python数据类型的内置方法
今日内容总结
一、数据类型的内置方法理论
所谓内置方法就是数据类型内部自带的一些快捷操作
表现形式:
变量名.方法名(参数可以自己加)
变量名或是数据值的后方跟上英文状态的句号然后跟上方法。
注:在尝试记忆的过程中,不推荐死记硬背,建议带入到平时的学习使用中记忆。
二、整形(int)的内置方法
1、类型转换(把其他类型转换成自己的类型)
整形可以把浮点型和特定条件下的变成整形(使用int方法):
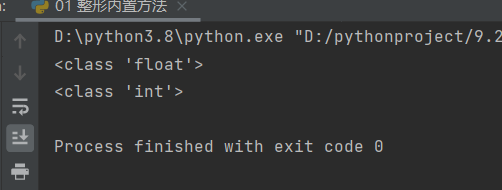
1.如果是没有小数部分的浮点型,会直接在使用int方法后变成整形。
a = float(666)
print(type(a))
print(type(int(a)))
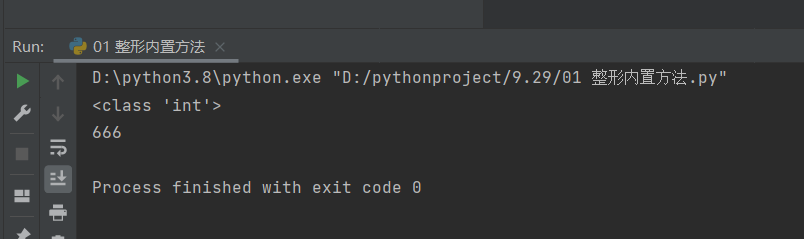
2.如果是有小数的浮点型,会直接砍掉小数部分,只显示整数部分。
# 这肯定是浮点型的数值,就不打印类型了
b = 666.666
print(type(int(b)))
print(int(b))
# 可以看到小数点后面的全砍掉了
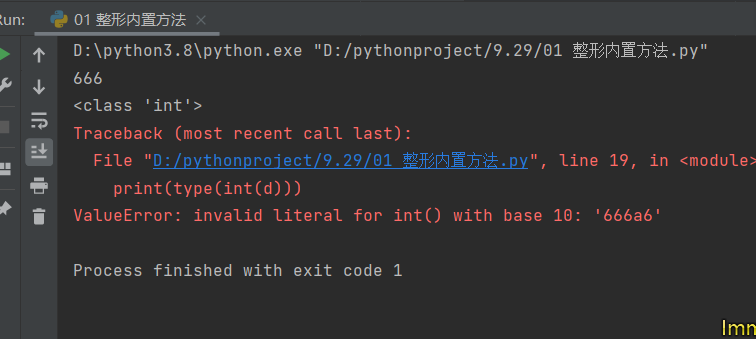
3、如果是字符串类型,需要确保组成的字符串中只有数字,如果出现背的字符会直接报错。
# 这里是没有加入其他字符的纯数字字符串
c = '666'
print(int(c))
print(type(int(c)))
# 这里是加入了字母的字符串
d = '666a6'
print(type(int(d)))
print(int(d))
# 通过观察结果发现有字母的会直接报错
2、进制转换
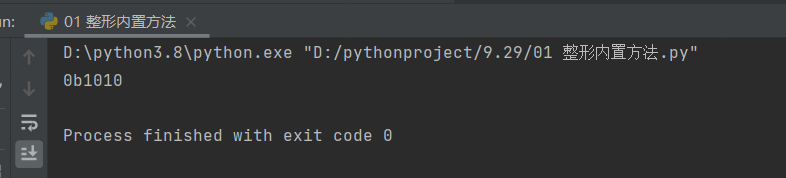
1.转换成二进制
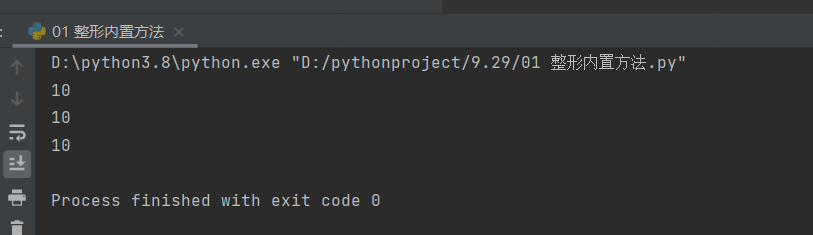
a = 10
print(bin(a)) # 0b1010
2.转换成八进制
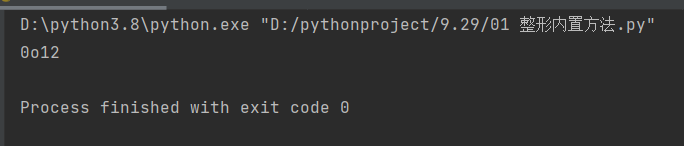
a = 10
print(oct(a)) # 0o12
3.转换成十六进制
a = 10
print(hex(a)) # 0xa

4.其他进制转换成十进制
# 这里就直接用之前转的数据
b = 0b1010
c = 0o12
d = 0xa
print(int(b))
print(int(c))
print(int(d))
特殊情况讲解
我们可以看到上方的转换结果中,其他进制的结果前面都有出现特殊符号,如0b、0o、0x。这是对应进制的代表符号。当我们使用int方法转换其他进制的时候,如果数据是字符串类型,依旧使用进制符号+数值的形式去转换的话会直接失败,这里我们需要在字符串后方跟上进制数才能转换。如果字符串中没有写进制符号也没用影响,在后面跟上进制数一样可以转换。
把值放到字符串中,并且。举例:
# 这里值还是用之前转的数据
x = '1010'
y = '12'
z = 'a'
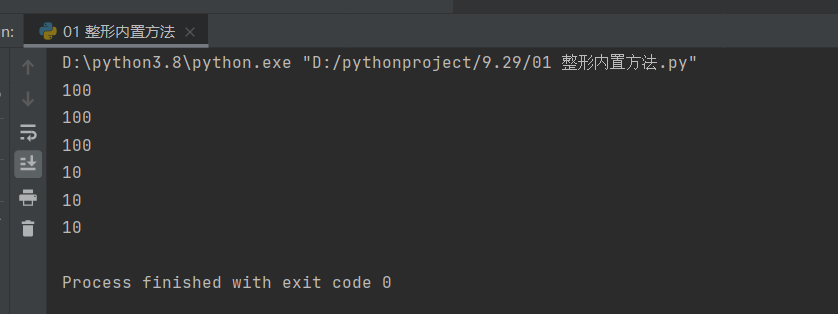
print(int("0b1100100", 2))
print(int("0o144", 8))
print(int("0x64", 16))
print(int(x, 2))
print(int(y, 8))
print(int(z, 16))
三、浮点型(float)的内置方法
1、类型转换(把其他类型转换成自己的类型)
float方法可以把整形、特殊情况下的字符串变成float类型:
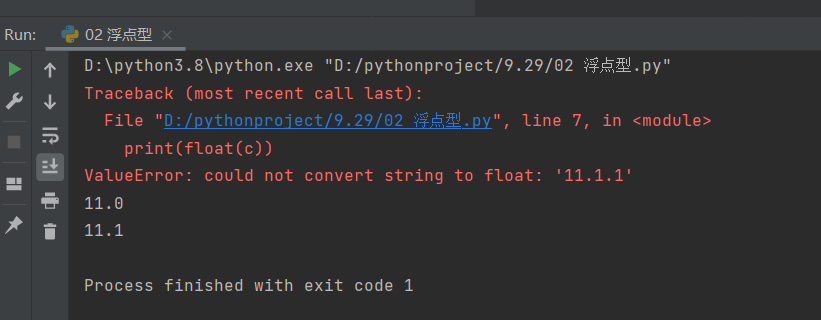
a = 11
b = '11.1'
c = '11.1.1'
print(float(a))
print(float(b))
print(float(c))
# 这里的话运行c的转换的时候会直接报错
特殊说明:
python对数字的运算其实并不敏感(精确),但是由于背后大佬较多,我们可以使用模块进行精确计算。举例:
# 证明:python对数字不敏感(准确)
print(0.1 + 0.2) # 经典的0.1+0.2!=0.3
# output:0.30000000000000004
print(1.01 + 1.02)
# output:2.0300000000000002
四、字符串(str)的内置方法
1、类型转换(把其他类型转换成自己的类型)
字符串可以转换所有类型的数据值,从结果看就是在两边加上引号:
a = 11
b = 11.1
c = [1, 1, 2, 2]
d = {'name': '猪猪男孩康世宏', 'age': 99}
e = {1, 2, 3, 3}
f = (1,3,3,4)
g = True
print(str(a))
print(type(str(a)))
print(str(b))
print(type(str(b)))
print(str(c))
print(type(str(c)))
print(str(d))
print(type(str(d)))
print(str(e))
print(type(str(e)))
print(str(f))
print(type(str(f)))
print(str(g))
print(type(str(g)))
2、内置方法(掌握)
1.索引取值
根据字符所在位置取值(从0开始)
# 索引取值
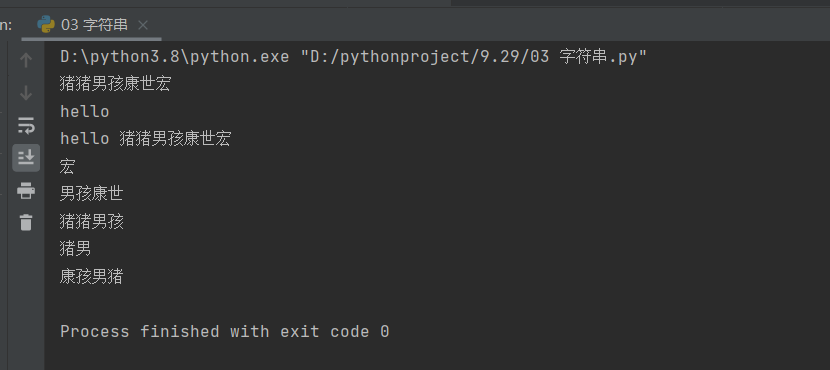
information = 'hello 猪猪男孩康世宏'
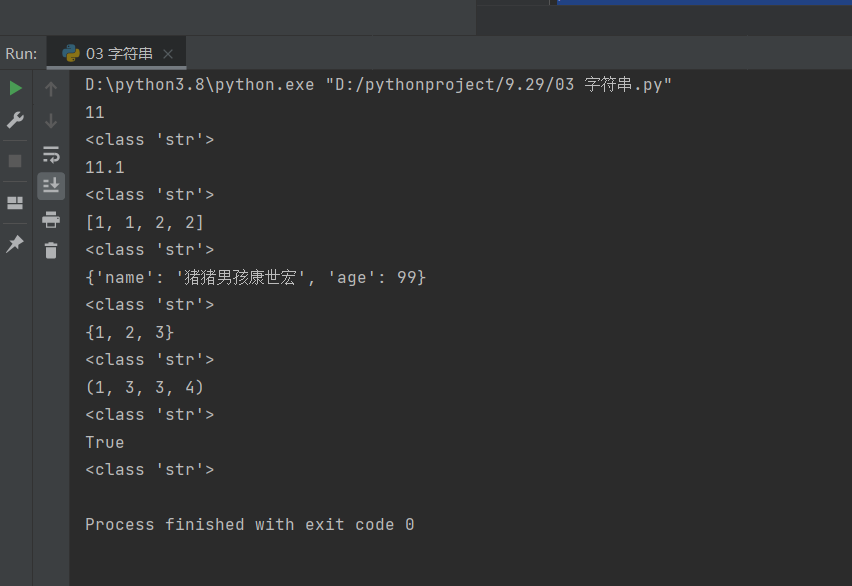
