常用内置模块
一、常用内置模块(部分第三方模块需要自己下载)
因为功能相似的代码会被归类到一个py文件中,因此我们需要了解一些常用内置模块的功能。
1、collections模块
提供了除基础数据类型外的一些数据类型
1.具名元组:namedtuple
调用语句如下:
from collections import namedtuple
这个数据类型的作用是生成一个可以用名称来访问元素内容的元组,然后我们可以根据数据的名称返回对应的信息。
from collections import namedtuple
# 表示二维坐标系
point = namedtuple('点', ['x', 'y'])
# 生成点信息
p1 = point(1, 2)
print(p1) # 点(x=1, y=2)
print(p1.x) # 1
print(p1.y) # 2
card = namedtuple('扑克牌', ['num', 'color'])
c1 = card('A', '黑♠')
c2 = card('A', '红♥')
print(c1, c1.num, c1.color) # 扑克牌(num='A', color='黑♠') A 黑♠
print(c2, c2.num, c2.color) # 扑克牌(num='A', color='红♥') A 红♥
2.双向列表:deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
队列:先进先出
栈:后进先出,也就是先进后出
from collections import deque
q = deque(['a', 'b', 'c'])
q.append('x')
# 往后面插入数据值,跟列表一样
q.appendleft('y')
# 从前面直接插入数据值
print(q)
# deque(['y', 'a', 'b', 'c', 'x'])
deque除了实现list的append和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
拓展:
队列
1、队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。
栈(stack):
1、栈(stack)又名堆栈,它是一种运算受限的线性表。其限制是仅允许在表的一端进行插入和删除运算。这一端被称为栈顶,相对地,把另一端称为栈底,栈就相当于一个有底的水桶,出栈的过程就像倒出水的过程,是先进后出。
2、栈(Stack)是操作系统在建立某个进程或者线程时(在支持多线程的操作系统中是线程)为这个线程建立的存储区域。
堆(Heap):
1、堆是在程序运行时,而不是在程序编译时,请求操作系统分配给自己某个大小的内存空间。即动态分配内存,对其访问和对一般内存的访问没有区别。
2、堆是指程序运行时申请的动态内存,而栈只是指一种使用堆的方法(即先进后出)。栈是先进后出的,但是于堆而言却没有这个特性,两者都是存放临时数据的地方。 对于堆,我们可以随心所欲的进行增加变量和删除变量,不要遵循什么次序,只要你喜欢。
堆、栈、队列之间的区别是?
1、堆是在程序运行时,而不是在程序编译时,申请某个大小的内存空间。即动态分配内存,对其访问和对一般内存的访问没有区别。
2、栈就是一个桶,后放进去的先拿出来,它下面本来有的东西要等它出来之后才能出来。(后进先出)
3、队列只能在队头做删除操作,在队尾做插入操作.而栈只能在栈顶做插入和删除操作。(先进先出)
3.有序字典:OrderedDict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
from collections import OrderedDict
d = dict([('a', 1), ('b', 2), ('c', 3)])
print(d)
# {'a': 1, 'c': 3, 'b': 2}
od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
print(od)
# OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
od = OrderedDict()
od['z'] = 1
od['y'] = 2
od['x'] = 3
print(od.keys()) # 按照插入的Key的顺序返回
# odict_keys(['z', 'y', 'x'])
4.字典集合:ChainMap()
可以将多个字典集合到一个字典中去,对外提供一个统一的视图。注意:该操作并是不将所有字典做了一次拷贝,实际上是在多个字典的上层又进行了一次封装而已。
from collections import ChainMap
user1 = {"name": "admin", "age": "20"}
user2 = {"name": "root", "weight": 65}
users = ChainMap(user1, user2)
print(users.maps)
users.maps[0]["name"] = "tiger"
print(users.maps)
for key, value in users.items():
print(key, value)
# 输出如下
# [{'name': 'admin', 'age': '20'}, {'name': 'root', 'weight': 65}]
# [{'name': 'tiger', 'age': '20'}, {'name': 'root', 'weight': 65}]
# name tiger
# weight 65
# age 20
由此可见,如果 ChainMap() 中的多个字典有重复 key,查看的时候可以看到所有的 key,但遍历的时候却只会遍历 key 第一次出现的位置,其余的忽略。同时,我们可以通过返回的新的视图来更新原来的的字典数据。进一步验证了该操作不是做的拷贝,而是直接指向原字典。
5.当 key 不存在时返回默认值:defaultdict
from collections import defaultdict
default_dict = defaultdict(int)
default_dict["x"] = 10
print(default_dict["x"])
print(default_dict["y"])
# 这里的y可以看到没有添加进去
# 输出如下
# 10
# 0
注意,defaultdict 的参数必须是可操作的。比如 python 内置类型,或者无参的可调用的函数。
def getUserInfo():
return {
"name" : "",
"age" : 0
}
default_dict = defaultdict(getUserInfo)
admin = default_dict["admin"]
print(admin)
admin["age"] = 34
print(admin)
# 输出如下
# {'name': '', 'age': 0}
# {'name': '', 'age': 34}
6.可以重新排序的字典:OrderedDict
- OrderedDict 类有一个 move_to_end() 方法,可以有效地将元素移动到任一端。
from collections import OrderedDict
user = OrderedDict()
user["name"] = "admin"
user["age"] = 23
user["weight"] = 65
print(user)
user.move_to_end("name") # 将元素移动至末尾
print(user)
user.move_to_end("name", last = False) # 将元素移动至开头
print(user)
# 输出如下
# OrderedDict([('name', 'admin'), ('age', 23), ('weight', 65)])
# OrderedDict([('age', 23), ('weight', 65), ('name', 'admin')])
# OrderedDict([('name', 'admin'), ('age', 23), ('weight', 65)])
7.计数器:Counter
Counter 可以简单理解为一个计数器,可以统计每个元素出现的次数,同样 Counter() 是需要接受一个可迭代的对象的。
from collections import Counter
animals = ["cat", "dog", "cat", "bird", "horse", "tiger", "horse", "cat"]
animals_counter = Counter(animals)
print(animals_counter)
print(animals_counter.most_common(2))
Counter({'cat': 3, 'horse': 2, 'dog': 1, 'bird': 1, 'tiger': 1})
# 输出如下
# Counter({'cat': 3, 'horse': 2, 'dog': 1, 'bird': 1, 'tiger': 1})
# [('cat', 3), ('horse', 2)]
其实一个 Counter 就是一个字典,其额外提供的 most_common() 函数通常用于求 Top k 问题。
2、时间模块
这个模块我们就比较熟悉了,之前学的时候调用过内部的几个功能
三种时间表现形式
