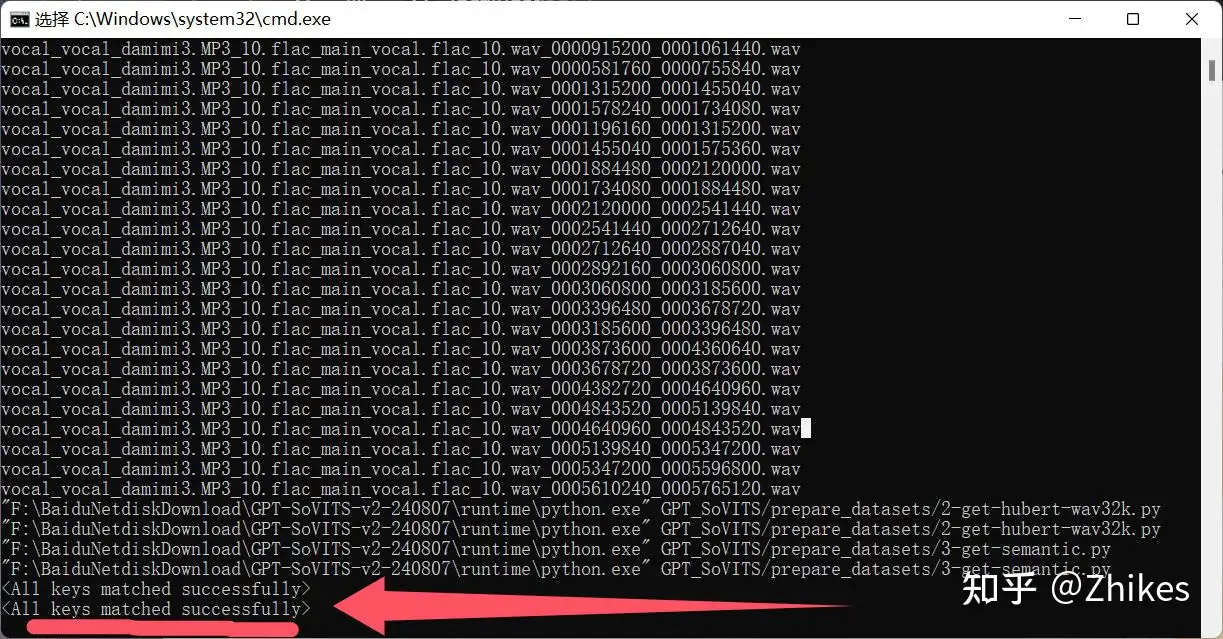
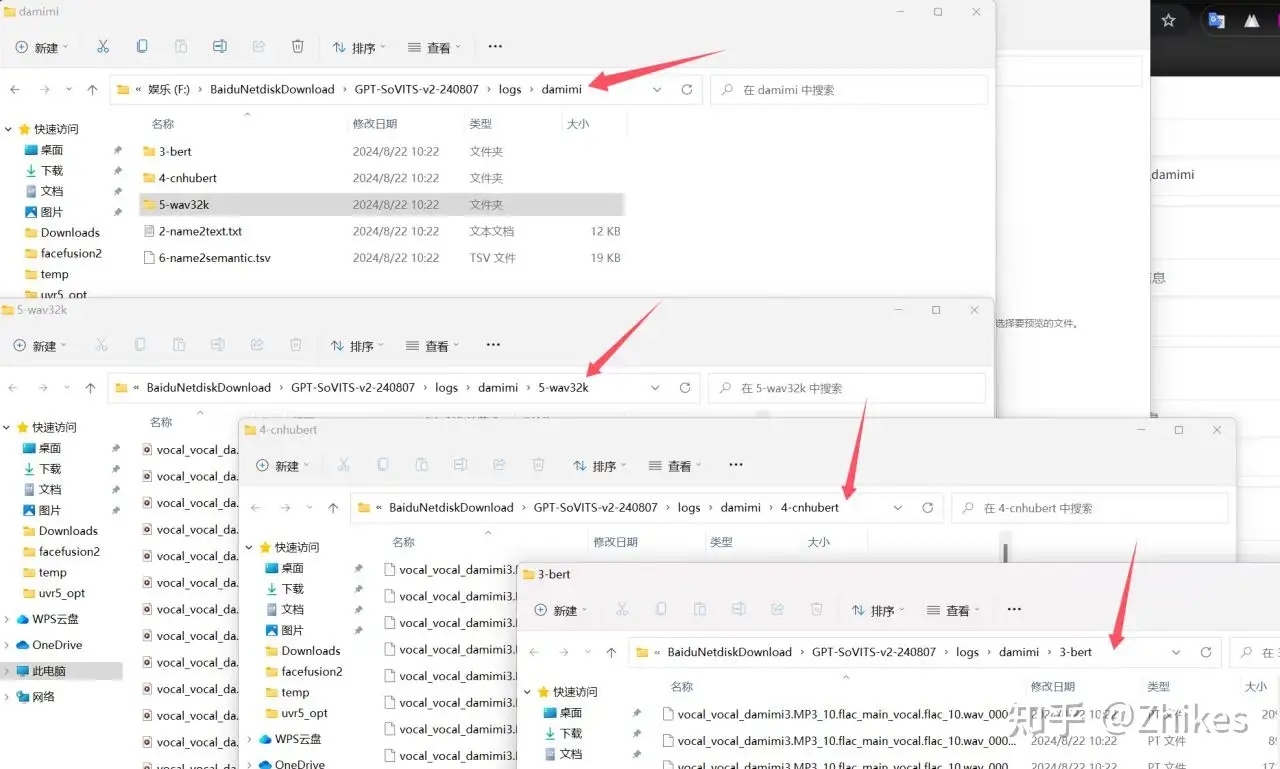
也可以到logs目录中,成功执行里面有三个文件夹和两个文件,三个文件夹里面有文件基本代表执行成功,如下图标注所示
如果重试依然执行失败,请更换声音素材重新尝试
五、训练模型
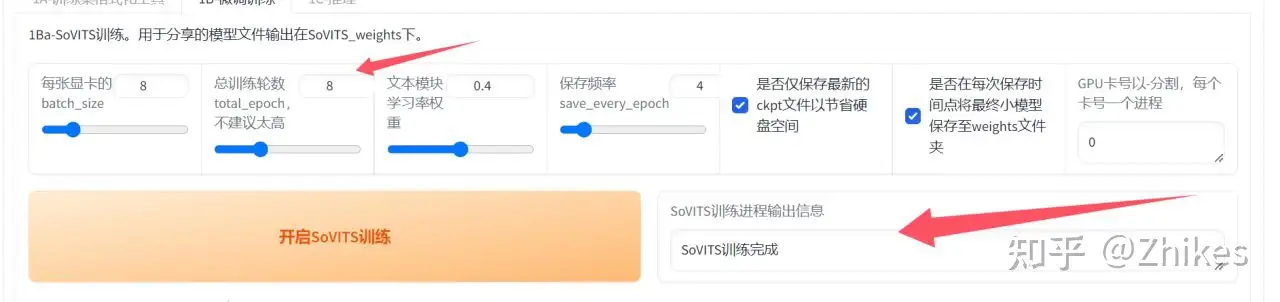
1.开启SoVITS训练