print(information[0])
这里就是取了第一个值:
切片取值
# 升级版本:切片取值
information = 'hello 猪猪男孩康世宏'
print(information[6:]) # 从6取到结尾
print(information[:6]) # 取到第六个就结束,第六个不取
print(information[:]) # 取所有的值
print(information[-1:]) # 从后往前取,从后往前取的时候
print(information[-5:-1]) # 用负的位置坐标取值,需要小的在前大的在后
print(information[6:10]) # 从第六个开始,取到10,但是取不到10的位置,只能到九
print(information[6:10:2]) # 从第六个开始,取到10,但是取不到10的位置,并且两个字符取一次
print(information[10:6:-1]) # 从第10个开始,取到6,但是取不到6的位置,是从后往前取
结果如下:
2.统计字符串长度(个数)
len:计算字符串长度或个数
# 计算长度的len
information = 'hello 猪猪男孩康世宏'
print(len(information))
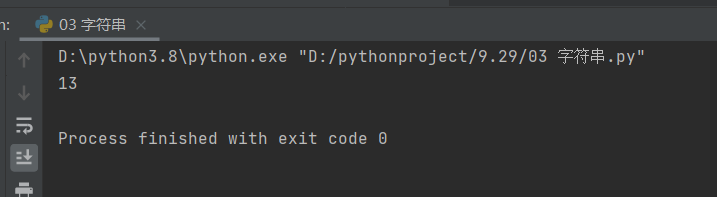
注:字符串中的空格也算一个字符。
3.strip方法:删除首尾的内容
作用介绍:删除字符串首尾的空格,或是指定的字符。生活中主要使用在账号密码的输入中,可以减少错误。
# 删除字符串首尾的空格
# information = ' hello 猪猪男孩康世宏 '
# print(information.strip())
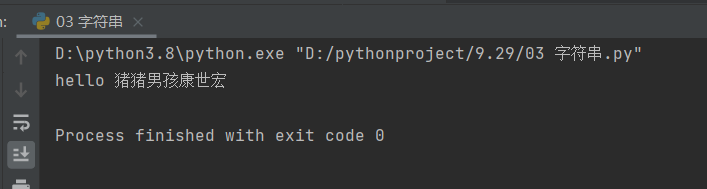
# 删除字符串首尾的指定字符
information = ' hello 猪猪男孩康世宏 '
print(information.strip('猪'))
# 这里可以看到没有变化,因为'猪猪在中间位置'
information = ' hello 猪猪男孩康世宏宏宏宏'
print(information.strip('宏'))
# 这里可以看到后面的宏字没了
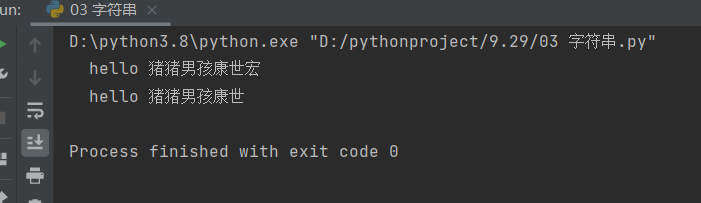
两种变形:
lstrip和rstrip:删除左侧或右侧字符的strip方法
# 左侧:lstrip
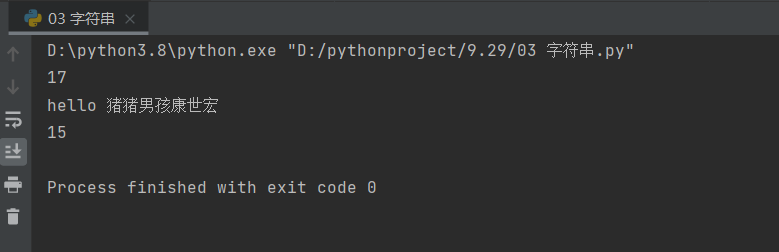
information = ' hello 猪猪男孩康世宏 '
print(len(information))
print(information.lstrip())
print(len(information.lstrip()))
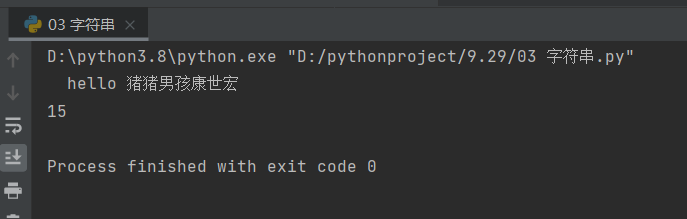
# 右侧:rstrip
information = ' hello 猪猪男孩康世宏 '
print(information.rstrip())
print(len(information.rstrip()))
4.split方法:切块
split:删除指定的字符并从删除的位置把字符串变成列表中的一个个值
# split
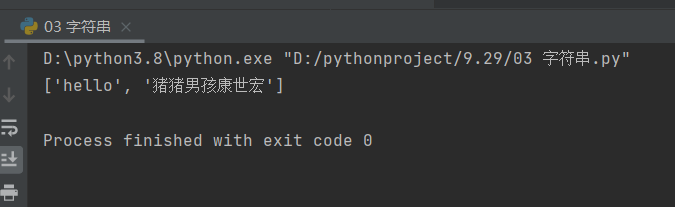
information = 'hello 猪猪男孩康世宏'
print(information.split(' '))
# 这里我们可以看到根据中间的空格把字符串分成了含有两个值的列表,并且空格被删掉了
# 分成指定个数个块
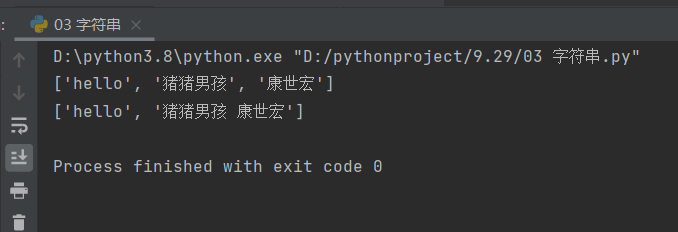
information = 'hello 猪猪男孩 康世宏'
print(information.split(' '))
print(information.split(' ',maxsplit=1))
这里表现出我们可以通过设置参数,设定切割次数:
rsplit:从右边切割
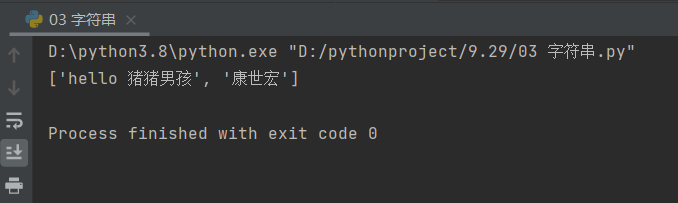
这里我们可以发现,split只有从右边切割的方法,没有从左边切割的方法,因为split本身就是从左往右切割的。
# 其他形式:
# 从右边切割
information = 'hello 猪猪男孩 康世宏'
print(information.rsplit(' ',maxsplit=1))
# 这里只切割一次,方便比较
5.format方法:格式化输出
format方法拥有和%s相似的功能,但是更为强大,也更方便
format方法有四种表现形式,如下:
表现形式一
插入占位的符号,输入占位符输入的值,不能多不能少
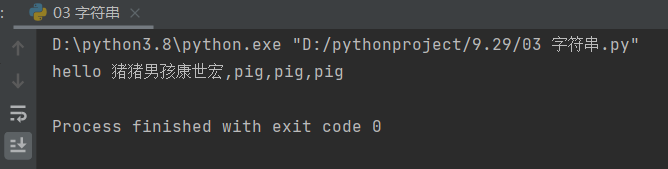
# 表现形式一
information = 'hello 猪猪男孩康世宏,{},{},{}'
print(information.format('pig','pig','pig'))
表现形式二
通过插入数据的索引位置,把相应的值插入占位符中
# 表现形式二
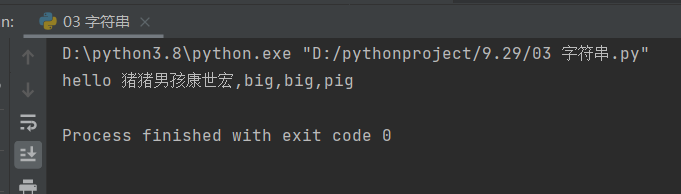
information = 'hello 猪猪男孩康世宏,{0},{0},{1}'
print(information.format('big','pig'))
表现形式三
通过变量的绑定关系插入数据值格式化输出
# 表现形式三
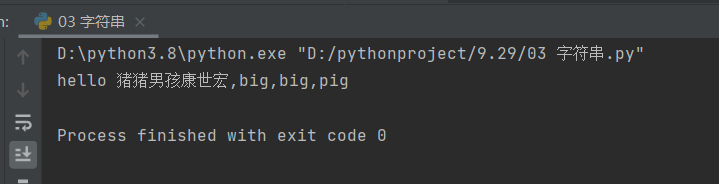