1.时间戳(timestamp)
返回秒数。通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
2.结构化时间(struct_time)
主要是给计算机看的,人看不适应,但是根据中间的单词意思也可以看懂
这里需要注意,因为外国的日期和星期跟我们不太一样,我们需要根据具体情况修改。
3.格式化时间(Format String)
主要是给人看的,通过一定的符号表示对应的年月日时分秒
代码演示:
#导入时间模块
import time
#时间戳
print(time.time())
# 结果:1666168973.8717413
#时间字符串
print(time.strftime("%Y-%m-%d %X"))
# 结果:2022-10-19 16:42:53
print(time.strftime("%Y-%m-%d %H-%M-%S"))
# 前面三个表示日期的%字符可以用%+小写的x表示,后面三个表示时间的%字符可以用大写的X表示
# 结果:2022-10-19 16-42-53
#时间元组:localtime将一个时间戳转换为当前时区的struct_time
print(time.localtime())
# 结果:time.struct_time(tm_year=2022, tm_mon=10, tm_mday=19, tm_hour=16, tm_min=42, tm_sec=53, tm_wday=2, tm_yday=292, tm_isdst=0)
拓展1:
格式化时间中,各个符号代表的意思:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
拓展2:
struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
| 索引(Index) | 属性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | 比如2011 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 60 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为0 |
几种时间格式的转换
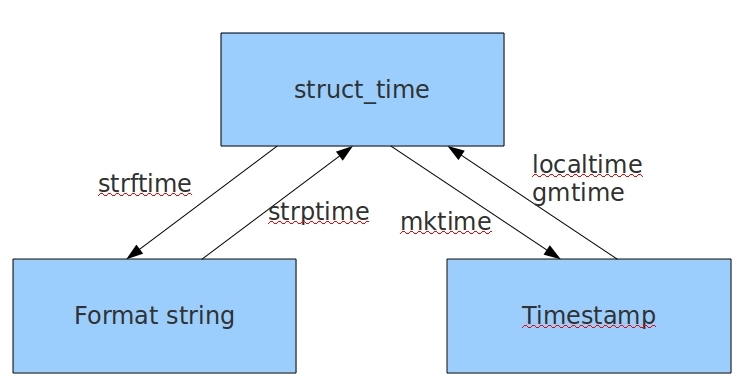
import time
#时间戳-->结构化时间
# time.gmtime(时间戳) # 根据UTC时间进行转换,与英国伦敦当地时间一致
# time.localtime(时间戳) # 根据当地时间进行转换。例如我们现在在北京执行这个方法:与UTC时间相差8小时,UTC时间+8小时 = 北京时间
print(time.gmtime(1500000000))
# 结果:time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=2, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0)
print(time.localtime(1500000000))
# 结果:time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0)
#结构化时间-->时间戳
#time.mktime(结构化时间)
time_tuple = time.localtime(1500000000)
print(time.mktime(time_tuple))
# 结果:1500000000.0
import time
#结构化时间-->字符串时间
#time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则显示当前时间
print(time.strftime("%Y-%m-%d %X"))
# 结果:'2017-07-24 14:55:36'
print(time.strftime("%Y-%m-%d", time.localtime(1500000000)))
# 结果:'2017-07-14'
#字符串时间-->结构化时间
#time.strptime(时间字符串,字符串对应格式)
print(time.strptime("2017-03-16", "%Y-%m-%d"))
# 结果:time.struct_time(tm_year=2017, tm_mon=3, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=75, tm_isdst=-1)
print(time.strptime("07/24/2017", "%m/%d/%Y"))
# 结果:time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1)
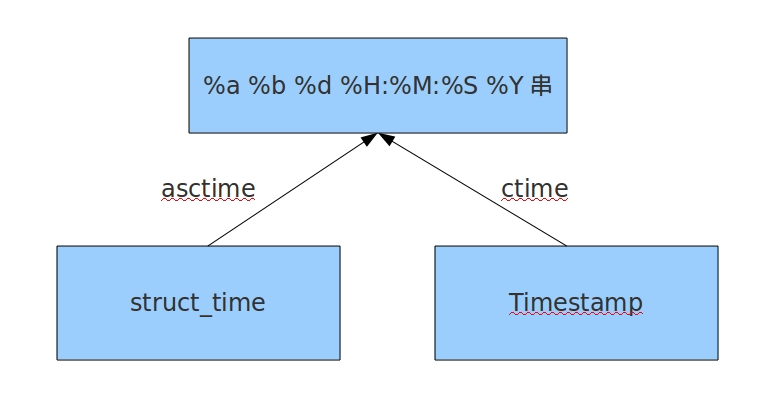
import time
#结构化时间 --> %a %b %d %H:%M:%S %Y串
#time.asctime(结构化时间) 如果不传参数,直接返回当前时间的格式化串
print(time.asctime(time.localtime(1500000000)))
# 结果'Fri Jul 14 10:40:00 2017'
print(time.asctime())
# 结果'Mon Jul 24 15:18:33 2017'
#时间戳 --> %a %b %d %H:%M:%S %Y串
#time.ctime(时间戳) 如果不传参数,直接返回当前时间的格式化串
print(time.ctime())
# 结果'Mon Jul 24 15:19:07 2017'
print(time.ctime(1500000000))
# 结果'Fri Jul 14 10:40:00 2017'
datetime模块
1.datetime.now() # 获取当前datetime
datetime.utcnow() # 获取当前格林威治时间
from datetime import datetime
#获取当前本地时间
a=datetime.now()
print('当前日期:',a)
#获取当前世界时间
b=datetime.utcnow()
print('世界时间:',b)
2.datetime(2017, 5, 23, 12, 20) # 用指定日期时间创建datetime
from datetime import datetime
#用指定日期创建
c=datetime(2017, 5, 23, 12, 20)
print('指定日期:',c)
3.将以下字符串转换成datetime类型:
'2017/9/30'
'2017年9月30日星期六'
'2017年9月30日星期六8时42分24秒'
'9/30/2017'
'9/30/2017 8:42:50 '
from datetime import datetime
d=datetime.strptime('2017/9/30','%Y/%m/%d')
print(d)
e=datetime.strptime('2017年9月30日星期六','%Y年%m月%d日星期六')
print(e)
f=datetime.strptime('2017年9月30日星期六8时42分24秒','%Y年%m月%d日星期六%H时%M分%S秒')
print(f)
g=datetime.strptime('9/30/2017','%m/%d/%Y')
print(g)
h=datetime.strptime('9/30/2017 8:42:50 ','%m/%d/%Y %H:%M:%S ')
print(h)
4.将以下datetime类型转换成字符串:
2017年9月28日星期4,10时3分43秒
Saturday, September 30, 2017
9/30/2017 9:22:17 AM
September 30, 2017
from datetime import datetime
i=datetime(2017,9,28,10,3,43)
print(i.strftime('%Y年%m月%d日%A,%H时%M分%S秒'))
j=datetime(2017,9,30,10,3,43)
print(j.strftime('%A,%B %d,%Y'))
k=datetime(2017,9,30,9,22,17)
print(k.strftime('%m/%d/%Y %I:%M:%S%p'))
l=datetime(2017,9,30)
print(l.strftime('%B %d,%Y'))
5.用系统时间输出以下字符串:
今天是2017年9月30日
今天是这周的第?天
今天是今年的第?天
今周是今年的第?周
今天是当月的第?天
from datetime import datetime
#获取当前系统时间
m=datetime.now()
print(m.strftime('今天是%Y年%m月%d日'))
print(m.strftime('今天是这周的第%w天'))
print(m.strftime('今天是今年的第%j天'))
print(m.strftime('今周是今年的第%W周'))
print(m.strftime('今天是当月的第%d天'))
3、随机数模块:random
功能简介:
import random
# 随机小数
print(random.random())
# 大于0且小于1之间的小数
# 0.7664338663654585
print(random.uniform(1, 3))
