文件操作
文件操作
一、概念讲解
首先我们要知道文件是操作系统暴露给用户的快捷方式,当我们使用的时候只需要双击就能将文件读取到内存中运行,使用ctrl+s就可以将文件保存到硬盘中,这些对文件进行修改或使用的动作就是文件操作,除了借助操作系统,我们可以使用python代码进行这一系列的操作。
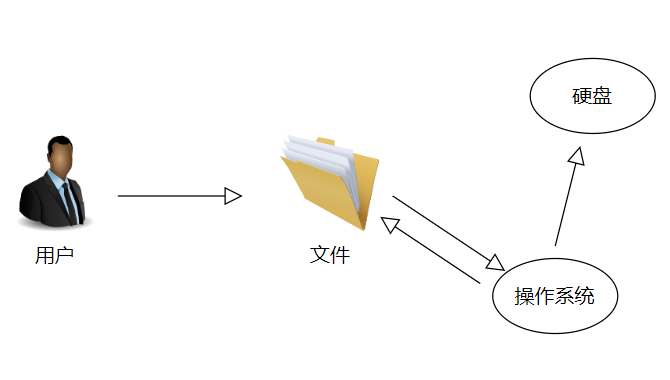
二、通过代码打开文件的两种方式
方式一:
f=open(文件路径,文件读写模式,encoding='文件编码类型(默认情况下为utf8)')
f.close()
特点:一次只能打开一个文件,使用完文件后需要输入f.close关闭文件,但是如果忘记关闭文件并不会有提示。
方法二:
with open(文件路径,文件读写模式,encoding='文件编码类型(默认情况下为utf8)') as f1,open(文件路径,文件读写模式,encoding='文件编码类型(默认情况下为utf8)') as f2:
with条件下的操作代码
特点:当我们使用with方法打开文件的时候,可以一次性打开多个文件并且不需要输入close方法,会自动运行close方法。
一些小知识点总结:
①当我们在使用代码打开文件的时候,如果填写的文件路径中有撬棍符号(\)的时候,我们需要在路径文本的前面加上一个r。为了防止漏写,我们可以在每个路径前面都加上r,免去判断的过程。
②在我们选择文件的读写模式的时候,通常写的都是简写,他们的全称分别是:rt、wt、at。
③当我们打开文件暂时不知道需要做什么的时候可以使用pass和...来跳过并保证代码通畅运行,但是在使用过程中通常都写pass,三个点怕在检查的时候看不清。
④当我们在写入的时候,需要注意换行符的使用,如果不加入换行符会一直在同一行书写,直到那一行写满才会换行。
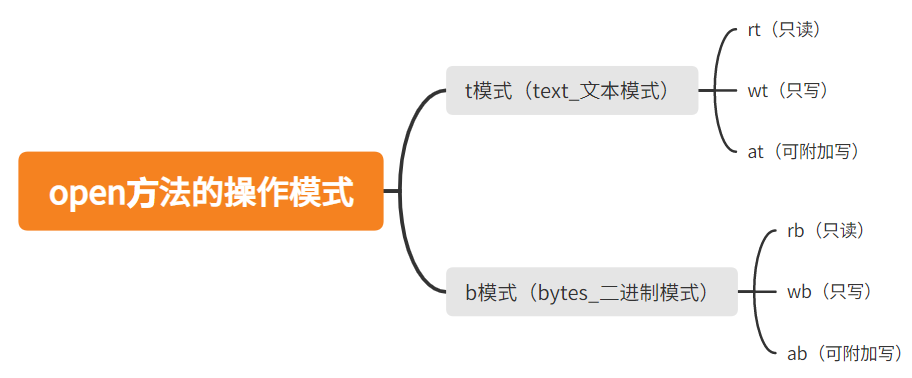
三、文件的读写模式
这里的读写模式只针对文本文件,其他类型的文件需要专属的软件才能打开。对于文本文件有三种读写模式:只读模式(r)、只写模式(w)、只追加模式(a)。
1、只读模式(r)
在只读模式下我们只能读取文本中的内容不能修改。
当我们使用只读模式打开文件的时候如果文件不存在会报错,如果存在就正常打开。
with open(r'D:\pythonproject\a.txt','r',encoding='utf8') as f1:
a = f1.read()
print(a) # 结果:这是a文本
2、只写模式(w)
在只写模式下打开文件会清空其中的内容,然后写入我们需要写入的内容,通常来说在开发程序的时候用的都是只写模式,需要我们生成第一手代码。但是在只写模式下我们不能进行读取的动作。
当我们使用只写模式打开文件的时候如果文件不存在会创建新文件,如果存在就清空内容然后写入。
with open(r'D:\pythonproject\a.txt','w',encoding='utf8') as f1:
a = f1.write('猪猪男孩小康康')
with open(r'D:\pythonproject\a.txt', 'r', encoding='utf8') as f2:
b = f2.read()
print(b) # 结果:猪猪男孩小康康
3、只追加模式(a)
在只追加模式下我们同样不能读取文本的内容,当我们在往文件内写入内容的时候,会在文件的末尾插入我们缩写的内容。