依然是在分栏 1.GPT-SoVITS-TTS进行处理,他下面还有个微调训练,也就是叫做训练模型。
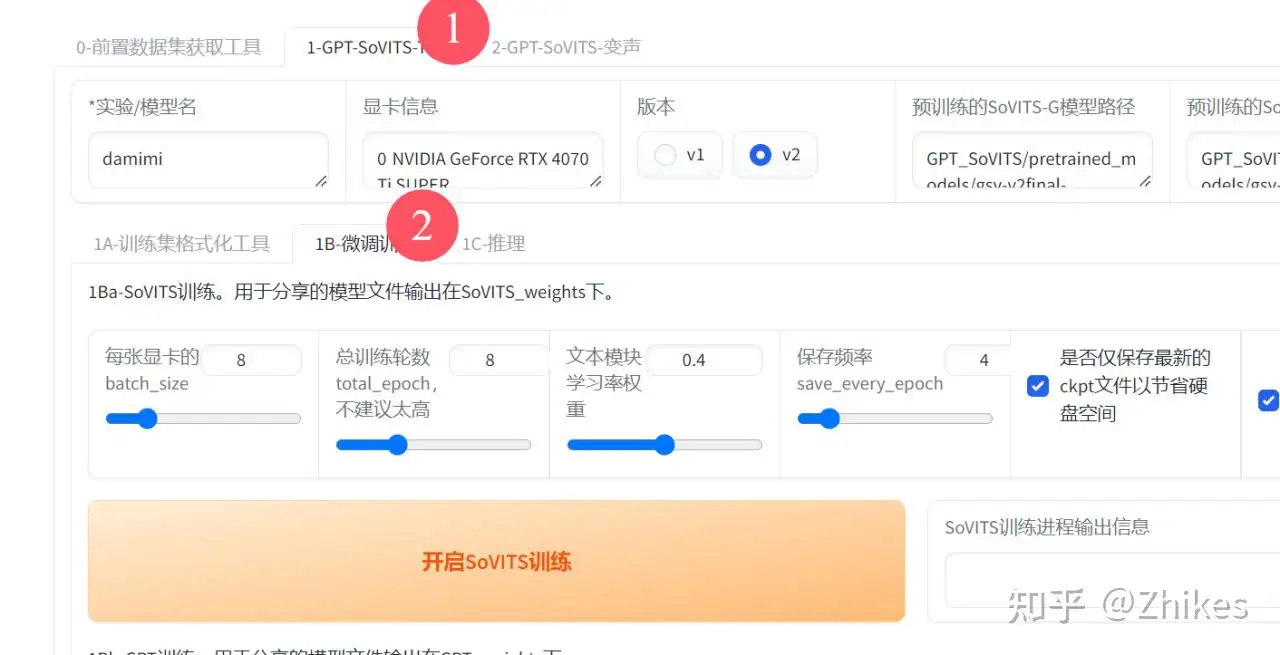
图上所示参数基本可以默认。除了batch_size和总训练轮数简单设置一下
batch_size:6g设置1 8g设置212设置5 16g设置8 22g设置12 24设置14
这个当然要看你显卡体质,你可以观察任务管理器,跑满了就降低一点,剩余多,就停止掉训练调高一点,这里没有什么是固定的说法。
总训练轮数:长一点的音频素材可以设置15,短一点的推荐默认的8即可。
