面向对象
一、面向对象概念引入(人狗大战)
在讲面向对象之前我们用一个简单的人狗大战来引入这个概念,让人可以更加直观的感受到什么是面向对象编程。
人狗大战简介
就是用代码编写一个简单的小游戏,人跟狗可以互相攻击,这里我们用字典记录数据值。
推导步骤1:代码定义出人和狗
"""推导步骤1:代码定义出人和狗"""
person1 = {
'name': 'jason',
'age': 18,
'gender': 'male',
'p_type': '猛男',
'attack_val': 8000,
'life_val': 99999999
}
person2 = {
'name': 'kevin',
'age': 28,
'gender': 'female',
'p_type': '淑女',
'attack_val': 1,
'life_val': 100
}
dog1 = {
'name': '小黑',
'd_type': '泰迪',
'attack_val': 100,
'life_val': 8000
}
dog2 = {
'name': '小白',
'd_type': '恶霸',
'attack_val': 2,
'life_val': 80000
}
ps:这里我们不难发现,频繁进行重复的操作不够方便,我们会想到使用函数封装功能,因此有了第二个阶段。
推导步骤2:将产生人和狗的字典封装成函数并封装人和狗的攻击函数
"""推导步骤2:将产生人和狗的字典封装成函数并封装人和狗的攻击函数"""
def create_person(name, age, gender, p_type, attack_val, life_val):
person_dict = {
'name': name,
'age': age,
'gender': gender,
'p_type': p_type,
'attack_val': attack_val,
'life_val': life_val
}
return person_dict
def create_dog(name, d_type, attack_val, life_val):
dog_dict = {
'name': name,
'd_type': d_type,
'attack_val': attack_val,
'life_val': life_val
}
return dog_dict
# 定义好了函数之后只要调用函数并传入参数就可以获得新定义的人与狗
p1 = create_person('jason', 18, 'male', '猛男', 8000, 99999999)
p2 = create_person('kevin', 28, 'female', '淑女', 100, 800)
d1 = create_dog('小黑', '恶霸', 800, 900000)
d2 = create_dog('小白', '泰迪', 100, 800000)
print(p1, p2)
print(d1, d2)
# 定义出人打狗的动作 狗咬人的动作
def person_attack(person_dict, dog_dict):
print(f"人:{person_dict.get('name')}准备揍狗:{dog_dict.get('name')}")
dog_dict['life_val'] -= person_dict.get('attack_val')
print(f"人揍了狗一拳 狗掉血:{person_dict.get('attack_val')} 狗剩余血量:{dog_dict.get('life_val')}")
def dog_attack(dog_dict, person_dict):
print(f"狗:{dog_dict.get('name')}准备咬人:{person_dict.get('name')}")
person_dict['life_val'] -= dog_dict.get('attack_val')
print(f"狗咬了人一口 人掉血:{dog_dict.get('attack_val')} 人剩余血量:{person_dict.get('life_val')}")
# 其实就是根据字典的值进行加减
person_attack(p1, d1)
dog_attack(d2, p2)
推导步骤3:人和狗的攻击混乱
到了这一步,这个小游戏就可以运行起来玩了,但是我们又发现一个小问题,人的攻击函数和狗的攻击函数,并没有限制使用对象,这就导致有时候会出现如下问题:
jason这个人会扮成狗狗咬人
有的狗又会扮成人打人
"""推导步骤3:人和狗的攻击混乱"""
person_attack(d1, p1)
dog_attack(p1, d2)
为了解决这个问题,我们想到了可以使用功能字典的方式把函数名称传进去。通过这样的方式限制功能的调用方式。
二、面向对象核心思路前戏
推导步骤4:如何实现只有人只能调用的人的攻击动作,狗只能调用狗的攻击动作>>>:数据与功能的绑定
"""推导步骤4:如何实现只有人只能调用的人的攻击动作 狗只能调用狗的攻击动作>>>:数据与功能的绑定"""
def get_person(name, age, gender, p_type, attack_val, life_val):
# 产生人的函数(功能)
def person_attack(person_dict, dog_dict):
print(f"人:{person_dict.get('name')}准备揍狗:{dog_dict.get('name')}")
dog_dict['life_val'] -= person_dict.get('attack_val')
print(f"人揍了狗一拳 狗掉血:{person_dict.get('attack_val')} 狗剩余血量:{dog_dict.get('life_val')}")
# 表示人的信息(数据)
person_dict = {
'name': name,
'age': age,
'gender': gender,
'p_type': p_type,
'attack_val': attack_val,
'life_val': life_val,
'person_attack': person_attack
}
return person_dict
def get_dog(name, d_type, attack_val, life_val):
def dog_attack(dog_dict, person_dict):
print(f"狗:{dog_dict.get('name')}准备咬人:{person_dict.get('name')}")
person_dict['life_val'] -= dog_dict.get('attack_val')
print(f"狗咬了人一口 人掉血:{dog_dict.get('attack_val')} 人剩余血量:{person_dict.get('life_val')}")
dog_dict = {
'name': name,
'd_type': d_type,
'attack_val': attack_val,
'life_val': life_val,
'dog_attack': dog_attack
}
return dog_dict
person1 = get_person('jason', 18, 'male', '猛男', 8000, 99999999)
dog1 = get_dog('小黑', '恶霸', 800, 900000)
person1.get('person_attack')(person1, dog1)
由于功能字典定义在生成人或生成狗的函数内,而查找变量名和函数名称的时候只能向外面的名称空间查找,因此我们就把攻击的函数定义在生成函数内,让功能字典刚好可以调用到攻击函数。
面向对象核心思想:数据与功能的绑定
通过上面的推导流程,其实就是达成了一个目的,让一个对象的数据值和功能绑定到一起,只有这个对象才能调用。
三、编程思想分析
我们平时听到的面向对象本质其实是一种编程思想大致可以分为两种
- 面向过程编程
- 面向对象编程
1、编程思想之面向过程编程
过程即流程,面向过程就是按照固定的流程解决问题,将程序的执行流程化,即分步操作,分步的过程中解决问题。
eg:截止ATM为止 使用的几乎都是面向过程编程
注册功能 登录功能 转账功能
上述功能都需要列举出每一步的流程,并且随着步骤的深入,问题的解决越来越简单。
ps:过程可以理解成是流水线,面向过程编程可以理解成是在创建一条流水线。我们先提出问题,然后制定出该问题的解决方案。
2.面向对象编程
对象的概念
”面向对象“的核心是“对象”二字,而对象的精髓在于“整合“,什么意思?