# 大于1小于3的小数
# 1.6270147180533838#恒富:发红包
# 随机整数
print(random.randint(1, 5))
print(random.randrange(1, 10, 2))
# 随机选择一个返回
print(random.choice([1, '23', [4, 5]]))
print(random.choices([1, '23', [4, 5]]))
# choices返回的不是字符了,返回的是保留原来数据类型的数据值
# 随机选择多个返回,返回的个数为函数的第二个参数
print(random.sample([1, '23', [4, 5]], 2))
# [[4, 5], '23']
# 打乱列表顺序
item = [1, 3, 5, 7, 9]
random.shuffle(item) # 打乱次序
print(item)
# [5, 1, 3, 7, 9]
random.shuffle(item)
print(item)
# [5, 9, 7, 1, 3]
产生图片验证码(搜狗面试题):
每一位都可以是大写字母 小写字母 数字 n位
import random
def suijishu(n):
res = ''
for i in range(n):
wd_d = chr(random.randint(65, 90))
wd = chr(random.randint(97, 122))
num = str(random.randint(0, 9))
choice = random.choice([wd, wd_d, num])
res = res + choice
print(res)
suijishu(5)
二、os模块(重要)
OS模块主要用于代码与操作系统的交互
1、mkdir/makedirs
创建目录(文件夹)
import os
# 1.创建目录(文件夹)
os.mkdir(r'd1')
# 相对路径 在执行文件所在的路径下创建目录 可以创建单级目录
os.mkdir(r'd2\d22\d222')
# 不可以创建多级目录
os.makedirs(r'd2\d22\d222')
# 可以创建多级目录
os.makedirs(r'd3')
# 也可以创建单级目录
2、rmdir/removedirs
删除目录(文件夹),内部有文件的不能删除
os.rmdir(r'd1')
# 可以删除单级目录
os.rmdir(r'd2\d22\d222') # 不可以一次性删除多级目录
os.removedirs(r'd2\d22') # 可以删除多级目录
os.removedirs(r'd2\d22\d222\d2222') # 只能删除空的多级目录
os.rmdir(r'd3') # 只能删空的单级目录
3、listdir
列举指定路径下内容名称
print(os.listdir())
print(os.listdir(r'D:\\'))
4、rename/remove
重命名/删除文件
os.rename(r'a.txt', r'aaa.txt')
# 把a.txt命名成aaa.txt
os.remove(r'aaa.txt')
5、getcwd/chdir
获取/切换当前工作目录
print(os.getcwd())
# D:\pythonProject03\day19
os.chdir('..')
# 切换到上一级目录
print(os.getcwd())
# D:\pythonProject03
os.mkdir(r'hei')
6、abspath/dirname
动态获取项目根路径(重要)
print(os.path.abspath(__file__))
# 获取执行文件的绝对路径(具体到文件名称) D:/pythonProject03/day19/01 os模块.py
print(os.path.dirname(__file__))
# 获取执行文件所在的目录路径(具体到文件的所在文件夹)D:/pythonProject03/day19
7、exists/isfile/isdir
判断路径是否存在(文件、目录)
print(os.path.exists(r'01 os模块.py')) # 判断文件路径是否存在 True
print(os.path.exists(r'D:\pythonProject03\day19'))
# 判断目录是否存在 True
print(os.path.isfile(r'01 os模块.py')) # 判断路径是否是文件 True
print(os.path.isfile(r'D:\pythonProject03\day19'))
# 判断路径是否是文件 False
print(os.path.isdir(r'01 os模块.py')) # False
print(os.path.isdir(r'D:\pythonProject03\day19'))
# True
8、join
路径拼接(重要)
s1 = r'D:\pythonProject03\day19'
s2 = r'01 os模块.py'
print(f'{s1}\{s2}')
"""
涉及到路径拼接一定不要自己做 因为不同的操作系统路径分隔符不一样
"""
print(os.path.join(s1, s2))
9、getsize
获取文件大小(字节)
print(os.path.getsize(r'a.txt'))
10、其他功能
# 获取文件/目录信息
print(os.stat(r'modeos.py'))
# 结果:os.stat_result(st_mode=33206, st_ino=5066549580814332, st_dev=504610996, st_nlink=1, st_uid=0, st_gid=0,
# st_size=2975, st_atime=1666252445, st_mtime=1666252445, st_ctime=1666250317)
# 运行shell命令,直接显示
os.system("bash command")
# 运行shell命令,获取执行结果
os.popen('bash command').read()
# 返回path最后的文件名。如果path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
print(os.path.basename(r'D:/pythonproject/10.20/')) # 返回空值
print(os.path.basename(r'D:/pythonproject/10.20/modeos.py'))
# 结果:modeos.py
# 如果path是绝对路径,返回True
print(os.path.isabs(r'modeos.py'))
# 结果:False
print(os.path.isabs(r'D:/pythonproject/10.20/modeos.py'))
# 结果:True
# 返回path所指向的文件或者目录的最后访问时间
print(os.path.getatime(r'D:/pythonproject/10.20'))
# 结果:1666252253.9921
# 返回path所指向的文件或者目录的最后修改时间
print(os.path.getmtime(r'D:/pythonproject/10.20/modeos.py'))
# 结果:1666252253.9710982
三、sys模块
sys模块用于跟python解释器进行交互,比如之前设置系统的环境变量位置
1、arge
实现从程序外部向程序传递参数,当我们在pycharm运行文件的时候并不能实现外部传参的功能
res = sys.argv
if len(res) != 3:
print('执行命令缺少了用户名或密码')
else:
username = res[1]
password = res[2]
if username == 'jason' and password == '123':
print('jason您好 文件正常执行')
else:
print('您不是jason无权执行该文件')
这段代码的作用就是判断有没有传参数进来,没有,传了参数就进行判断信息是否正确
2、path
获取执行文件的环境变量
import sys
# 获取执行文件的sys.path(环境变量,前两个是一样的,因为pycharm帮我们加了一次,然后我们运行的时候当前路径也会加进去)
print(sys.path)
# 结果:['D:\\pythonproject\\10.20', 'D:\\pythonproject\\10.20', 'D:\\PyCharm 2021.1.3\\plugins\\python\\helpers\\pycharm_display',
# 'D:\\python3.8\\python38.zip', 'D:\\python3.8\\DLLs', 'D:\\python3.8\\lib', 'D:\\python3.8',
# 'D:\\python3.8\\lib\\site-packages', 'D:\\PyCharm 2021.1.3\\plugins\\python\\helpers\\pycharm_matplotlib_backend']
3、getrecursionlimit
获取python解释器默认最大递归深度
# 获取python解释器默认最大递归深度
print(sys.getrecursionlimit()) # 默认为1000
4、setrecursionlimit
修改python解释器默认最大递归深度
