
SQL Server调优系列基础篇(索引运算总结)
前言
上几篇文章我们介绍了如何查看查询计划、常用运算符的介绍、并行运算的方式,有兴趣的可以点击查看。
本篇将分析在SQL Server中,如何利用先有索引项进行查询性能优化,通过了解这些索引项的应用方式可以指导我们如何建立索引、调整我们的查询语句,达到性能优化的目的。
闲言少叙,进入本篇的正题。
技术准备
基于SQL Server2008R2版本,利用微软的一个更简洁的案例库(Northwind)进行解析。
简介
所谓的索引应用就是在我们日常写的T-SQL语句中,如何利用现有的索引项,再分析的话就是我们所写的查询条件,其实大部分情况也无非以下几种:
1、等于谓词:select ...where...column=@parameter
2、比较谓词:select ...where...column> or < or <> or <= or >= @parameter
3、范围谓词:select ...where...column in or not in or between and @parameter
4、逻辑谓词:select ...where...一个谓词 or、and 其它谓词 or、and 更多谓词....
我们就依次分析上面几种情况下,如何利用索引进行查询优化的
一、动态索引查找
所谓的动态索引查找就是SQL Server在执行语句的时候,才格式化查询条件,然后根据查询条件的不同自动的去匹配索引项,达到性能提升的目的。
来举个例子
SET SHOWPLAN_TEXT ON GO SELECT OrderID FROM Orders WHERE ShipPostalCode IN (N'05022',N'99362')
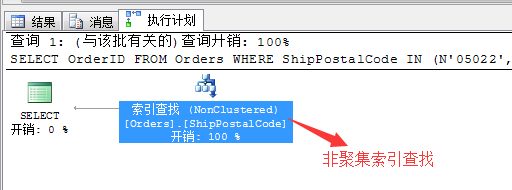
因为我们在表Orders的列ShipPostalCode列中建立了非聚集索引列,所以这里查询的计划利用了索引查找的方式。这也是需要建立索引的地方。
我们来利用文本的方式来查看该语句的详细的执行计划脚本,语句比较长,我用记事本换行,格式化查看
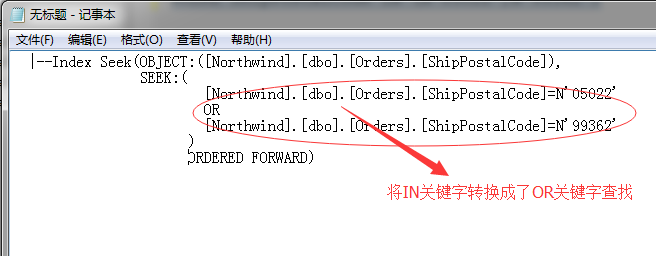
我们知道这张表的该列里存在一个非聚集索引,所以在查询的时候要尽量使用,如果通过索引扫描的方式消耗就比较大了,所以SQL Server尽量想采取索引查找的方式,其实IN关键字和OR关键字逻辑是一样的。
于是上面的查询条件就转换成了:
[Northwind].[dbo].[Orders].[ShipPostalCode]=N'05022'
OR
[Northwind].[dbo].[Orders].[ShipPostalCode]=N'99362'
这样就可以采用索引查找了,先查找第一个结果,然后再查找第二个,而这个过程在SQL Server中就被称为:动态索引查找。
是不是有点智能的感觉了....