所有的程序都是由”数据”与“功能“组成,因而编写程序的本质就是定义出一系列的数据,然后定义出一系列的功能来对数据进行操作。在学习”对象“之前,程序中的数据与功能是分离开的。如下所示:
# 数据:name、age、sex
name='lili'
age=18
sex='female'
# 功能:tell_info
def tell_info(name,age,sex):
print('<%s:%s:%s>' %(name,age,sex))
# 此时若想执行查看个人信息的功能,需要同时拿来两样东西,一类是功能tell_info,另外一类则是多个数据name、age、sex,然后才能执行,非常麻烦
tell_info(name,age,sex)
对象其实就是一个"容器" 将数据与功能整合到一起,只要是符合上述描述的事物都可以称之为是对象!!! (python中一切皆对象)。
在学习了“对象”之后,我们就有了一个容器,该容器可以盛放数据与功能,所以我们可以说:对象是把数据与功能整合到一起的产物,或者说”对象“就是一个盛放数据与功能的容器/箱子/盒子。
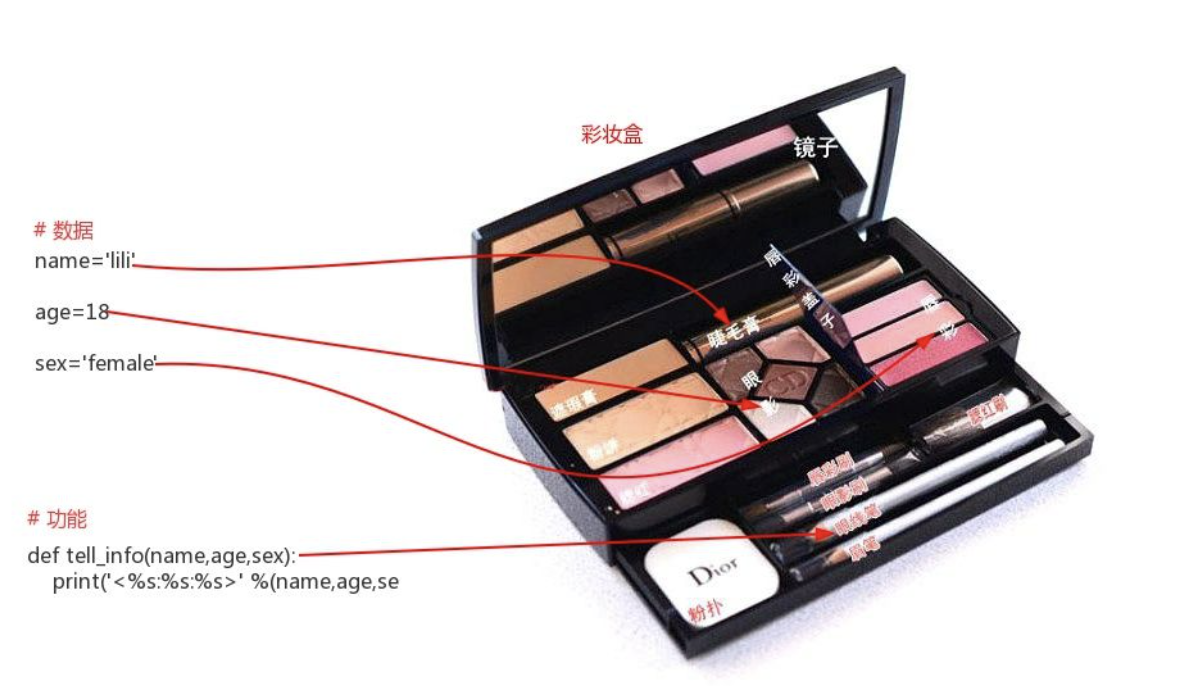
如果把”数据“比喻为”睫毛膏“、”眼影“、”唇彩“等化妆所需要的原材料;把”功能“比喻为眼线笔、眉笔等化妆所需要的工具,那么”对象“就是一个彩妆盒,彩妆盒可以把”原材料“与”工具“都装到一起。
如果我们把”化妆“比喻为要执行的业务逻辑,此时只需要拿来一样东西即可,那就是彩妆盒,因为彩妆盒里整合了化妆所需的所有原材料与功能,这比起你分别拿来原材料与功能才能执行,要方便的多。
eg:游戏人物:亚索 劫 盲僧
面向对象编程有点类似于造物主的感觉 我们只需要造出一个个对象
至于该对象将来会如何发展跟程序员没关系 也无法控制
上述两种编程思想没有优劣之分 需要结合实际需求而定:
如果需求是注册 登录 人脸识别肯定面向过程更合适
如果需求是游戏人物肯定是面向对象更合适
实际编程两种思想是彼此交融的 只不过占比不同
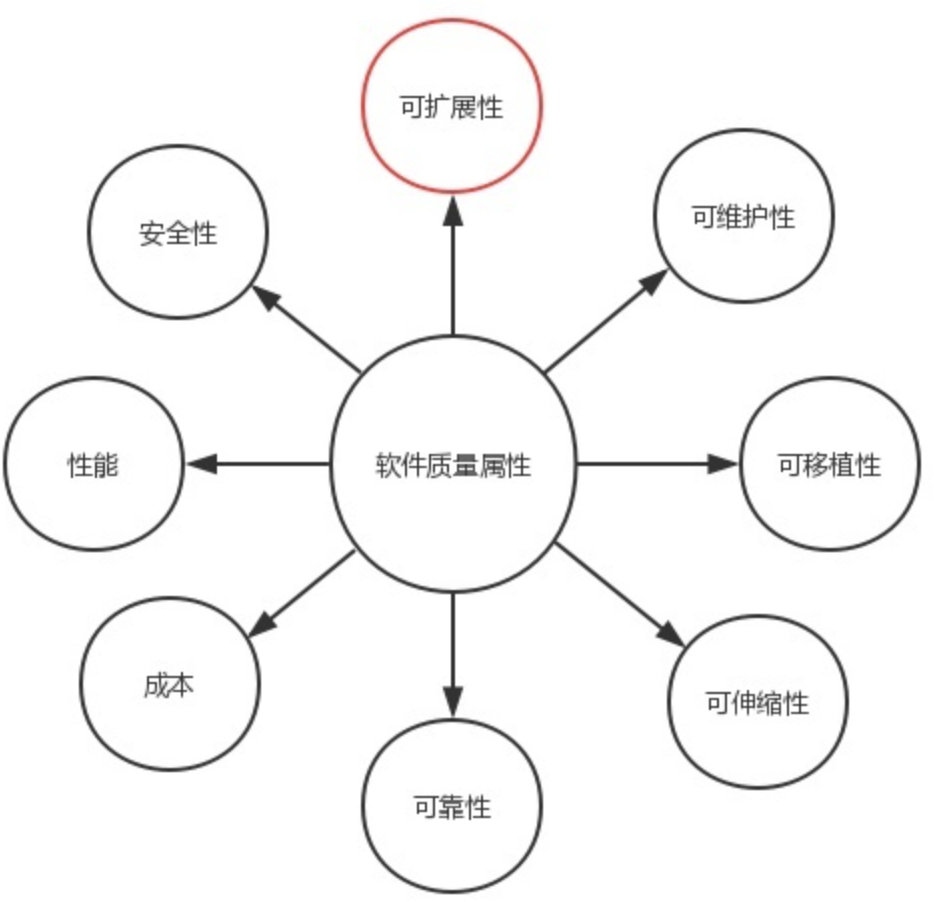
在了解了对象的基本概念之后,理解面向对象的编程方式就相对简单很多了,面向对象编程就是要造出一个个的对象,把原本分散开的相关数据与功能整合到一个个的对象里,这么做既方便使用,也可以提高程序的解耦合程度,进而提升了程序的可扩展性(需要强调的是,软件质量属性包含很多方面,面向对象解决的仅仅只是扩展性问题)
四、面向对象之类与对象
类即类别/种类,是面向对象分析和设计的基石,如果多个对象有相似的数据与功能,那么该多个对象就属于同一种类。有了类的好处是:我们可以把同一类对象相同的数据与功能存放到类里,而无需每个对象都重复存一份,这样每个对象里只需存自己独有的数据即可,极大地节省了空间。所以,如果说对象是用来存放数据与功能的容器,那么类则是用来存放多个对象相同的数据与功能的容器。
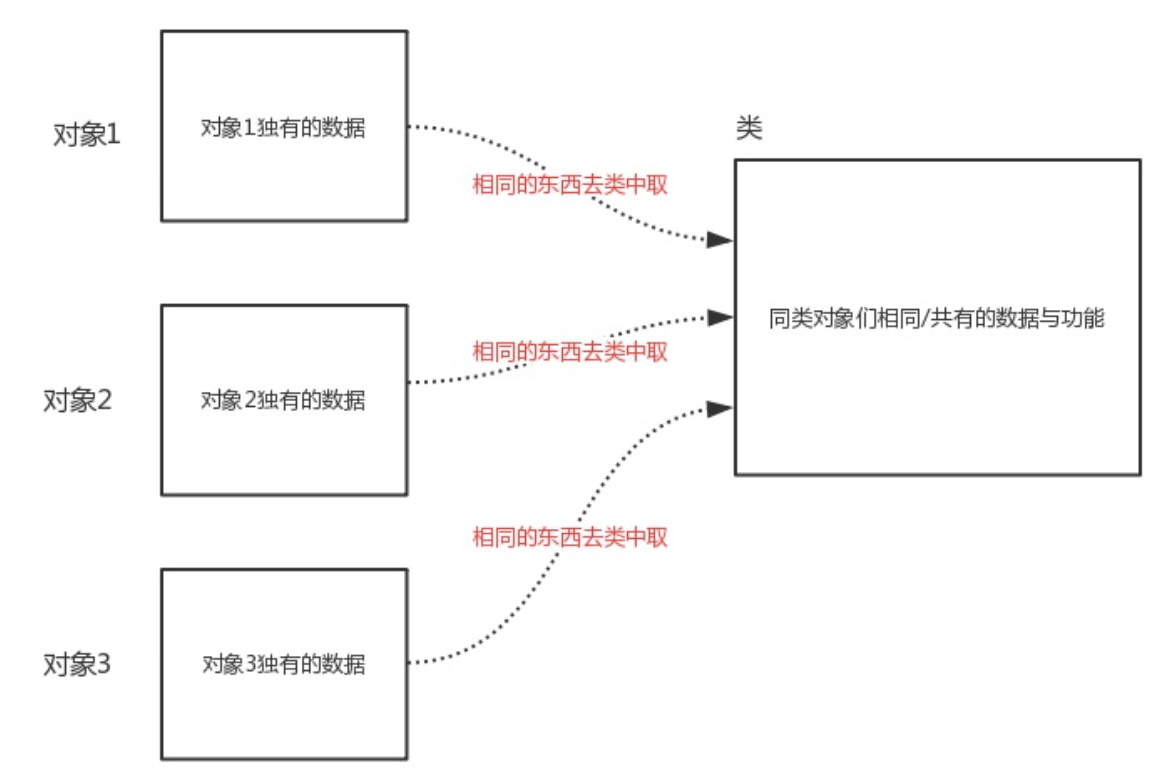
综上所述,虽然我们是先介绍对象后介绍类,但是需要强调的是:在程序中,必须要事先定义类,然后再调用类产生对象(调用类拿到的返回值就是对象)。产生对象的类与对象之间存在关联,这种关联指的是:对象可以访问到类中共有的数据与功能,所以类中的内容仍然是属于对象的,类只不过是一种节省空间、减少代码冗余的机制,面向对象编程最终的核心仍然是去使用对象。
在了解了类与对象这两大核心概念之后,我们就可以来介绍一下面向对象编程啦。
对象:数据与功能的结合体 对象才是核心
类:多个对象相同数据和功能的结合体 类主要就是为了节省代码
"""
一个人 对象
一群人 人类(所有人相同的特征)
一条狗 对象
一群狗 犬类(所有狗相同的特征)
"""
现实中一般是先有对象再有类
程序中如果想要产生对象 必须要先定义出类
说的再直白一点,就是先通过类创建对象,这时候的对象内部没有自己特有的内容,但是有类中公共的数据值和功能,当我们给他加上自己特有的内容后,这个对象就有了其他的功能和数据。
五、类与对象的创建
面向对象并不是一门新的技术 但是为了很好的一眼区分开 针对面向对象设计了新的语法格式
python中一定要有类 才能借助于类产生对象
1.类的语法结构
class 类名:
'''代码注释'''
对象公共的数据
对象公共的功能
1.class是定义类的关键字
2.类名的命名与变量名几乎一致 需要注意的时候首字母推荐大写用于区分
3.数据:变量名与数据值的绑定 功能(方法)其实就是函数
2.类的定义与调用
类在定义阶段就会执行类体代码 但是属于类的局部名称空间 外界无法直接调用
# 需求:清华大学学生选课系统
# 定义类
class Student:
# 对象公共的数据
school_name = '清华大学'
# 对象公共的功能
def choice_course(self):
print('学生选课功能')
1.查看名称空间
我们使用点+双下dict的方法获得类的名称空间,但是这并不意味类就是一个字典,只是我们用字典的形式给他表现出来。其次我们还可以在双下dict后接点+get(名称)来获得值或函数地址
# 查看名称空间
print(Student.__dict__)
# {'__module__': '__main__', 'school_name': '清华大学', 'choice_course': <function Student.choice_course at 0x0000024179E670D0>, '__dict__': <attribute '__dict__' of 'Student' objects>, '__weakref__': <attribute '__weakref__' of 'Student' objects>, '__doc__': None}
print(Student.__dict__.get('school_name'))
# 清华大学
print(Student.__dict__.get('choice_course'))
# <function Student.choice_course at 0x0000024179E670D0>
2.类和对象访问数据或者功能
在面向对象中,类和对象访问数据或者功能,可以统一采用句点符。
print(Student.school_name)
# 清华大学
print(Student.choice_course)
# <function Student.choice_course at 0x0000024602B770D0>
3.产生对象和查看\修改对象中的内容
类名加括号就会产生对象,并且每执行一次都会产生一个全新的对象。
obj1 = Student()
变量名obj1接收类名加括号之后的返回值(结果)是产生一个新的对象,这里会产生三个不同对象。
obj2 = Student()
obj3 = Student()
print(obj1, obj2, obj3)
# <__main__.Student object at 0x0000020A848A4A60> <__main__.Student object at 0x0000020A848DF100> <__main__.Student object at 0x0000020A848DF2E0>
print(obj1.__dict__)
对象自己目前什么都没有
# {}
print(obj2.__dict__)
# {}
print(obj3.__dict__)
# {}
通过点+名称的方式修改类中的值
print(obj1.school_name)
# 清华大学
print(obj2.school_name)
# 清华大学
print(obj3.school_name)
# 清华大学
Student.school_name = '家里蹲大学'
print(obj1.school_name)
# 家里蹲大学
print(obj2.school_name)
# 家里蹲大学
print(obj3.school_name)
# 家里蹲大学
ps:数据和功能,也可以统称为属性
数据>>>属性名
功能>>>:方法
六、对象独有的数据推导流程
class Student:
# 对象公共的数据
school_name = '清华大学'
# 对象公共的功能
def choice_course(self):
print('学生选课功能')
obj1 = Student()
obj2 = Student()
推导流程1:每个对象手动添加独有的数据
添加方式跟字典新增键值对类似
print(obj1.__dict__)
# {} 手动加入独有数据前
obj1.__dict__['name'] = 'jason'
obj1.__dict__['age'] = 18