# 修改python解释器默认最大递归深度
sys.setrecursionlimit(2000)
5、version
返回当前的解释器版本
# 返回当前的解释器版本
print(sys.version)
# 3.8.6 (tags/v3.8.6:db45529, Sep 23 2020, 15:52:53) [MSC v.1927 64 bit (AMD64)]
6、platform
返回平台信息
# 返回平台信息
print(sys.platform)
# 平台信息 基本都是win32(了解即可)
7、exit
返回程序中间的退出信息,arg=0为正常退出,其他为异常退出
四、json模块
json模块用于不同语言之间的数据传输。json模块也称为序列化模块,序列化可以打破语言限制实现不同编程语言之间数据交互。
序列化:数据类型>>>json格式字符串
特征:文件中引号是双引号
json模块有四个方法:dump、load、dumps、loads
json相关操作
针对数据
json.dumps()
json.loads()
dumps可以直接将数据变成json格式,load可以用于将json格式数据变成python格式
针对文件
json.dump()
json.load()
使用dump可以将数据序列号(变成json格式)然后写入文件,load可以将json文件中的序列化数据转化成python格式。
五、re模块
简介
如果想要在python中使用正则表达式就可以导入re模块:
import re
常见操作方法:
1、.findall()
查找所有符合正则表达式要求的数据 结果直接是一个列表,第一个参数是查找对象,第二个参数是被查找的内容。
res = re.findall('a', 'jason apple eva')
print(res)
# ['a', 'a', 'a']
2、.finditer()
查找所有符合正则表达式要求的数据 结果直接是一个迭代器对象,第一个参数是查找对象,第二个参数是被查找的内容。
res = re.finditer('a', 'jason apple eva')
print(res)
# <callable_iterator object at 0x000001C249C45BB0>
这里就是相当于对这个可迭代对象进行了双下iter操作,把对象变成了迭代器对象,这时候我们可以用for或是双下next来获取内部内容,相比findall,在对大文件进行查找到的时候finditer使用的更多,不会占用过多的内存空间。
3、.search()
根据查找对象进行分割,查找对象会被删除。
第一个参数是查找对象,第二个参数是被查找的内容。
res = re.search('a', 'jason apple eva')
print(res)
# <re.Match object; span=(1, 2),match='a'>
函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
print(res.group()) # a 匹配到一个符合条件的数据就立刻结束
# a
4、match()
匹配字符串的开头 如果不符合后面不用看了。
第一个参数是查找对象,第二个参数是被查找的内容。
res = re.match('a', 'jason apple eva')
print(res) # None 匹配字符串的开头 如果不符合后面不用看了
5、compile()
当某一个正则表达式需要频繁使用的时候 我们可以做成模板
obj = re.compile('\d{3}')
res1 = obj.findall('23423422342342344')
res2 = obj.findall('asjdkasjdk32423')
print(res1, res2)
# ['234', '234', '223', '423', '423'] ['324']
6、split()
第一个参数是查找对象,第二个参数是被查找的内容。
ret = re.split('[ab]', 'abcd')
print(ret)
# ['', '', 'cd']
根据参数中的第一个字符把被查找内容分成''和'bcd',然后再根据查找对象中的b,分成'',''和'cd',数据值存在一个列表中。
7、sub()
进行替换操作,第一个参数是被替换的字符,第二个参数是需要替换进去的字符,第三个位置是被替换的字符串。
ret = re.sub('\d', 'H', 'eva3jason4yuan4', 1) # 将数字替换成'H',参数1表示只替换1个
print(ret) # evaHjason4yuan4
返回的结果是个字符串
8、subn()
跟sub一样是进行替换
ret = re.subn('\d', 'H', 'eva3jason4yuan4') # 将数字替换成'H',返回的结果是元组(参数的内容分别是替换的结果,替换了多少次)
print(ret) # ('evaHjasonHyuanH', 3)
返回的结果是个元组
9、re.S
匹配的时候忽略换行符(也能匹配换行符)
res = re.findall('a', 'jason apple eva', re.S)
10、re.I
匹配的时候忽略大小写
res = re.findall('a', 'jason apple eva', re.I)
re模块补充说明
1、分组优先
当我们使用括号跟管道符的时候会出现分组优先的顺序。
findall()
res = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
print(res) # ['oldboy']
# findall分组优先展示:优先展示括号内正则表达式匹配到的内容
res = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com')
print(res) # ['www.oldboy.com']
如果是默认情况下,会返回括号内匹配到的内容,如果在匹配对象前面加上?:就会返回完整的内容
search()
res = re.search('www.(baidu|oldboy).com', 'www.oldboy.com')
print(res.group()) # www.oldboy.com
match()
res = re.match('www.(baidu|oldboy).com', 'www.oldboy.com')
print(res.group()) # www.oldboy.com
使用match和search的时候需要使用group查看内容,得到的内容也是完整的结果
2、分组别名
有时候我们需要匹配的分组描述可能十分复杂,这时我们可以通过给分组取名来让我们更方便地获
取分组。
分组命名的规则为:(?P
在使用search查找的时候,得到的结果需要用group打印出来,但是这个时候我们可以根据索引的顺序,单独获得search语句中给的内容。
res = re.search('www.(?P<content>baidu|oldboy)(?P<hei>.com)', 'www.oldboy.com')
print(res.group()) # www.oldboy.com
print(res.group('content')) # oldboy
print(res.group(0)) # www.oldboy.com
print(res.group(1)) # oldboy
print(res.group(2)) # .com
print(res.group('hei')) # .com
六、网络爬虫模块之requests模块
requests模块用于模拟浏览器想网页发送网络请求
# 1.朝指定网址发送请求获取页面数据(等价于:浏览器地址栏输入网址回车访问)
res = requests.get('http://www.redbull.com.cn/about/branch')
print(res.content) # 获取bytes类型的网页数据(二进制)
res.encoding = 'utf8' # 指定编码
print(res.text) # 获取字符串类型的网页数据(默认按照utf8)
方法介绍:
1、get()
模拟浏览器想网页地址发送请求
# 写法一:
response = requests.get("http://www.baidu.com/")
# 写法二:
# response = requests.request("get", "http://www.baidu.com/")
2、添加headers和查询参数
如果想添加 headers,可以传入headers参数来增加请求头中的headers信息。如果要将参数放在url中传递,可以利用 params 参数。
import requests
kw = {'wd':'长城'}
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# params 接收一个字典或者字符串的查询参数,字典类型自动转换为url编码,不需要urlencode()
response = requests.get("http://www.baidu.com/s?", params = kw, headers = headers)
3、text
#查看响应内容,response.text 返回的是Unicode格式的数据
print response.text
#<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer> .....