information = 'hello 猪猪男孩康世宏,{first},{first},{second}'
print(information.format(first='big',second='pig'))
表现形式四
通过在定义想要输出的文本时,在文本前面加上f就可以使用format方法格式化输出
# 表现形式四
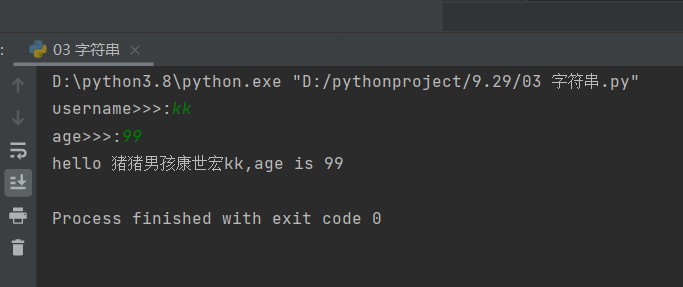
name = input('username>>>:')
age = input('age>>>:')
information = f'hello 猪猪男孩康世宏{name},age is {age}'
print(information)
3、内置方法(了解)
1.大小写的改变和判断
upper()、lower()、isupper()、islower()可以分别用来改变字符串中字母的大小写或是判断是不是全是大写或小写(其他字符不受影响)。这些功能通常会出现在登陆环节中的验证码中,降低验证的失误率。
upper()
把当前字符串中的字母全部转变成大写的形式
# 1、字母大小写变换和判断
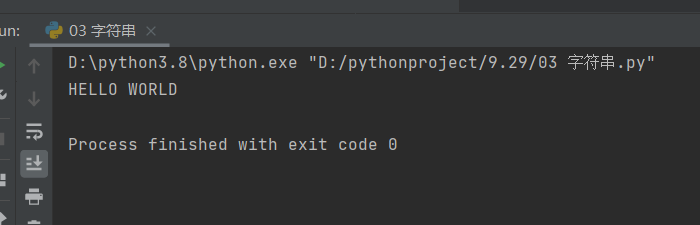
# upper()把所有字母变成大写
infor = 'hello world'
print(infor.upper())
lower()
把当前字符串中的字母全部转变成小写的形式
# lower()把所有字母变成小写
infor1 = 'HELLO WORLD'
print(infor1.lower())
isupper()
判断当前字符串中的字母是否全为大写的形式,如果是返回True,否则返回False
# isupper()判断当前字符串中的字母是否全为大写的形式
infor2 = 'Hello World'
infor1 = 'HELLO WORLD'
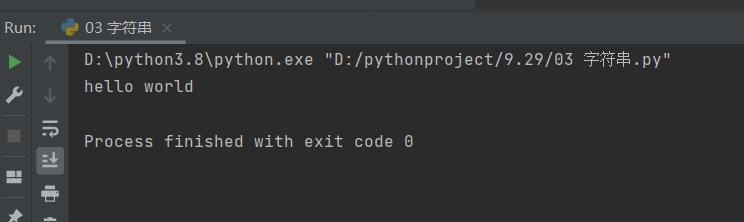
print(infor1.isupper())
print(infor2.isupper())
这里我们用两组字符串进行对比可以明显看到差别:
islower()
判断当前字符串中的字母是否全为小写的形式,如果是返回True,否则返回False
# islower()判断当前字符串中的字母是否全为小写的形式
infor2 = 'Hello World'
infor = 'hello world'
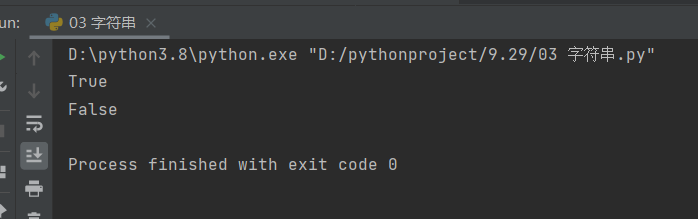
print(infor.islower())
print(infor2.islower())
这里我们也用两组字符串进行对比:
2.判断字符串中的数据值是否是纯数字:isdigit
这里我们使用isdigit进行判断,如果字符串中是纯数字就会返回True,否则返回False
# 2、判断字符串中的数据值是否为纯数字,是就返回True,否则返回False
test_1 = '11111'
test_2 = '不太聪明的狗子康11111'
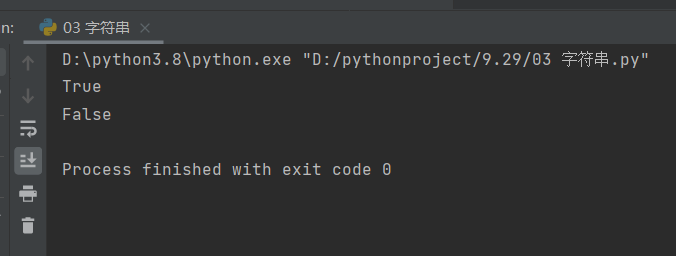
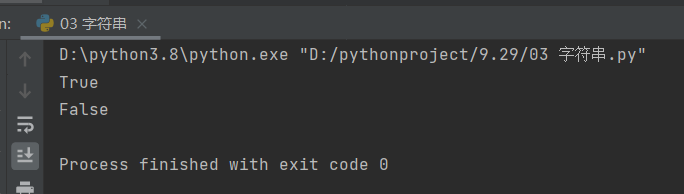
print(test_1.isdigit())
print(test_2.isdigit())
结果如下:
3.替换字符串中的指定内容:replace
根据输入的内容,从左往右依次替换其中的需要被替换的内容
1.替换选中内容的所有对象
# 3.替换指定内容:replace
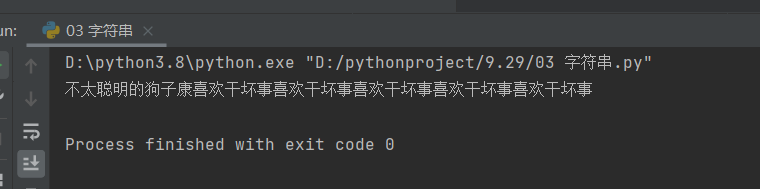
test_2 = '不太聪明的狗子康11111'
print(test_2.replace('1','喜欢干坏事'))
结果如下:
2.替换选中内容,并且可以自定义替换个数
# 替换指定内容并且指定替换的个数
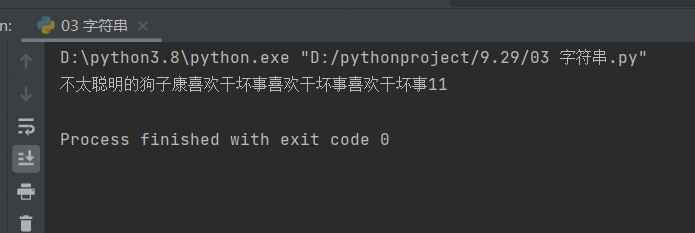
test_2 = '不太聪明的狗子康11111'
print(test_2.replace('1','喜欢干坏事',3))
结果如下:
4.字符串的拼接:join
通过之前的学习,我们可以察觉到数据值之间可以通过运算符号进行操作,比如可以通过'+'号连接起来。也可以通过'*'号一次性输出多个数据值。
除去这些方法,还有'join'方法可以打到同样的效果,并且更加高效,更加方便。
代码展示:
通过运算符号操作
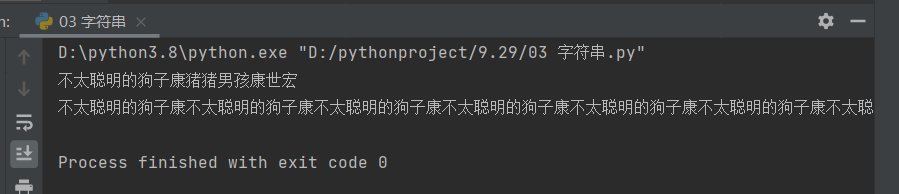
# 通过运算符号进行操作
recent = '不太聪明的狗子康'
recent1 = '猪猪男孩康世宏'
print(recent + recent1)
print(recent * 10)
通过join方法进行拼接
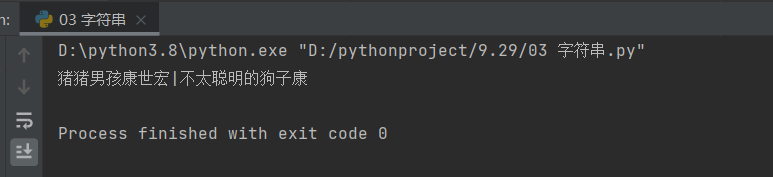
# 通过join方法:字符串的拼接
recent = '不太聪明的狗子康'
recent1 = '猪猪男孩康世宏'
print('|'.join([recent1,recent]))
# 通过'|'符号把列表中的两个数据值组成一个字符串
这里的话需要把字符串放入列表中输出,否则会因为不能装下这么多数据值而报错
5.统计指定字符出现的次数:count
count这个单词就是统计的意思,所以它的作用也是一样的,可以统计指定字符出现的次数
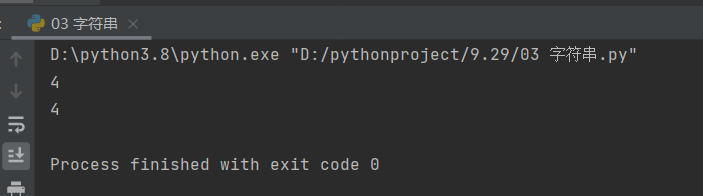
# 统计指定字符出现的次数
recent2 = '猪猪男孩康世宏,96969696'
print(recent2.count('9'))