当我们用只追加模式打开文件的时候如果文件不存在会创建一个新的文件,如果文件存在就会在末尾加入缩写的内容。
with open(r'D:\pythonproject\a.txt','a',encoding='utf8') as f1:
a = f1.write('猪猪男孩小康康')
with open(r'D:\pythonproject\a.txt', 'r', encoding='utf8') as f2:
b = f2.read()
print(b) # 结果:这是a文本猪猪男孩小康康
四、文件的操作模式
上文中我们讲解的文本的读写模式只是操作模式中的一种,也是默认的操作模式,在输入读写模式的时候只需要简写就可以。这里我们还要介绍通用的操作模式——二进制模式。为了方便理解我们把t模式(文本操作模式)和b模式(二进制操作模式)对比着讲解:
| t模式 | b模式 |
|---|---|
| 默认的操作模式 | 二进制操作模式 |
| 三种操作模式的全称是rt、wt、at,当我们使用的时候可以省略t | 对应的三种模式是rb、wb、ab,使用的时候需要写全 |
| 只能对文本文件进行操作 | 可以对所有类型的文件进行操作,但是部分类型的文件不能打开 |
| 操作的时候可以指定的个数,是字符的个数 | 操作的时候可以指定操作的个数,这里是字节的个数(一个英文一个字节,一个中文三个字节) |
| 需要在后面指定编码的类型(encoding = 'utf8') | 不需要在后面指定编码类型(已经是二进制了) |
注:二进制操作模式下的各种规律是和文本操作模式下一样的,可以参考上面的例子。
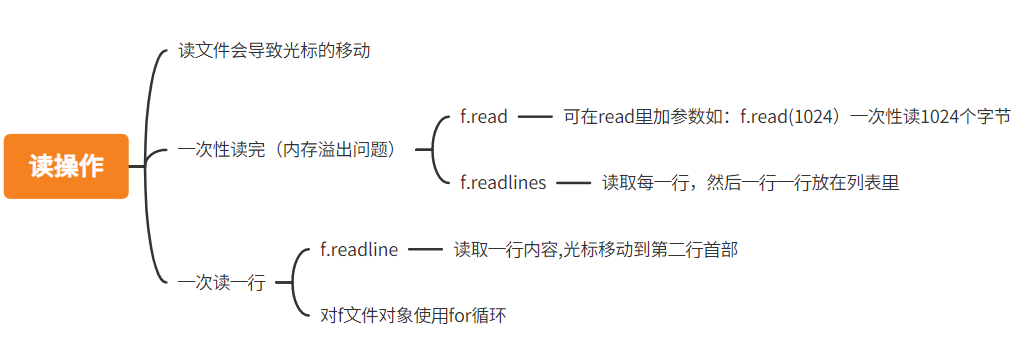
五、文件的诸多方法
1、read()
把文件中的所有内容一次性读取出来,括号内可以加入参数控制一次读取多少数据值,但是在不同的操作模式下有不同的读取规律。当文件过大的时候容易出现内存溢出的情况,因此有了以下读取方式:
for line in document:
print(line)
通过for循环一行行读取内容,防止出现内存溢出的情况。
with open(r'D:\pythonproject\a.txt', 'r', encoding='utf8') as f6:
print(f6.read())
# 结果如下:
'''
小康康爱睡觉
小康康爱洗澡
小康康爱干饭
'''
2、readline()
执行一次会读取一行的内容,和for循环功能相似,但是需要重复执行。
with open(r'D:\pythonproject\a.txt', 'r',encoding='utf8') as f4:
a = f4.readline()
b = f4.readline()
c = f4.readline()
print(a)
print(b)
print(c)
# 结果如下:
'''
猪猪男孩小康康1
猪猪男孩小康康2
猪猪男孩小康康3
'''
3、readlines()
一次性读取所有的文件内容,并把他们以一行为一个数据值分开,放入列表中。
with open(r'D:\pythonproject\a.txt', 'r',encoding='utf8') as f4:
a = f4.readlines()
print(a)
# 结果如下:
'''
['猪猪男孩小康康1\n', '猪猪男孩小康康2\n', '猪猪男孩小康康3']