所以有时候我们写语句的时候,尽量要使用SQL Server的这点智能了,让其能自动的查找到索引,提升性能。
有时候偏偏我们写的语句让SQL Server的智能消失,举个例子:
--参数化查询条件 DECLARE @Parameter1 NVARCHAR(20),@Parameter2 NVARCHAR(20) SELECT @Parameter1=N'05022',@Parameter2=N'99362' SELECT OrderID FROM Orders WHERE ShipPostalCode IN (@Parameter1,@Parameter2)
我们将这两个静态的筛序值改成参数,有时候我们写的存储过程灰常喜欢这么做!我们来看这种方式的生成的查询计划
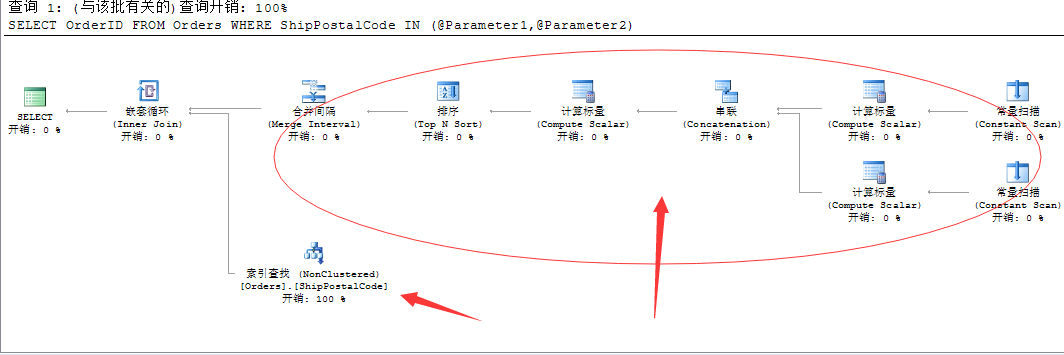
本来很简单的一个非聚集索引查找搞定的执行计划,我们只是将这两个数值没有直接写入IN关键字中,而是利用了两个变量来代替。
看看上面SQL Server生成的查询计划!尼玛...这都是些啥???还用起来嵌套循环,我就查询了一个Orders表...你嵌套循环个啥....上面动态索引查找的能力去哪了???
好吧,我们用文本查询计划来查看下,这个简单的语句到底在干些啥...
|--Nested Loops(Inner Join, OUTER REFERENCES:([Expr1009], [Expr1010], [Expr1011])) |--Merge Interval | |--Sort(TOP 2, ORDER BY:([Expr1012] DESC, [Expr1013] ASC, [Expr1009] ASC, [Expr1014] DESC)) | |--Compute Scalar(DEFINE:([Expr1012]=((4)&[Expr1011]) = (4) AND NULL = [Expr1009], [Expr1013]=(4)&[Expr1011], [Expr1014]=(16)&[Expr1011])) | |--Concatenation | |--Compute Scalar(DEFINE:([Expr1004]=[@Parameter2], [Expr1005]=[@Parameter2], [Expr1003]=(62))) | | |--Constant Scan | |--Compute Scalar(DEFINE:([Expr1007]=[@Parameter1], [Expr1008]=[@Parameter1], [Expr1006]=(62))) | |--Constant Scan |--Index Seek(OBJECT:([Northwind].[dbo].[Orders].[ShipPostalCode]), SEEK:([Northwind].[dbo].[Orders].[ShipPostalCode] > [Expr1009] AND [Northwind].[dbo].[Orders].[ShipPostalCode] < [Expr1010]) ORDERED FORWARD)
挺复杂的是吧,其实我分析了一下脚本,关于为什么会生成这个计划脚本的原因,是为了解决如下几个问题:
1、前面我们写的脚本在IN里面写的是两个常量值,并且是不同的值,所以形成了两个索引值的查找通过OR关键字组合,
这种方式貌似没问题,但是我们将这两个数值变成了参数,这就引来了新的问题,假如这两个参数我们输入的是相等的,那么利用前面的执行计划就会生成如下
[Northwind].[dbo].[Orders].[ShipPostalCode]=N'05022'
OR
[Northwind].[dbo].[Orders].[ShipPostalCode]=N'05022'
这样执行产生的输出结果就是2条一样的输出值!...但是表里面确实只有1条数据...所以这样输出结果不正确!