# 这里统计的是9出现的次数
print(recent2.count('96'))
# 这里统计的是96出现的次数
6.判断字符串的开头或结尾
在字符串中我们可以startswith和endswith来判断字符串开头或结尾是否是我们想要的数据值。
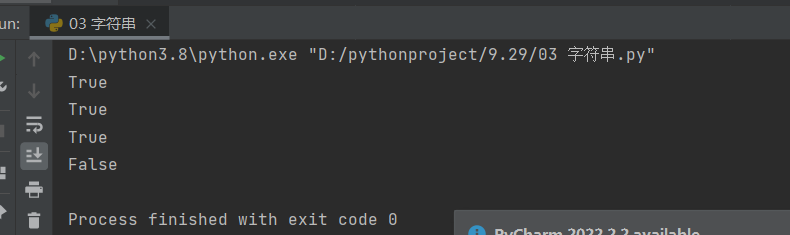
startswith
判断开始位置的值
# startswith:判断字符串开始的值
recent1 = '猪猪男孩康世宏'
print(recent1.startswith('猪'))
print(recent1.startswith('猪猪'))
print(recent1.startswith('猪猪男孩'))
# 取一个中间的字符用于举反例
print(recent1.startswith('康'))
endswith
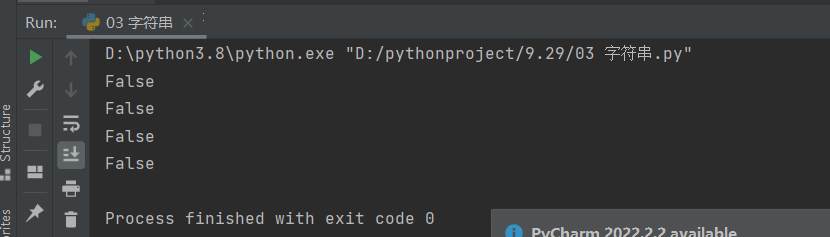
判断结束位置的值
# endswith:判断字符串末尾的值
recent1 = '猪猪男孩康世宏'
print(recent1.endswith('猪'))
print(recent1.endswith('猪猪'))
print(recent1.endswith('猪猪男孩'))
# 取一个中间的字符用于举反例
print(recent1.endswith('康'))
7.其他方法补充
①:title
起到一个把所有英文单词首字母大写其他字母小写的作用
res = 'helLO wORld hELlo worLD'
print(res.title()) # Hello World Hello World
②:capitalize
起到一个把第一个单词首字母大写,其他字母小写的作用
res = 'helLO wORld hELlo worLD'
print(res.capitalize()) # Hello world hello world
③:swapcase
起到把所有字母的大小写反转的作用
res = 'helLO wORld hELlo worLD'
print(res.swapcase()) # HELlo WorLD HelLO WORld
④:index
返回指定字符的索引值,如果找不到字符会直接报错。当输入多个字符的时候会返回字符中第一个字符的索引值。
res = 'helLO wORld hELlo worLD'
print(res.index('O'))
# 这里是找不到的情况
print(res.index('c')) # 找不到直接报错
⑤:find
也是用于寻找字符的索引值,如果找不到字符就返回值'-1'。当输入多个字符的时候会返回字符中第一个字符的索引值。
res = 'helLO wORld hELlo worLD'
print(res.find('O'))
print(res.find('c')) # 找不到默认返回-1
print(res.find('LO')) # 3
五、列表(list)的内置方法
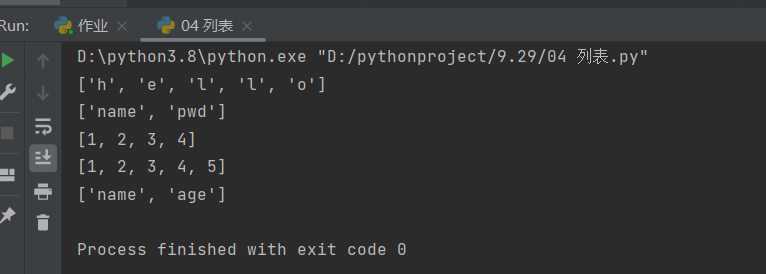
1、类型转换(把其他类型转换成自己的类型)
注:能够被for循环遍历的数据类型都可以转换成列表
print(list('hello'))
print(list({'name': 'jason', 'pwd': 123}))
print(list((1, 2, 3, 4)))
print(list({1, 2, 3, 4, 5}))
print(list({'name': 'java','age':'18'}))
运行结果如下:
2、索引取值
根据列表的索引顺序,可以取出指定位置的数据值
l1 = [111, 222, 333, 444, 555, 666, 777, 888]
print(l1[0])
# 取第一个
print(l1[-1])
# 取最后一个
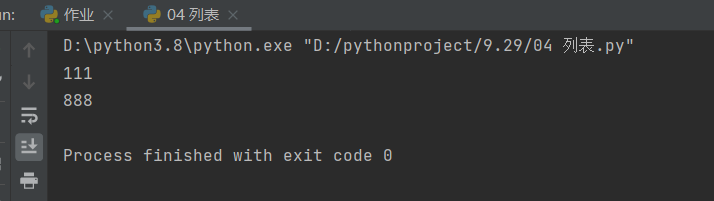
切片操作
类似字符串的切片,可以参考字符串的例子。不过操作单位是一个个的数据值不再是一个个字符。
l1 = [111, 222, 333, 444, 555, 666, 777, 888]
print(l1[0:5])
# 从头取到第五个,第五个取不到
print(l1[:])
# 取所有的数据
print(l1[::-1])
# 从数据的后面往前取
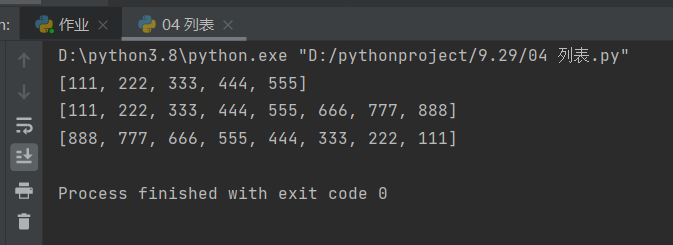
3、统计列表的长度(个数)
依旧是len方法,不过跟字符串不同的是,列表中一个数据值算一个长度。
print(len(l1)) # 8
4、数据值的修改
这里跟之前说的一样,通过索引位置修改绑定的值。
l1 = [111, 222, 333, 444, 555, 666, 777, 888]
l1[0] = 123
print(l1)
# 开头就变成了123
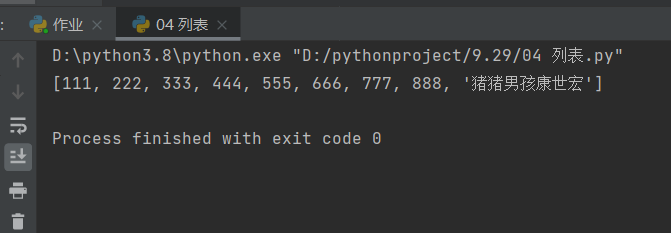
5、添加数据值
方式一:尾部添加数据值——append
# 方式一:尾部添加数据值——append
l1 = [111, 222, 333, 444, 555, 666, 777, 888]
l1.append('猪猪男孩康世宏')
print(l1)
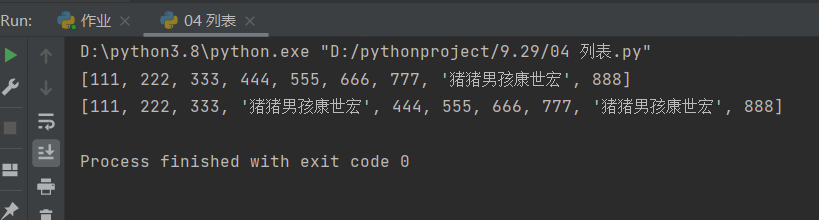
方式二:任意位置插入数据值——insert
# 方式二:任意位置插入数据值——insert
l1 = [111, 222, 333, 444, 555, 666, 777, 888]
l1.insert(-1,'猪猪男孩康世宏')