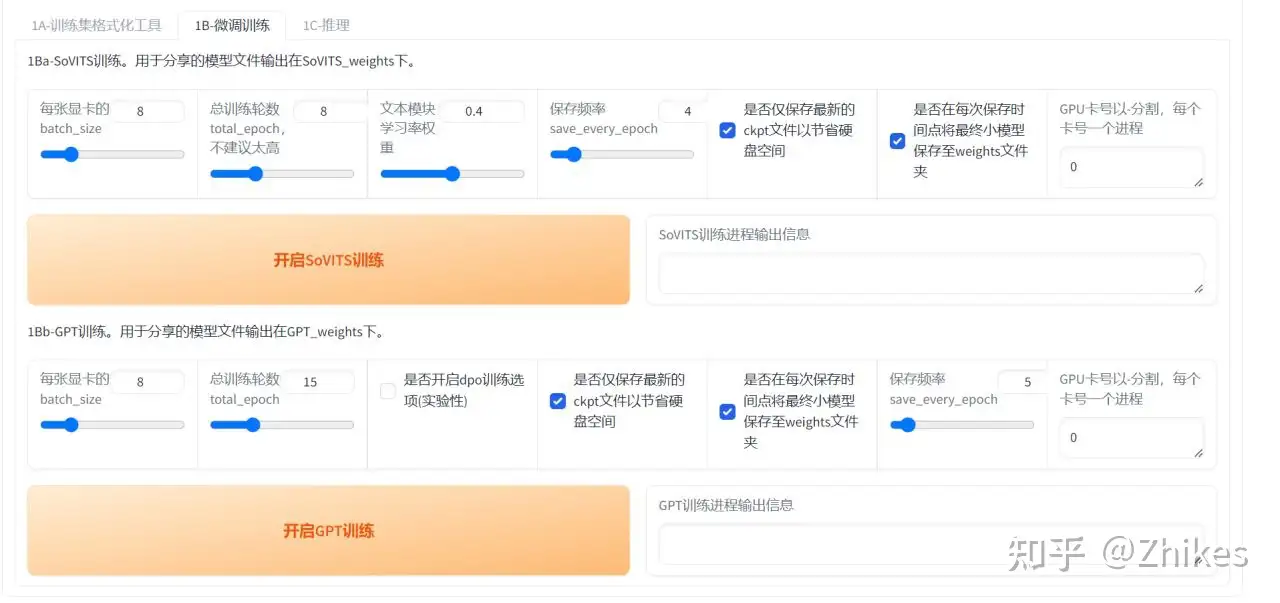
先开启SoVITS训练,完成后再 开启GPT训练,这里我们点击开始SoVITS训练
查看cmd非常必要,我执行时,cmd界面又卡住,一样的,关掉cmd窗口,重启软件,界面这样才是正常的,软件本身有一堆bug
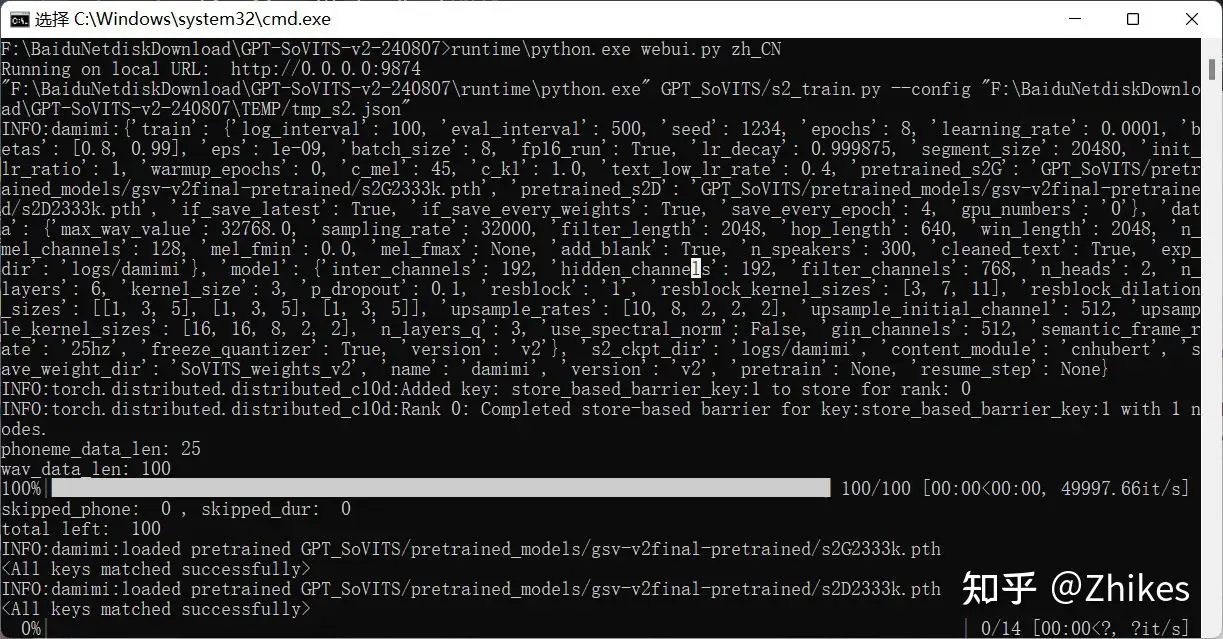
正常执行界面,也可以切出任务管理器,查看GPU显存占用有没有波动,cmd没有输出,GPU显存一定时间没有波动,那就是要重新启动了,因为程序卡主了。