'''
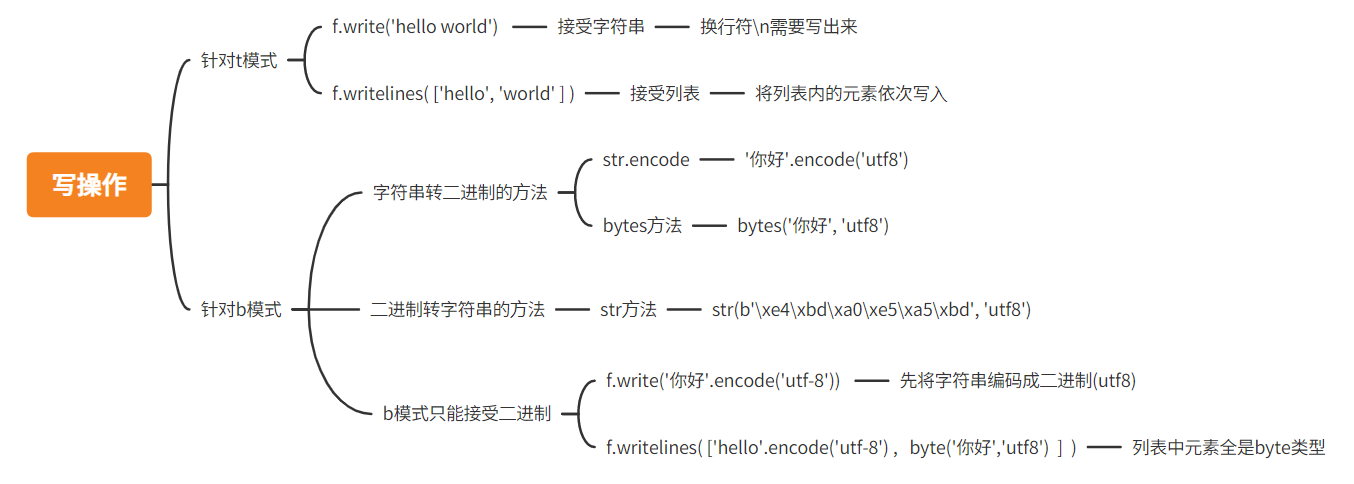
4、write()
写入内容
with open(r'D:\pythonproject\a.txt', 'w',encoding='utf8') as f5:
a = f5.write('小康康爱睡觉')
with open(r'D:\pythonproject\a.txt', 'r', encoding='utf8') as f6:
print(f6.read())
# 结果如下:
'''
小康康爱睡觉
'''
5、writelines()
在括号内可以插入一个列表,之后会将列表中的数据值一个个都写入到文本中
with open(r'D:\pythonproject\a.txt', 'w',encoding='utf8') as f5:
a = f5.writelines(['小康康爱睡觉\n','小康康爱洗澡\n','小康康爱干饭\n'])
with open(r'D:\pythonproject\a.txt', 'r', encoding='utf8') as f6:
print(f6.read())
# 结果如下:
'''
小康康爱睡觉
小康康爱洗澡
小康康爱干饭
'''
6、readabel()
用于判断文件是否可以读取
with open(r'D:\pythonproject\a.txt', 'r',encoding='utf8') as f4:
a = f4.readable()
print(a)
# 结果如下:
'''
True
'''
with open(r'D:\pythonproject\a.txt', 'w',encoding='utf8') as f5:
a = f5.readable()
print(a)
# 结果如下:
'''
False
'''
7、writable()
用于判断文件是否可以写入
with open(r'D:\pythonproject\a.txt', 'r',encoding='utf8') as f4:
a = f4.writable()
print(a)
# 结果如下:
'''
False
'''
with open(r'D:\pythonproject\a.txt', 'w',encoding='utf8') as f5:
a = f5.writable()
print(a)
# 结果如下:
'''
True
'''
8、flush()
强制保存的作用
9、tell
返回光标所在位置的函数,他可以返回光标距离开头的字节数。
with open(r'D:\pythonproject\a.txt', 'r',encoding='utf8') as f4:
a = f4.read()
# 先让光标跑到末尾然后返回距离开头的位置
b = f4.tell()
print(a)
print(b)
# 结果:
'''
猪猪男孩小康康
21
'''
六、文件内光标的移动
在上面尝试文件的操作模式的相关内容的时候我们会发现有些代码第一次执行有内容读取到,后面就读取不到内容了,这是因为光标在第一次读取后就到了文件的最末尾,之后的几次读取就没有内容可以读取了。
接下来我们介绍一个函数用于改变光标的位置(tell函数由于使用少放到了上面):
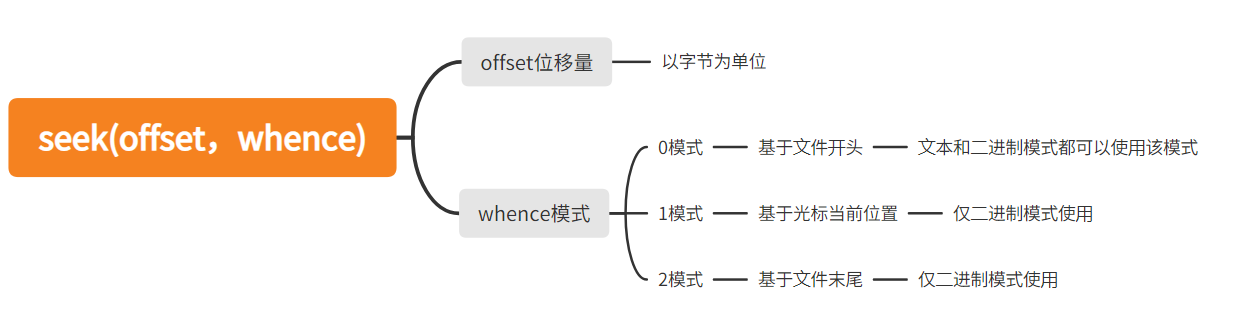
seek(offset, whence)