print(l1)
# 这里我们发现反方向插入数据的时候,不能把数据值加入到最后,只能加在倒数第二个位置
l1.insert(3,'猪猪男孩康世宏')
print(l1)
# 这里顺序插入数据没什么特点
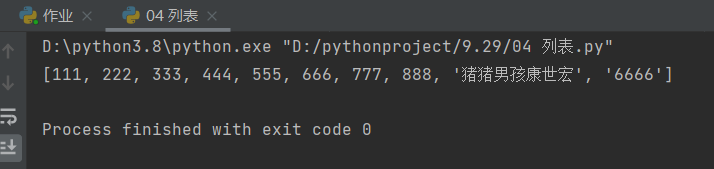
方式三:扩展列表(合并列表)——extend
# 方式三:扩展列表(合并列表)——extend
l1 = [111, 222, 333, 444, 555, 666, 777, 888]
l2 = ['猪猪男孩康世宏','6666']
l1.extend(l2)
print(l1)
# 可以从结果发现加进去的列表会在后面
6、删除列表数据
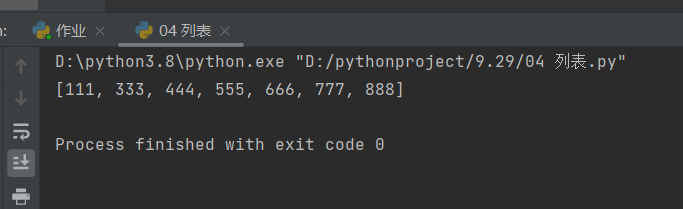
方式一:通用的删除关键字——del
# 方式一:通用的删除关键字——del
l1 = [111, 222, 333, 444, 555, 666, 777, 888]
del l1[1]
# 删除索引1位置的数据值
print(l1)
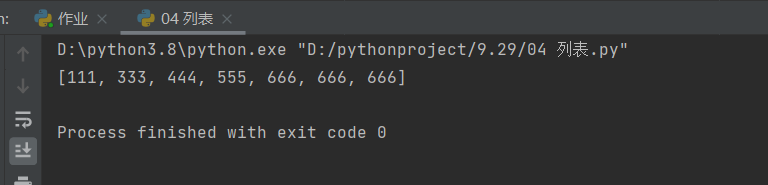
方式二:删除指定数据值——remove
# 方式二:删除指定数据值——remove
l1 = [111, 666, 333, 444, 555, 666, 666, 666]
l1.remove(666)
print(l1)
# 这里我们可以发现remove方法一次只能删除一个数据值,并且是从前往后删
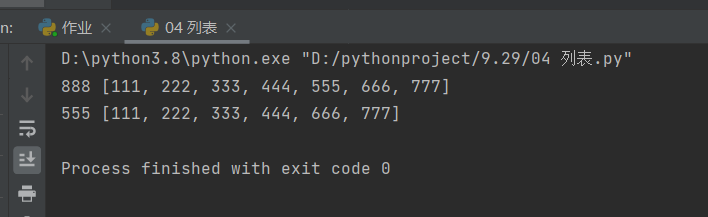
方式三:删除指定索引处的值或是删除最后的数据值——pop(删除的同时可以取得数据值)
# 方式三:删除指定索引处的值或是删除最后的数据值——pop(删除的同时可以取得数据值)
# 删除最后的数据并获得它
l1 = [111, 222, 333, 444, 555, 666, 777, 888]
res = l1.pop()
print(res, l1)
# 删除指定的数据并获得它
res = l1.pop(4)
# 这里是删除索引为4的数据值——555
print(res, l1)
7、排序
方式一:升序——sort
# 方式一:升序——sort
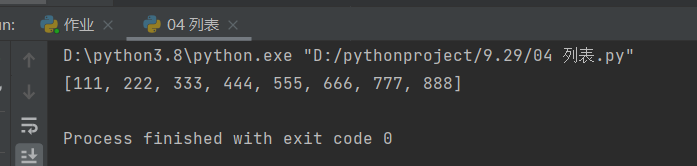
l1 = [111, 444, 555, 666, 222, 333, 777, 888]
l1.sort()
print(l1)
方式二:降序——sort(reverse=True)
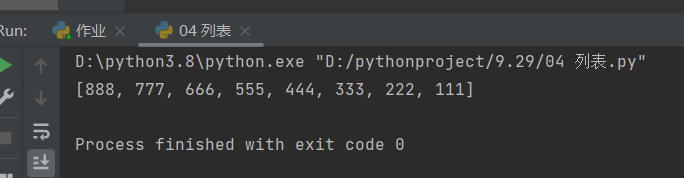
# 方式二:降序——sort(reverse=True)
l1 = [111, 444, 555, 666, 222, 333, 777, 888]
l1.sort(reverse=True)
print(l1)
8、统计某个数据值出现的次数——count
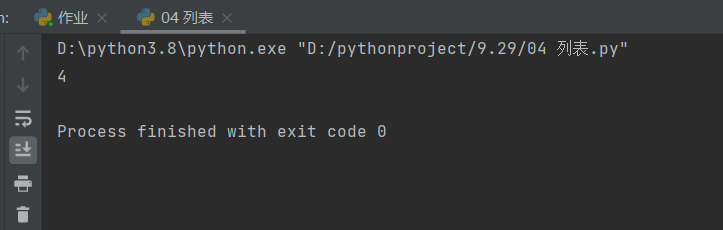
### 8、统计某个数据值出现的次数——count
l1 = [111, 222, 333, 444, 555, 666, 666, 666, 666]
print(l1.count(666))
9、颠倒列表的排序——reverse
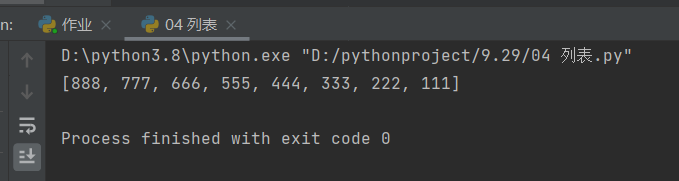
### 9、颠倒列表的排序——reverse
l1 = [111, 222, 333, 444, 555, 666, 777, 888]
l1.reverse()
print(l1)
六、可变类型和不可变类型
当我们在验证字符串和列表的相关功能的同时,我们会发现两者的输出方式不一样,使用方法后列表只需要输出列表就可以得到改变等候的结果,但是字符串需要把方法放大打印的语句中才能输出改变后的结果。这里我们引进了可变类型和不可变类型来解释其中原理。当字符串应用了内置方法后,在内存中它的绑定的内存地址并没有改变(就是没有修改自己的值),而是产生了一个新的值,我们输出的也是这个值。到了列表中,就相当于直接修改了列表中的数据,我们如果用变量名绑定方法执行的语句,打印出来后会得到一个'None',而直接打印列表就可以得到改变后的结果,但是列表的内存地址并没有改变只是其中的数据换了。
规律小结:
可变类型:值改变 内存地址不变
不可变类型:值改变 内存地址肯定变
七、字典的内置方法
1、类型转换(把其他类型转换成自己的类型)
与之前的数据类型相同,字典的转换方法就是dict()。但是字典的转换条件很苛刻,只有以下两种情况下的字符串可以用于转换,所以通常我们都是自己定义。
两种转换形式:
# 转换方法一:
nfo = dict([['name', 'tony'], ('age', 18)])
# 如果我们想用dict方法转换字典,需要在括号内建立一个列表并在列表内建立两个列表分别放入键(key)和值(value),否则就报错。
print(nfo) # 输出结果:{'name': 'tony', 'age': 18}
# 转换方法二:fromkeys会从元组中取出每个值当做key,然后与None组成key:value放到字典中
nfo1 = {}.fromkeys(('name', 'age', 'sex'), None)
print(nfo1) # 输出结果:{'name': None, 'age': None, 'sex': None}
2、取值
第一种方法:
我们可以通过键(key)取值,但是我们需要注意,如果没有这个键(key),就会直接报错。
user_dict = {