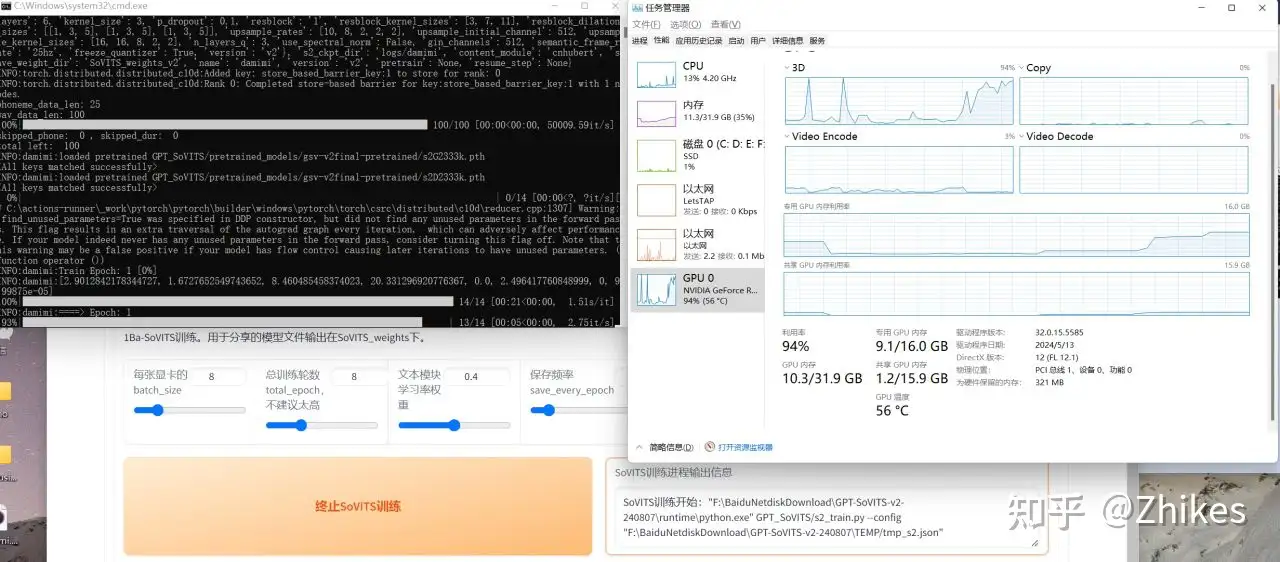
cmd输出窗口可以看到执行的批次,划线处
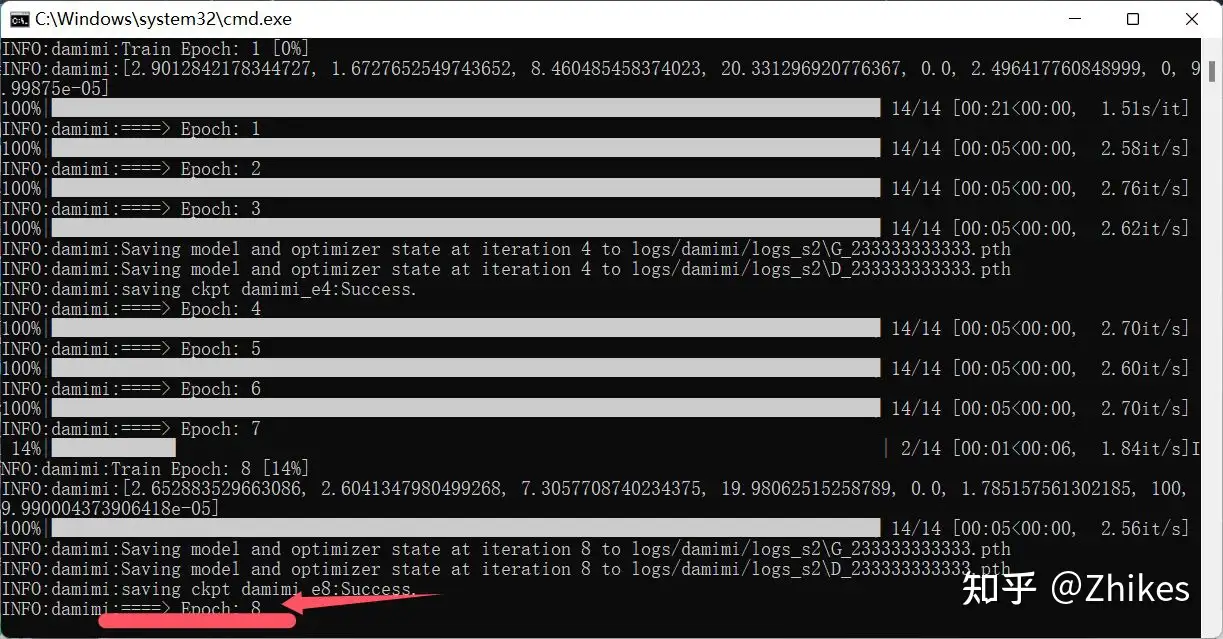
我设置的批次是8,完成后的cmd窗口输出和软件界面提示一并放出。
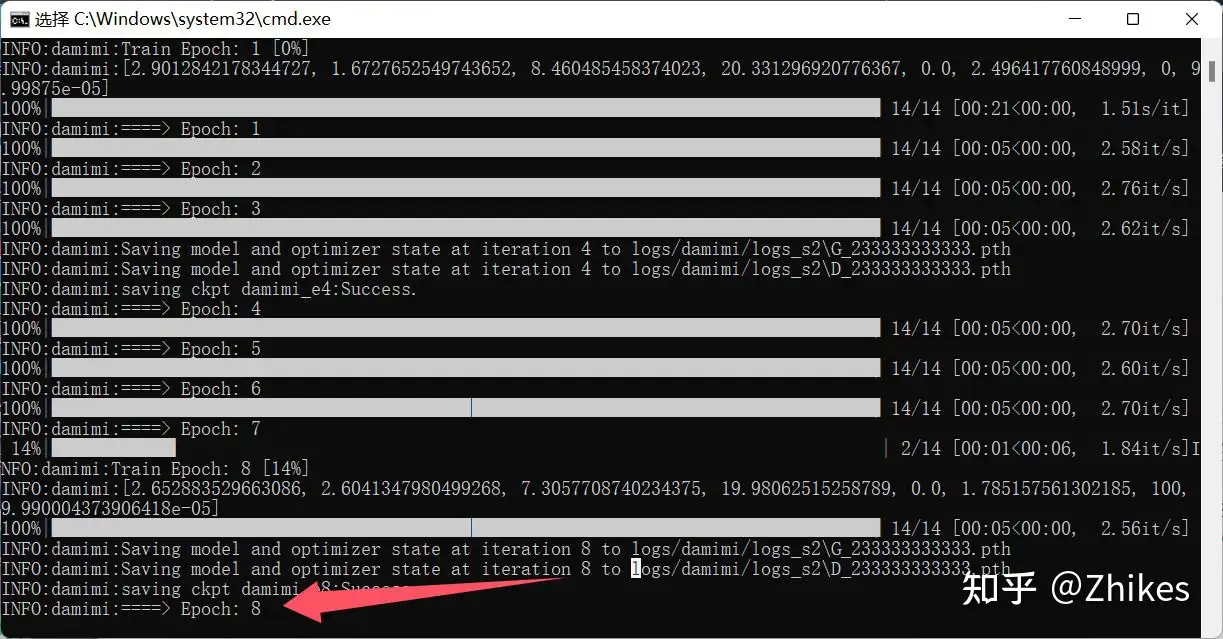
我的声音素材时长大概3分钟,可以重新调整总训练轮数为15重新训练。具体看你要求,一般总训练轮数15基本已经满足使用了。