4、content
# 查看响应内容,response.content返回的字节流数据
print respones.content
5、url
# 查看完整url地址
print response.url
# http://www.baidu.com/?wd=%E9%95%BF%E5%9F%8E
6、encoding
# 查看响应头部字符编码
print response.encoding
# ISO-8859-1
7、status_code
# 查看响应码
print response.status_code
# 200
8、timeout
请求超时
time = requests.get('www.baidu.com',timeout=1) # 1秒内不响应 就抛出异常
time2 = requests.get('www.baidu.com',timeout=(5,30)) # 请求的两个阶段 连接和读取 我们分别设置这两个阶段的timeout 超过就报错
9、verify=False
忽略ssl证书
# 忽略ssl证书 SSLerror
responed = requests.get('www.xxx.com',verify=False) # 参数verify控制不验证 HTTPS HTTP
10、Session维持
# Session维持 模拟同一个会话 不用担心cookies
s = requests.Session() # 创建session对象
s.get('www.xxx.com', cookies='') # 设置好cookies
r = s.get('www.xxx.com/xxx.html') # 再次使用get时,这个cookies状态依旧保持
网络爬虫实战之爬取链家二手房数据
import requests
import re
res = requests.get('https://sh.lianjia.com/ershoufang/pudong/')
# print(res.text)
data = res.text
home_title_list = re.findall(
'<a class="" href=".*?" target="_blank" data-log_index=".*?" data-el="ershoufang" data-housecode=".*?" data-is_focus="" data-sl="">(.*?)</a>',
data)
# print(home_title_list)
home_name_list = re.findall('<a href=".*?" target="_blank" data-log_index=".*?" data-el="region">(.*?) </a>', data)
# print(home_name_list)
home_street_list = re.findall(
'<div class="positionInfo"><span class="positionIcon"></span><a href=".*?" target="_blank" data-log_index=".*?" data-el="region">.*? </a> - <a href=".*?" target="_blank">(.*?)</a> </div>',
data)
# print(home_street_list)
home_info_list = re.findall('<div class="houseInfo"><span class="houseIcon"></span>(.*?)</div>', data)
# print(home_info_list)
home_watch_list = re.findall('<div class="followInfo"><span class="starIcon"></span>(.*?)</div>', data)
# print(home_watch_list)
home_total_price_list = re.findall(
'<div class="totalPrice totalPrice2"><i> </i><span class="">(.*?)</span><i>万</i></div>', data)
# print(home_total_price_list)
home_unit_price_list = re.findall(
'<div class="unitPrice" data-hid=".*?" data-rid=".*?" data-price=".*?"><span>(.*?)</span></div>', data)
# print(home_unit_price_list)
home_data = zip(home_title_list, home_name_list, home_street_list, home_info_list, home_watch_list,
home_total_price_list, home_unit_price_list)
with open(r'home_data.txt','w',encoding='utf8') as f:
for data in home_data:
print(
"""
房屋标题:%s
小区名称:%s
街道名称:%s
详细信息:%s
关注程度:%s
房屋总价:%s
房屋单价:%s
"""%data
)
f.write("""
房屋标题:%s
小区名称:%s
街道名称:%s
详细信息:%s
关注程度:%s
房屋总价:%s
房屋单价:%s\n
"""%data)
这里的思路是,先分开获取想要查找的每个信息,然后用zip方法拼接输出,同时分开依次存到文件中
七、自动化办公领域之openpyxl模块
1.excel文件的后缀名问题
03版本之前
.xls
03版本之后
.xlsx
2.操作excel表格的第三方模块
xlwt往表格中写入数据、wlrd从表格中读取数据
兼容所有版本的excel文件
openpyxl最近几年比较火热的操作excel表格的模块
03版本之前的兼容性较差
ps:还有很多操作excel表格的模块 甚至涵盖了上述的模块>>>:pandas
3.openpyxl操作
在学习这方面知识之前,我们需要了解到,应当强化自己的网上学习能力,比如openpyxl模块就可以在网上查看说明来了解相关功能(页面是纯英文可以翻译页面也可以在网上找别人写的博客)
功能介绍
创建一个excel文件
from openpyxl import Workbook
# 实例化
wb = Workbook()
# 激活 worksheet
ws = wb.active
打开一个excel文件
from openpyxl import load_workbook
wb2 = load_workbook('文件名称.xlsx')
存储数据
1、append
这是一行一行加入数据功能,也可以一次加入多行
# 可以附加行,从第一列开始附加(从最下方空白处,最左开始)(可以输入多行)
ws.append([1, 2, 3])
2、['单元格位置'] = 内容
ws['A1'] = 42
3、Python 类型会被自动转换
ws['A3'] = datetime.datetime.now().strftime("%Y-%m-%d")
创建表
# 方式一:插入到最后(default)
>>> ws1 = wb.create_sheet("Mysheet")
# 方式二:插入到最开始的位置
>>> ws2 = wb.create_sheet("Mysheet", 0)
选择表
# sheet 名称可以作为 key 进行索引
>>> ws3 = wb["New Title"]
>>> ws4 = wb.get_sheet_by_name("New Title")
>>> ws is ws3 is ws4
True
查看表名
# 显示所有表名
>>> print(wb.sheetnames)
['Sheet2', 'New Title', 'Sheet1']
# 遍历所有表
>>> for sheet in wb:
... print(sheet.title)
修改工作簿名称
title
可以更改工作簿名称
通过待修改名称工作簿‘点’的方式在后方赋予新的名称
导入模块:
form openpyxl import workbook
代码用法:
from openpyxl import Workbook
wb = Workbook()
ws1 = wb.cerate_sheet('用户信息表', 0)
ws1.title = 'user_infor'
修改工作簿颜色
sheet_properties.tabColor
用来给工作簿背景修改颜色,需要用到RGB色域
导入模块:
from openpyxl import Workbook
wb = Workbook()