'username': 'jason',
'password': 123,
'hobby': ['read', 'music', 'run']
}
print(user_dict['username']) # jason
print(user_dict['phone']) # k不存在会直接报错
第二种方法:
我们也可以通过使用.get方法来取值,如果没有这个键,默认会返回None,也可以自己定义返回值,不会报错。
user_dict = {
'username': 'jason',
'password': 123,
'hobby': ['read', 'music', 'run']
}
print(user_dict.get('username')) # jason
print(user_dict.get('age')) # None
# get方法可以有两个参数,第一个参数用于查找键(key),第二个参数用于在找不到的情况下给出提示
print(user_dict.get('username', '没有哟 嘿嘿嘿')) # jason 键存在的情况下获取对应的值
print(user_dict.get('phone', '没有哟 嘿嘿嘿')) # 键不存在默认返回None 可以通过第二个参数自定义
3、修改数据值
由于字典是无序的,我们要通过键来修改值。
user_dict = {
'username': 'jason',
'password': 123,
'hobby': ['read', 'music', 'run']
}
user_dict['username'] = 'java'
print(user_dict)
# 结果如下:{'username': 'java', 'password': 123, 'hobby': ['read', 'music', 'run']}
4、增加数据值
字典中增加新的值不需要使用方法,依旧是输入键和值,如果键存在的时候,就是修改值,如果键不存在,就是新增值。
user_dict = {
'username': 'jason',
'password': 123,
'hobby': ['read', 'music', 'run']
}
user_dict['language'] = 'java'
print(user_dict)
# 结果如下:{'username': 'jason', 'password': 123, 'hobby': ['read', 'music', 'run'], 'language': 'java'}
append方法
需要字典的值都是列表才能使用
# 这里的append方法其实和根据键增加值是一样的效果
user_test = {'name':[1],'pwd':[1],'hobby':[1]}
user_test['name'].append('jason')
user_test['pwd'].append(123)
user_test['hobby'].append('study')
print(user_test)
# 结果如下:{'name': [1, 'jason'], 'pwd': [1, 123], 'hobby': [1, 'study']}
从代码中我们可以得出结论,当字典的值是可变类型的时候,可以使用append方法加入值,当值为列表的时候会加在列表末尾。
5、删除数据值
1.del 方法
del是删除的通用方法,在del后方跟上删除的键就能把键和值一起删了
user_dict = {
'username': 'jason',
'password': 123,
'hobby': ['read', 'music', 'run']
}
del user_dict['username']
print(user_dict)
# 结果:{'password': 123, 'hobby': ['read', 'music', 'run']}
2.pop方法
跟其他方法中的用法相同,在删除的同时,可以取得删除对象的值(键不行)
user_dict = {
'username': 'jason',
'password': 123,
'hobby': ['read', 'music', 'run']
}
res = user_dict.pop('password')
print(user_dict)
# 结果:{'hobby': ['read', 'music', 'run']}
print(res) # 123
6、统计字典中键值对的个数
len方法可以统计字典中的数据个数。
user_dict = {
'username': 'jason',
'password': 123,
'hobby': ['read', 'music', 'run']
}
print(len(user_dict)) # 3
7、字典三剑客
1.keys方法
可以打印出所有的键
user_dict = {
'username': 'jason',
'password': 123,
'hobby': ['read', 'music', 'run']
}
print(user_dict.keys())
# 一次性获取字典所有的键 dict_keys(['username', 'password', 'hobby'])
2.values方法
可以打印出所有的值
user_dict = {
'username': 'jason',
'password': 123,
'hobby': ['read', 'music', 'run']
}
print(user_dict.values())
# 一次性获取字典所有的值 dict_values(['jason', 123, ['read', 'music', 'run']])
3.items方法