2.开启GPT训练
batch_size和总训练轮数和1中所述的一样设置即可,开始GPT训练
点击后cmd一段时间没输出就关掉重开,不得不说bug是真多
正常界面应该是这样的
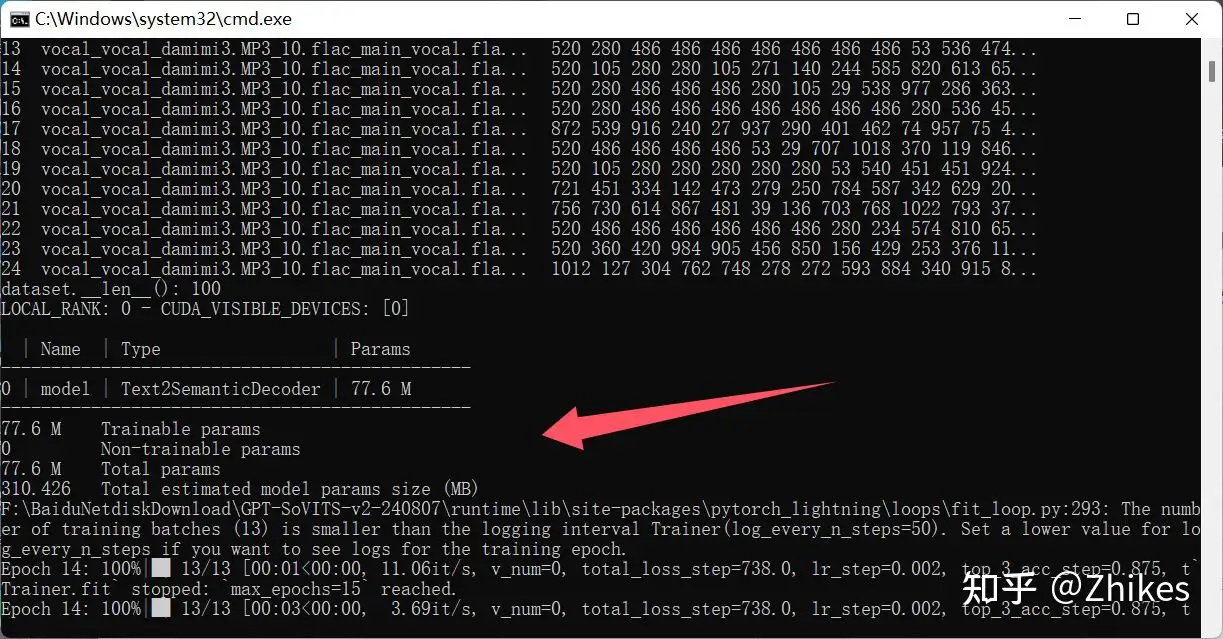
处理完成的界面显示

SoVITS 和 GPT训练都完成后,就可以在模型目录查看到这两个模型
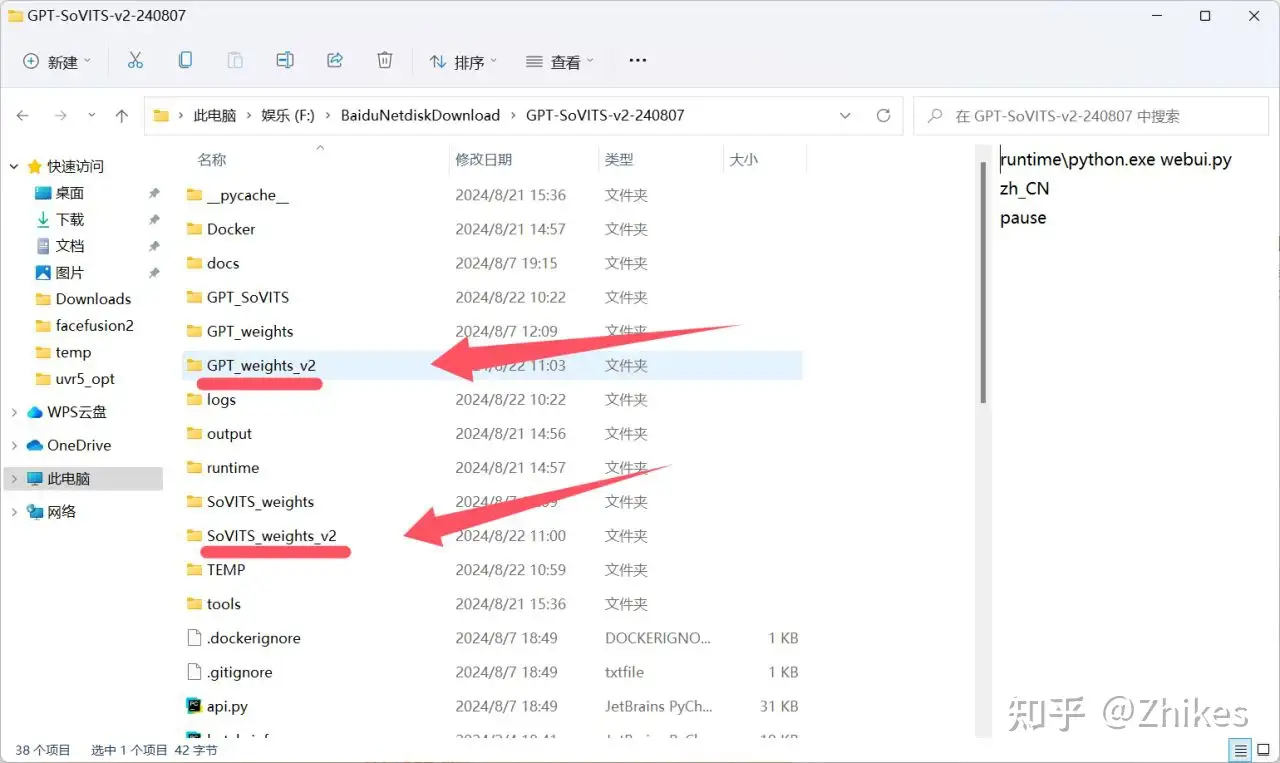