obj1.__dict__['hobby'] = 'study'
print(obj1.__dict__)
# {'name': 'jason', 'age': 18, 'hobby': 'study'}
print(obj1.name)
# jason
print(obj1.age)
# 18
print(obj1.hobby)
# study
print(obj2.__dict__)
# {}
obj2.__dict__['name'] = 'kevin'
obj2.__dict__['age'] = 28
obj2.__dict__['hobby'] = 'music'
print(obj2.__dict__)
# {'name': 'kevin', 'age': 28, 'hobby': 'music'}
print(obj2.name)
# kevin
print(obj2.age)
# 28
print(obj2.hobby)
# music
推导流程2:将添加对象独有数据的代码封装成函数
def init(obj, name, age, hobby):
obj.__dict__['name'] = name
obj.__dict__['age'] = age
obj.__dict__['hobby'] = hobby
stu1 = Student()
stu2 = Student()
生成两个对象
init(stu1, 'jason', 18, 'music')
init(stu2, 'kevin', 29, 'read')
添加独有数据
print(stu1.__dict__)
# {'name': 'jason', 'age': 18, 'hobby': 'music'}
print(stu2.__dict__)
# {'name': 'kevin', 'age': 29, 'hobby': 'read'}
推导流程3:给学生对象添加独有数据的函数只有学生对象有资格调用
这里就是人狗大战中限制调用的那一步
class Student:
# 对象公共的数据
school_name = '清华大学'
# 专门给学生添加独有数据的功能
def init(obj, name, age, hobby):
obj.__dict__['name'] = name
obj.__dict__['age'] = age
obj.__dict__['hobby'] = hobby
# 对象公共的功能
def choice_course(self):
print('学生选课功能')
创建对象谈价独有数据
stu1 = Student()
Student.init(stu1, 'jason', 18, 'music')
stu2 = Student()
Student.init(stu2, 'kevin', 29, 'read')
print(stu1.__dict__, stu2.__dict__)
# {'name': 'jason', 'age': 18, 'hobby': 'music'} {'name': 'kevin', 'age': 29, 'hobby': 'read'}
stu1.choice_course()
# 学生选课功能
推导步骤4:init方法变形
这里其实没什么变化,就是把init变成了双下init然后查看调用的时候需要几个参数。
class Student:
# 对象公共的数据
school_name = '清华大学'
# 专门给学生添加独有数据的功能 类产生对象的过程中自动触发
def __init__(obj, name, age, hobby):
obj.__dict__['name'] = name
obj.__dict__['age'] = age
obj.__dict__['hobby'] = hobby
# 对象公共的功能
def choice_course(self):
print('学生选课功能')
stu1 = Student('jason', 18, 'read')
print(stu1.__dict__)
# {'name': 'jason', 'age': 18, 'hobby': 'read'}
print(stu1.name)
# jason
print(stu1.school_name)
# 清华大学
我们不难发现,现在这个状况下调用类创建对象只需要三个参数了,并且不需要先创建对象了。其实双下init的作用就是在你调用类方法的时候会自动把当前对象当作第一个参数传进来,让你节省了一步。
推导步骤5:变量名修改
class Student:
# 对象公共的数据
school_name = '清华大学'
# 专门给学生添加独有数据的功能 类产生对象的过程中自动触发
def __init__(self, name, age, hobby):
self.name = name # self.__dict__['name'] = name
self.age = age
self.hobby = hobby
# 对象公共的功能
def choice_course(self):
print('学生选课功能')
stu1 = Student('jason', 18, 'read')
print(stu1.name)
# jason
print(stu1.school_name)
# 清华大学
因为上面把init变成双下init之后就不需要传第一个参数确定方法执行对象了,因此python这边是建议我们使用self来充当这里的参数名称,当然了,其他名字也是一样的效果。
七、对象独有的功能推导流程
所谓功能,其实就是具有一定功能的函数,把这个函数变成对象独有的。
class Student:
# 对象公共的数据
school_name = '清华大学'
# 专门给学生添加独有数据的功能 类产生对象的过程中自动触发
def __init__(self, name, age, hobby):
self.name = name # self.__dict__['name'] = name
self.age = age
self.hobby = hobby
# 对象公共的功能
def choice_course(self):
print(f'学生{self.name}正在选课')
stu1 = Student('jason', 18, 'music')
stu2 = Student('kevin', 28, 'read')
1.直接在全局定义功能
直接在全局定义功能,但是该函数就不是学生对象独有的了。
def eat():
print('吃东西')
stu1.eat = eat
print(stu1.__dict__)
# {'name': 'jason', 'age': 18, 'hobby': 'music', 'eat': <function eat at 0x000001DCB291A4C0>}
stu1.eat()
# 吃东西
2.把功能定义在类中
定义在类中的功能,默认就是绑定给对象使用的,谁来调谁就是主人公
# Student.choice_course(123) # 类调用需要自己传参数
# choice_course(stu1) 对象调用会自动将对象当做第一个参数传入
stu1.choice_course()
stu1.choice_course()
stu2.choice_course()
# 学生jason正在选课
# 学生jason正在选课
# 学生kevin正在选课
# 对象修改数据值
stu1.name = 'tony' # 当点的名字已经存在的情况下 则修改对应的值
# 对象新增数据值
stu1.pwd = 123 # 当点的名字不存在的情况下 则新增数据
print(stu1.__dict__)
# {'name': 'tony', 'age': 18, 'hobby': 'music', 'pwd': 123}
八、动静态方法
昨天我们学习了类中可以存放函数并且公共功能和一些函数独有的功能其实是放在一起的,我们在给对象调用独有方法的时候其实就是把这个方法给他传一份过去,变成独有的。
那说了这么多,其实类中的函数是可以设置调用条件的——也就是我们所说的动静态方法。
动态方法
分成两种方法,第一种就是我们昨天学习的,单纯的函数,第二种是使用@classmethod语法糖装饰的函数。
单纯的函数我们发现对象调用可以少写一个参数(调用者的参数可以不写),类来自己调用的时候需要给他写上参数。
第二种方式就是无论对象还是类,你来用都可以少写一个参数。
class Student:
school_name = '摆烂大学'
# 1.类中直接定义函数 默认绑定给对象 类调用有几个参数传几个 对象调用第一个参数就是对象自身
def func1(self):
print('看谁最能摆烂 真的好棒棒!!!')