可以把所有键值对都打印出来
user_dict = {
'username': 'jason',
'password': 123,
'hobby': ['read', 'music', 'run']
}
print(user_dict.items())
# 一次性获取字典的键值对数据 dict_items([('username', 'jason'), ('password', 123), ('hobby', ['read', 'music', 'run'])])
这里拓展一种更加方便的输出方式
user_dict = {
'username': 'jason',
'password': 123,
'hobby': ['read', 'music', 'run']
}
for i in user_dict.items():
k, v = i
print(k)
# k会单独打印所有的键
# 结果:
'''
username
jason
password
'''
print(v)
# v会单独打印所有的值
# 结果
'''
123
hobby
['read', 'music', 'run']
'''
# 当然我们可以把两者放在一起打印出一个个的键值对
print(k, v)
# 结果
'''
username jason
password 123
hobby ['read', 'music', 'run']
'''
8、补充说明
fromkeys方法
多用于快速生成值相同的字典
user_dict = {
'username': 'jason',
'password': 123,
'hobby': ['read', 'music', 'run']
}
res = dict.fromkeys(['name', 'pwd', 'hobby'], [])
print(res)
# 结果:{'name': [], 'pwd': [], 'hobby': []}
使用formkeys方法创建的列表在使用append方法加入值的时候是同时往所有的键中加入值
res = dict.fromkeys(['name', 'pwd', 'hobby'], [])
res['name'].append('jason')
res['pwd'].append(123)
res['hobby'].append('study')
print(res)
# 结果如下:{'name': ['jason', 123, 'study'], 'pwd': ['jason', 123, 'study'], 'hobby': ['jason', 123, 'study']}
setdefault方法
setdefault方法有两个参数,第一个参数是键,第二个参数是想要插入的值。
当key存在时则不做任何修改,并返回已存在key对应的value值
user_dict = {
'username': 'jason',
'password': 123,
'hobby': ['read', 'music', 'run']
}
res = user_dict.setdefault('username','tony')
print(user_dict, res) # 键存在则不修改 结果是键对应的值
# {'username': 'jason', 'password': 123, 'hobby': ['read', 'music', 'run']} jason
当key不存在则新增键值对,并将新增的value返回
user_dict = {
'username': 'jason',
'password': 123,
'hobby': ['read', 'music', 'run']
}
res = user_dict.setdefault('age',123)
print(user_dict, res) # 键不存在则新增键值对 结果是新增的值
{'username': 'jason', 'password': 123, 'hobby': ['read', 'music', 'run'], 'age': 123} 123
popitem方法
跟pop方法的用法相似,默认情况下会先删除最后一个插入的键值对,同样我们也可以用变量名绑定这个键值对。
user_dict = {
'username': 'jason',
'password': 123,
'hobby': ['read', 'music', 'run']
}
res1 = user_dict.popitem() # 弹出键值对 后进先出
print(res1)
# 结果:('age', 123)
八、元组的内置方法
1、类型转换(把其他类型转换成自己的类型)
tuple()方法,可以for循环的数据类型都是可以转换成元组类型的
2、索引取值
元组的索引取值跟列表的相似,根据索引位置就可以得到对应的值
a = (1, 2, 3, 4, 5)
print(a[3]) # 结果是4
切片取值
元组的切片取值也跟列表相似,它的顺序、步幅也是一样设置的。
a = (1, 2, 3, 4, 5)
print(a[0:3]) # (1, 2, 3)
print(a[2:3]) # (3,)
print(a[::-1]) # (5, 4, 3, 2, 1)
print(a[::]) # (1, 2, 3, 4, 5)
3、统计元组内数据个数——len()
a = (1, 2, 3, 4, 5)
print(len(a)) # 值为5
4、统计某一数据值出现的次数——count
b = (1,1,1,2,2,3,3,)
print(b.count(1)) # 结果为为3