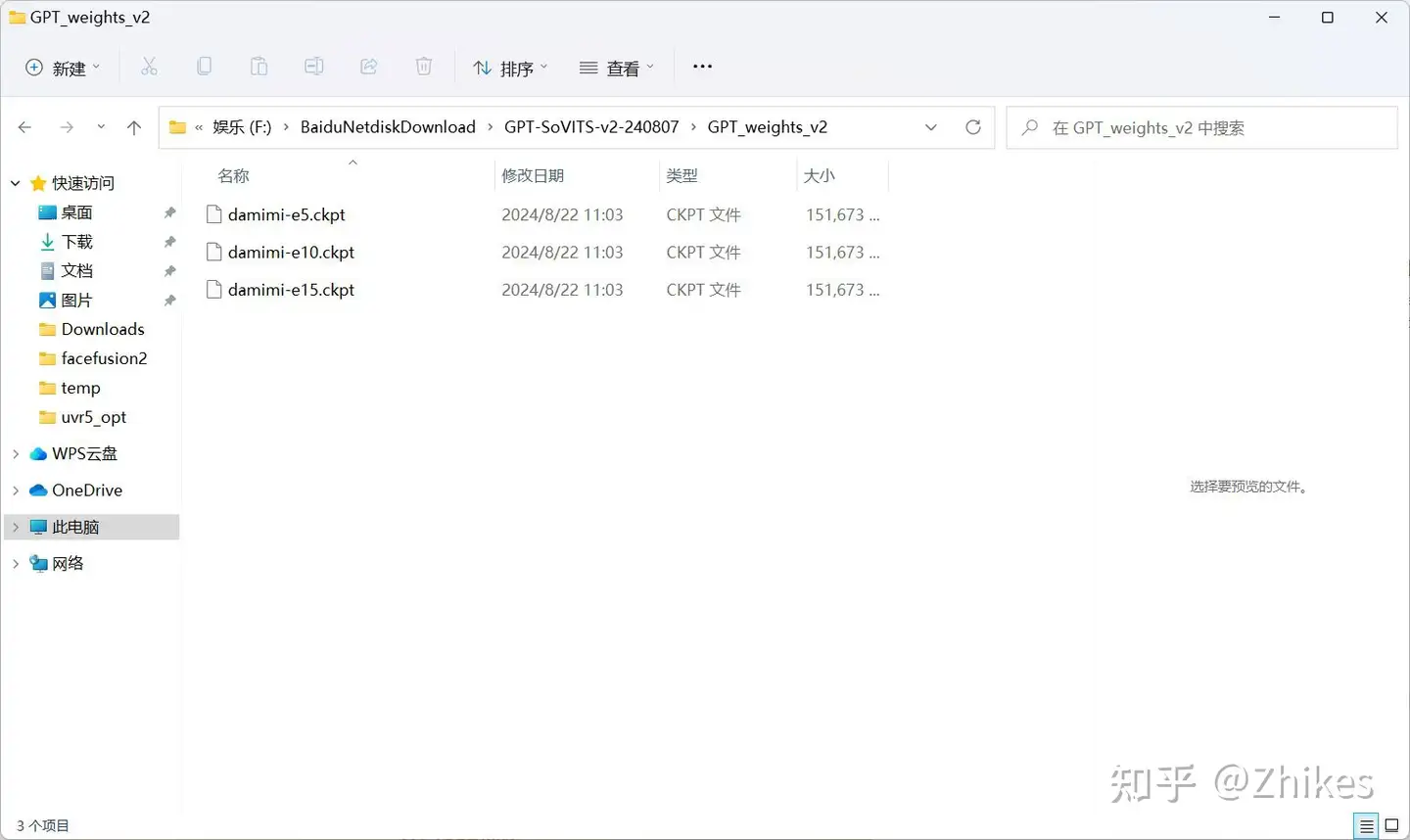
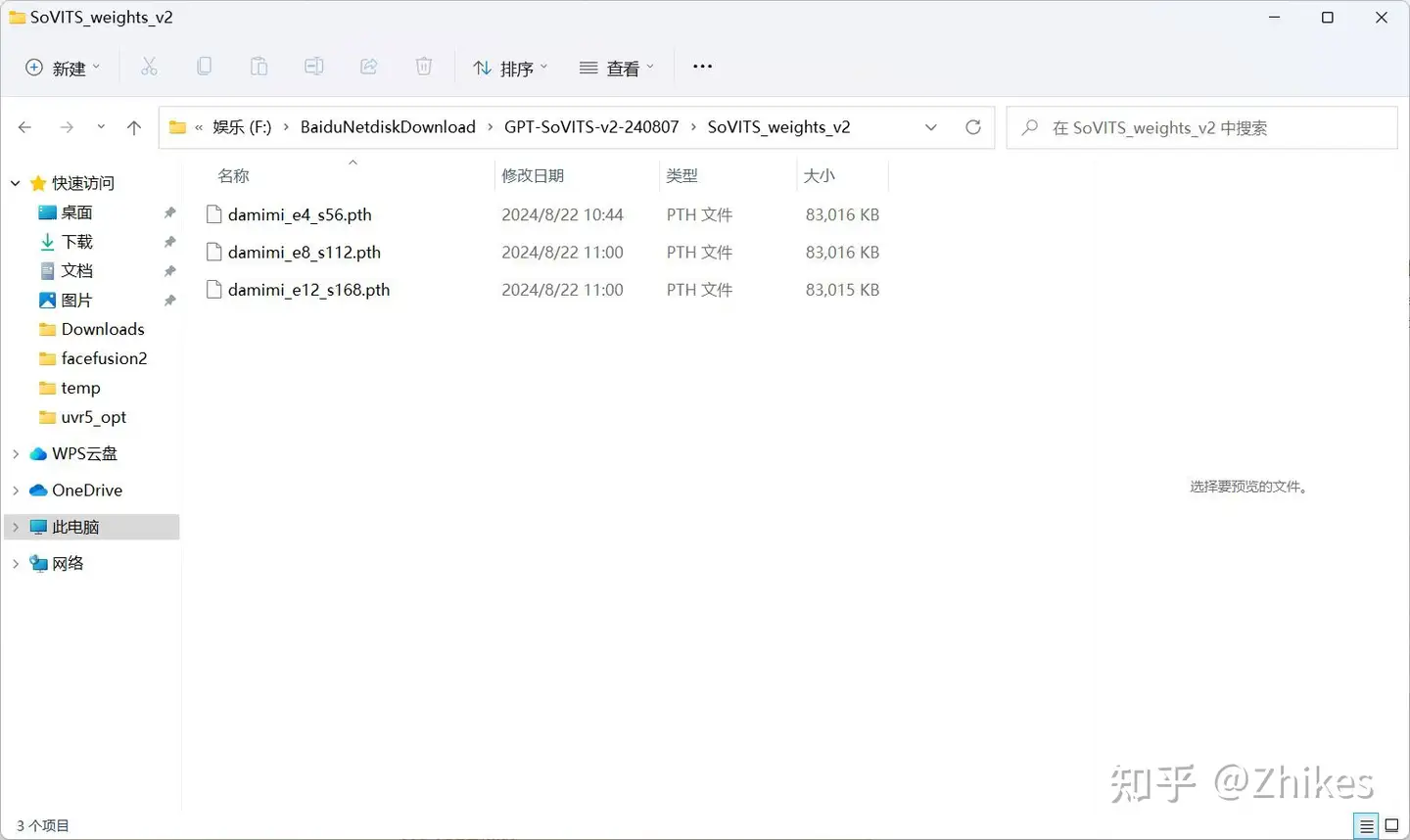
你训练好的模型也可以发送给别人,别人复制到相同目录下,就可以实现根据模型克隆语音。
六、克隆声音
这也是最后一个环节了,用之前训练好的模型克隆声音。
先切换分栏到推理界面,然后点击刷新模型
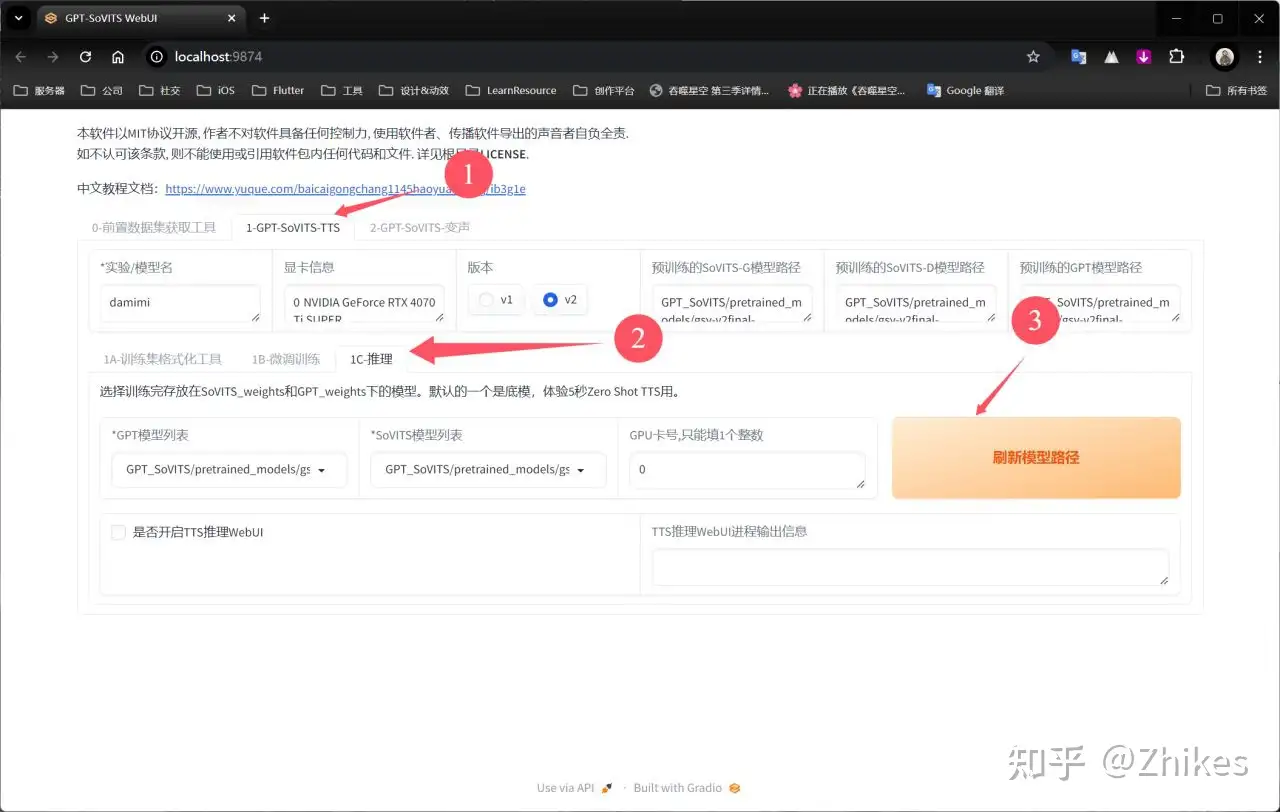
在GPT模型列表和SoVITS模型列表选择之前训练的模型即可,一般选择训练轮数最大的,和步数最多的,e代表轮数,s代表步数