所以变成参数后首先解决的问题就是去重问题,2个一样的变成1个。
2、上面变成参数,还引入了另外一个问题,加入我们两个值有一个传入的为Null值,或者两个都为Null值,同样输出结果面临着这样的问题。所以这里还要解决的去Null值的问题。
为了解决上面的问题,我们来粗略的分析一下执行计划,看SQL Server如何解决这个问题的
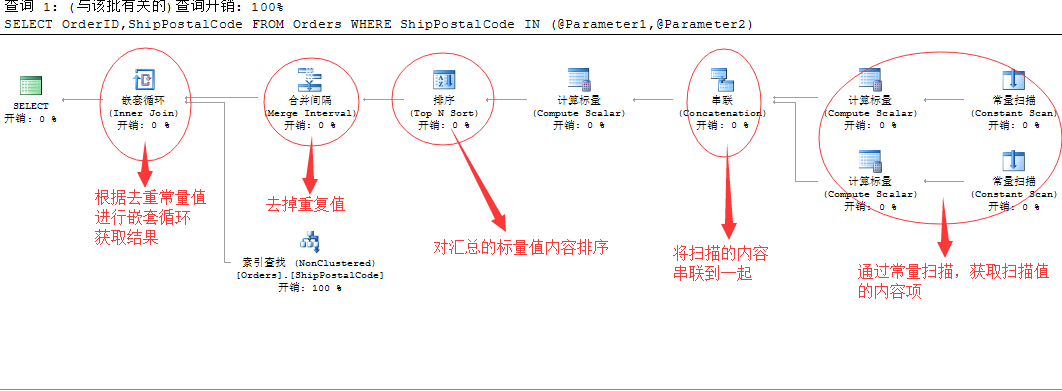
简单点将就是通过扫描变量中的值,然后将内容进行汇总值,然后在进行排序,再将参数中的重复值去掉,这样获取的值就是一个正确的值,最后拿这些去重后的参数值参与到嵌套循环中,和表Orders进行索引查找。
但是分析的过程中,有一个问题我也没看明白,就是最好的经过去重之后的常量汇总值,用来嵌套循环连接的时候,在下面的索引查找的时候的过滤条件变成了 and 查找
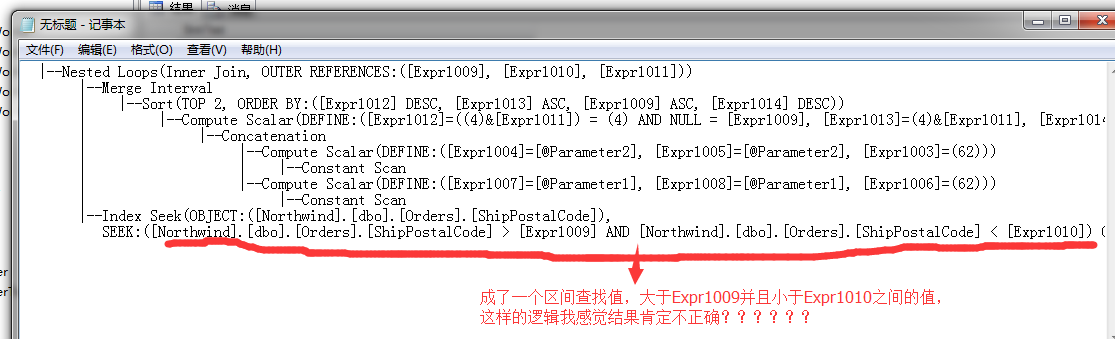
我将上面的最后的索引查找条件,整理如下:
|--Index Seek(OBJECT:([Northwind].[dbo].[Orders].[ShipPostalCode]), SEEK:
(
[Northwind].[dbo].[Orders].[ShipPostalCode] > [Expr1009]
AND
[Northwind].[dbo].[Orders].[ShipPostalCode] < [Expr1010]
) ORDERED FORWARD)
这个地方怎么搞的?我也没弄清楚,还望有看明白童鞋的稍加指导下....