ws1 = wb.create_sheet('用户信息表', 0)
ws1.sheet_properties.tabColor = 'FF6666'
# 将标题背景改为指定RRGGBB颜色代码
访问单元格
cell( )
可以通过工作簿'点'的方式,在后方参数内填写内容的位置,来修改内容
row:行
colum:列
value:值(对应位置的数据)
# 方法一
>>> c = ws['A4']
# 方法二:row 行;column 列
>>> d = ws.cell(row=4, column=2, value=10)
# 方法三:只要访问就创建
>>> for i in range(1,101):
... for j in range(1,101):
... ws.cell(row=i, column=j)
保存文件
save( )
在关键词后方参数内填入文件保存的地址,同时赋予文件名
wb = Workbook()
wb.save('user_infor.xlsx')
# balances.xlsx 是保存的路径,也就是文件名。
# 编辑完要保存才行。
多单元格访问
# 通过切片
>>> cell_range = ws['A1':'C2']
# 通过行(列)
>>> colC = ws['C']
>>> col_range = ws['C:D']
>>> row10 = ws[10]
>>> row_range = ws[5:10]
# 通过指定范围(行 → 行)
>>> for row in ws.iter_rows(min_row=1, max_col=3, max_row=2):
... for cell in row:
... print(cell)
<Cell Sheet1.A1>
<Cell Sheet1.B1>
<Cell Sheet1.C1>
<Cell Sheet1.A2>
<Cell Sheet1.B2>
<Cell Sheet1.C2>
# 通过指定范围(列 → 列)
>>> for row in ws.iter_rows(min_row=1, max_col=3, max_row=2):
... for cell in row:
... print(cell)
<Cell Sheet1.A1>
<Cell Sheet1.B1>
<Cell Sheet1.C1>
<Cell Sheet1.A2>
<Cell Sheet1.B2>
<Cell Sheet1.C2>
# 遍历所有 方法一
>>> ws = wb.active
>>> ws['C9'] = 'hello world'
>>> tuple(ws.rows)
((<Cell Sheet.A1>, <Cell Sheet.B1>, <Cell Sheet.C1>),
(<Cell Sheet.A2>, <Cell Sheet.B2>, <Cell Sheet.C2>),
...
(<Cell Sheet.A8>, <Cell Sheet.B8>, <Cell Sheet.C8>),
(<Cell Sheet.A9>, <Cell Sheet.B9>, <Cell Sheet.C9>))
# 遍历所有 方法二
>>> tuple(ws.columns)
((<Cell Sheet.A1>,
<Cell Sheet.A2>,
<Cell Sheet.A3>,
...
<Cell Sheet.B7>,
<Cell Sheet.B8>,
<Cell Sheet.B9>),
(<Cell Sheet.C1>,
...
<Cell Sheet.C8>,
<Cell Sheet.C9>))
举例
from openpyxl import Workbook
# 创建一个excel文件(实例化)
wb = Workbook()
# 在一个excel文件内创建多个工作簿
wb1 = wb.create_sheet('学生名单')
wb2 = wb.create_sheet('舔狗名单')
wb3 = wb.create_sheet('海王名单')
# 还可以修改默认的工作簿位置
wb4 = wb.create_sheet('富婆名单', 0)
# 还可以二次修改工作簿名称
wb4.title = '高富帅名单'
wb4.sheet_properties.tabColor = "1072BA"
# 填写数据的方式1
# wb4['F4'] = 666
# 填写数据的方式2
# wb4.cell(row=3, column=1, value='jason')
# 填写数据的方式3
wb4.append(['编号', '姓名', '年龄', '爱好']) # 表头字段
wb4.append([1, 'jason', 18, 'read'])
wb4.append([2, 'kevin', 28, 'music'])
wb4.append([3, 'tony', 58, 'play'])
wb4.append([4, 'oscar', 38, 'ball'])
wb4.append([5, 'jerry', 'ball'])
wb4.append([6, 'tom', 88,'ball','哈哈哈'])
# 填写数学公式
# wb4.cell(row=1, column=1, value=12321)
# wb4.cell(row=2, column=1, value=3424)
# wb4.cell(row=3, column=1, value=23423432)
# wb4.cell(row=4, column=1, value=2332)
# wb4['A5'] = '=sum(A1:A4)'
# wb4.cell(row=8, column=3, value='=sum(A1:A4)')
# 保存该excel文件
wb.save(r'111.xlsx')
"""
openpyxl主要用于数据的写入 至于后续的表单操作它并不是很擅长 如果想做需要更高级的模块pandas
import pandas
data_dict = {
"公司名称": comp_title_list,
"公司地址": comp_address_list,
"公司邮编": comp_email_list,
"公司电话": comp_phone_list
}
# 将字典转换成pandas里面的DataFrame数据结构
df = pandas.DataFrame(data_dict)
# 直接保存成excel文件
df.to_excel(r'pd_comp_info.xlsx')
excel软件正常可以打开操作的数据集在10万左右 一旦数据集过大 软件操作几乎无效
需要使用代码操作>>>:pandas模块
"""
八、hashlib加密模块
hashlib模块是用于数据加密的,模块中有很多种加密算法,比如md5、base64、hmac、sha1等sha系列的加密算法。
1、何为加密
将明文数据处理成密文数据 让人无法看懂(无法逆转),但是可以通过已经加密过的结果进行穷举,来推测明文。
2、为什么加密
为了保证数据的安全
3、如何判断数据是否以加密
我们可以观看数据的构成,如果是用无序的数字、字母、符号来组成的,基本上都是加密数据
4、密文的长短有什么意义
密文越长表示两种情况,第一种就是明文很长,第二种就是加密的算法很复杂,这里我们需要注意算法并不是越复杂越好,应该根据实际情况选择使用,有些时候反而使用简单的算法就足够了。
5、加密算法的基本操作
# 第一步导入模块
import hashlib
# 2.传入明文数据
md5 = hashlib.md5()
md5.update(b'hello')
# 3.获取加密密文
res = md5.hexdigest()
print(res) # 5d41402abc4b2a76b9719d911017c592
注:md5中需要使用二进制才能转换
6、加密补充说明
1.加密算法不变 内容如果相同 那么结果肯定相同
# md5.update(b'hello~world~python~666') # 一次性传可以
md5.update(b'hello') # 分多次传也可以
md5.update(b'~world') # 分多次传也可以
md5.update(b'~python~666') # 分多次传也可以
2.加密之后的结果是无法反解密的
只能从明文到密文正向推导 无法从密文到明文反向推导
常见的解密过程其实是提前猜测了很多种结果
123 密文
321 密文
222 密文
3.加盐处理
在明文里面添加一些额外的干扰项
# 1.选择加密算法
md5 = hashlib.md5()
# 2.传入明文数据
md5.update('公司设置的干扰项'.encode('utf8'))
md5.update(b'hello python') # 一次性传可以
# 3.获取加密密文
res = md5.hexdigest()
print(res) # e53024684c9be1dd3f6114ecc8bbdddc
4.动态加盐
干扰项是随机变化的
eg:当前时间、用户名部分...