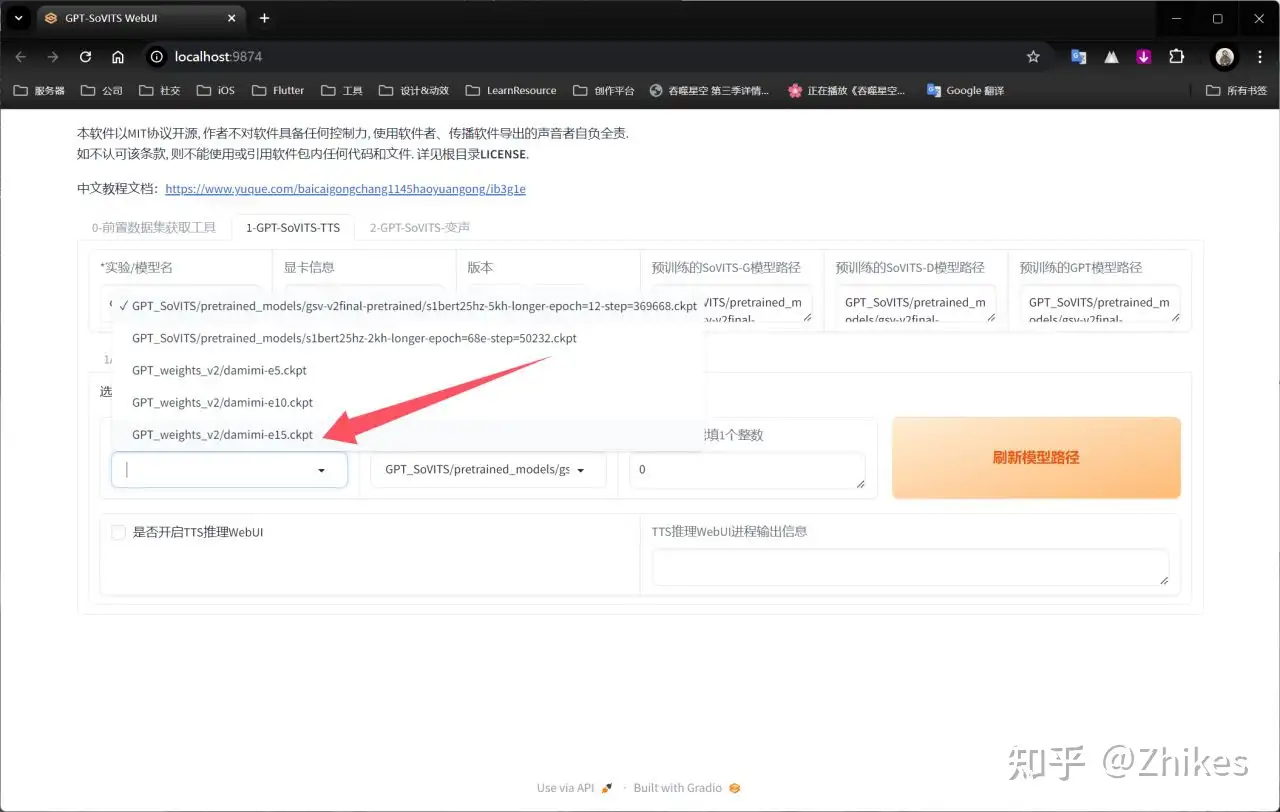
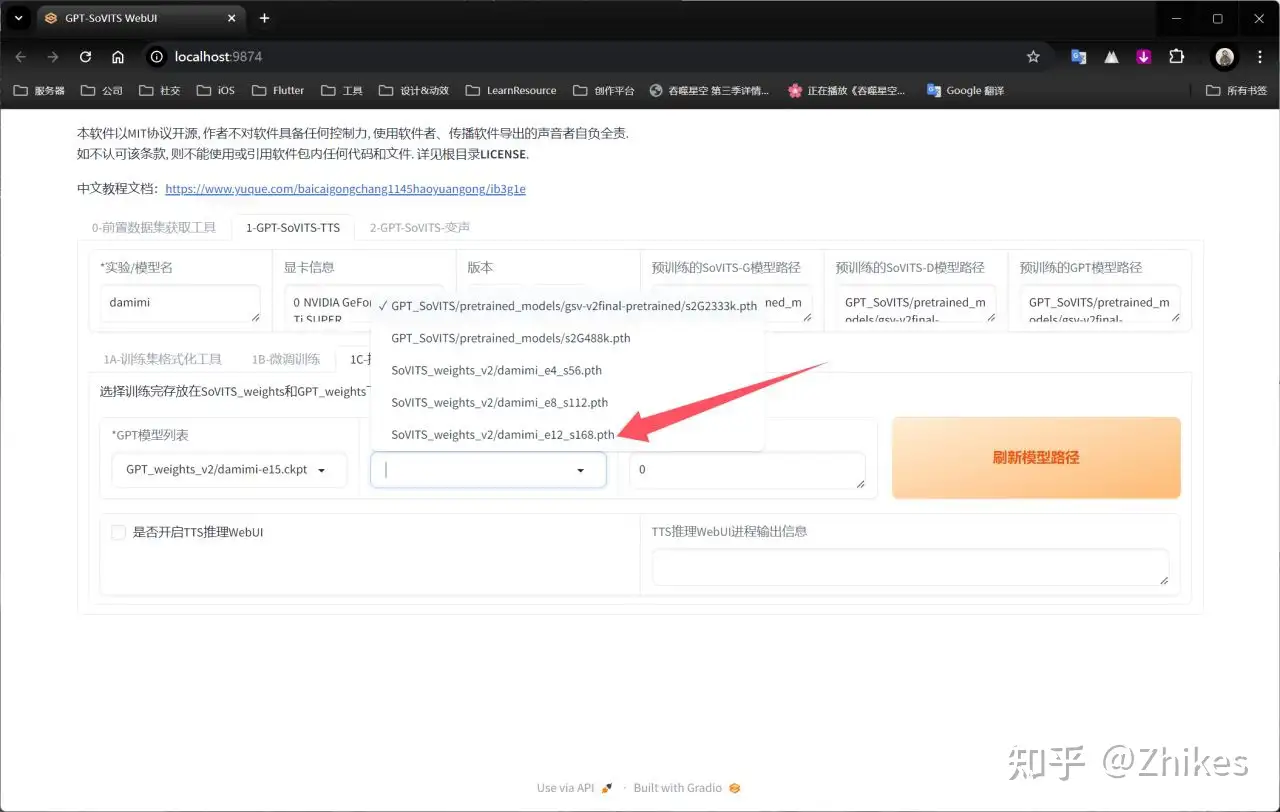
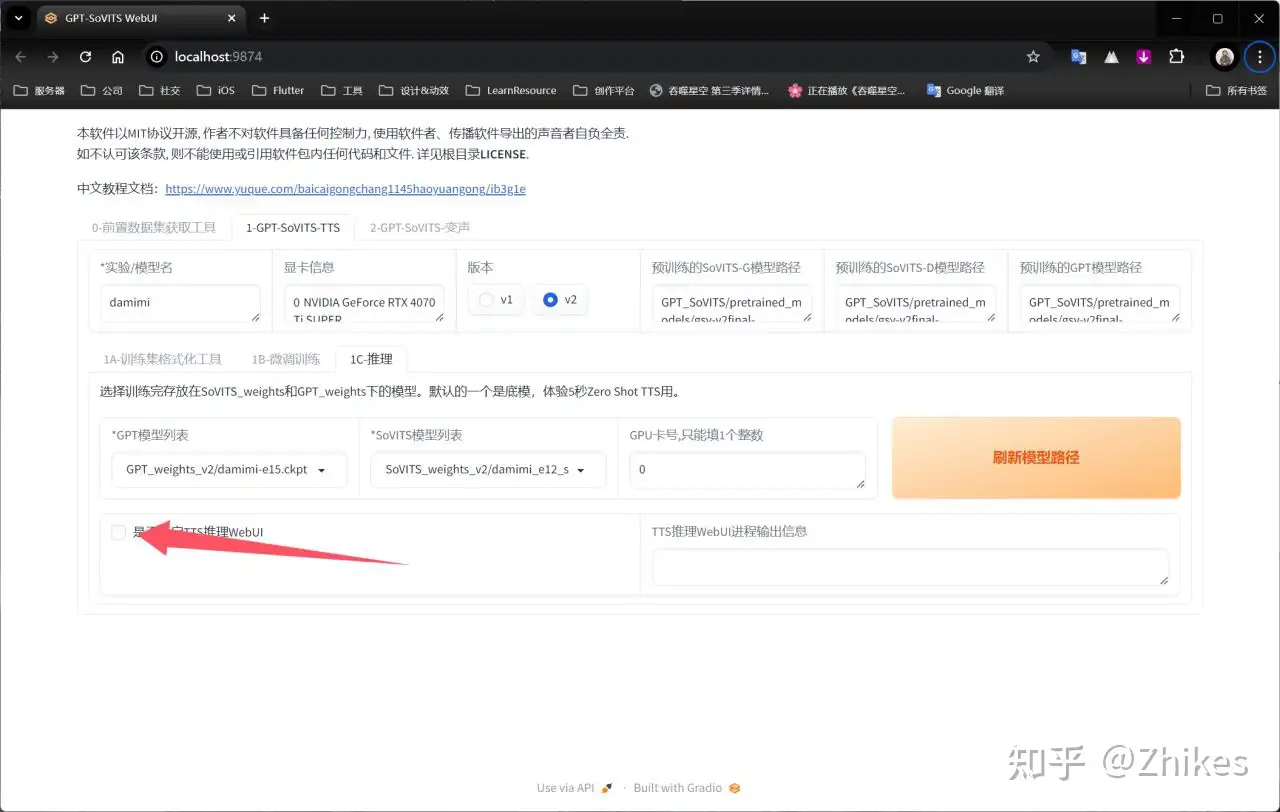
再勾选下面箭头指向处,会自动打开新的网页
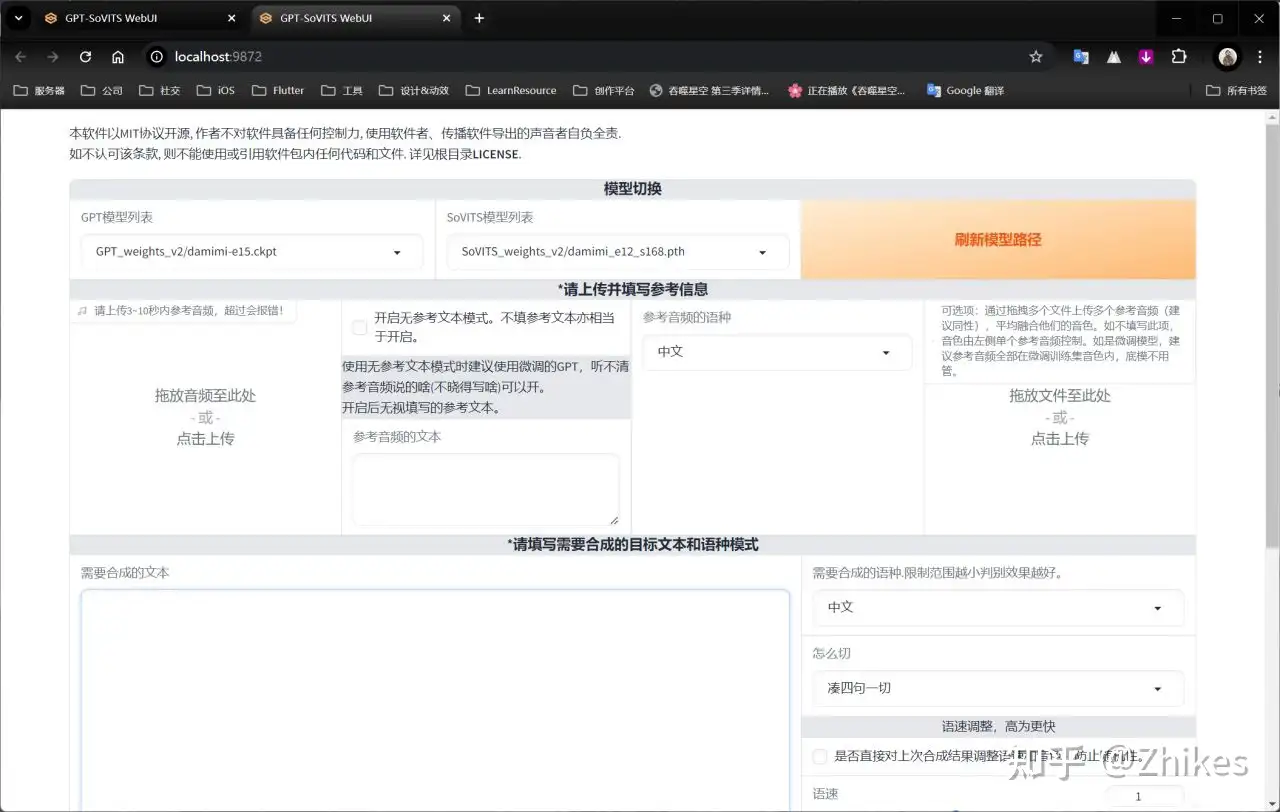
可以在之前的音频切分找到需要使用的素材
拖拽进去