这里的offset参数是用来控制移动的位移量,位移量只能是是字节(bytes)
whence参数是规定使用的模式,有0,1,2三种模式,其中0模式表示基于文件开头开始操作,1模式表示在文件的当前位置进行操作,2模式表示在文件的末尾进行操作,但是位移量需要变成负数才能读到结果。在使用时候文本模式只能使用0模式,二进制模式可以使用所有模式
t模式下的操作展示:
with open(r'D:\pythonproject\a.txt', 'rt, encoding='utf8') as f2:
a = f2.read()
b = f2.read()
f2.seek(0, 0)
c = f2.read()
print('结果:'+a)
print('结果:'+b)
print('结果:'+c)
# 结果如下:
'''
结果:猪猪男孩小康康
结果:
结果:猪猪男孩小康康
'''
b模式下的操作展示:
with open(r'D:\pythonproject\a.txt', 'rb') as f3:
f3.seek(6, 0)
# 跳过六个字节(两个中文)然后读取所有内容
a = f3.read()
# 跳过六个字节(两个中文)后,在当前位置再往后跳六个字节(两个中文字符),然后读取所有的后续内容
f3.seek(6, 0)
f3.seek(6, 1)
b = f3.read()
# 光标回到开头(初始化),然后从末尾往前取六个字节(两个中文字符),再读取后续内容
f3.seek(0,0)
f3.seek(-6, 2)
c = f3.read()
# 光标回到开头(初始化),然后读取六个字节(两个中文字符)
f3.seek(0, 0)
d = f3.read(6)
print('结果:'+a.decode('utf8'))
print('结果:'+b.decode('utf8'))
print('结果:'+c.decode('utf8'))
print('结果:'+d.decode('utf8'))
# 结果如下:
'''
结果:男孩小康康
结果:小康康
结果:康康
结果:猪猪
'''
with open(r'D:\pythonproject\a.txt', 'rb') as f4:
七、 文件内光标移动案例(了解)
昨天讲解了如何使文件内的光标移动,现在我们举一个更符合实际情况的例子。
import time
# 这里是用于调用时间模块,他会返回给我们一个时间戳,下面的代码是用于监控文件中是否有新的内容产生
with open(r'a.txt', 'rb') as f:
# 打开a文件,使用的是二进制模式
f.seek(0, 2)
# 把光标定位到文件的最末尾
while True:
# 开始不断的监控,一次往下读取一行
line = f.readline()
# 如果监控一次没有发现新的内容就暂时停止0.5秒,如果监控到了新的内容就把他打印出来
if len(line) == 0:
# 没有内容,停止0.5秒
time.sleep(0.5)
else:
# 监控到了新的内容,将其打印出来
print(line.decode('utf8'), end='')
八、计算机硬盘修改数据的原理(了解,为了文件内容修改作解释)