# 2.被@classmethod修饰的函数 默认绑定给类 类调用第一个参数就是类自身 对象也可以调用并且会自动将产生该对象的类当做第一个参数传入
@classmethod
def func2(cls):
print('嘿嘿嘿 猜猜我是干嘛滴', cls)
# 3.普普通通的函数 无论是类还是对象调用 都必须自己手动传参
@staticmethod
def func3(a):
print('哈哈哈 猜猜我又是什么', a)
obj = Student()
# 1.绑定给对象的方法
obj.func1()
Student.func1(123)
Student.func1(Student)
# 其实就是必须得有个参数,也可以随便给
# 2.绑定给类的方法
Student.func2() # fun2(Student)
obj.func2() # func2(Student)
print(Student)
静态方法
使用时代码接上面
静态方法就相当于python不帮我们做任何偷懒操作了,所有的参数都需要传。
Student.func3(Student)
obj.func3(321)
九、面向对象之继承的概念
面向对象三大特性
封装 继承 多态
1.三者中继承最为核心(实操最多 体验最强)
2.封装和多态略微抽象
1.继承的含义
-
继承是一种创建新类的方式,在Python中,新建的类可以继承一个或多个父类,新建的类可称为子类或派生类,父类又可称为基类或超类。
-
根据继承的数量可以分为单继承和多继承。
'''单继承和多继承简单定义'''
class Parent1:
pass
class Parent2:
pass
class Sub1(Parent1): #单继承
pass
print(Sub1.__bases__) # 查看自己的父类---->(<class '__main__.Parent1'>,)
class Sub2(Parent1,Parent2): # 多继承
pass
print(Sub2.__bases__) # 查看自己的父类---->(<class '__main__.Parent1'>, <class '__main__.Parent2'>)
例:在现实生活中继承表示人与人之间资源的从属关系
eg:儿子继承父亲 干女儿继承干爹
在编程世界中继承表示类与类之间资源的从属关系
eg:类A继承类B
2.继承的目的
- 在现实生活中儿子继承父亲就拥有了父亲所有资源的支配权限
- 在编程世界中类A继承类B就拥有了类B中所有的数据和方法使用权限
3.继承解决了什么问题
- 类解决对象与对象之间代码冗余的问题,子类可以遗传父类的属性
- 继承解决的是类与类之间代码冗余的问题
- object类丰富了代码的功能
4.多继承的优缺点
- 优点:子类可以同时遗传多个父类的属性,最大限度的重用代码
- 缺点:违反人的思维习惯,一个人有两个爹,代码的可读性会变差,不建议使用多继承.
- 继承表达的是一种“是”什么的关系
5.继承的实操
class Son(Father):
pass
1.在定义类的时候类名后面可以加括号填写其他类名 意味着继承其他类
2.在python支持多继承 括号内填写多个类名彼此逗号隔开即可
class Son(F1, F2, F3):
pass
1.继承其他类的类 Son
我们称之为子类、派生类
2.被继承的类 Father F1 F2 F3
我们称之为父类、基类、超类
ps:我们最常用的就是子类和父类
十、继承的本质
继承中类与对象的作用
对象:数据与功能的结合体
类(子类):多个对象相同数据和功能的结合体
父类:多个类(子类)相同数据和功能结合体
ps:类与父类本质都是为了节省代码
继承本质应该分为两部分
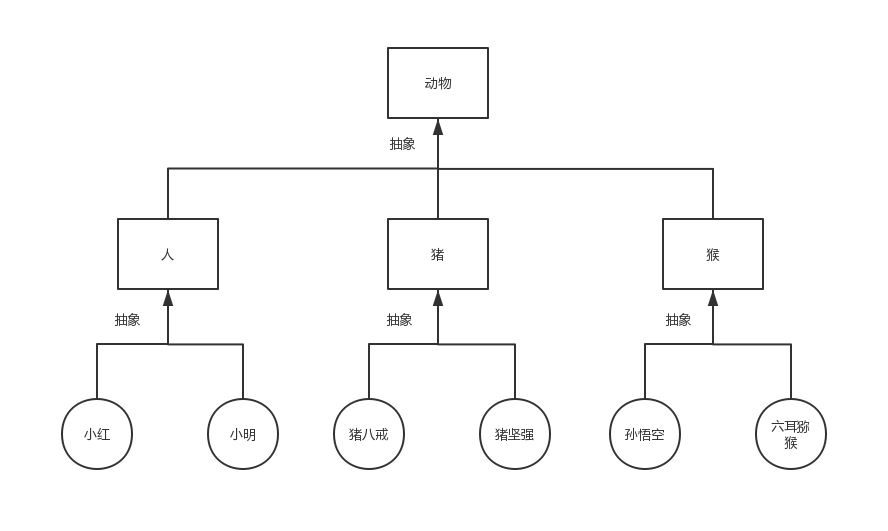
抽象:
将多个类相同的东西抽出去形成一个新的类
继承:
将多个类继承刚刚抽取出来的新的类
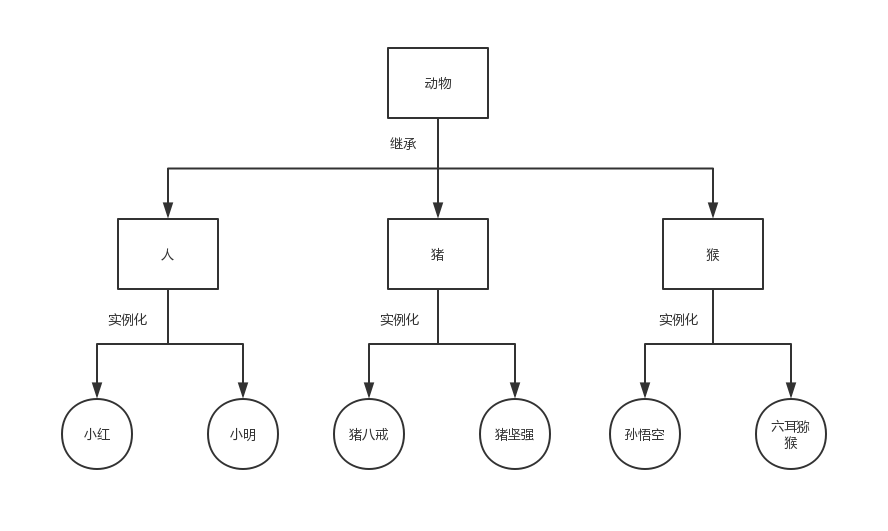
抽象即总结相似之处,总结对象之间的相似之处得到类,总结类与类之间的相似之处就可以得到父类,如下图所示:
基于抽象的结果,我们就找到了继承关系:
基于上图我们可以看出类与类之间的继承指的是什么’是’什么的关系(比如人类,猪类,猴类都是动物类)。子类可以继承/遗传父类所有的属性,因而继承可以用来解决类与类之间的代码重用性问题。比如我们按照定义Student类的方式再定义一个Teacher类:
class Teacher:
school='清华大学'
def __init__(self,name,sex,age):
self.name=name
self.sex=sex
self.age=age
def teach(self):
print('%s is teaching' %self.name)
类Teacher与Student之间存在重复的代码,老师与学生都是人类,所以我们可以得出如下继承关系,实现代码重用:
class People:
school='清华大学'
def __init__(self,name,sex,age):
self.name=name
self.sex=sex
self.age=age
class Student(People):
def choose(self):
print('%s is choosing a course' %self.name)
class Teacher(People):
def teach(self):
print('%s is teaching' %self.name)
Teacher类内并没有定义__init__方法,但是会从父类中找到__init__,因而仍然可以正常实例化,如下:
>>> teacher1=Teacher('lili','male',18)
>>> teacher1.school,teacher1.name,teacher1.sex,teacher1.age
('清华大学', 'lili', 'male', 18)
十一、名字的查找顺序
1.不继承情况下名字的查找顺序
1.不继承情况下名字的查找顺序
class C1:
name = 'jason'
def func(self):
print('from func')
obj = C1()
# print(C1.name) # 类肯定找的自己的
obj.name = '你迷了吗' # 由于对象原本没有name属性 该语法会在对象名称空间中创建一个新的'键值对'
print(obj.__dict__)
print(obj.name) # 你迷了吗
print(C1.name)
"""
对象查找名字的顺序
1.先从自己的名称空间中查找
2.自己没有再去产生该对象的类中查找
3.如果类中也没有 那么直接报错
对象自身 >>> 产生对象的类
"""
2.单继承情况下名字的查找顺序
2.单继承情况下名字的查找顺序
# class F1:
# name = 'jason'
# class S1(F1):
# name = 'kevin'
# obj = S1()
# obj.name = 'oscar'
# print(obj.name)
'''
对象自身 >>> 产生对象的类 >>> 父类
'''
# class F3:
# # name = 'jerry'
# pass
#
# class F2(F3):
# # name = 'tony'
# pass
#
# class F1(F2):
# # name = 'jason'
# pass
#
# class S1(F1):
# # name = 'kevin'
# pass
# obj1 = S1()
# # obj1.name = '嘿嘿嘿'
# print(obj1.name)
例题:
class A1:
def func1(self):
print('from A1 func1')
def func2(self):
print('from A1 func2')
self.func1()
class B1(A1):
def func1(self):
print('from B1 func1')
obj = B1()
obj.func2()
- 查找顺序讲解
先在obj的名称空间中查找,找不到就去B1中查找,因为B1的父系是A1,所以最后会在A1中找到func2。
func2中又出现了一格self.func1(),这时候我们应该把他拿出来看,这行代码就相当于在外面另外写了一个obj.func1(),因此这里调用的是B1中的func1.