5.加密实战操作
1.用户密码加密
2.文件安全性校验
3.文件内容一致性校验
4.大文件内容加密
截取部分内容加密即可
比如一种情况就是,在一个大文件的每隔四分之一处取一千个字节进行加密,如果两个文件的密文一样说明,这里就是一样的两个文件
九、subprocess模块
subprocess是python内置的模块,这个模块中的Popen可以查看用户输入的命令行是否存在
如果存在,把内容写入到stdout管道中
如果不存在,把信息写入到stderr管道
需要注意的是,这个模块的返回结果只能让开发者看一次,如果想多次查看,需要在第一次输出的时候,把所有信息写入到变量中。
1、subprocess中的popen用法:
-
Popen基本格式:subprocess.Popen(‘命令’, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
-
shell=True 表示要在终端中运行的命令
stdout=sbuprocess.PIPE 表示当命令存在的时候,把结果写入到stdout管道
stderr=sbuprocess.PIPE 表示当命令不存在的时候,把结果吸入到stderr管道
import subprocess
res = subprocess.Popen(
'asdas', # 操作系统要执行的命令
shell=True, # 固定配置
stdin=subprocess.PIPE, # 输入命令
stdout=subprocess.PIPE, # 输出结果
)
print('正确结果', res.stdout.read().decode('gbk')) # 获取操作系统执行命令之后的正确结果
print('错误结果', res.stderr) # 获取操作系统执行命令之后的错误结果
2. subprocess模块中的常用函数
| 函数 | 描述 |
|---|---|
| subprocess.run() | Python 3.5中新增的函数。执行指定的命令,等待命令执行完成后返回一个包含执行结果的CompletedProcess类的实例。 |
| subprocess.call() | 执行指定的命令,返回命令执行状态,其功能类似于os.system(cmd)。 |
| subprocess.check_call() | Python 2.5中新增的函数。 执行指定的命令,如果执行成功则返回状态码,否则抛出异常。其功能等价于subprocess.run(…, check=True)。 |
| subprocess.check_output() | Python 2.7中新增的的函数。执行指定的命令,如果执行状态码为0则返回命令执行结果,否则抛出异常。 |
| subprocess.getoutput(cmd) | 接收字符串格式的命令,执行命令并返回执行结果,其功能类似于os.popen(cmd).read()和commands.getoutput(cmd)。 |
| subprocess.getstatusoutput(cmd) | 执行cmd命令,返回一个元组(命令执行状态, 命令执行结果输出),其功能类似于commands.getstatusoutput()。 |
说明:
1.在Python 3.5之后的版本中,官方文档中提倡通过subprocess.run()函数替代其他函数来使用subproccess模块的功能;
2.在Python 3.5之前的版本中,我们可以通过subprocess.call(),subprocess.getoutput()等上面列出的其他函数来使用subprocess模块的功能;
3.subprocess.run()、subprocess.call()、subprocess.check_call()和subprocess.check_output()都是通过对subprocess.Popen的封装来实现的高级函数,因此如果我们需要更复杂功能时,可以通过subprocess.Popen来完成。
4.subprocess.getoutput()和subprocess.getstatusoutput()函数是来自Python 2.x的commands模块的两个遗留函数。它们隐式的调用系统shell,并且不保证其他函数所具有的安全性和异常处理的一致性。另外,它们从Python 3.3.4开始才支持Windows平台。
3、上面各函数的定义及参数说明
subprocess.run(args, *, stdin=None, input=None, stdout=None, stderr=None, shell=False, timeout=None, check=False, universal_newlines=False)
subprocess.call(args, *, stdin=None, stdout=None, stderr=None, shell=False, timeout=None)
subprocess.check_call(args, *, stdin=None, stdout=None, stderr=None, shell=False, timeout=None)
subprocess.check_output(args, *, stdin=None, stderr=None, shell=False, universal_newlines=False, timeout=None)
subprocess.getstatusoutput(cmd)
subprocess.getoutput(cmd)
参数说明:
args: 要执行的shell命令,默认应该是一个字符串序列,如[‘df’, ‘-Th’]或(‘df’, ‘-Th’),也可以是一个字符串,如’df -Th’,但是此时需要把shell参数的值置为True。
shell: 如果shell为True,那么指定的命令将通过shell执行。如果我们需要访问某些shell的特性,如管道、文件名通配符、环境变量扩展功能,这将是非常有用的。当然,python本身也提供了许多类似shell的特性的实现,如glob、fnmatch、os.walk()、os.path.expandvars()、os.expanduser()和shutil等。
check: 如果check参数的值是True,且执行命令的进程以非0状态码退出,则会抛出一个CalledProcessError的异常,且该异常对象会包含 参数、退出状态码、以及stdout和stderr(如果它们有被捕获的话)。
stdout, stderr:input: 该参数是传递给Popen.communicate(),通常该参数的值必须是一个字节序列,如果universal_newlines=True,则其值应该是一个字符串。
run()函数默认不会捕获命令执行结果的正常输出和错误输出,如果我们向获取这些内容需要传递subprocess.PIPE,然后可以通过返回的CompletedProcess类实例的stdout和stderr属性或捕获相应的内容;
call()和check_call()函数返回的是命令执行的状态码,而不是CompletedProcess类实例,所以对于它们而言,stdout和stderr不适合赋值为subprocess.PIPE;
check_output()函数默认就会返回命令执行结果,所以不用设置stdout的值,如果我们希望在结果中捕获错误信息,可以执行stderr=subprocess.STDOUT。
universal_newlines: 该参数影响的是输入与输出的数据格式,比如它的值默认为False,此时stdout和stderr的输出是字节序列;当该参数的值设置为True时,stdout和stderr的输出是字符串。
十、logging日志模块
1、如何理解日志
所谓日志就是一个用来记录我们行为举止的代码,类似以前的史官,我们在平时的使用中并不要求自己可以写出来,会用别人的代码并且会改就可以了。因为以后会使用整合更好的模块来使用。
2、日志的五种级别
logging模块日志级别有DEBUG < INFO < WARNING < ERROR < CRITICAL 五种。