好了,我们继续
上面的执行计划中,提到了一个新的运算符:合并间隔(merge interval operator)
我们来分析下这个运算符的作用,其实在上面我们已经在执行计划的图中标示出该运算符的作用了,去掉重复值。
其实关于去重的操作有很多的,比如前面文章中我们提到的各种去重操作。
这里怎么又冒出个合并间隔去重?其实原因很简单,因为我们在使用这个运算符之前已经对结果进行了排序操作,排序后的结果项重复值是紧紧靠在一起的,所以就引入了合并间隔的方式去处理,这样性能是最好的。
更重要的是合并间隔这种运算符应用场景不仅仅局限于重复值的去除,更重要的是还应用于重复区间的去除。
来看下面的例子
--参数化查询条件 DECLARE @Parameter1 DATETIME,@Parameter2 DATETIME SELECT @Parameter1='1998-01-01',@Parameter2='1998-01-04' SELECT OrderID FROM ORDERS WHERE OrderDate BETWEEN @Parameter1 AND DATEADD(DAY,6,@Parameter1) OR OrderDate BETWEEN @Parameter2 AND DATEADD(DAY,6,@Parameter2)
我们看看这个生成的查询计划项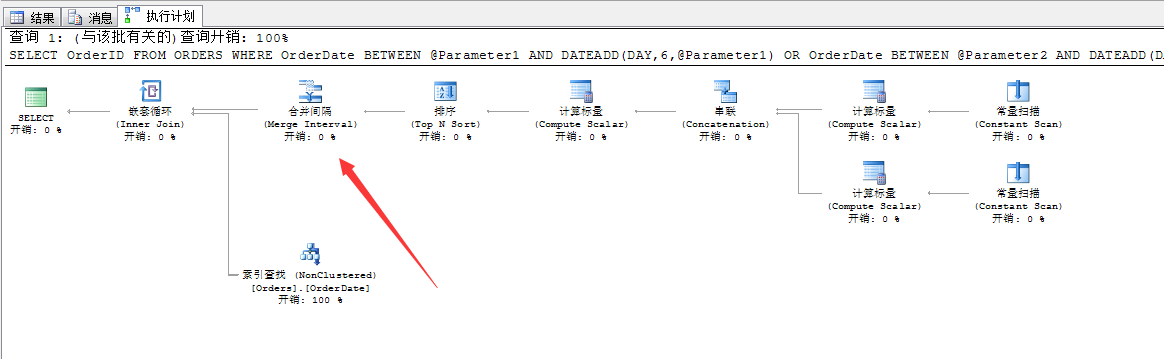
可以看到,SQL Server为我们生成的查询计划,和前面我们写的语句是一模一样的,当然我们的语句也没做多少改动,改动的地方就是查询条件上。
我们来分析下这个查询条件:
WHERE OrderDate BETWEEN @Parameter1 AND DATEADD(DAY,6,@Parameter1)
OR OrderDate BETWEEN @Parameter2 AND DATEADD(DAY,6,@Parameter2)
很简单的筛选条件,要获取订单日期在1998-01-01开始到1998-01-07内的值或者1998-01-04开始到1998-01-10内的值(不包含开始日期)
这里用的逻辑谓词为:OR...其实也就等同于我们前面写的IN
但是我们这里再分析一下,你会发现这两个时间段是重叠的

这个重复的区间值,如果用到前面的直接索引查找,在这段区间之内的搜索出来的范围值就是重复的,所以为了避免这种问题,SQL Server又引入了“合并间隔”这个运算符。
其实,经过上面的分析,我们已经分析出这种动态索引查找的优缺点了,有时候我们为了避免这种复杂的执行计划生成,使用最简单的方式就是直接传值进入语句中(当然这里需要重编译),当然大部分的情况我们写的程序都是只定义的参数,然后进行的运算。可能带来的麻烦就是上面的问题,当然有时候参数多了,为了合并间隔所应用的排序就消耗的内存就会增长。怎么使用,根据场景自己酌情分析。
二、索引联合
所谓的索引联合,就是根据就是根据筛选条件的不同,拆分成不同的条件,去匹配不同的索引项。
举个例子