5、查找指定数据值的索引——index
a = (1, 2, 3, 4, 5)
print(a.index(3)) # 结果为2
6、一些注意事项
1.元组的内部如果只有一个数据值,后面需要跟上逗号,否则就会变成数据值对应的类型。
2.元组是不可变类型,但是当元组内绑定上可变类型的时候,绑定的那个可变类型中的数据时可以修改的。
九、集合的内置方法
1、类型转换(把其他类型转换成自己的类型)
这里需要注意,只能把不可变类型的数据值转换成集合,但是只有数字和小数点的列表也可以。
注:集合内部也是无序的,没有索引
s = set([1,2,3,4])
s1 = set((1,2,3,4))
s2 = set({'name':'jason',})
s3 = set('oscar')
print(s)
print(s1)
print(s2)
# 只能取到键
print(s3)
# 结果如下:
'''
{1, 2, 3, 4}
{1, 2, 3, 4}
{'name'}
{'s', 'a', 'r', 'c', 'o'}
'''
2、需要掌握的方法
1.去重
当我们对其他类型数据使用set()方法转换成集合的时候,会自动把其中重复部分删除,但是因为集合是无序的,并不能保持之前的排列顺序。
s1 = {11, 22, 11, 22, 22, 11, 222, 11, 22, 33, 22}
l1 = [11, 22, 33, 22, 11, 22, 33, 22, 11, 22, 33, 22]
s1 = set(l1)
l1 = list(s1)
print(s1)
print(l1)
# 结果如下:
'''
{33, 11, 22}
[33, 11, 22]
'''
2.关系运算
我们可以使用一些符号对集合进行关系运算,这些符号就是一些集合内置方法的化简。
# 假设这是两个人的好友列表
f1 = {'jason', 'tony', 'jerry', 'oscar'} # 用户1的好友列表
f2 = {'jack', 'jason', 'tom', 'tony'} # 用户2的好友列表
# 1.求两个人的共同好友
print(f1 & f2) # {'jason', 'tony'}
# .intersection()方法也是这个效果:得到集合a与集合b共有的元素。
# 2.求用户1独有的好友
print(f1 - f2) # {'jerry', 'oscar'}
# difference()方法也是这个效果:得到集合a中包含,但集合b中不包含的元素。
# 3.求两个人所有的好友
print(f1 | f2) # {'jason', 'jack', 'tom', 'tony', 'oscar', 'jerry'}
# a.union(b) 得到集合a和集合b中,包含的所有元素。
# 4.求两个人各自独有的好友
print(f1 ^ f2) # {'oscar', 'tom', 'jack', 'jerry'}
# symmetric_difference()方法也是这个效果
# 5.父集:一个集合是否包含另外一个集合
# 包含则返回True
print({1, 2, 3} > {1, 2})
# True
print({1, 2, 3} >= {1, 2})
# True
# 不存在包含关系,则返回False
print({1, 2, 3} > {1, 3, 4, 5})
# False
print({1, 2, 3} >= {1, 3, 4, 5})
# False
# 6.子集
print({1, 2} < {1, 2, 3})
# True
print({1, 2} <= {1, 2, 3})
# True
# a.issuperset(b) 判断集合b是否为集合a的子集,即集合b中的元素是否全部包含在集合a中。是为True,否为False。
# a.issubset(b) 判断集合a是否为集合b的子集,即集合a中的元素是否全部包含在集合b中。是为True,否为False。
3、需要了解的方法
1.计算集合中的数据值个数——len()
#长度len()
a = {"11111", 666}
print(len(a)) # 结果为2
2.添加
add
#添加操作.add()
a = {"11111", 666}
a.add("yyds")
print(a) # 结果:{"11111", 666, "yyds"}
update(x)
向集合中,添加x中的每一个元素。x可以是字符串、列表、元组、集合类型。
#添加操作.update()
a = {"11111", 666}
a.update("yyds", "关注了")
print(a) # 结果:{"11111", 666, "yyds", "关注了"}
3.删除操作
.remove(x) 删除集合中的元素x。
#删除操作.remove()
a = {"编程八点档", 666}
a.remove(666)
print(a) # {"编程八点档"}
.discard(x) 删除集合中的元素x。
#删除操作.discard()
a = {"编程八点档", 666}
a.discard(666)
print(a) # {"编程八点档"}
.pop() 随机删除集合中的某个元素。
#删除操作.pop()
a = {"编程八点档", 666}
a.pop()
print(a) # {666}
.clear() 清空集合。
#删除操作.clear()
a = {"编程八点档", 666}
a.clear()
print(a) # set()


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)