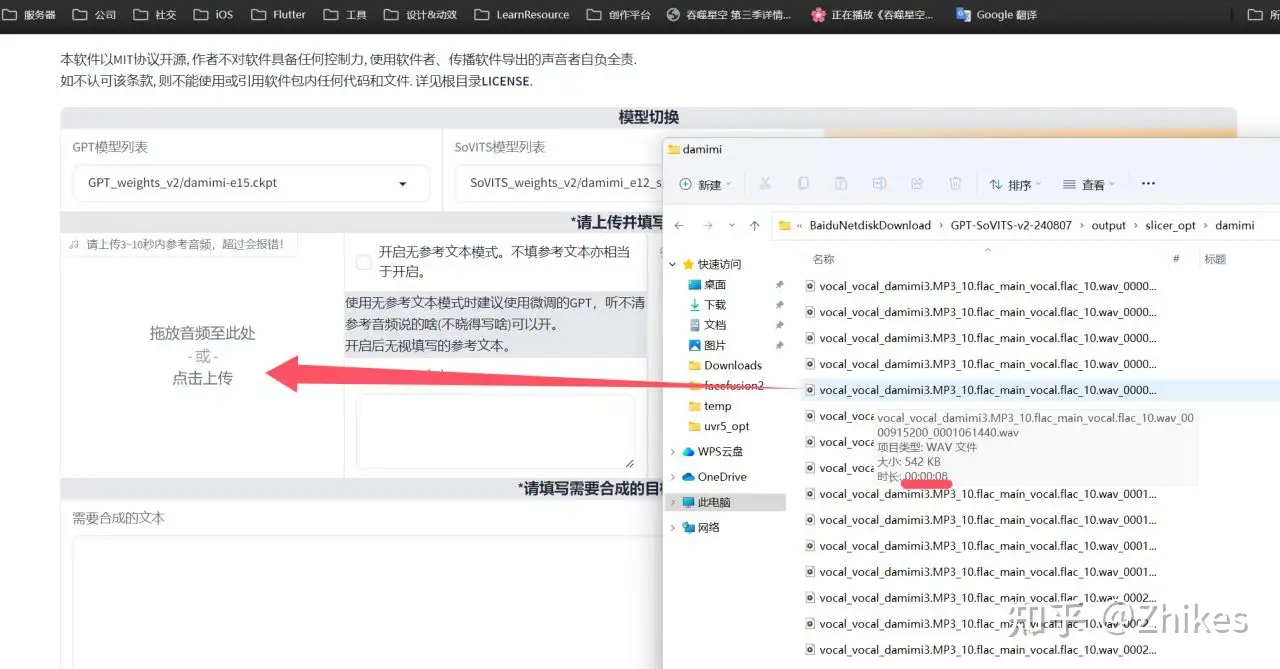
找到之前的打标文件,找到对应的文本复制
如下图按照顺序,在序号③中填入你想要让他说的话,第④个序号中,怎么切一般选择按中文句号切
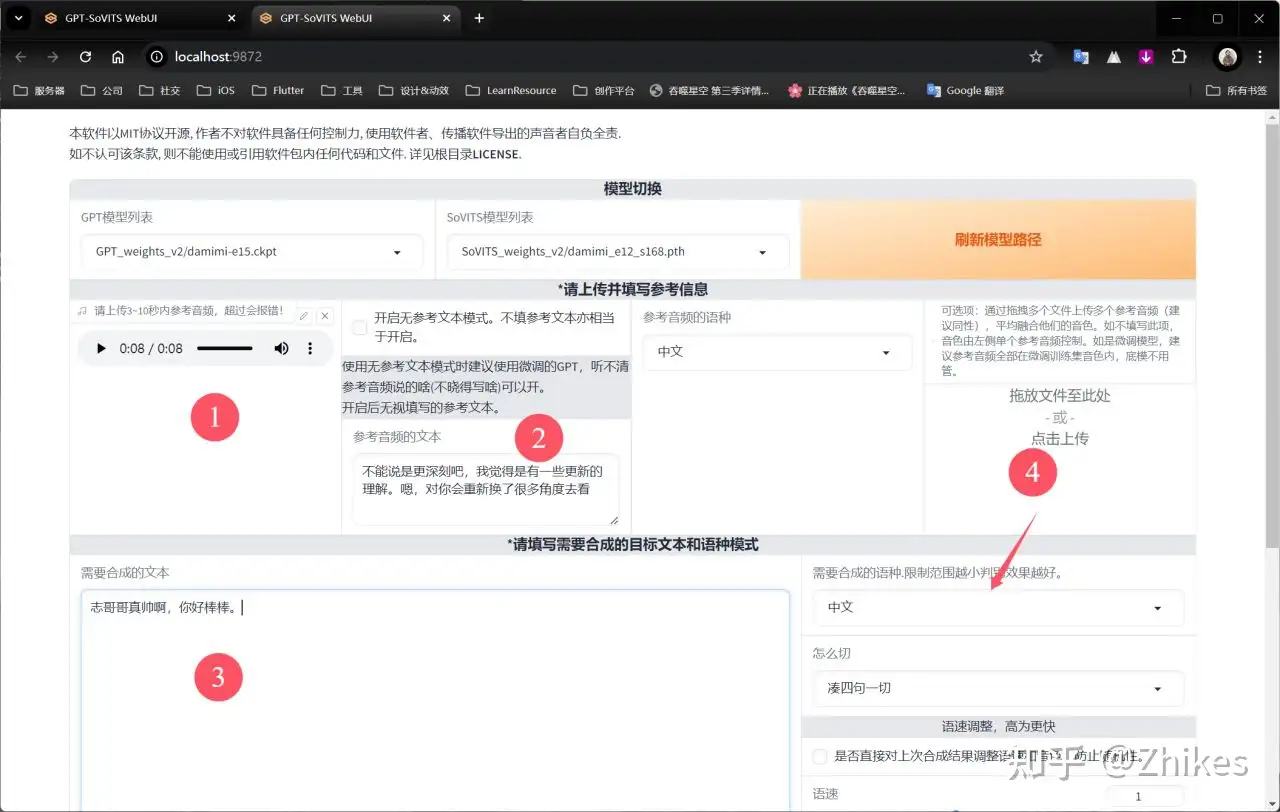
最后点击合成语音即可
好的,教程到此结束,谢谢大家的观看,有问题可以通过公众好加入星球联系提供支持。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号