DEBUG - 调试模式,应用场景是问题诊断;
INFO - 通常只记录程序中一般事件的信息,用于确认工作一切正常;
WARNING - 打印警告信息,系统还在正常运行;
ERROR - 错误导致某些功能不能正常运行时记录的信息;
CRITICAL - 当发生严重错误,导致应用程序不能继续运行时记录的信息。
3、组成部分
- logger:提供记录日志的方法。
- handler:选择日志的输出地方(一个logger添加多个handler)。
- filter:给用户提供更加细粒度的控制日志的输出内容。
- format:用户格式化输出日志的信息。
4、配置方法
1.基础配置
logging.basicConfig(filename="config.log",
filemode="w",
format="%(asctime)s-%(name)s-%(levelname)s-%(message)s",
level=logging.INFO)
2.使用配置文件的方式
fileConfig(filename,defaults=None,disable_existing_loggers=Ture )
3.使用一个字典方式来写配置信息
使用dictConfig(dict,defaults=None, disable_existing_loggers=Ture )函数
3、日志输出
-
StreamHandler
-
logging.StreamHandler:日志输出到流,可以是sys.stderr,sys.stdout或者文件 -
FileHandler
-
logging.FileHandler:日志输出到文件 -
BaseRotatingHandler
-
logging.handlers.BaseRotatingHandler:基本的日志回滚方式 -
RotatingHandler
-
logging.handlers.RotatingHandler:日志回滚方式,支持日志文件最大数量和日志文件回滚
4、format常用格式说明
%(levelno)s: 打印日志级别的数值
%(levelname)s: 打印日志级别名称
%(pathname)s: 打印当前执行程序的路径,其实就是sys.argv[0]
%(filename)s: 打印当前执行程序名
%(funcName)s: 打印日志的当前函数
%(lineno)d: 打印日志的当前行号
%(asctime)s: 打印日志的时间
%(thread)d: 打印线程ID
%(threadName)s: 打印线程名称
%(process)d: 打印进程ID
%(message)s: 打印日志信息
5、日志的执行过程
1、产生日志
2、过滤日志
这里我们需要注意,通常来说我们会在产生日志的时候设置需要产生的日志。其他不需要的日志就不会生成,所以基本用不到这个模块
3、输出日志
4、日志格式
六、字段解释
# 字段解释
filename:日志文件名的prefix;
when:是一个字符串,用于描述滚动周期的基本单位,字符串的值及意义如下:
“S”: Seconds
“M”: Minutes
“H”: Hours
“D”: Days
“W”: Week day (0=Monday)
“midnight”: Roll over at midnight
interval: 滚动周期,单位有when指定,比如:when=’D’,interval=1,表示每天产生一个日志文件
backupCount: 表示日志文件的保留个数
举例:
import logging
# 1.日志的产生(准备原材料) logger对象
logger = logging.getLogger('购物车记录')
# 2.日志的过滤(剔除不良品) filter对象>>>:可以忽略 不用使用
# 3.日志的产出(成品) handler对象
hd1 = logging.FileHandler('a1.log', encoding='utf-8') # 输出到文件中
hd2 = logging.FileHandler('a2.log', encoding='utf-8') # 输出到文件中
hd3 = logging.StreamHandler() # 输出到终端
# 4.日志的格式(包装) format对象
fm1 = logging.Formatter(
fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
)
fm2 = logging.Formatter(
fmt='%(asctime)s - %(name)s: %(message)s',
datefmt='%Y-%m-%d',
)
# 5.给logger对象绑定handler对象
logger.addHandler(hd1)
logger.addHandler(hd2)
logger.addHandler(hd3)
# 6.给handler绑定formmate对象
hd1.setFormatter(fm1)
hd2.setFormatter(fm2)
hd3.setFormatter(fm1)
# 7.设置日志等级
logger.setLevel(10) # debug
# 8.记录日志
logger.debug('写了半天 好累啊 好热啊')
6、日志配置字典
通常来说我们都是使用日志字典的形式来达成功能的(功能多又方便,谁不喜欢呢)。这里也是跟之前的说的一样,会用就好,不需要了解。
import logging
import logging.config
# 定义日志输出格式 开始
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' # 其中name为getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
# 自定义文件路径
logfile_path = 'a3.log'
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 过滤日志
'handlers': {
# 打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
# 打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 5,
# 这里两个参数的意思是一个日志文件最多写5M,最多可以存在五个不同的日志文件,但是当数量达到五个之后就会出现最早的那个会被删除,
# 然后再产生一个新的文件(类似于覆盖了最早的那个文件)
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
# logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
# '购物车记录': {
# 'handlers': ['default','console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
# 'level': 'WARNING',
# 'propagate': True, # 向上(更高level的logger)传递
# }, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
},
}
logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置
# logger1 = logging.getLogger('购物车记录')
# logger1.warning('尊敬的VIP客户 晚上好 您又来啦')
# logger1 = logging.getLogger('注册记录')
# logger1.debug('jason注册成功')
logger1 = logging.getLogger('红浪漫顾客消费记录')
# 当这里的getLogger内部的参数如果字典中没有,就会自动使用字典中名称为空的那个模版来执行
logger1.debug('慢男 猛男 骚男')