强调:对象点名字 永远从对象自身开始一步步查找
以后在看到self.名字的时候 一定要搞清楚self指代的是哪个对象
3.多继承情况下名字的查找顺序
广度优先:
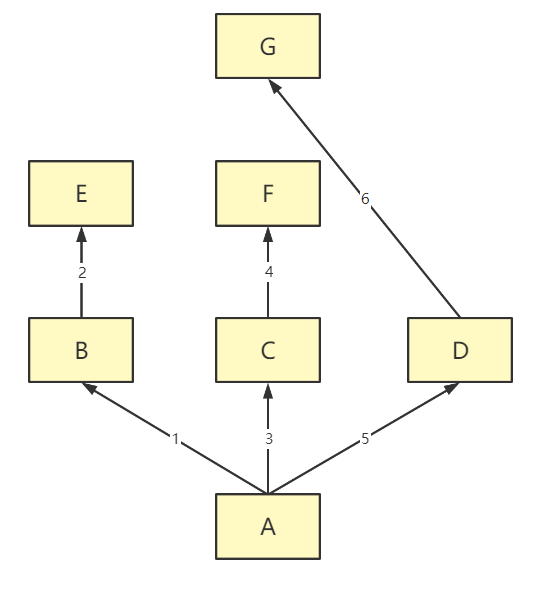
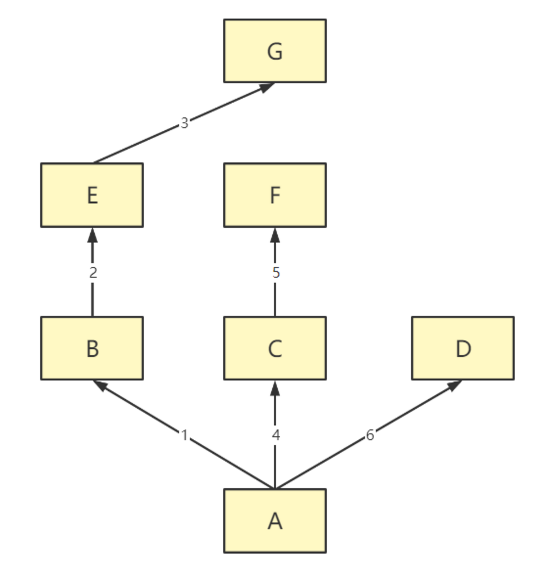
深度优先:
特殊情况
-
菱形继承
广度优先(最后才会找闭环的定点)
当我们继承的顺序如下图形成闭环的时候,会先根据广度优先顺序查找,最后才回去最上面的闭环处查找。
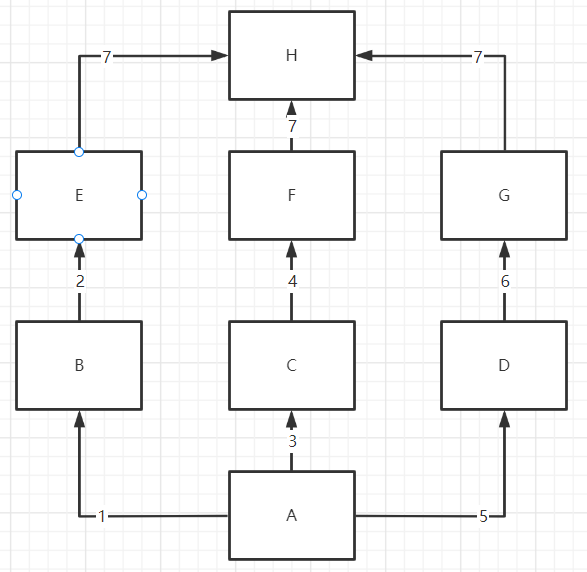
-
非菱形继承
深度优先(从左往右每条道走完为止,也就是普通的查找顺序)
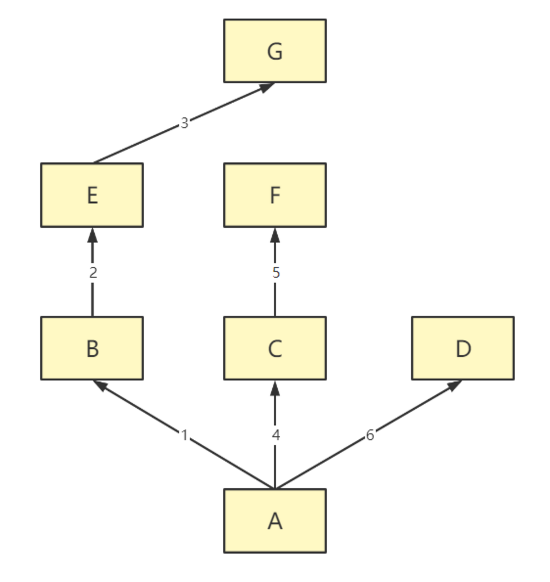
ps:mro()方法可以直接获取名字的查找顺序
对象自身 >>> 产生对象的类 >>> 父类(从左往右)
# class F1:
# # name = 'jason'
# pass
#
#
# class F2:
# # name = 'oscar'
# pass
#
# class F3:
# # name = 'jerry'
# pass
#
# class S1(F1, F2, F3):
# # name = '嘿嘿嘿'
# pass
# obj = S1()
# # obj.name = '想干饭'
# print(obj.name)
'''
对象自身 >>> 产生对象的类 >>> 父类(从左往右)
'''
class G:
name = 'from G'
pass
class A:
# name = 'from A'
pass
class B:
# name = 'from B'
pass
class C:
# name = 'from C'
pass
class D(A):
# name = 'from D'
pass
class E(B):
# name = 'from E'
pass
class F(C):
# name = 'from F'
pass
class S1(D,E,F):
pass
obj = S1()
# print(obj.name)
print(S1.mro())
十二、经典类与新式类
在Python 2及以前的版本中,由任意内置类型派生出的类(只要一个内置类型位于类树的某个位置),都属于“新式类”,都会获得所有“新式类”的特性;反之,即不由任意内置类型派生出的类,则称之为“经典类”。
“新式类”和“经典类”的区分在Python 3之后就已经不存在,在Python 3.x之后的版本,因为所有的类都派生自内置类型object(即使没有显示的继承object类型),即所有的类都是“新式类”。
概括
经典类:不继承object或者其子类的类
新式类:继承object或者其子类的类
在python2中有经典类和新式类
在python3中只有新式类(所有类默认都继承object)
ps:这里的object类,可以看成一个虚的东西,在名称查找的时候虽然出现了闭环,但是因为他是虚的所以不影响查找顺序。
class Student(object):pass
ps:以后我们在定义类的时候 如果没有其他明确的父类,也可能习惯写object兼容python2(虽然遇到python2的可能性很小了)
十三、派生方法
这里主要用到一个super()方法,所谓派生方法就是子类基于父类的某个方法做了拓展或是增加了一些条件。
class Person:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Student(Person):
def __init__(self, name, age, gender, sid):
super().__init__(name, age, gender) # 子类调用父类的方法
self.sid = sid
class Teacher(Person):
def __init__(self, name, age, gender, level):
super().__init__(name, age, gender)
self.level = level
stu1 = Student('jason', 18, 'male', 666)
print(stu1.__dict__)
学生类可以在创建对象的时候调用父类的方法,并且还可以添加自己独有的数据
tea1 = Teacher('tony', 28, 'female', 99)
print(tea1.__dict__)
老师类也跟学生类一样,可以添加独有的数据
class MyList(list):
def append(self, values):
if values == 'jason':
print('jason不能尾部追加')
return
super().append(values)
当我们想要做一些限制条件的时候也可以在类中添加。
obj = MyList()
print(obj, type(obj))
obj.append(111)
obj.append(222)
obj.append(333)
obj.append('jason')
print(obj)
十四、派生方法实战
这里的例子用到了dumps方法举例子,当我们使用dumps转换数据值的时候如果遇到变量名就会报错。通过ctrl+数据包左键点进去的方式查看内部的代码结构,我们发现dumps的注释中提到只有部分数据类型是可以转换的,像变量名那样的数据值并不在内。
之后我们看到代码中的cls关键字参数就是主动报错的代码。因此我们想到可以麻溜的用上派生方法,在发现当前数据类型不能直接转换的时候,我们获取这个变量名的数据值,然后给他送进去转换,就圆满达成目标了。当然,我们简单粗暴一点,把获得结果外面套个str()也可以达成目标
import json
import datetime
d = {
't1': datetime.date.today(),
't2': datetime.datetime.today(),
't3': 'jason'
}
# res = json.dumps(d)
# print(res)
"""
序列化报错
raise TypeError(f'Object of type {o.__class__.__name__} '
TypeError: Object of type date is not JSON serializable
"""
"""
能够被序列化的数据是有限的>>>:里里外外都必须是下列左边的类型
+-------------------+---------------+
| Python | JSON |
+===================+===============+
| dict | object |
+-------------------+---------------+
| list, tuple | array |
+-------------------+---------------+
| str | string |
+-------------------+---------------+
| int, float | number |
+-------------------+---------------+
| True | true |
+-------------------+---------------+
| False | false |
+-------------------+---------------+
| None | null |
+-------------------+---------------+
"""
# 1.转换方式1:手动转类型(简单粗暴)
d = {
't1': str(datetime.date.today()),
't2': str(datetime.datetime.today())
}
res = json.dumps(d)
print(res)
# 2.转换方式2:派生方法(儒雅高端)
"""
查看dumps源码 注意cls参数 默认传JsonEncoder
查看该类的源码 发现default方法是报错的发起者
编写类继承JsonEncoder并重写default方法 之后调用dumps手动传cls=我们自己写的类
"""
class MyJsonEncoder(json.JSONEncoder):
def default(self, o):
"""
:param o: 接收无法被序列化的数据
:return: 返回可以被序列化的数据
"""
if isinstance(o, datetime.datetime): # 判断是否是datetime类型 如果是则处理成可以被序列化的类型
return o.strftime('%Y-%m-%d %X')
elif isinstance(o, datetime.date):
return o.strftime('%Y-%m-%d')
return super().default(o) # 最后还是调用原来的方法 防止有一些额外操作没有做
res = json.dumps(d, cls=MyJsonEncoder)
print(res)
十五、面向对象三大特性之封装
封装:指的就是把数据与功能都整合到一起
封装数据的目的:保护隐私
功能封装的目的:隔离复杂度
分两步实现:隐藏与开放接口
隐藏属性
Python的Class机制采用双下划线开头的方式将属性隐藏起来(设置成私有的),但其实这仅仅只是一种变形操作,类中所有双下滑线开头的属性都会在类定义阶段、检测语法时自动变成“_类名__属性名”的形式:
class Foo:
__N=0 # 变形为_Foo__N
def __init__(self): # 定义函数时,会检测函数语法,所以__开头的属性也会变形
self.__x=10 # 变形为self._Foo__x
def __f1(self): # 变形为_Foo__f1
print('__f1 run')