SELECT OrderID FROM ORDERS WHERE OrderDate BETWEEN '1998-01-01' AND '1998-01-07' OR ShippedDate BETWEEN '1998-01-01' AND '1998-01-07'
这段代码是查询出订单中的订单日期在1998年1月1日到1998年1月7日的或者发货日期同样在1998年1月1日到1998年1月7日的。
逻辑很简单,我们知道在这种表里面这两个字段都有索引项。所以这个查询在SQL Server中就有了两个选择:
1、一次性的来个索引扫描根据匹配结果项输出,这样简单有效,但是如果订单表数据量比较大的话,性能就会很差,因为大部分数据就根本不是我们想要的,还要浪费时间去扫描。
2、就是通过两列的索引字段直接查找获取这部分数据,这样可以直接减少数据表的扫描量,但是带来的问题就是,如果分开扫描,有一部分数据就是重复的:那些同时在1998年1月1日到1998年1月7日的订单,发货日期也在这段时间内,因为两个扫描项都包含,所以再输出的时候需要将这部分重复数据去掉。
我们来看SQL Server如何选择
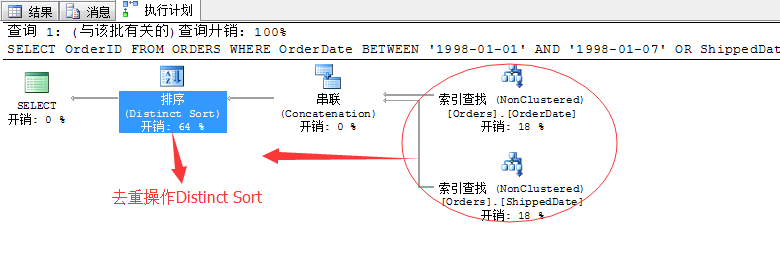
看来SQL Server经过评估选择了第2中方法。但是上面的方法也不尽完美,采用去重操作耗费了64%的资源。
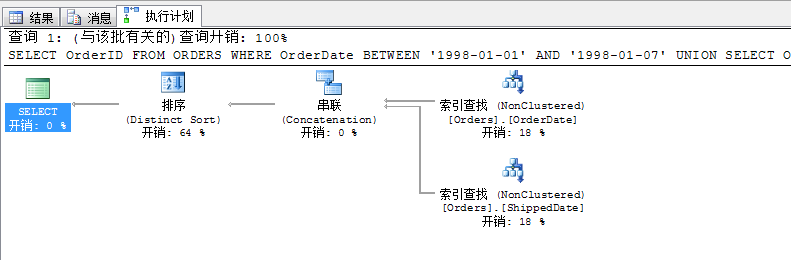
其实,上面的方法,我们根据生成的查询计划可以变通的使用以下逻辑,其效果和上面的语句是一样的,并且生成的查询计划也一样
SELECT OrderID FROM ORDERS WHERE OrderDate BETWEEN '1998-01-01' AND '1998-01-07' UNION SELECT OrderID FROM ORDERS WHERE ShippedDate BETWEEN '1998-01-01' AND '1998-01-07'
我们再来看一个索引联合的例子
SELECT OrderID FROM ORDERS WHERE OrderDate = '1998-01-01' OR ShippedDate = '1998-01-01'
我们将上面的Between and不等式筛选条件改成等式筛选条件,我们来看一下这样形成的执行计划
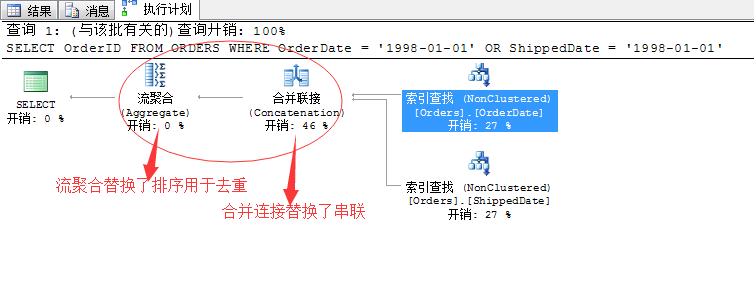
基本相同的语句,只是我们改变了不同的查询条件,但是生成的查询计划还是变化蛮大的,有几点不同之处:
1、前面的用between...and 的筛选条件,通过索引查找返回的值进行组合是用的串联的方式,所谓的串联就是两个数据集拼凑在一起就行,无所谓顺序连接什么的。
2、前面的用between...and 的筛选条件,通过串联拼凑的结果集去重的方式,是排序去重(Sort Distinct)...并且耗费了大量的资源。这里采用了流聚合来干这个事,基本不消耗
我们来分析以下产生着两点不同的原因有哪些:
首先、这里改变了筛选条件为等式连接,所通过索引查找所产生的结果项是排序的,并且按照我们所要查询的OrderID列排序,因此在两个数据集进行汇总的时候,正适合合并连接的条件!需要提前排序。所以这里最优的方式就是采用合并连接!