在计算机的存储设备中,经过发展,到目前为止出现了两种主流设备设备:机械硬盘和固态硬盘。固态硬盘是通过算法来存储数据值的,机械硬盘是通过在光盘上刻录数据的方式来达成存储数据的目的。而机械硬盘的存储数据的方式就跟我们通过代码操作文件进行修改内容的原理十分相似。当我们刚买来一个机械硬盘的时候,它的内部并没有写入数据,内部的光盘上是空的,当我们第一次保存文件进去的时候,就相当于往光盘上刻录我们的数据。当数据写满后,就相当于光盘上录满了内容,此时我们需要删除一些数据,但是当我们删除这些数据的时候并不表示这些数据已经永久删除了,他们只是从写满时候的占有态变成了自由态,这个时候只是不能被读写。如果我们使用恢复数据的软件进行恢复,就可以重新获得这些数据。但是当我们在这些数据变成自由态的时候,保存了其他数据,那么这些数据值就不存在了。
之后当我们对保存的文件进行修改的时候会出现两种情况,需要分别表述:
情况一:保存到其他地方
当我们的磁盘进行保存操作的时候,他并没有把这个文件保存在原本的位置,而是取消了原本文件的占有态,使他变成自由态,并在其他地方重新保存了一个跟原文件一样名称的修改后的文件。
特点:占用磁盘空间较多,但是节约内存资源。
情况二:保存到原来位置(覆盖)
当我们对磁盘进行保存操作的时候,系统把修改后的文件保存到了原来的位置。但是保存在这里的文件并不是原来的文件了,在我们看不到的地方计算机进行了一系列的操作:1、删除原本的文件,2、把修改后的文件保存到原来的磁盘位置中,3、给保存后的文件命名成原来的名字。
特点:节省磁盘空间。但是占用内存资源较多。
九、文件内容修改
之前我们所讲的文件的操作其实就是对于内容的修改,当我们使用代码完成修改后,跟我们平时使用软件不一样,不需要刻意进行保存,修改结束后就会自动保存。
在我们使用代码对文件内容进行修改的时候,计算机的处理逻辑跟机械磁盘的处理方式相似,也是两种保存方式:
方式一
修改完成后保存在原来的地方
# 修改文件内容的方式1:覆盖写
with open(r'a.txt', 'r', encoding='utf8') as f:
data = f.read()
with open(r'a.txt', 'w', encoding='utf8') as f1:
f1.write(data.replace('jason', 'tony'))
# 打开文件读取内容后替换jason为tony,并把替换后的内容覆盖到原来的文件中
方式二
删掉原来的文件,把内存中修改后的文件保存到其他地方命名成原来的名字
# 修改文件内容的方式2:换地写
'''先在另外一个地方写入内容 然后将源文件删除 将新文件命名成源文件'''
import os
# 调用了一个名叫os的方法库,方便后续使用内置方法操作
with open('a.txt', 'r', encoding='utf8') as read_f, open('.a.txt.swap', 'w', encoding='utf-8') as write_f:
for line in read_f:
write_f.write(line.replace('tony', 'kevinSB'))
# 从文件中读取内容然后遍历进行对比替换,并把替换后的内容写入到另一个文件中,最后我们会在另一个文件中得到修改后的结果
os.remove('a.txt') # 删除原来的文件
os.rename('.a.txt.swap', 'a.txt') # 把另一个文件命名成原来文件的名字,就当作把他替换了


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)