def f2(self): # 定义函数时,会检测函数语法,所以__开头的属性也会变形
self.__f1() #变形为self._Foo__f1()
print(Foo.__N) # 报错AttributeError:类Foo没有属性__N
obj = Foo()
print(obbj.__x) # 报错AttributeError:对象obj没有属性__x
虽然我们发现这些类中定义的名字不能直接用了,但是我们需要知道这些类中的双下开头的名字只是变了个形式,如果我们知道了这些名字的格式和种类名称,就可以使用全程访问类中的隐藏起来的名字。
同时,我们在类中定义别的函数调用这些隐藏起来的函数的话,是不需要写上隐藏后的名字的,直接调用函数即可。
注:python中没有绝对的隐藏,因此要不要直接用这些隐藏函数也是一种君子规定。
如何调用隐藏属性
class MyClass:
school_name = '老女孩大学'
_ = '嘿嘿嘿'
_name = 'tony'
'''类在定义阶段 名字前面有两个下划线 那么该名字会被隐藏起来 无法直接访问'''
__age = 18
"""在python中其实没有真正意义上的隐藏 仅仅是换了个名字而已 _类名__名字"""
def __choice_course(self):
print('老北鼻正在选课')
print(MyClass.school_name)
# 老女孩大学
obj = MyClass()
print(obj.school_name)
# 老女孩大学
print(MyClass._)
# 嘿嘿嘿
print(MyClass._name)
# tony
MyClass.__hobby = 'JDB' # 无法隐藏
print(MyClass.__hobby)
# JDB
obj = MyClass()
obj.__addr = '派出所'
print(obj.__addr)
# 派出所
print(MyClass.__dict__)
# {'__module__': '__main__', 'school_name': '老女孩大学', '_': '嘿嘿嘿', '_name': 'tony', '_MyClass__age': 18, '_MyClass__choice_course': <function MyClass.__choice_course at 0x00000222BC04A4C0>, '__dict__': <attribute '__dict__' of 'MyClass' objects>, '__weakref__': <attribute '__weakref__' of 'MyClass' objects>, '__doc__': None, '__hobby': 'JDB'}
print(MyClass._MyClass__age)
# 18
-
通过上面的代码进行尝试后,我们发现在python中其实没有真正意义上的隐藏,仅仅是换了个名字而已,_类名__名字。
-
同时只有在类的定义阶段,名字前面有两个下划线的名称才会被隐藏起来,无法直接访问。如果在对象中使用两个下划线+名称的方式,得到的只是一个普通的变量名,并没有隐藏的效果。
隐藏属性的作用和使用方式
将数据隐藏起来就限制了类外部对数据的直接操作,然后类内应该提供相应的接口来允许类外部间接地操作数据,接口之上可以附加额外的逻辑来对数据的操作进行严格地控制
ps:隐藏是将数据和功能隐藏起来不让用户直接调用,而是开发一些接口间接调用,从而可以在接口内添加额外的操作。
class Person:
def __init__(self, name, age, hobby):
self.__name = name # 对象也可以拥有隐藏的属性
self.__age = age
self.__hobby = hobby
def get_info(self):
# 类体代码中 是可以直接使用隐藏的名字
print(f"""
姓名:{self.__name}
年龄:{self.__age}
爱好:{self.__hobby}
""")
# 隐藏的属性开放修改的接口 可以自定义很多功能
def set_name(self, new_name):
if len(new_name) == 0:
raise ValueError('你好歹写点东西')
if new_name.isdigit():
raise ValueError('名字不能是数字')
self.__name = new_name
obj = Person('jason', 18, 'read')
obj.get_info()
# obj.set_name('tony老师')
# obj.get_info()
obj.set_name('')
这里我们把人这个类创建时候的属性变成隐藏的,同时定义查看函数查案和修改这些隐藏的值(也就是创建接口进行控制)
以后我们在编写面向对象代码类的定义时,也会看到很多单下划线开头的名字,表达的意思通常是提示不要直接访问,而是让我们查找一下,下面可能了定义了接口。
十六、伪装
伪装的操作
可以将类中的函数“伪装成”对象的数据属性,对象在访问该特殊属性时会触发功能的执行,然后将返回值作为本次访问的结果(将类里面的方法伪装成类里面的数据)
ps:使用了伪装之后,就不能以加括号的形式调用了
这里我们使用BMI的计算来引入伪装的装饰器和语法糖:
# BMI指数:衡量一个人的体重与身高对健康影响的一个指标
# 体质指数(BMI)=体重(kg)÷身高^2(m)
# EX:70kg÷(1.75×1.75)=22.86
class Person(object):
def __init__(self, name, height, weight):
self.name = name
self.height = height
self.weight = weight
@property
def BMI(self):
return self.weight / (self.height ** 2)
p1 = Person('jason', 1.83, 78)
# p1.BMI() # BMI应该作为人的基本数据而不是方法
# print(p1.BMI) # 利用装饰器伪装成数据
这里介绍了property装饰器,它的功能很简单,就是实现伪装的功能,让我们节省掉用时候的小括号,并且把函数运行的结果输出。
两个小功能:删除和修改
@name.setter
这个是修改值
@name.deleter
这个是删除值
class Foo:
def __init__(self, val):
self.__NAME = val # 将属性隐藏起来
@property
def name(self):
return self.__NAME
@name.setter
def name(self, value):
if not isinstance(value, str): # 在设定值之前进行类型检查
raise TypeError('%s must be str' % value)
self.__NAME = value # 通过类型检查后,将值value存放到真实的位置self.__NAME
@name.deleter
def name(self):
raise PermissionError('Can not delete')
f = Foo('jason')
print(f.name)
f.name = 'jason123'
print(f.name)
del f.name
# f.name = 'jason' # 触发name.setter装饰器对应的函数name(f,’jason')
# f.name = 123 # 触发name.setter对应的的函数name(f,123),抛出异常TypeError
# del f.name # 触发name.deleter对应的函数name(f),抛出异常PermissionError
十七、面向对象三大特性之多态
概念讲解
多态更像是一种概念,一种墨守成规的约定,当我们在创建类的时候,如果出现几个功能相似的类,那我们在定义他们内部方法的时候需要把类似的功能名称设置成一样,这样的话当我们调用的时候不用刻意记忆方法名称,统一使用即可。
举例说明:
现实中水有很多形态,固态液态和气态。这里我们拿气态举例,不是只有水才能是气态,其他的很多物质也可以在特定条件下变成气态,但是当我们描述气态的东西时,使用的语言和探究的方向都是相同的。这些相同的东西就跟多态要求的作用是一样的。
这里我们引入python崇尚的‘鸭子类型’(duck typing):“如果看起来像、叫声像而且走起路来像鸭子,那么它就是鸭子”。
class Animal:
def spark(self):
'''叫的方法'''
pass
class Cat(Animal):
# def miao(self):
# print('喵喵喵')
def spark(self):
print('喵喵喵')
class Dog(Animal):
# def wang(self):
# print('汪汪汪')
def spark(self):
print('汪汪汪')
class Pig(Animal):
# def heng(self):
# print('哼哼哼')
def spark(self):
print('哼哼哼')
面向对象中多态意思:
一种事物可以有多种形态,但是针对相同的功能应该定义相同的方法。这样无论我们拿到的是哪个具体的事物,都可以通过相同的方法调用功能。
s1 = 'hello world'
l1 = [11, 22, 33, 44]
d = {'name': 'jason', 'pwd': 123}
print(s1.__len__())
print(l1.__len__())
print(d.__len__())
比如这里的双下len方法,不同数据类型调用的时候都是使用相同的函数名调用功能。
文件 能够读取数据也能够保存数据
内存 能够读取数据也能够保存数据
硬盘 能够读取数据也能够保存数据
......