那么前面我们用between...and 的筛选条件通过索引查找获取的结果项也是排序的,但是这里它没有按照OrderID排序,它是按照OrderDate或者ShippedDate列排序的,而我们的结果是要OrderID列,所以这里的排序是没用的......所以SQL Server只能选择一个串联操作,将结果汇聚到一起,然后在排序了......我希望这里我已经讲明白了...
其次、关于去重操作,毫无疑问采用流聚合(Aggregate)这种方式最好,消耗内存少,速度又快...但是前提是要提前排序...前面选用的排序去重(Sort Distinct)纯属无奈之举...
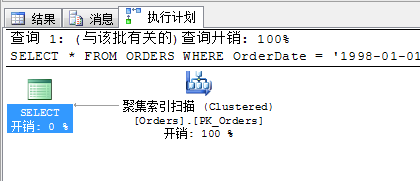
总结下:我们在写语句的时候能确定为等式连接,最好采用等式连接。还有就是如果能确定输出条件的最好能写入,避免多余的书签查找,还有万恶的SELEECT *....
如果写了万恶的SELECT *...那么你所写的语句基本上就可以和非聚集索引查找告别了....顶多就是聚集索引扫描或者RID查找...
瞅瞅以下语句
SELECT * FROM ORDERS WHERE OrderDate = '1998-01-01' OR ShippedDate = '1998-01-01'
最后,奉上一个AND的一个连接谓词的操作方式,这个方式被称为:索引交叉,意思就是说如果两个或多个筛选条件如果采用的索引是交叉进行的,那么使用一个就可以进行查询。
来看个语句就明白了
SELECT OrderID FROM ORDERS WHERE OrderDate = '1998-01-01' AND ShippedDate = '1998-03-05'
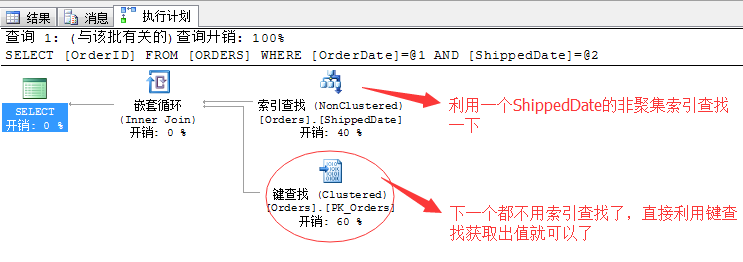
这里我们采用了的谓词连接方式为AND,所以在实际执行的时候,虽然两列都存在非聚集索引,理论都可以使用,但是我们只要选一个最优的索引进行查找,另外一个直接使用书签查找出来就可以。省去了前面介绍的各种神马排序去重....流聚合去重....等等不人性的操作。
看来AND连接符是一个很帅的运算符...所以很多时候我们在尝试写OR的情况下,不如换个思路改用AND更高效。
参考文献
- 微软联机丛书逻辑运算符和物理运算符引用
- 参照书籍《SQL.Server.2005.技术内幕》系列
结语
此篇文章主要介绍了索引运算的一些方式,主要是描述了我们平常在写语句的时候所应用的方式,并且举了几个例子,算作抛砖引玉吧,其实我们平常所写的语句中无非也就本篇文章中介绍的各种方式的更改,拼凑。而且根据此,我们该怎样建立索引也作为一个指导项。
下一篇我们介绍子查询一系列的内容,有兴趣可提前关注,关于SQL Server性能调优的内容涉及面很广,后续文章中依次展开分析。
有问题可以留言或者私信,随时恭候有兴趣的童鞋加入SQL SERVER的深入研究。共同学习,一起进步。
文章最后给出上几篇的连接,看来有必要整理一篇目录了.....
如果您看了本篇博客,觉得对您有所收获,请不要吝啬您的“推荐”。