class File:
def read(self): pass
def write(self): pass
class Memory:
def read(self): pass
def write(self): pass
class Disk:
def read(self): pass
def write(self): pass
上面的一切皆文件(类似的,我们可以通过这里理解一句众所周知的话:python中一切皆对象)
多态中的约束方法
虽然python永远提倡自由简介大方,不约束程序员行为,但是多态提供了约束的方法。
导入abc模块后使用装饰器@abc.abstractmethod,我们可以发现必须要有一个名为talk的方法,这里就相当于强制要求了,内部功能可以自定义。
import abc
# 指定metaclass属性将类设置为抽象类,抽象类本身只是用来约束子类的,不能被实例化
class Animal(metaclass=abc.ABCMeta):
@abc.abstractmethod # 该装饰器限制子类必须定义有一个名为talk的方法
def talk(self): # 抽象方法中无需实现具体的功能
pass
class Cat(Animal): # 但凡继承Animal的子类都必须遵循Animal规定的标准
def talk(self):
pass
cat = Cat() # 若子类中没有一个名为talk的方法则会抛出异常TypeError,无法实例化
十八、面向对象之反射
推导思路
1、当我们用对象进行操作的时候,修改查看数据值都是用点的方式+名称
2、为了让这个代码简洁一点,我们想到使用input获取用户输入,然后用参数的形式来调用
3、但是这时候我们还是发现不行,因为input获取的是字符串,不是变量名那样的形式,导致报错。
4、虽然这里走到死胡同了,但是python做了反射这个东西来实现对象和用户的交互。
反射功能介绍
什么是反射:
反射就是通过字符串的形式去对象(模块)中操作(查找/获取/删除/添加)成员
反射的本质(核心):基于字符串的事件驱动,利用字符串的形式去操作对象/模块中成员(方法、属性)
在Python中,反射指的是通过字符串来操作对象的属性,涉及到四个内置函数的使用:
1.hasattr() 重点
- 判断对象是否含有某个字符串对应的属性名或方法名
2.getattr() 重点
- 根据字符串获取对象对应的属性的值或方法名(函数体代码)的结果
3.setattr()
- 根据字符串给对象设置或者修改数据
4.delattr()
- 根据字符串删除对象里面的名字
class Teacher:
def __init__(self,full_name):
self.full_name =full_name
t=Teacher('jason Lin')
# hasattr(object,'name')
hasattr(t,'full_name') # 按字符串'full_name'判断有无属性t.full_name
# getattr(object, 'name', default=None)
getattr(t,'full_name',None) # 等同于t.full_name,不存在该属性则返回默认值None
# setattr(x, 'y', v)
setattr(t,'age',18) # 等同于t.age=18
# delattr(x, 'y')
delattr(t,'age') # 等同于del t.age
十九、反射案例
cmd终端(简易版)
这里我们用代码创建一个建议的cmd终端(当然了,内部数据弄简陋一点也没事):
# 模拟cmd终端
class WinCmd:
def tasklist(self):
print("""
1.学习编程
2.学习python
3.学习英语
""")
def ipconfig(self):
print("""
地址:127.0.0.1
地址:上海浦东新区
""")
def get(self, target_file):
print('获取指定文件', target_file)
def put(self, target_file):
print('上传指定文件', target_file)
def server_run(self):
print('欢迎进入简易版本cmd终端')
while True:
target_cmd = input('请输入您的指令>>>:')
res = target_cmd.split(' ')
if len(res) == 1:
if hasattr(self, res[0]):
getattr(self, res[0])()
else:
print(f'{res[0]}不是内部或者外部命令')
elif len(res) == 2:
if hasattr(self, res[0]):
getattr(self, res[0])(res[1])
else:
print(f'{res[0]}不是内部或者外部命令')
obj = WinCmd()
obj.server_run()
总体思路如下:
1、我们创个类当成小的cmd
2、类中定义各个函数充当执行命令时的功能
3、弄一个启动函数,内部需要具备相应的逻辑关系来调用其他功能函数。比如我们考虑到cmd中的命令是用一个空格隔开的,因此我们用split通过空格分开数据值,然后如果是一个的数据值,直接把他放到getatter中执行获取结果,如果长度不是一个的话就我们就把第二个的数据值当成参数传给第一个数据值代表的方法。如果还有别的更长的方法,那就要另外写代码设置了。
从文件中拿名字(简单证明一切皆对象)
import settings
print(dir(settings)) # dir列举对象可以使用的名字
useful_dict = {}
for name in dir(settings):
if name.isupper():
useful_dict[name] = getattr(settings, name)
print(useful_dict)
while True:
target_name = input('请输入某个名字')
if hasattr(settings, target_name):
print(getattr(settings, target_name))
else:
print('该模块文件中没有该名字')
思路:
1、我们把一个文件当模块直接导入,并用dir方法查看内部有那些名字
2、根据名字的种类,分成方法名称和变量名称
3、根据当前打开的是settings文件,我们想到内部名称需要都是大写,因此我们用一个for循环筛选出大写的名称
4、我们跟第一个例子一样,用input获取输入然后使用hasatter判断有没有这玩意,然后有的话就打印结果,没得话就返回提示信息。
二十、面向对象的魔法方法
魔法方法:是指方法名以两个下划线开头并以两个下划线结尾的方法
特点:调用时不需要人为调用,只要在特定条件下就会自动触发运行。
例如我们最开始学习类的时候使用到的双下init方法,就是在创建空对象之后自动触发给对象添加独有的数据。
1.__init__
类名加括号 给对象添加独有数据时自动触发
class C(object):
def __init__(self, name):
self.name = name
2.___str__
对象在被执行打印操作的时候自动触发,该方法返回什么打印的结果就是什么
并且该方法必须要返回一个字符串类型的数据
def __str__(self):
return f'对象:{self.name}'
3.__call__
对象加括号调用的时候自动触发 该方法返回什么对象调用之后的返回值就是什么
def __call__(self, *args, **kwargs):
print('__call__')
print(args, kwargs)
return 123
在使用双下call的时候要注意,返回值不能是self,会引起递归,从而出现报错的情况
4.__getattr__
对象在查找无法使用的名字(没有的名字)时自动触发,该方法的返回值是什么,点不存在的名字就可以得到什么
def __getattr__(self, item):
# print('__getattr__')
# print(item)
return f'抱歉 您索要的名字{item}压根不存在'
5.__getattribute__
对象在查找名字的时候就会自动触发该方法,有它的存在就不会执行上面的__getattr__
def __getattribute__(self, item):
# print('__getattribute__')
return '哈哈哈'
# print(type(item))
# if hasattr(self, item):
# return getattr(self, item)
# return f'抱歉 {item}名字不存在'
6.__setattr__
当对象执行 对象.名字=值 的时候就会自动触发
给对象添加或者修改数据的时候自动触发 对象.名字 = 值
def __setattr__(self, key, value):
# print('__setattr__')
# print(key, value)
pass
7.__enter__
当对象被当做with上下文管理操作的开始自动触发,并且该方法返回什么 as后面的变量名就会接收到什么(就我们平时写的f那里的名称)
def __enter__(self):
return 123
8.__exit__
当对象参与with上下文管理语法运行完毕之后自动触发(子代码结束)
def __exit__(self, exc_type, exc_val, exc_tb):
f.close()
我们在学习文件操作的时候不是说了,两种操作方式,with方式打开文件不需要使用f.close()关闭文件。
这里就相当于在结束的时候出发了双下exit然后内部执行了f.close()。
二十一、魔法方法笔试题
1.补全下列代码使得运行不报错即可
class Context:
pass
with Context() as f:
f.do_something()
答案如下:
class Context:
def do_something(self):
pass
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
pass
with Context() as f:
f.do_something()
2.自定义字典类型并让字典能够通过句点符的方式操作键值对
class MyDict(dict):
def __setattr__(self, key, value):
self[key] = value
def __getattr__(self, item):
return self.get(item)
obj = MyDict()
obj.name = 'jason'
obj.pwd = 18
obj.hobby = 'read'
# print(obj)
print(obj.name)
print(obj.pwd)
print(obj.hobby)
# print(obj)
# print(obj) # 字典存储的数据 {}
# print(obj.__dict__) # 字典对象名称空间 {'name': 'jason'}
print(type(obj))
二十二、元类
1、元类简介
1.元类定义推导
"""推导步骤1:如何查看数据的数据类型"""
s1 = 'hello world' # str()
l1 = [11, 22, 33, 44] # list()
d1 = {'name': 'jason', 'pwd': 123} # dict()
t1 = (11, 22, 33, 44) # tuple()
print(type(s1)) # <class 'str'>
print(type(l1)) # <class 'list'>
print(type(d1)) # <class 'dict'>
print(type(t1)) # <class 'tuple'>
我们使用type查看数据类型的时候发现这些类型的前面都有一个class,也就是说明所有的这些数据类型其实都是一个个不同的类。
"""推导步骤2:其实type方法是用来查看产生对象的类名"""
class Student:
pass
obj = Student()
print(type(obj)) # <class '__main__.Student'>
通过上面的尝试,我们发现使用type可以查看对象的产生者,也就是产生对象的类的名字
"""推导步骤3:python中一切皆对象 我们好奇type查看类名显示的是什么"""
class Student:
pass
obj = Student()
print(type(obj)) # <class '__main__.Student'>
print(type(Student)) # <class 'type'>
class A: pass
class B: pass
print(type(A), type(B))
这里我们发现,产生type的类还是type,因此我们把产生类的类称作元类
"""结论:我们定义的类其实都是由type类产生的>>>:元类(产生类的类)"""
2.元类介绍
什么是元类呢?一切源自于一句话:python中一切皆为对象。
通过上面的推导流程,我们可以结合之前所学的知识点发现,几乎我们所有的对象都是实例化(调用类产生对象)得到的。
2、创建元类的两种方式
方式一:
使用关键字class
class Teacher:
school_name = '老女儿'
def func1(self):pass
print(Teacher)
print(Teacher.__dict__)
方式二:
利用元类type type(类名,类的父类,类的名称空间)
cls = type('Student', (object,), {'name':'jason'})
print(cls)
print(cls.__dict__)
"""
了解知识:名称空间的产生
1.手动写键值对
缺点:针对绑定方法不好定义
2.内置方法exec
能够运行字符串类型的代码并产生名称空间
"""
3、元类定制类的产生行为
"""
推导
对象是由类名加括号产生的 __init__
类是由元类加括号产生的 __init__
"""
这里我们自定义一个元类,来实现下面的目的:
"""所有的类必须首字母大写 否则无法产生"""
# 1.自定义元类:继承type的类也称之为元类
class MyMetaClass(type):
def __init__(self, what, bases=None, dict=None):
# print('what', what)
# print('bases', bases)
# print('dict', dict)
if not what.istitle():
raise TypeError('你是不是python程序员 懂不懂规矩 类名首字母应该大写啊!!!')
super().__init__(what, bases, dict)
# 2.指定类的元类:利用关键字metaclass指定类的元类
class myclass(metaclass=MyMetaClass):
desc = '元类其实很有趣 就是有点绕'
class Student(metaclass=MyMetaClass):
info = '我是学生 我很听话'
print(Student)
print(Student.__dict__)
代码运行流程简述:
1、类创建对象时,其实是先调用元类中的双下init产生一个空的对象。我们在双下init这里使用派生的方式,写上判断条件,如果生成独有数据值的参数不是关键字参数,那么直接主动报错,否则就直接调用type那边的双下init直接达成创建空类(通过一切皆对象来理解这里为什么是类)的操作。
4、元类定制对象的产生行为
"""
推导
对象加括号会执行产生该对象类里面的 __call__
类加括号会执行产生该类的类里面的 __call__
"""
这里我们自定义一个元类,来实现下面的目的:
"""给对象添加独有数据的时候 必须采用关键字参数传参"""
通过上面定制类的操作,我们得知产生对象的流程如下:
1.产生一个空对象(骨架)
2.调用__init__给对象添加独有的数据(血肉)
3.返回创建好的对象
因此这个判断参数是否为关键字的操作还是放在自定义元类中
class MyMetaClass(type):
def __call__(self, *args, **kwargs):
# print(args) # ('jason', 18, 'male')
# print(kwargs) # {}
if args:
raise TypeError("你怎么回事 Jason要求对象的独有数据必须按照关键字参数传参 我看你是不想干了!!!")
return super().__call__(*args, **kwargs)
class Student(metaclass=MyMetaClass):
def __init__(self, name, age, gender):
# print('__init__')
self.name = name
self.age = age
self.gender = gender
# obj = Student('jason', 18, 'male')
obj = Student(name='jason',age= 18,gender= 'male')
print(obj.__dict__)
代码运行流程简述:
1、类创建对象时,其实是先调用元类中的双下call产生一个空的对象。我们在双下call这里使用派生的方式,写上判断条件,如果生成独有数据值的参数不是关键字参数,那么直接主动报错,否则就直接调用type那边的双下call直接达成创建空对象的操作。
2、我们创建出一个空的对象后,才是到类代码中的双下init这里执行添加参数的操作
3、接着把创建好的对象返回出去
5、魔法方法之双下new
上面我们说了类在创建对象的时候是使用对应的元类中的双下call来创建一个空的对象的,然后才到双下init中进行添加独有数据值的操作,这里我们要引出一个魔法方法——双下new,他就是产生空对象的代码。
ps:小知识点,双下new来自object中
class MyMetaClass(type):
def __call__(self, *args, **kwargs):
# 1.产生一个空对象(骨架)
obj = self.__new__(self)
# 2.调用__init__给对象添加独有的数据(血肉)
self.__init__(obj,*args, **kwargs)
# 3.返回创建好的对象
return obj
class Student(metaclass=MyMetaClass):
def __init__(self, name):
self.name = name
obj = Student('jason')
print(obj.name)
"""
__new__可以产生空对象
"""
代码运行流程简述:
1、类创建对象时,其实是先调用元类中的双下call产生一个空的对象。产生空对象用的是双下new方法
2、我们创建出一个空的对象后,调用双下init进行添加数据值的操作
3、接着把创建好的对象返回出去
二十三、设计模式简介
1.设计模式
对软件设计中普遍存在(反复出现)的各种问题,所提出的解决方案。每一个设计模式都系统地命名、解释和评价了面向对象系统中一个重要的和重复出现的设计。
设计模式分成三大类,总共有23种
创建型模式(5种):工厂方法模式、抽象工厂模式、创建者模式、原型模式、单例模式
结构型模式(7种):适配器模式、桥模式、组合模式、装饰模式、外观模式、享元模式、代理模式
行为型模式(11种):解释器模式、责任链模式、命令模式、迭代器模式、中介者模式、备忘录模式、观察者模式、状态模式、策略模式、访问者模式、模板方法模式
2.单例模式
类加括号无论执行多少次永远只会产生一个对象
目的:
当类中有很多非常强大的方法 我们在程序中很多地方都需要使用
如果不做单例 会产生很多无用的对象浪费存储空间
我们想着使用单例模式 整个程序就用一个对象
from abc import abstractmethod, ABCMeta
class Singleton:
def __new__(cls, *args, **kwargs):
if not hasattr(cls, "_instance"):
cls._instance = super(Singleton, cls).__new__(cls)
return cls._instance
class MyClass(Singleton):
def __init__(self, a):
self.a = a
a = MyClass(10)
b = MyClass(20)
print(a.a)
print(b.a)
print(id(a), id(b))
二十四、单例模式实现的多种方式
方式一:使用类
class C1:
__instance = None
def __init__(self, name, age):
self.name = name
self.age = age
@classmethod
# 使用装饰器,让类加括号调用的时候也可以省略一个参数
def singleton(cls):
# 判断cls(也就是self)有没有这个属性,也就是判断之前内部有没有创建出__instance这个对象,如果有了就直接把他返回出去,如果没有就根据设定的参数创建一个
if not cls.__instance:
cls.__instance = cls('jason', 18)
return cls.__instance
# 这里的意思是如果不传参数产生新的对象,始终调用的是同一个对象
obj1 = C1.singleton()
obj2 = C1.singleton()
obj3 = C1.singleton()
print(id(obj1), id(obj2), id(obj3))
obj4 = C1('kevin', 28)
obj5 = C1('tony', 38)
print(id(obj4), id(obj5))
方法二:使用metaclass方式(自定义元类)
class Mymeta(type):
def __init__(self, name, bases, dic): # 定义类Mysql时触发
# 事先先从配置文件中取配置来造一个Mysql的实例出来(创建类的时候就给这个类创建一个默认对象)
self.__instance = object.__new__(self) # 产生对象
self.__init__(self.__instance, 'jason', 18) # 初始化对象
# 上述两步可以合成下面一步
# self.__instance=super().__call__(*args,**kwargs)
# 这里就是用type的代码生成新的类
super().__init__(name, bases, dic)
def __call__(self, *args, **kwargs): # Mysql(...)时触发
# 当类定义好了之后,被用来创建对象的时候就会触发双下call,如果没有传参就直接返回之前创建类时定义的默认对象,如果有参数就会生成新的对象返回出去
if args or kwargs: # args或kwargs内有值
obj = object.__new__(self)
self.__init__(obj, *args, **kwargs)
return obj
return self.__instance
class Mysql(metaclass=Mymeta):
def __init__(self, name, age):
self.name = name
self.age = age
# 这里的思路跟上面的相似,如果不传参数产生新的对象,始终调用的是同一个对象
obj1 = Mysql()
obj2 = Mysql()
print(id(obj1), id(obj2))
obj3 = Mysql('tony', 321)
obj4 = Mysql('kevin', 222)
print(id(obj3), id(obj4))
方法三:自定义双下new
# 类加括号无论执行多少次永远只会产生一个对象
class Singleton_:
def __new__(self, *args, **kwargs):
if not hasattr(self, '_instance'):
self._instance = super(Singleton_, self).__new__(self)
return self._instance
# 我们通过今天的学习得知双下new是产生对象的方法,因此我们在这里进行派生操作,
# 用hasatter检测当前类是是否已经有创建过对象,如果没有就新建一个(使用super拿元类的双下new直接创建),如果有就返回有的那个对象
a = Singleton_()
b = Singleton_()
print(a)
print(b)
方法四:基于模块的单例模式
在一个py文件中创建一个对象,然后让外面的代码一直调用这个类,从而达到单例模式的目的。
'''基于模块的单例模式:提前产生一个对象 之后导模块使用'''
class C1:
def __init__(self, name):
self.name = name
obj = C1('jason')
def outer(cls):
_instance = cls('jason', 18)
def inner(*args, **kwargs):
if args or kwargs:
obj = cls(*args, **kwargs)
return obj
return _instance
return inner
@outer # Mysql=outer(Mysql)
class Mysql:
def __init__(self, host, port):
self.host = host
self.port = port
obj1 = Mysql()
obj2 = Mysql()
obj3 = Mysql()
print(obj1 is obj2 is obj3) # True
obj4 = Mysql('1.1.1.3', 3307)
obj5 = Mysql('1.1.1.4', 3308)
print(obj3 is obj4) # False
二十五、pickle序列化模块
优势:
python中几乎所有的数据类型(列表,字典,集合,类等)都可以用pickle来序列化,我们的对象也可以。
缺陷:
1、只能够在python中使用,无法跨语言传输
2、pickle序列化后的数据,可读性差,人一般无法识别。(都是二进制,能看懂也不是一般人了)
方法介绍:
pickle.dump(obj, file[, protocol])
序列化对象,并将结果数据流写入到文件对象中。参数protocol是序列化模式,默认值为0,表示以文本的形式序列化。protocol的值还可以是1或2,表示以二进制的形式序列化。
pickle.load(file)
反序列化对象。将文件中的数据解析为一个Python对象。
其中要注意的是,在load(file)的时候,要让python能够找到类的定义,否则会报错:
注:pickle模块保存数据的文件是没有格式的
"""
需求:产生一个对象并保存到文件中 取出来还是一个对象
"""
class C1:
def __init__(self, name, age):
self.name = name
self.age = age
def func1(self):
print('from func1')
def func2(self):
print('from func2')
obj = C1('jason', 18)
# 这里的对象,并不能以对象的格式存储到文件中,因此我们使用pickle模块
import pickle
with open(r'a.txt', 'wb') as f:
pickle.dump(obj, f)
with open(r'a.txt', 'rb') as f:
data = pickle.load(f)
print(data)
# <__main__.C1 object at 0x0000026712C75BB0>


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)